
optillm
Optimizing inference proxy for LLMs
Stars: 2848

optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
README:
![]()
🚀 2-10x accuracy improvements on reasoning tasks with zero training




🤗 HuggingFace Space • 📓 Colab Demo • 💬 Discussions
OptiLLM is an OpenAI API-compatible optimizing inference proxy that implements 20+ state-of-the-art techniques to dramatically improve LLM accuracy and performance on reasoning tasks - without requiring any model training or fine-tuning.
It is possible to beat the frontier models using these techniques across diverse tasks by doing additional compute at inference time. A good example of how to combine such techniques together is the CePO approach from Cerebras.
- 🎯 Instant Improvements: 2-10x better accuracy on math, coding, and logical reasoning
- 🔌 Drop-in Replacement: Works with any OpenAI-compatible API endpoint
- 🧠 20+ Optimization Techniques: From simple best-of-N to advanced MCTS and planning
- 📦 Zero Training Required: Just proxy your existing API calls through OptiLLM
- ⚡ Production Ready: Used in production by companies and researchers worldwide
- 🌍 Multi-Provider: Supports OpenAI, Anthropic, Google, Cerebras, and 100+ models via LiteLLM
Get powerful reasoning improvements in 3 simple steps:
# 1. Install OptiLLM
pip install optillm
# 2. Start the server
export OPENAI_API_KEY="your-key-here"
optillm
# 3. Use with any OpenAI client - just change the model name!from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1")
# Add 'moa-' prefix for Mixture of Agents optimization
response = client.chat.completions.create(
model="moa-gpt-4o-mini", # This gives you GPT-4o performance from GPT-4o-mini!
messages=[{"role": "user", "content": "Solve: If 2x + 3 = 7, what is x?"}]
)Before OptiLLM: "x = 1" ❌
After OptiLLM: "Let me work through this step by step: 2x + 3 = 7, so 2x = 4, therefore x = 2" ✅
OptiLLM delivers measurable improvements across diverse benchmarks:
| Technique | Base Model | Improvement | Benchmark |
|---|---|---|---|
| CePO | Llama 3.3 70B | +18.6 points | Math-L5 (51.0→69.6) |
| AutoThink | DeepSeek-R1-1.5B | +9.34 points | GPQA-Diamond (21.72→31.06) |
| LongCePO | Llama 3.3 70B | +13.6 points | InfiniteBench (58.0→71.6) |
| MOA | GPT-4o-mini | Matches GPT-4 | Arena-Hard-Auto |
| PlanSearch | GPT-4o-mini | +20% pass@5 | LiveCodeBench |
Full benchmark results below ⬇️
pip install optillm
optillm
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
2024-10-22 07:45:06,293 - INFO - Starting server with approach: autodocker pull ghcr.io/codelion/optillm:latest
docker run -p 8000:8000 ghcr.io/codelion/optillm:latest
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
2024-10-22 07:45:06,293 - INFO - Starting server with approach: autoTo use optillm without local inference and only as a proxy you can add the -proxy suffix.
docker pull ghcr.io/codelion/optillm:latest-proxyClone the repository with git and use pip install to setup the dependencies.
git clone https://github.com/codelion/optillm.git
cd optillm
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt| Approach | Slug | Description |
|---|---|---|
| Cerebras Planning and Optimization | cepo |
Combines Best of N, Chain-of-Thought, Self-Reflection, Self-Improvement, and various prompting techniques |
| CoT with Reflection | cot_reflection |
Implements chain-of-thought reasoning with <thinking>, <reflection> and <output> sections |
| PlanSearch | plansearch |
Implements a search algorithm over candidate plans for solving a problem in natural language |
| ReRead | re2 |
Implements rereading to improve reasoning by processing queries twice |
| Self-Consistency | self_consistency |
Implements an advanced self-consistency method |
| Z3 Solver | z3 |
Utilizes the Z3 theorem prover for logical reasoning |
| R* Algorithm | rstar |
Implements the R* algorithm for problem-solving |
| LEAP | leap |
Learns task-specific principles from few shot examples |
| Round Trip Optimization | rto |
Optimizes responses through a round-trip process |
| Best of N Sampling | bon |
Generates multiple responses and selects the best one |
| Mixture of Agents | moa |
Combines responses from multiple critiques |
| Monte Carlo Tree Search | mcts |
Uses MCTS for decision-making in chat responses |
| PV Game | pvg |
Applies a prover-verifier game approach at inference time |
| Deep Confidence | N/A for proxy | Implements confidence-guided reasoning with multiple intensity levels for enhanced accuracy |
| CoT Decoding | N/A for proxy | Implements chain-of-thought decoding to elicit reasoning without explicit prompting |
| Entropy Decoding | N/A for proxy | Implements adaptive sampling based on the uncertainty of tokens during generation |
| Thinkdeeper | N/A for proxy | Implements the reasoning_effort param from OpenAI for reasoning models like DeepSeek R1 |
| AutoThink | N/A for proxy | Combines query complexity classification with steering vectors to enhance reasoning |
| Plugin | Slug | Description |
|---|---|---|
| System Prompt Learning | spl |
Implements what Andrej Karpathy called the third paradigm for LLM learning, this enables the model to acquire program solving knowledge and strategies |
| Deep Think | deepthink |
Implements a Gemini-like Deep Think approach using inference time scaling for reasoning LLMs |
| Long-Context Cerebras Planning and Optimization | longcepo |
Combines planning and divide-and-conquer processing of long documents to enable infinite context |
| Majority Voting | majority_voting |
Generates k candidate solutions and selects the most frequent answer through majority voting (default k=6) |
| MCP Client | mcp |
Implements the model context protocol (MCP) client, enabling you to use any LLM with any MCP Server |
| Router | router |
Uses the optillm-modernbert-large model to route requests to different approaches based on the user prompt |
| Chain-of-Code | coc |
Implements a chain of code approach that combines CoT with code execution and LLM based code simulation |
| Memory | memory |
Implements a short term memory layer, enables you to use unbounded context length with any LLM |
| Privacy | privacy |
Anonymize PII data in request and deanonymize it back to original value in response |
| Read URLs | readurls |
Reads all URLs found in the request, fetches the content at the URL and adds it to the context |
| Execute Code | executecode |
Enables use of code interpreter to execute python code in requests and LLM generated responses |
| JSON | json |
Enables structured outputs using the outlines library, supports pydantic types and JSON schema |
| GenSelect | genselect |
Generative Solution Selection - generates multiple candidates and selects the best based on quality criteria |
| Web Search | web_search |
Performs Google searches using Chrome automation (Selenium) to gather search results and URLs |
| Deep Research | deep_research |
Implements Test-Time Diffusion Deep Researcher (TTD-DR) for comprehensive research reports using iterative refinement |
| Proxy | proxy |
Load balancing and failover across multiple LLM providers with health monitoring and round-robin routing |
We support all major LLM providers and models for inference. You need to set the correct environment variable and the proxy will pick the corresponding client.
| Provider | Required Environment Variables | Additional Notes |
|---|---|---|
| OptiLLM | OPTILLM_API_KEY |
Uses the inbuilt local server for inference, supports logprobs and decoding techniques like cot_decoding & entropy_decoding
|
| OpenAI | OPENAI_API_KEY |
You can use this with any OpenAI compatible endpoint (e.g. OpenRouter) by setting the base_url
|
| Cerebras | CEREBRAS_API_KEY |
You can use this for fast inference with supported models, see docs for details |
| Azure OpenAI |
AZURE_OPENAI_API_KEYAZURE_API_VERSIONAZURE_API_BASE
|
- |
| Azure OpenAI (Managed Identity) |
AZURE_API_VERSIONAZURE_API_BASE
|
Login required using az login, see docs for details
|
| LiteLLM | depends on the model | See docs for details |
You can then run the optillm proxy as follows.
python optillm.py
2024-09-06 07:57:14,191 - INFO - Starting server with approach: auto
2024-09-06 07:57:14,191 - INFO - Server configuration: {'approach': 'auto', 'mcts_simulations': 2, 'mcts_exploration': 0.2, 'mcts_depth': 1, 'best_of_n': 3, 'model': 'gpt-4o-mini', 'rstar_max_depth': 3, 'rstar_num_rollouts': 5, 'rstar_c': 1.4, 'base_url': ''}
* Serving Flask app 'optillm'
* Debug mode: off
2024-09-06 07:57:14,212 - INFO - WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:8000
* Running on http://192.168.10.48:8000
2024-09-06 07:57:14,212 - INFO - Press CTRL+C to quitOnce the proxy is running, you can use it as a drop in replacement for an OpenAI client by setting the base_url as http://localhost:8000/v1.
import os
from openai import OpenAI
OPENAI_KEY = os.environ.get("OPENAI_API_KEY")
OPENAI_BASE_URL = "http://localhost:8000/v1"
client = OpenAI(api_key=OPENAI_KEY, base_url=OPENAI_BASE_URL)
response = client.chat.completions.create(
model="moa-gpt-4o",
messages=[
{
"role": "user",
"content": "Write a Python program to build an RL model to recite text from any position that the user provides, using only numpy."
}
],
temperature=0.2
)
print(response)The code above applies to both OpenAI and Azure OpenAI, just remember to populate the OPENAI_API_KEY env variable with the proper key.
There are multiple ways to control the optimization techniques, they are applied in the follow order of preference:
- You can control the technique you use for optimization by prepending the slug to the model name
{slug}-model-name. E.g. in the above code we are usingmoaor mixture of agents as the optimization approach. In the proxy logs you will see the following showing themoais been used with the base model asgpt-4o-mini.
2024-09-06 08:35:32,597 - INFO - Using approach moa, with gpt-4o-mini
2024-09-06 08:35:35,358 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:39,553 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,795 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,797 - INFO - 127.0.0.1 - - [06/Sep/2024 08:35:44] "POST /v1/chat/completions HTTP/1.1" 200 -- Or, you can pass the slug in the
optillm_approachfield in theextra_body.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "" }],
temperature=0.2,
extra_body={"optillm_approach": "bon|moa|mcts"}
)- Or, you can just mention the approach in either your
systemoruserprompt, within<optillm_approach> </optillm_approach>tags.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "<optillm_approach>re2</optillm_approach> How many r's are there in strawberry?" }],
temperature=0.2
)[!TIP] You can also combine different techniques either by using symbols
&and|. When you use&the techniques are processed in the order from left to right in a pipeline with response from previous stage used as request to the next. While, with|we run all the requests in parallel and generate multiple responses that are returned as a list.
Please note that the convention described above works only when the optillm server has been started with inference approach set to auto. Otherwise, the model attribute in the client request must be set with the model name only.
We now support all LLM providers (by wrapping around the LiteLLM sdk). E.g. you can use the Gemini Flash model with moa by setting passing the api key in the environment variable os.environ['GEMINI_API_KEY'] and then calling the model moa-gemini/gemini-1.5-flash-002. In the output you will then see that LiteLLM is being used to call the base model.
9:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,011 - INFO -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,481 - INFO - HTTP Request: POST https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-002:generateContent?key=[redacted] "HTTP/1.1 200 OK"
19:43:21 - LiteLLM:INFO: utils.py:988 - Wrapper: Completed Call, calling success_handler
2024-09-29 19:43:21,483 - INFO - Wrapper: Completed Call, calling success_handler
19:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini[!TIP] optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes the same OpenAI API compatible chat completions endpoint. This should allow you to integrate it into any existing tools or frameworks easily. If the LLM you want to use doesn't have an OpenAI API compatible endpoint (like Google or Anthropic) you can use LiteLLM proxy server that supports most LLMs.
The following sequence diagram illustrates how the request and responses go through optillm.
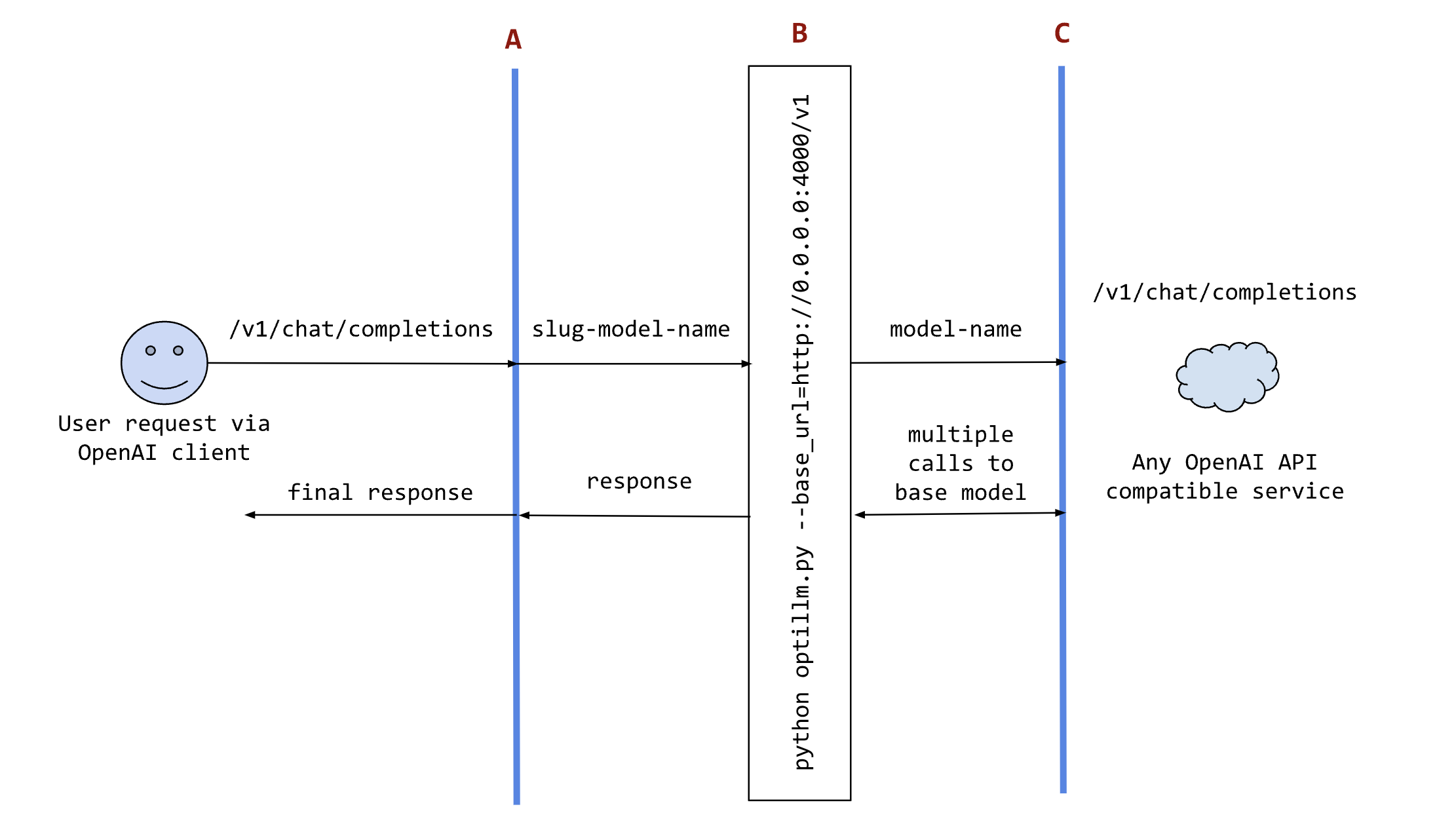
In the diagram:
-
Ais an existing tool (like oobabooga), framework (like patchwork) or your own code where you want to use the results from optillm. You can use it directly using any OpenAI client sdk. -
Bis the optillm service (running directly or in a docker container) that will send requests to thebase_url. -
Cis any service providing an OpenAI API compatible chat completions endpoint.
We support loading any HuggingFace model or LoRA directly in optillm. To use the built-in inference server set the OPTILLM_API_KEY to any value (e.g. export OPTILLM_API_KEY="optillm")
and then use the same in your OpenAI client. You can pass any HuggingFace model in model field. If it is a private model make sure you set the HF_TOKEN environment variable
with your HuggingFace key. We also support adding any number of LoRAs on top of the model by using the + separator.
E.g. The following code loads the base model meta-llama/Llama-3.2-1B-Instruct and then adds two LoRAs on top - patched-codes/Llama-3.2-1B-FixVulns and patched-codes/Llama-3.2-1B-FastApply.
You can specify which LoRA to use using the active_adapter param in extra_body field of OpenAI SDK client. By default we will load the last specified adapter.
OPENAI_BASE_URL = "http://localhost:8000/v1"
OPENAI_KEY = "optillm"
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct+patched-codes/Llama-3.2-1B-FastApply+patched-codes/Llama-3.2-1B-FixVulns",
messages=messages,
temperature=0.2,
logprobs = True,
top_logprobs = 3,
extra_body={"active_adapter": "patched-codes/Llama-3.2-1B-FastApply"},
)You can also use the alternate decoding techniques like cot_decoding and entropy_decoding directly with the local inference server.
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
messages=messages,
temperature=0.2,
extra_body={
"decoding": "cot_decoding", # or "entropy_decoding"
# CoT specific params
"k": 10,
"aggregate_paths": True,
# OR Entropy specific params
"top_k": 27,
"min_p": 0.03,
}
)- Set the
OPENAI_API_KEYenv variable to a placeholder value- e.g.
export OPENAI_API_KEY="sk-no-key"
- e.g.
- Run
./llama-server -c 4096 -m path_to_modelto start the server with the specified model and a context length of 4096 tokens - Run
python3 optillm.py --base_url base_urlto start the proxy- e.g. for llama.cpp, run
python3 optillm.py --base_url http://localhost:8080/v1
- e.g. for llama.cpp, run
[!WARNING] The Anthropic API, llama.cpp-server, and ollama currently do not support sampling multiple responses from a model, which limits the available approaches to the following:
cot_reflection,leap,plansearch,rstar,rto,self_consistency,re2, andz3. For models on HuggingFace, you can use the built-in local inference server as it supports multiple responses.
The Model Context Protocol (MCP) plugin enables OptiLLM to connect with MCP servers, bringing external tools, resources, and prompts into the context of language models. This allows for powerful integrations with filesystem access, database queries, API connections, and more.
The Model Context Protocol (MCP) is an open protocol standard that allows LLMs to securely access tools and data sources through a standardized interface. MCP servers can provide:
- Tools: Callable functions that perform actions (like writing files, querying databases, etc.)
- Resources: Data sources for providing context (like file contents)
- Prompts: Reusable prompt templates for specific use cases
- Create a configuration file at
~/.optillm/mcp_config.jsonwith the following structure:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/path/to/allowed/directory1",
"/path/to/allowed/directory2"
],
"env": {}
}
},
"log_level": "INFO"
}Each server entry in mcpServers consists of:
- Server name: A unique identifier for the server (e.g., "filesystem")
- command: The executable to run the server
- args: Command-line arguments for the server
- env: Environment variables for the server process
- description (optional): Description of the server's functionality
You can use any of the official MCP servers or third-party servers. Some popular options include:
-
Filesystem:
@modelcontextprotocol/server-filesystem- File operations -
Git:
mcp-server-git- Git repository operations -
SQLite:
@modelcontextprotocol/server-sqlite- SQLite database access -
Brave Search:
@modelcontextprotocol/server-brave-search- Web search capabilities
Example configuration for multiple servers:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/home/user/documents"],
"env": {}
},
"search": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-brave-search"],
"env": {
"BRAVE_API_KEY": "your-api-key-here"
}
}
},
"log_level": "INFO"
}Once configured, the MCP plugin will automatically:
- Connect to all configured MCP servers
- Discover available tools, resources, and prompts
- Make these capabilities available to the language model
- Handle tool calls and resource requests
The plugin enhances the system prompt with MCP capabilities so the model knows which tools are available. When the model decides to use a tool, the plugin:
- Executes the tool with the provided arguments
- Returns the results to the model
- Allows the model to incorporate the results into its response
Here are some examples of queries that will engage MCP tools:
- "List all the Python files in my documents directory" (Filesystem)
- "What are the recent commits in my Git repository?" (Git)
- "Search for the latest information about renewable energy" (Search)
- "Query my database for all users who registered this month" (Database)
The MCP plugin logs detailed information to:
~/.optillm/logs/mcp_plugin.log
Check this log file for connection issues, tool execution errors, and other diagnostic information.
-
Command not found: Make sure the server executable is available in your PATH, or use an absolute path in the configuration.
-
Connection failed: Verify the server is properly configured and any required API keys are provided.
-
Method not found: Some servers don't implement all MCP capabilities (tools, resources, prompts). Verify which capabilities the server supports.
-
Access denied: For filesystem operations, ensure the paths specified in the configuration are accessible to the process.
optillm supports various command-line arguments for configuration. When using Docker, these can also be set as environment variables prefixed with OPTILLM_.
| Parameter | Description | Default Value |
|---|---|---|
--approach |
Inference approach to use | "auto" |
--simulations |
Number of MCTS simulations | 2 |
--exploration |
Exploration weight for MCTS | 0.2 |
--depth |
Simulation depth for MCTS | 1 |
--best-of-n |
Number of samples for best_of_n approach | 3 |
--model |
OpenAI model to use | "gpt-4o-mini" |
--base-url |
Base URL for OpenAI compatible endpoint | "" |
--rstar-max-depth |
Maximum depth for rStar algorithm | 3 |
--rstar-num-rollouts |
Number of rollouts for rStar algorithm | 5 |
--rstar-c |
Exploration constant for rStar algorithm | 1.4 |
--n |
Number of final responses to be returned | 1 |
--return-full-response |
Return the full response including the CoT with tags | False |
--port |
Specify the port to run the proxy | 8000 |
--optillm-api-key |
Optional API key for client authentication to optillm | "" |
--cepo_* |
See CePO Parameters section below for detailed config options | Various |
CePO Parameters
| Parameter | Description | Default Value |
|---|---|---|
--cepo_bestofn_n |
Number of responses to be generated in best of n stage | 3 |
--cepo_bestofn_temperature |
Temperature for verifier in best of n stage | 0.1 |
--cepo_bestofn_max_tokens |
Maximum number of tokens for verifier in best of n stage | 4096 |
--cepo_bestofn_rating_type |
Type of rating in best of n stage ("absolute" or "pairwise") | "absolute" |
--cepo_planning_n |
Number of plans generated in planning stage | 3 |
--cepo_planning_m |
Number of attempts to generate n plans in planning stage | 6 |
--cepo_planning_temperature_step1 |
Temperature for generator in step 1 of planning stage | 0.55 |
--cepo_planning_temperature_step2 |
Temperature for generator in step 2 of planning stage | 0.25 |
--cepo_planning_temperature_step3 |
Temperature for generator in step 3 of planning stage | 0.1 |
--cepo_planning_temperature_step4 |
Temperature for generator in step 4 of planning stage | 0 |
--cepo_planning_max_tokens_step1 |
Maximum number of tokens in step 1 of planning stage | 4096 |
--cepo_planning_max_tokens_step2 |
Maximum number of tokens in step 2 of planning stage | 4096 |
--cepo_planning_max_tokens_step3 |
Maximum number of tokens in step 3 of planning stage | 4096 |
--cepo_planning_max_tokens_step4 |
Maximum number of tokens in step 4 of planning stage | 4096 |
--cepo_print_output |
Whether to print the output of each stage | False |
--cepo_config_file |
Path to CePO configuration file | None |
--cepo_use_plan_diversity |
Use additional plan diversity step | False |
--cepo_rating_model |
Specify a model for rating step if different than for completion | None |
optillm can optionally be built and run using Docker and the provided Dockerfile.
-
Make sure you have Docker and Docker Compose installed on your system.
-
Either update the environment variables in the docker-compose.yaml file or create a
.envfile in the project root directory and add any environment variables you want to set. For example, to set the OpenAI API key, add the following line to the.envfile:OPENAI_API_KEY=your_openai_api_key_here
-
Run the following command to start optillm:
docker compose up -d
This will build the Docker image if it doesn't exist and start the optillm service.
-
optillm will be available at
http://localhost:8000.
When using Docker, you can set these parameters as environment variables. For example, to set the approach and model, you would use:
OPTILLM_APPROACH=mcts
OPTILLM_MODEL=gpt-4To secure the optillm proxy with an API key, set the OPTILLM_API_KEY environment variable:
OPTILLM_API_KEY=your_secret_api_keyWhen the API key is set, clients must include it in their requests using the Authorization header:
Authorization: Bearer your_secret_api_key
| Model | GPQA-Diamond | MMLU-Pro | ||
|---|---|---|---|---|
| Accuracy (%) | Avg. Tokens | Accuracy (%) | Avg. Tokens | |
| DeepSeek-R1-Distill-Qwen-1.5B | 21.72 | 7868.26 | 25.58 | 2842.75 |
| with Fixed Budget | 28.47 | 3570.00 | 26.18 | 1815.67 |
| with AutoThink | 31.06 | 3520.52 | 26.38 | 1792.50 |
| Model¹ | Context window | Short samples (up to 32K words) | Medium samples (32–128K words) |
|---|---|---|---|
| Llama 3.3 70B Instruct | 128K | 36.7 (45.0) | 27.0 (33.0) |
| LongCePO + Llama 3.3 70B Instruct | 8K | 36.8 ± 1.38 | 38.7 ± 2.574 (39.735)² |
| Mistral-Large-Instruct-2411 | 128K | 41.7 (46.1) | 30.7 (34.9) |
| o1-mini-2024-09-12 | 128K | 48.6 (48.9) | 33.3 (32.9) |
| Claude-3.5-Sonnet-20241022 | 200K | 46.1 (53.9) | 38.6 (41.9) |
| Llama-4-Maverick-17B-128E-Instruct | 524K | 32.22 (50.56) | 28.84 (41.86) |
¹ Performance numbers reported by LongBench v2 authors, except for LongCePO and Llama-4-Maverick results.
² Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
| Model | Accuracy (%) |
|---|---|
| Llama 3.3 70B Instruct (full context) | 58.0 |
| LongCePO + Llama 3.3 70B Instruct (8K context) | 71.6 ± 1.855 (73.0)¹ |
| o1-mini-2024-09-12 (full context) | 58.0 |
| gpt-4o-2024-08-06 (full context) | 74.0 |
¹ Numbers in parentheses for LongCePO indicate accuracy of majority voting from 5 runs.
| Method | Math-L5 | MMLU-Pro (Math) | CRUX | LiveCodeBench (pass@1) | Simple QA |
|---|---|---|---|---|---|
| Llama 3.3 70B | 51.0 | 78.6 | 72.6 | 27.1 | 20.9 |
| Llama 3.1 405B | 49.8 | 79.2 | 73.0 | 31.8 | 13.5 |
| CePO (using Llama 3.3 70B) | 69.6 | 84.8 | 80.1 | 31.9 | 22.6 |
| QwQ 32B | 61.4 | 90.8 | 82.5 | 44.3 | 7.8 |
| CePO (using QwQ 32B) | 88.1 | 92.0 | 86.3 | 51.5 | 8.2 |
| DeepSeek R1 Llama | 83.1 | 82.0 | 84.0 | 47.3 | 14.6 |
| CePO (using DeepSeek R1 Llama) | 90.2 | 84.0 | 89.4 | 47.2 | 15.5 |
| Model | Score |
|---|---|
| o1-mini | 56.67 |
| coc-claude-3-5-sonnet-20241022 | 46.67 |
| coc-gemini/gemini-exp-1121 | 46.67 |
| o1-preview | 40.00 |
| gemini-exp-1114 | 36.67 |
| claude-3-5-sonnet-20241022 | 20.00 |
| gemini-1.5-pro-002 | 20.00 |
| gemini-1.5-flash-002 | 16.67 |
| Model | Accuracy |
|---|---|
| readurls&memory-gpt-4o-mini | 61.29 |
| gpt-4o-mini | 50.61 |
| readurls&memory-Gemma2-9b | 30.1 |
| Gemma2-9b | 5.1 |
| Gemma2-27b | 30.8 |
| Gemini Flash 1.5 | 66.5 |
| Gemini Pro 1.5 | 72.9 |
| Model | pass@1 | pass@5 | pass@10 |
|---|---|---|---|
| plansearch-gpt-4o-mini | 44.03 | 59.31 | 63.5 |
| gpt-4o-mini | 43.9 | 50.61 | 53.25 |
| claude-3.5-sonnet | 51.3 | ||
| gpt-4o-2024-05-13 | 45.2 | ||
| gpt-4-turbo-2024-04-09 | 44.2 |
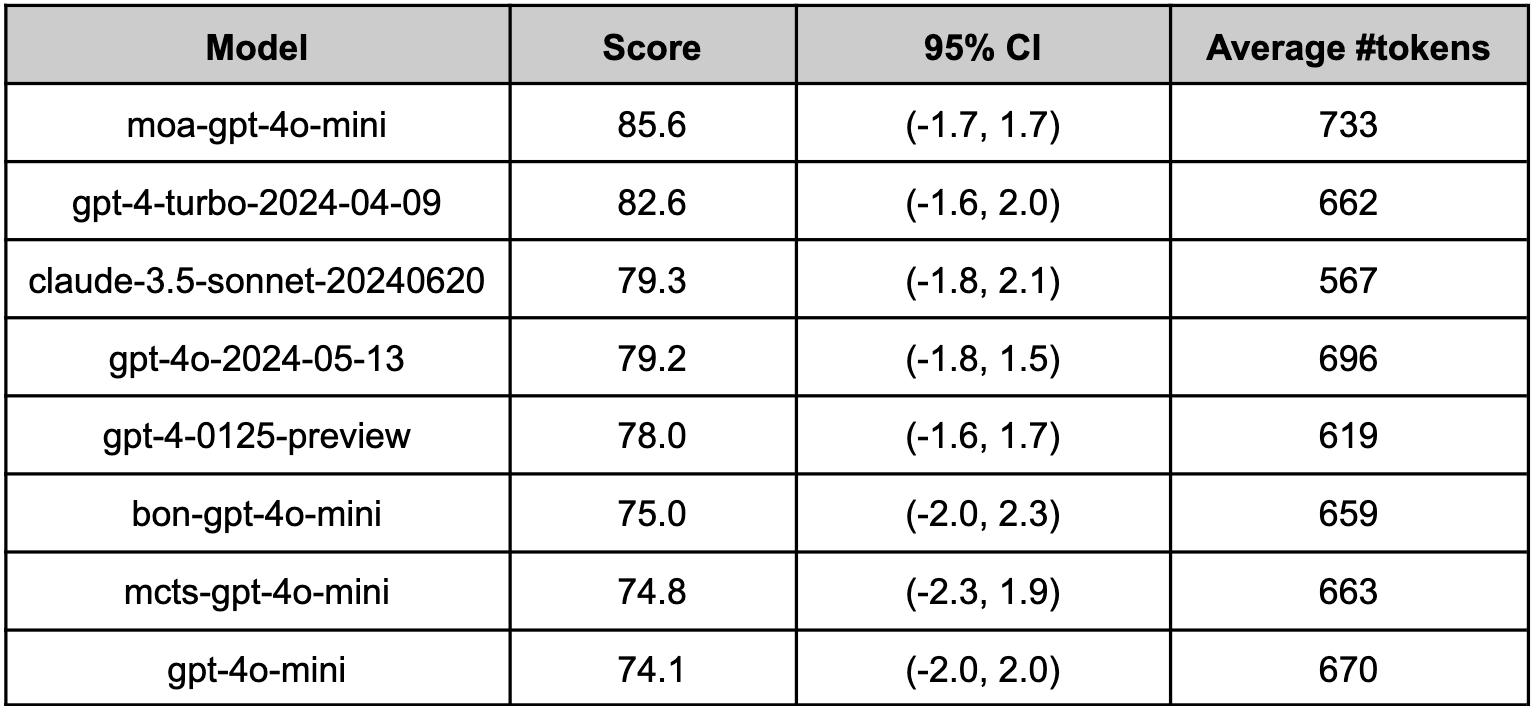
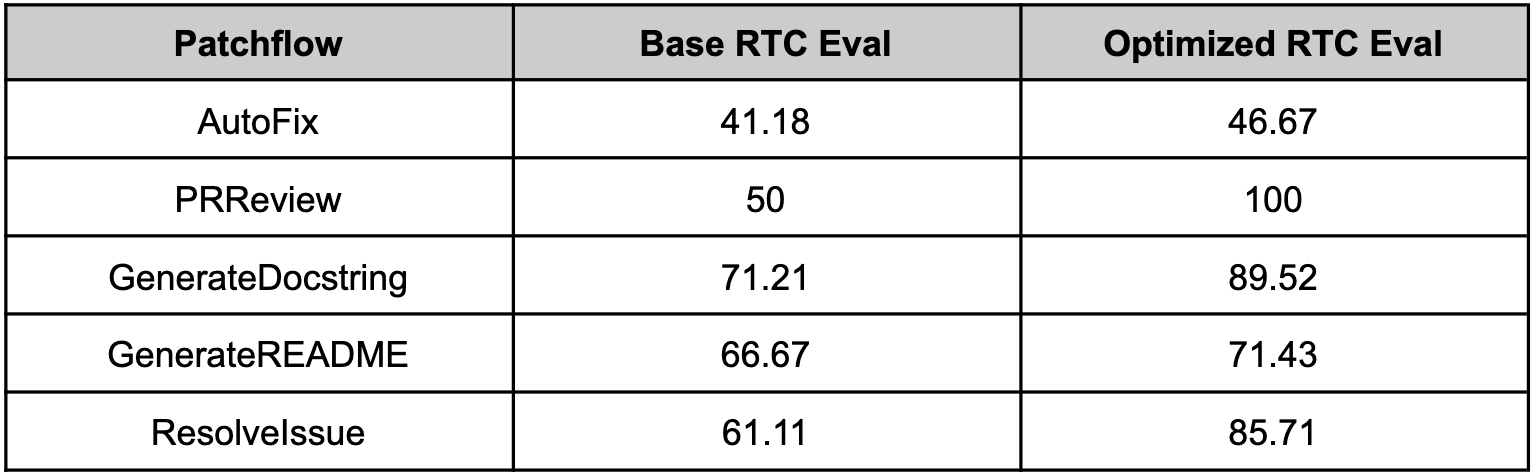
Since optillm is a drop-in replacement for OpenAI API you can easily integrate it with existing tools and frameworks using the OpenAI client. We used optillm with patchwork which is an open-source framework that automates development gruntwork like PR reviews, bug fixing, security patching using workflows called patchflows. We saw huge performance gains across all the supported patchflows as shown below when using the mixture of agents approach (moa).
OptiLLM includes a comprehensive test suite to ensure reliability and compatibility.
The main test suite can be run from the project root:
# Test all approaches with default test cases
python tests/test.py
# Test specific approaches
python tests/test.py --approaches moa bon mcts
# Run a single test
python tests/test.py --single-test "Simple Math Problem"Additional tests are available in the tests/ directory:
# Run all tests (requires pytest)
./tests/run_tests.sh
# Run specific test modules
pytest tests/test_plugins.py -v
pytest tests/test_api_compatibility.py -vAll tests are automatically run on pull requests via GitHub Actions. The workflow tests:
- Multiple Python versions (3.10, 3.11, 3.12)
- Unit tests for plugins and core functionality
- API compatibility tests
- Integration tests with various approaches
See tests/README.md for more details on the test structure and how to write new tests.
We ❤️ contributions! OptiLLM is built by the community, for the community.
- 🐛 Found a bug? Open an issue
- 💡 Have an idea? Start a discussion
- 🔧 Want to code? Check out good first issues
git clone https://github.com/codelion/optillm.git
cd optillm
python -m venv .venv
source .venv/bin/activate # or `.venv\Scripts\activate` on Windows
pip install -r requirements.txt
pip install -r tests/requirements.txt
# Run tests
python -m pytest tests/- Eliciting Fine-Tuned Transformer Capabilities via Inference-Time Techniques
- AutoThink: efficient inference for reasoning LLMs - Implementation
- Deep Think with Confidence: Confidence-guided reasoning and inference-time scaling - Implementation
- Self-Discover: Large Language Models Self-Compose Reasoning Structures - Implementation
- CePO: Empowering Llama with Reasoning using Test-Time Compute - Implementation
- LongCePO: Empowering LLMs to efficiently leverage infinite context - Implementation
- Chain of Code: Reasoning with a Language Model-Augmented Code Emulator - Inspired the implementation of coc plugin
- Entropy Based Sampling and Parallel CoT Decoding - Implementation
- Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation - Evaluation script
- Writing in the Margins: Better Inference Pattern for Long Context Retrieval - Inspired the implementation of the memory plugin
- Chain-of-Thought Reasoning Without Prompting - Implementation
- Re-Reading Improves Reasoning in Large Language Models - Implementation
- In-Context Principle Learning from Mistakes - Implementation
- Planning In Natural Language Improves LLM Search For Code Generation - Implementation
- Self-Consistency Improves Chain of Thought Reasoning in Language Models - Implementation
- Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers - Implementation
- Mixture-of-Agents Enhances Large Language Model Capabilities - Inspired the implementation of moa
- Prover-Verifier Games improve legibility of LLM outputs - Implementation
- Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning - Inspired the implementation of mcts
- Unsupervised Evaluation of Code LLMs with Round-Trip Correctness - Inspired the implementation of rto
- Patched MOA: optimizing inference for diverse software development tasks - Implementation
- Patched RTC: evaluating LLMs for diverse software development tasks - Implementation
- AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset - Implementation
- Test-Time Diffusion Deep Researcher (TTD-DR): Think More, Research More, Answer Better! - Implementation
If you use this library in your research, please cite:
@software{optillm,
title = {OptiLLM: Optimizing inference proxy for LLMs},
author = {Asankhaya Sharma},
year = {2024},
publisher = {GitHub},
url = {https://github.com/codelion/optillm}
}Ready to optimize your LLMs? Install OptiLLM and see the difference! 🚀
⭐ Star us on GitHub if you find OptiLLM useful!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for optillm
Similar Open Source Tools
optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
llm-structured-output-benchmarks
Benchmark various LLM Structured Output frameworks like Instructor, Mirascope, Langchain, LlamaIndex, Fructose, Marvin, Outlines, LMFormatEnforcer, etc on tasks like multi-label classification, named entity recognition, synthetic data generation. The tool provides benchmark results, methodology, instructions to run the benchmark, add new data, and add a new framework. It also includes a roadmap for framework-related tasks, contribution guidelines, citation information, and feedback request.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.
gpt-load
GPT-Load is a high-performance, enterprise-grade AI API transparent proxy service designed for enterprises and developers needing to integrate multiple AI services. Built with Go, it features intelligent key management, load balancing, and comprehensive monitoring capabilities for high-concurrency production environments. The tool serves as a transparent proxy service, preserving native API formats of various AI service providers like OpenAI, Google Gemini, and Anthropic Claude. It supports dynamic configuration, distributed leader-follower deployment, and a Vue 3-based web management interface. GPT-Load is production-ready with features like dual authentication, graceful shutdown, and error recovery.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.
terminator
Terminator is an AI-powered desktop automation tool that is open source, MIT-licensed, and cross-platform. It works across all apps and browsers, inspired by GitHub Actions & Playwright. It is 100x faster than generic AI agents, with over 95% success rate and no vendor lock-in. Users can create automations that work across any desktop app or browser, achieve high success rates without costly consultant armies, and pre-train workflows as deterministic code.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
Large-Language-Models-play-StarCraftII
Large Language Models Play StarCraft II is a project that explores the capabilities of large language models (LLMs) in playing the game StarCraft II. The project introduces TextStarCraft II, a textual environment for the game, and a Chain of Summarization method for analyzing game information and making strategic decisions. Through experiments, the project demonstrates that LLM agents can defeat the built-in AI at a challenging difficulty level. The project provides benchmarks and a summarization approach to enhance strategic planning and interpretability in StarCraft II gameplay.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.
AiOS
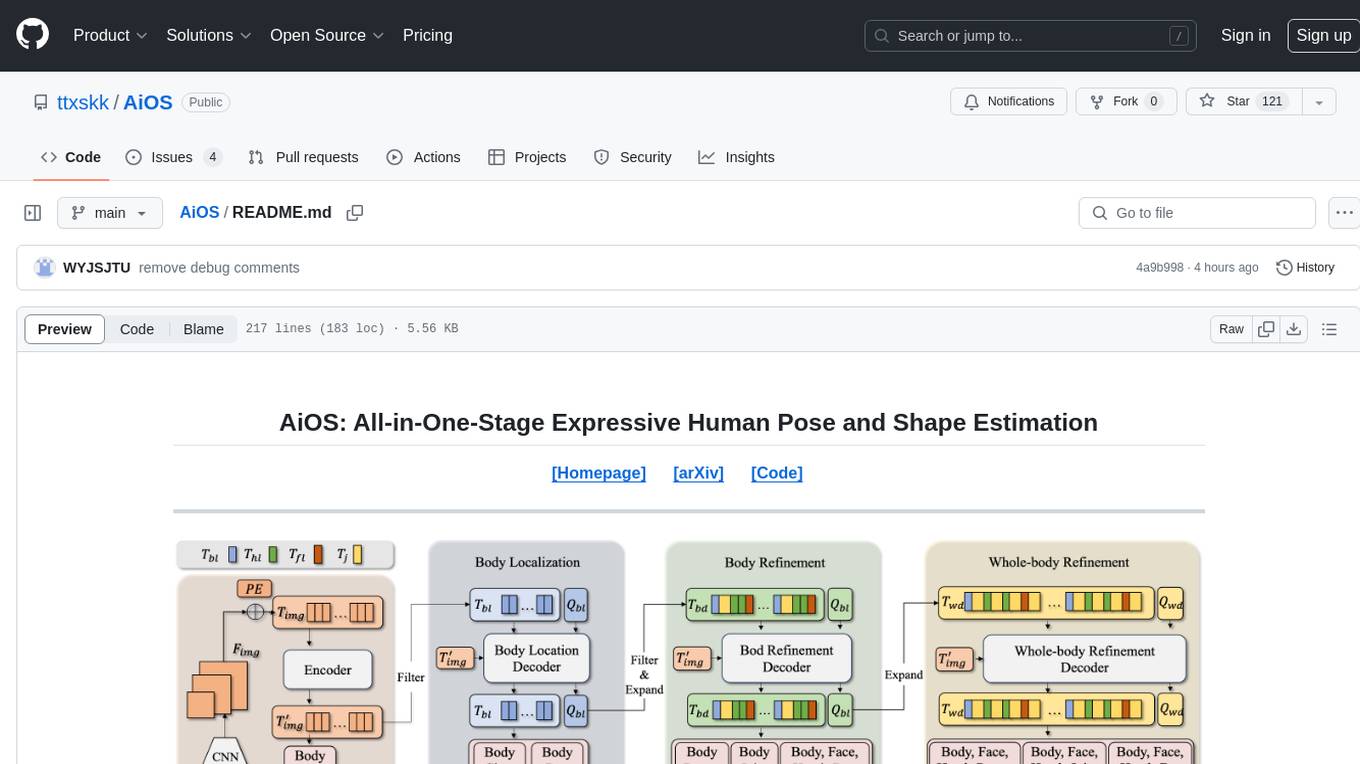
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
airswap-protocols
AirSwap Protocols is a repository containing smart contracts for developers and traders on the AirSwap peer-to-peer trading network. It includes various packages for functionalities like server registry, atomic token swap, staking, rewards pool, batch token and order calls, libraries, and utils. The repository follows a branching and release process for contracts and tools, with steps for regular development process and individual package features or patches. Users can deploy and verify contracts using specific commands with network flags.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.
portkey-python-sdk
The Portkey Python SDK is a control panel for AI apps that allows seamless integration of Portkey's advanced features with OpenAI methods. It provides features such as AI gateway for unified API signature, interoperability, automated fallbacks & retries, load balancing, semantic caching, virtual keys, request timeouts, observability with logging, requests tracing, custom metadata, feedback collection, and analytics. Users can make requests to OpenAI using Portkey SDK and also use async functionality. The SDK is compatible with OpenAI SDK methods and offers Portkey-specific methods like feedback and prompts. It supports various providers and encourages contributions through Github issues or direct contact via email or Discord.
For similar tasks
optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
Awesome-Model-Merging-Methods-Theories-Applications
A comprehensive repository focusing on 'Model Merging in LLMs, MLLMs, and Beyond', providing an exhaustive overview of model merging methods, theories, applications, and future research directions. The repository covers various advanced methods, applications in foundation models, different machine learning subfields, and tasks like pre-merging methods, architecture transformation, weight alignment, basic merging methods, and more.

llm-structured-output
This repository contains a library for constraining LLM generation to structured output, enforcing a JSON schema for precise data types and property names. It includes an acceptor/state machine framework, JSON acceptor, and JSON schema acceptor for guiding decoding in LLMs. The library provides reference implementations using Apple's MLX library and examples for function calling tasks. The tool aims to improve LLM output quality by ensuring adherence to a schema, reducing unnecessary output, and enhancing performance through pre-emptive decoding. Evaluations show performance benchmarks and comparisons with and without schema constraints.
HookPHP
HookPHP is an open-source project that provides a PHP extension for hooking into various aspects of PHP applications. It allows developers to easily extend and customize the behavior of their PHP applications by providing hooks at key points in the execution flow. With HookPHP, developers can efficiently add custom functionality, modify existing behavior, and enhance the overall performance of their PHP applications. The project is licensed under the MIT license, making it accessible for developers to use and contribute to.
ai-gateway
Envoy AI Gateway is an open source project that utilizes Envoy Gateway to manage request traffic from application clients to Generative AI services. The project aims to provide a seamless and efficient solution for handling communication between clients and AI services. It is designed to enhance the performance and scalability of AI applications by leveraging the capabilities of Envoy Gateway. The project welcomes contributions from the community and encourages collaboration to further develop and improve the functionality of the AI Gateway.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.
MoBA
MoBA (Mixture of Block Attention) is an innovative approach for long-context language models, enabling efficient processing of long sequences by dividing the full context into blocks and introducing a parameter-less gating mechanism. It allows seamless transitions between full and sparse attention modes, enhancing efficiency without compromising performance. MoBA has been deployed to support long-context requests and demonstrates significant advancements in efficient attention computation for large language models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.