
GenAIComps
GenAI components at micro-service level; GenAI service composer to create mega-service
Stars: 132
GenAIComps is an initiative aimed at building enterprise-grade Generative AI applications using a microservice architecture. It simplifies the scaling and deployment process for production, abstracting away infrastructure complexities. GenAIComps provides a suite of containerized microservices that can be assembled into a mega-service tailored for real-world Enterprise AI applications. The modular approach of microservices allows for independent development, deployment, and scaling of individual components, promoting modularity, flexibility, and scalability. The mega-service orchestrates multiple microservices to deliver comprehensive solutions, encapsulating complex business logic and workflow orchestration. The gateway serves as the interface for users to access the mega-service, providing customized access based on user requirements.
README:
Build Enterprise-grade Generative AI Applications with Microservice Architecture
This initiative empowers the development of high-quality Generative AI applications for enterprises via microservices, simplifying the scaling and deployment process for production. It abstracts away infrastructure complexities, facilitating the seamless development and deployment of Enterprise AI services.
GenAIComps provides a suite of microservices, leveraging a service composer to assemble a mega-service tailored for real-world Enterprise AI applications. All the microservices are containerized, allowing cloud native deployment. Checkout how the microservices are used in GenAIExamples.

- Install from Pypi
pip install opea-comps- Build from Source
git clone https://github.com/opea-project/GenAIComps
cd GenAIComps
pip install -e .Microservices are akin to building blocks, offering the fundamental services for constructing RAG (Retrieval-Augmented Generation) and other Enterprise AI applications.
Each Microservice is designed to perform a specific function or task within the application architecture. By breaking down the system into smaller, self-contained services, Microservices promote modularity, flexibility, and scalability.
This modular approach allows developers to independently develop, deploy, and scale individual components of the application, making it easier to maintain and evolve over time. Additionally, Microservices facilitate fault isolation, as issues in one service are less likely to impact the entire system.
The initially supported Microservices are described in the below table. More Microservices are on the way.
A Microservices can be created by using the decorator register_microservice. Taking the embedding microservice as an example:
from comps import register_microservice, EmbedDoc, ServiceType, TextDoc
@register_microservice(
name="opea_service@embedding_tgi_gaudi",
service_type=ServiceType.EMBEDDING,
endpoint="/v1/embeddings",
host="0.0.0.0",
port=6000,
input_datatype=TextDoc,
output_datatype=EmbedDoc,
)
def embedding(input: TextDoc) -> EmbedDoc:
embed_vector = embeddings.embed_query(input.text)
res = EmbedDoc(text=input.text, embedding=embed_vector)
return resA Megaservice is a higher-level architectural construct composed of one or more Microservices, providing the capability to assemble end-to-end applications. Unlike individual Microservices, which focus on specific tasks or functions, a Megaservice orchestrates multiple Microservices to deliver a comprehensive solution.
Megaservices encapsulate complex business logic and workflow orchestration, coordinating the interactions between various Microservices to fulfill specific application requirements. This approach enables the creation of modular yet integrated applications, where each Microservice contributes to the overall functionality of the Megaservice.
Here is a simple example of building Megaservice:
from comps import MicroService, ServiceOrchestrator
EMBEDDING_SERVICE_HOST_IP = os.getenv("EMBEDDING_SERVICE_HOST_IP", "0.0.0.0")
EMBEDDING_SERVICE_PORT = os.getenv("EMBEDDING_SERVICE_PORT", 6000)
LLM_SERVICE_HOST_IP = os.getenv("LLM_SERVICE_HOST_IP", "0.0.0.0")
LLM_SERVICE_PORT = os.getenv("LLM_SERVICE_PORT", 9000)
class ExampleService:
def __init__(self, host="0.0.0.0", port=8000):
self.host = host
self.port = port
self.megaservice = ServiceOrchestrator()
def add_remote_service(self):
embedding = MicroService(
name="embedding",
host=EMBEDDING_SERVICE_HOST_IP,
port=EMBEDDING_SERVICE_PORT,
endpoint="/v1/embeddings",
use_remote_service=True,
service_type=ServiceType.EMBEDDING,
)
llm = MicroService(
name="llm",
host=LLM_SERVICE_HOST_IP,
port=LLM_SERVICE_PORT,
endpoint="/v1/chat/completions",
use_remote_service=True,
service_type=ServiceType.LLM,
)
self.megaservice.add(embedding).add(llm)
self.megaservice.flow_to(embedding, llm)self.gateway = ChatQnAGateway(megaservice=self.megaservice, host="0.0.0.0", port=self.port)
## Check Mega/Micro Service health status and version number
Use below command to check Mega/Micro Service status.
```bash
curl http://${your_ip}:${service_port}/v1/health_check\
-X GET \
-H 'Content-Type: application/json'
Users should get output like below example if Mega/Micro Service works correctly.
{"Service Title":"ChatQnAGateway/MicroService","Version":"1.0","Service Description":"OPEA Microservice Infrastructure"}Welcome to the OPEA open-source community! We are thrilled to have you here and excited about the potential contributions you can bring to the OPEA platform. Whether you are fixing bugs, adding new GenAI components, improving documentation, or sharing your unique use cases, your contributions are invaluable.
Together, we can make OPEA the go-to platform for enterprise AI solutions. Let's work together to push the boundaries of what's possible and create a future where AI is accessible, efficient, and impactful for everyone.
Please check the Contributing guidelines for a detailed guide on how to contribute a GenAI example and all the ways you can contribute!
Thank you for being a part of this journey. We can't wait to see what we can achieve together!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for GenAIComps
Similar Open Source Tools
GenAIComps
GenAIComps is an initiative aimed at building enterprise-grade Generative AI applications using a microservice architecture. It simplifies the scaling and deployment process for production, abstracting away infrastructure complexities. GenAIComps provides a suite of containerized microservices that can be assembled into a mega-service tailored for real-world Enterprise AI applications. The modular approach of microservices allows for independent development, deployment, and scaling of individual components, promoting modularity, flexibility, and scalability. The mega-service orchestrates multiple microservices to deliver comprehensive solutions, encapsulating complex business logic and workflow orchestration. The gateway serves as the interface for users to access the mega-service, providing customized access based on user requirements.
aikit
AIKit is a one-stop shop to quickly get started to host, deploy, build and fine-tune large language models (LLMs). AIKit offers two main capabilities: Inference: AIKit uses LocalAI, which supports a wide range of inference capabilities and formats. LocalAI provides a drop-in replacement REST API that is OpenAI API compatible, so you can use any OpenAI API compatible client, such as Kubectl AI, Chatbot-UI and many more, to send requests to open-source LLMs! Fine Tuning: AIKit offers an extensible fine tuning interface. It supports Unsloth for fast, memory efficient, and easy fine-tuning experience.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
compose-for-agents
Compose for Agents is a tool that allows users to run demos using OpenAI models or locally with Docker Model Runner. The tool supports multi-agent and single-agent systems for various tasks such as fact-checking, summarizing GitHub issues, marketing strategy, SQL queries, travel planning, and more. Users can configure the demos by creating a `.mcp.env` file, supplying required tokens, and running `docker compose up --build`. Additionally, users can utilize OpenAI models by creating a `secret.openai-api-key` file and starting the project with the OpenAI configuration.
aikit
AIKit is a comprehensive platform for hosting, deploying, building, and fine-tuning large language models (LLMs). It offers inference using LocalAI, extensible fine-tuning interface, and OCI packaging for distributing models. AIKit supports various models, multi-modal model and image generation, Kubernetes deployment, and supply chain security. It can run on AMD64 and ARM64 CPUs, NVIDIA GPUs, and Apple Silicon (experimental). Users can quickly get started with AIKit without a GPU and access pre-made models. The platform is OpenAI API compatible and provides easy-to-use configuration for inference and fine-tuning.

FFAIVideo
FFAIVideo is a lightweight node.js project that utilizes popular AI LLM to intelligently generate short videos. It supports multiple AI LLM models such as OpenAI, Moonshot, Azure, g4f, Google Gemini, etc. Users can input text to automatically synthesize exciting video content with subtitles, background music, and customizable settings. The project integrates Microsoft Edge's online text-to-speech service for voice options and uses Pexels website for video resources. Installation of FFmpeg is essential for smooth operation. Inspired by MoneyPrinterTurbo, MoneyPrinter, and MsEdgeTTS, FFAIVideo is designed for front-end developers with minimal dependencies and simple usage.

vscode-unify-chat-provider
The 'vscode-unify-chat-provider' repository is a tool that integrates multiple LLM API providers into VS Code's GitHub Copilot Chat using the Language Model API. It offers free tier access to mainstream models, perfect compatibility with major LLM API formats, deep adaptation to API features, best performance with built-in parameters, out-of-the-box configuration, import/export support, great UX, and one-click use of various models. The tool simplifies model setup, migration, and configuration for users, providing a seamless experience within VS Code for utilizing different language models.
TinyLLM
TinyLLM is a project that helps build a small locally hosted language model with a web interface using consumer-grade hardware. It supports multiple language models, builds a local OpenAI API web service, and serves a Chatbot web interface with customizable prompts. The project requires specific hardware and software configurations for optimal performance. Users can run a local language model using inference servers like vLLM, llama-cpp-python, and Ollama. The Chatbot feature allows users to interact with the language model through a web-based interface, supporting features like summarizing websites, displaying news headlines, stock prices, weather conditions, and using vector databases for queries.
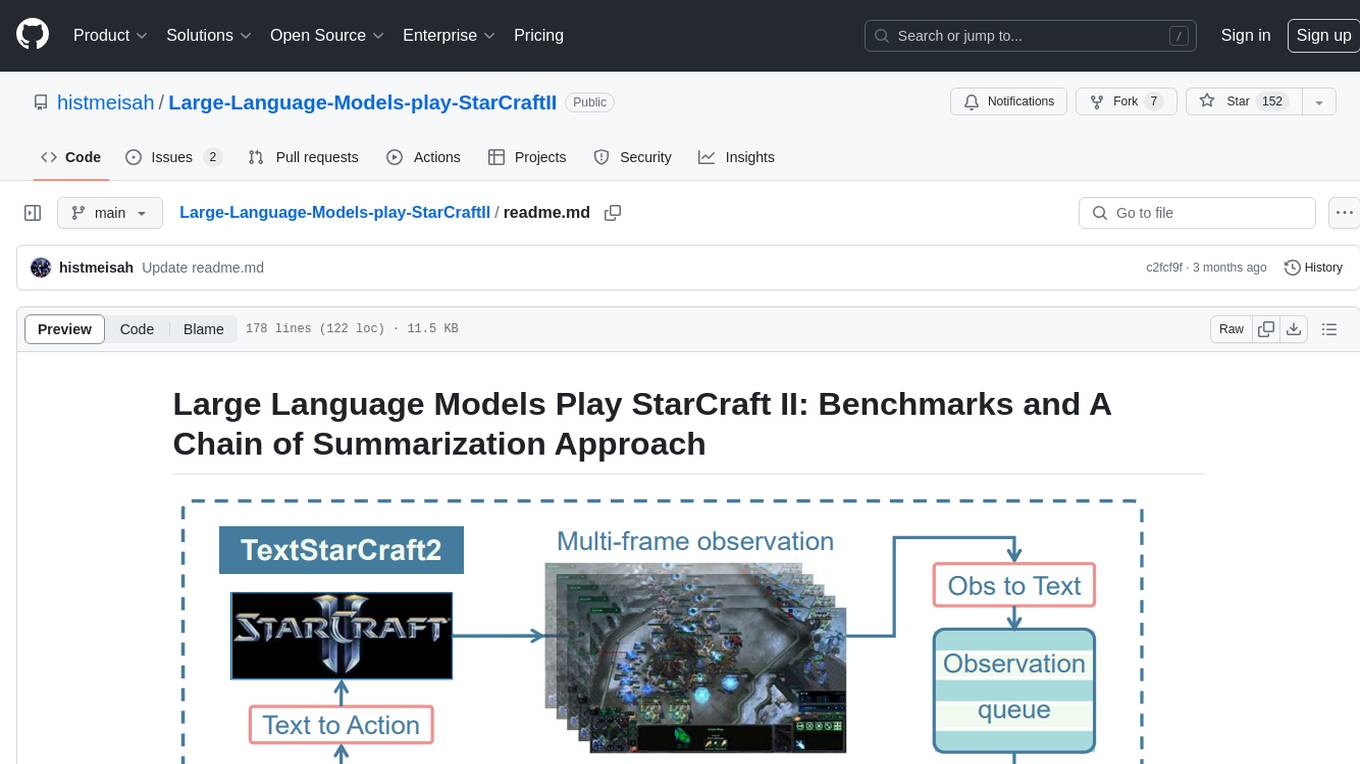
Large-Language-Models-play-StarCraftII
Large Language Models Play StarCraft II is a project that explores the capabilities of large language models (LLMs) in playing the game StarCraft II. The project introduces TextStarCraft II, a textual environment for the game, and a Chain of Summarization method for analyzing game information and making strategic decisions. Through experiments, the project demonstrates that LLM agents can defeat the built-in AI at a challenging difficulty level. The project provides benchmarks and a summarization approach to enhance strategic planning and interpretability in StarCraft II gameplay.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.
agentic
Agentic is a standard AI functions/tools library optimized for TypeScript and LLM-based apps, compatible with major AI SDKs. It offers a set of thoroughly tested AI functions that can be used with favorite AI SDKs without writing glue code. The library includes various clients for services like Bing web search, calculator, Clearbit data resolution, Dexa podcast questions, and more. It also provides compound tools like SearchAndCrawl and supports multiple AI SDKs such as OpenAI, Vercel AI SDK, LangChain, LlamaIndex, Firebase Genkit, and Dexa Dexter. The goal is to create minimal clients with strongly-typed TypeScript DX, composable AIFunctions via AIFunctionSet, and compatibility with major TS AI SDKs.
llm-gateway
llm-gateway is a gateway tool designed for interacting with third-party LLM providers such as OpenAI, Cohere, etc. It tracks data exchanged with these providers in a postgres database, applies PII scrubbing heuristics, and ensures safe communication with OpenAI's services. The tool supports various models from different providers and offers API and Python usage examples. Developers can set up the tool using Poetry, Pyenv, npm, and yarn for dependency management. The project also includes Docker setup for backend and frontend development.
willow-inference-server
Willow Inference Server (WIS) is a highly optimized language inference server implementation focused on enabling performant, cost-effective self-hosting of state-of-the-art models for speech and language tasks. It supports ASR and TTS tasks, runs on CUDA with low-end device support, and offers various transport options like REST, WebRTC, and Web Sockets. WIS is memory optimized, leverages CTranslate2 for Whisper support, and enables custom TTS voices. The server automatically detects available CUDA VRAM and optimizes functionality accordingly. Users can programmatically select Whisper models and parameters for each request to balance speed and quality.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
manim-generator
The 'manim-generator' repository focuses on automatic video generation using an agentic LLM flow combined with the manim python library. It experiments with automated Manim video creation by delegating code drafting and validation to specific roles, reducing render failures, and improving visual consistency through iterative feedback and vision inputs. The project also includes 'Manim Bench' for comparing AI models on full Manim video generation.
For similar tasks
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.
MoonshotAI-Cookbook
The MoonshotAI-Cookbook provides example code and guides for accomplishing common tasks with the MoonshotAI API. To run these examples, you'll need an MoonshotAI account and associated API key. Most code examples are written in Python, though the concepts can be applied in any language.
AHU-AI-Repository
This repository is dedicated to the learning and exchange of resources for the School of Artificial Intelligence at Anhui University. Notes will be published on this website first: https://www.aoaoaoao.cn and will be synchronized to the repository regularly. You can also contact me at [email protected].
modern_ai_for_beginners
This repository provides a comprehensive guide to modern AI for beginners, covering both theoretical foundations and practical implementation. It emphasizes the importance of understanding both the mathematical principles and the code implementation of AI models. The repository includes resources on PyTorch, deep learning fundamentals, mathematical foundations, transformer-based LLMs, diffusion models, software engineering, and full-stack development. It also features tutorials on natural language processing with transformers, reinforcement learning, and practical deep learning for coders.
Building-AI-Applications-with-ChatGPT-APIs
This repository is for the book 'Building AI Applications with ChatGPT APIs' published by Packt. It provides code examples and instructions for mastering ChatGPT, Whisper, and DALL-E APIs through building innovative AI projects. Readers will learn to develop AI applications using ChatGPT APIs, integrate them with frameworks like Flask and Django, create AI-generated art with DALL-E APIs, and optimize ChatGPT models through fine-tuning.
examples
This repository contains a collection of sample applications and Jupyter Notebooks for hands-on experience with Pinecone vector databases and common AI patterns, tools, and algorithms. It includes production-ready examples for review and support, as well as learning-optimized examples for exploring AI techniques and building applications. Users can contribute, provide feedback, and collaborate to improve the resource.
lingoose
LinGoose is a modular Go framework designed for building AI/LLM applications. It offers the flexibility to import only the necessary modules, abstracts features for customization, and provides a comprehensive solution for developing AI/LLM applications from scratch. The framework simplifies the process of creating intelligent applications by allowing users to choose preferred implementations or create their own. LinGoose empowers developers to leverage its capabilities to streamline the development of cutting-edge AI and LLM projects.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.