
TinyLLM
Setup and run a local LLM and Chatbot using consumer grade hardware.
Stars: 288
TinyLLM is a project that helps build a small locally hosted language model with a web interface using consumer-grade hardware. It supports multiple language models, builds a local OpenAI API web service, and serves a Chatbot web interface with customizable prompts. The project requires specific hardware and software configurations for optimal performance. Users can run a local language model using inference servers like vLLM, llama-cpp-python, and Ollama. The Chatbot feature allows users to interact with the language model through a web-based interface, supporting features like summarizing websites, displaying news headlines, stock prices, weather conditions, and using vector databases for queries.
README:
TinyLLM? Yes, the name is a bit of a contradiction, but it means well. It's all about putting a large language model (LLM) on a tiny system that still delivers acceptable performance.
This project helps you build a small locally hosted LLM with a ChatGPT-like web interface using consumer grade hardware. To read more about my research with llama.cpp and LLMs, see research.md.
- Key Features
- Hardware Requirements
- Manual Setup
- Run a Local LLM
- Run a Chatbot
- LLM Models
- LLM Tools
- References
- Supports multiple LLMs (see list below)
- Builds a local OpenAI API web service via Ollama, llama.cpp or vLLM.
- Serves up a Chatbot web interface with customizable prompts, accessing external websites (URLs), vector databases and other sources (e.g. news, stocks, weather).
- CPU: Intel, AMD or Apple Silicon
- Memory: 8GB+ DDR4
- Disk: 128G+ SSD
- GPU: NVIDIA (e.g. GTX 1060 6GB, RTX 3090 24GB) or Apple M1/M2
- OS: Ubuntu Linux, MacOS
- Software: Python 3, CUDA Version: 12.2
TODO - Quick start setup script.
# Clone the project
git clone https://github.com/jasonacox/TinyLLM.git
cd TinyLLMTo run a local LLM, you will need an inference server for the model. This project recommends these options: vLLM, llama-cpp-python, and Ollama. All of these provide a built-in OpenAI API compatible web server that will make it easier for you to integrate with other tools.
The Ollama project has made it super easy to install and run LLMs on a variety of systems (MacOS, Linux, Windows) with limited hardware. It serves up an OpenAI compatible API as well. The underlying LLM engine is llama.cpp. Like llama.cpp, the downside with this server is that it can only handle one session/prompt at a time. To run the Ollama server container:
# Install and run Ollama server
docker run -d --gpus=all \
-v $PWD/ollama:/root/.ollama \
-p 11434:11434 \
-p 8000:11434 \
--restart unless-stopped \
--name ollama \
ollama/ollama
# Download and test run the llama3 model
docker exec -it ollama ollama run llama3
# Tell server to keep model loaded in GPU
curl http://localhost:11434/api/generate -d '{"model": "llama3", "keep_alive": -1}'Ollama support several models (LLMs): https://ollama.com/library If you set up the docker container mentioned above, you can down and run them using:
# Download and run Phi-3 Mini, open model by Microsoft.
docker exec -it ollama ollama run phi3
# Download and run mistral 7B model, by Mistral AI
docker exec -it ollama ollama run mistralIf you use the TinyLLM Chatbot (see below) with Ollama, make sure you specify the model via: LLM_MODEL="llama3" This will cause Ollama to download and run this model. It may take a while to start on first run unless you run one of the ollama run or curl commands above.
vLLM offers a robust OpenAI API compatible web server that supports multiple simultaneous inference threads (sessions). It automatically downloads the models you specify from HuggingFace and runs extremely well in containers. vLLM requires GPUs with more VRAM since it uses non-quantized models. AWQ models are also available and more optimizations are underway in the project to reduce the memory footprint. Note, for GPUs with a compute capability of 6 or less, Pascal architecture (see GPU table), follow details here instead.
# Build Container
cd vllm
./build.sh
# Make a Directory to store Models
mkdir models
# Edit run.sh or run-awq.sh to pull the model you want to use. Mistral is set by default.
# Run the Container - This will download the model on the first run
./run.sh
# The trailing logs will be displayed so you can see the progress. Use ^C to exit without
# stopping the container. The llama-cpp-python's OpenAI API compatible web server is easy to set up and use. It runs optimized GGUF models that work well on many consumer grade GPUs with small amounts of VRAM. As with Ollama, a downside with this server is that it can only handle one session/prompt at a time. The steps below outline how to setup and run the server via command line. Read the details in llmserver to see how to set it up as a persistent service or docker container on your Linux host.
# Uninstall any old version of llama-cpp-python
pip3 uninstall llama-cpp-python -y
# Linux Target with Nvidia CUDA support
CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python==0.2.27 --no-cache-dir
CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python[server]==0.2.27 --no-cache-dir
# MacOS Target with Apple Silicon M1/M2
CMAKE_ARGS="-DLLAMA_METAL=on" pip3 install -U llama-cpp-python --no-cache-dir
pip3 install 'llama-cpp-python[server]'
# Download Models from HuggingFace
cd llmserver/models
# Get the Mistral 7B GGUF Q-5bit model Q5_K_M and Meta LLaMA-2 7B GGUF Q-5bit model Q5_K_M
wget https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/resolve/main/mistral-7b-instruct-v0.1.Q5_K_M.gguf
wget https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF/resolve/main/llama-2-7b-chat.Q5_K_M.gguf
# Run Test - API Server
python3 -m llama_cpp.server \
--model ./models/mistral-7b-instruct-v0.1.Q5_K_M.gguf \
--host localhost \
--n_gpu_layers 99 \
--n_ctx 2048 \
--chat_format llama-2The TinyLLM Chatbot is a simple web based python FastAPI app that allows you to chat with an LLM using the OpenAI API. It supports multiple sessions and remembers your conversational history. Some RAG (Retrieval Augmented Generation) features including:
- Summarizing external websites and PDFs (paste a URL in chat window)
- List top 10 headlines from current news (use
/news) - Display company stock symbol and current stock price (use
/stock <company>) - Provide current weather conditions (use
/weather <location>) - Use a vector databases for RAG queries - see RAG page for details
# Move to chatbot folder
cd ../chatbot
touch prompts.json
# Pull and run latest container - see run.sh
docker run \
-d \
-p 5000:5000 \
-e PORT=5000 \
-e OPENAI_API_BASE="http://localhost:8000/v1" \
-e LLM_MODEL="tinyllm" \
-e USE_SYSTEM="false" \
-e SENTENCE_TRANSFORMERS_HOME=/app/.tinyllm \
-v $PWD/.tinyllm:/app/.tinyllm \
--name chatbot \
--restart unless-stopped \
jasonacox/chatbotOpen http://localhost:5000 - Example session:
If a URL is pasted in the text box, the chatbot will read and summarize it.
The /news command will fetch the latest news and have the LLM summarize the top ten headlines. It will store the raw feed in the context prompt to allow follow-up questions.
You can also test the chatbot server without docker using the following.
# Install required packages
pip3 install fastapi uvicorn python-socketio jinja2 openai bs4 pypdf requests lxml aiohttp
# Run the chatbot web server
python3 server.pyHere are some suggested models that work well with llmserver (llama-cpp-python). You can test other models and different quantization, but in my experiments, the Q5_K_M models performed the best. Below are the download links from HuggingFace as well as the model card's suggested context length size and chat prompt mode.
| LLM | Quantized | Link to Download | Context Length | Chat Prompt Mode |
|---|---|---|---|---|
| 7B Models | ||||
| Mistral v0.1 7B | 5-bit | mistral-7b-instruct-v0.1.Q5_K_M.gguf | 4096 | llama-2 |
| Llama-2 7B | 5-bit | llama-2-7b-chat.Q5_K_M.gguf | 2048 | llama-2 |
| Mistrallite 32K 7B | 5-bit | mistrallite.Q5_K_M.gguf | 16384 | mistrallite (can be glitchy) |
| 10B Models | ||||
| Nous-Hermes-2-SOLAR 10.7B | 5-bit | nous-hermes-2-solar-10.7b.Q5_K_M.gguf | 4096 | chatml |
| 13B Models | ||||
| Claude2 trained Alpaca 13B | 5-bit | claude2-alpaca-13b.Q5_K_M.gguf | 2048 | chatml |
| Llama-2 13B | 5-bit | llama-2-13b-chat.Q5_K_M.gguf | 2048 | llama-2 |
| Vicuna 13B v1.5 | 5-bit | vicuna-13b-v1.5.Q5_K_M.gguf | 2048 | vicuna |
| Mixture-of-Experts (MoE) Models | ||||
| Hai's Mixtral 11Bx2 MoE 19B | 5-bit | mixtral_11bx2_moe_19b.Q5_K_M.gguf | 4096 | chatml |
| Mixtral-8x7B v0.1 | 3-bit | Mixtral-8x7B-Instruct-v0.1-GGUF | 4096 | llama-2 |
| Mixtral-8x7B v0.1 | 4-bit | Mixtral-8x7B-Instruct-v0.1-GGUF | 4096 | llama-2 |
Here are some suggested models that work well with vLLM.
| LLM | Quantized | Link to Download | Context Length | License |
|---|---|---|---|---|
| Mistral v0.1 7B | None | mistralai/Mistral-7B-Instruct-v0.1 | 32k | Apache 2 |
| Mistral v0.2 7B | None | mistralai/Mistral-7B-Instruct-v0.2 | 32k | Apache 2 |
| Mistral v0.1 7B AWQ | AWQ | TheBloke/Mistral-7B-Instruct-v0.1-AWQ | 32k | Apache 2 |
| Mixtral-8x7B | None | mistralai/Mixtral-8x7B-Instruct-v0.1 | 32k | Apache 2 |
| Pixtral-12B-2409 12B Vision | None | mistralai/Pixtral-12B-2409 | 128k | Apache 2 |
| Meta Llama-3 8B | None | meta-llama/Meta-Llama-3-8B-Instruct | 8k | Meta |
| Meta Llama-3.2 11B Vision | FP8 | neuralmagic/Llama-3.2-11B-Vision-Instruct-FP8-dynamic | 128k | Meta |
| Qwen-2.5 7B | None | Qwen/Qwen2.5-7B-Instruct | 128k | Apache 2 |
| Yi-1.5 9B | None | 01-ai/Yi-1.5-9B-Chat-16K | 16k | Apache 2 |
| Phi-3 Small 7B | None | microsoft/Phi-3-small-8k-instruct | 16k | MIT |
| Phi-3 Medium 14B | None | microsoft/Phi-3-medium-4k-instruct | 4k | MIT |
| Phi-3.5 Vision 4B | None | microsoft/Phi-3.5-vision-instruct | 128k | MIT |
| Phi-4 14B | None | microsoft/phi-4 | 16k | MIT |
A CLI utility (llm) and Python library for interacting with Large Language Models. To configure this tool to use your local LLM's OpenAI API:
# Install llm command line tool
pipx install llm
# Location to store configuration files:
dirname "$(llm logs path)"You define the model in the extra-openai-models.yaml file. Create this file in the directory discovered above. Edit the model_name and api_base to match your LLM OpenAI API setup:
- model_id: tinyllm
model_name: meta-llama/Meta-Llama-3.1-8B-Instruct
api_base: "http://localhost:8000/v1"# Configure llm to use your local model
llm models default tinyllm
# Test
llm "What is love?"- LLaMa.cpp - https://github.com/ggerganov/llama.cpp
- LLaMa-cpp-python - https://github.com/abetlen/llama-cpp-python
- vLLM - https://github.com/vllm-project/vllm
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TinyLLM
Similar Open Source Tools
TinyLLM
TinyLLM is a project that helps build a small locally hosted language model with a web interface using consumer-grade hardware. It supports multiple language models, builds a local OpenAI API web service, and serves a Chatbot web interface with customizable prompts. The project requires specific hardware and software configurations for optimal performance. Users can run a local language model using inference servers like vLLM, llama-cpp-python, and Ollama. The Chatbot feature allows users to interact with the language model through a web-based interface, supporting features like summarizing websites, displaying news headlines, stock prices, weather conditions, and using vector databases for queries.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

vscode-unify-chat-provider
The 'vscode-unify-chat-provider' repository is a tool that integrates multiple LLM API providers into VS Code's GitHub Copilot Chat using the Language Model API. It offers free tier access to mainstream models, perfect compatibility with major LLM API formats, deep adaptation to API features, best performance with built-in parameters, out-of-the-box configuration, import/export support, great UX, and one-click use of various models. The tool simplifies model setup, migration, and configuration for users, providing a seamless experience within VS Code for utilizing different language models.
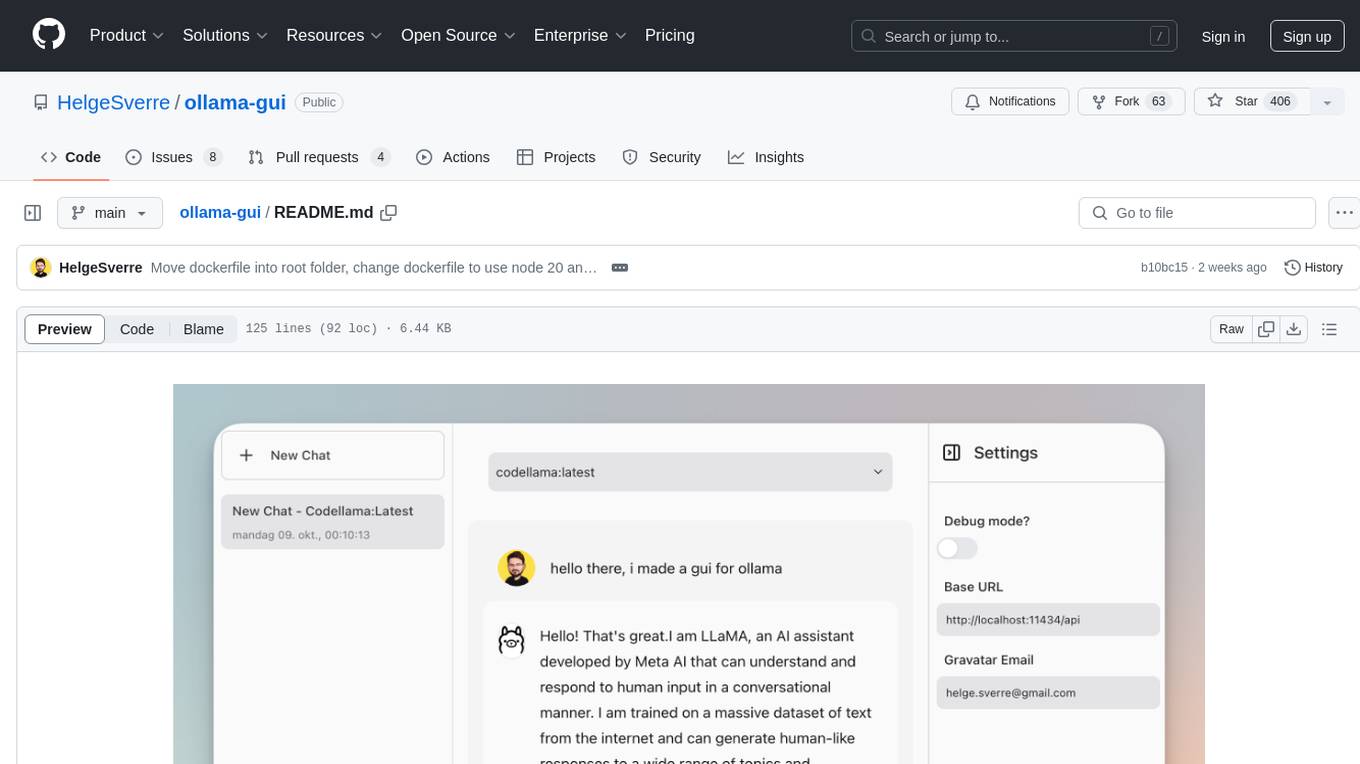
ollama-gui
Ollama GUI is a web interface for ollama.ai, a tool that enables running Large Language Models (LLMs) on your local machine. It provides a user-friendly platform for chatting with LLMs and accessing various models for text generation. Users can easily interact with different models, manage chat history, and explore available models through the web interface. The tool is built with Vue.js, Vite, and Tailwind CSS, offering a modern and responsive design for seamless user experience.
manim-generator
The 'manim-generator' repository focuses on automatic video generation using an agentic LLM flow combined with the manim python library. It experiments with automated Manim video creation by delegating code drafting and validation to specific roles, reducing render failures, and improving visual consistency through iterative feedback and vision inputs. The project also includes 'Manim Bench' for comparing AI models on full Manim video generation.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.
SimpleAICV_pytorch_training_examples
SimpleAICV_pytorch_training_examples is a repository that provides simple training and testing examples for various computer vision tasks such as image classification, object detection, semantic segmentation, instance segmentation, knowledge distillation, contrastive learning, masked image modeling, OCR text detection, OCR text recognition, human matting, salient object detection, interactive segmentation, image inpainting, and diffusion model tasks. The repository includes support for multiple datasets and networks, along with instructions on how to prepare datasets, train and test models, and use gradio demos. It also offers pretrained models and experiment records for download from huggingface or Baidu-Netdisk. The repository requires specific environments and package installations to run effectively.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.
llama-gpt
LlamaGPT is a self-hosted, offline, ChatGPT-like chatbot, powered by Llama 2. It is 100% private, with no data leaving your device. It supports various models, including Nous Hermes Llama 2 7B/13B/70B Chat and Code Llama 7B/13B/34B Chat. You can install LlamaGPT on your umbrelOS home server, M1/M2 Mac, or anywhere else with Docker. It also provides an OpenAI-compatible API for easy integration. LlamaGPT is still under development, with plans to add more features such as custom model loading and model switching.
llm-graph-builder
Knowledge Graph Builder App is a tool designed to convert PDF documents into a structured knowledge graph stored in Neo4j. It utilizes OpenAI's GPT/Diffbot LLM to extract nodes, relationships, and properties from PDF text content. Users can upload files from local machine or S3 bucket, choose LLM model, and create a knowledge graph. The app integrates with Neo4j for easy visualization and querying of extracted information.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.
star-vector
StarVector is a multimodal vision-language model for Scalable Vector Graphics (SVG) generation. It can be used to perform image2SVG and text2SVG generation. StarVector works directly in the SVG code space, leveraging visual understanding to apply accurate SVG primitives. It achieves state-of-the-art performance in producing compact and semantically rich SVGs. The tool provides Hugging Face model checkpoints for image2SVG vectorization, with models like StarVector-8B and StarVector-1B. It also offers datasets like SVG-Stack, SVG-Fonts, SVG-Icons, SVG-Emoji, and SVG-Diagrams for evaluation. StarVector can be trained using Deepspeed or FSDP for tasks like Image2SVG and Text2SVG generation. The tool provides a demo with options for HuggingFace generation or VLLM backend for faster generation speed.
Online-RLHF
This repository, Online RLHF, focuses on aligning large language models (LLMs) through online iterative Reinforcement Learning from Human Feedback (RLHF). It aims to bridge the gap in existing open-source RLHF projects by providing a detailed recipe for online iterative RLHF. The workflow presented here has shown to outperform offline counterparts in recent LLM literature, achieving comparable or better results than LLaMA3-8B-instruct using only open-source data. The repository includes model releases for SFT, Reward model, and RLHF model, along with installation instructions for both inference and training environments. Users can follow step-by-step guidance for supervised fine-tuning, reward modeling, data generation, data annotation, and training, ultimately enabling iterative training to run automatically.
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
For similar tasks
TinyLLM
TinyLLM is a project that helps build a small locally hosted language model with a web interface using consumer-grade hardware. It supports multiple language models, builds a local OpenAI API web service, and serves a Chatbot web interface with customizable prompts. The project requires specific hardware and software configurations for optimal performance. Users can run a local language model using inference servers like vLLM, llama-cpp-python, and Ollama. The Chatbot feature allows users to interact with the language model through a web-based interface, supporting features like summarizing websites, displaying news headlines, stock prices, weather conditions, and using vector databases for queries.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.

LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.
ReEdgeGPT
ReEdgeGPT is a tool designed for reverse engineering the chat feature of the new version of Bing. It provides documentation and guidance on how to collect and use cookies to access the chat feature. The tool allows users to create a chatbot using the collected cookies and interact with the Bing GPT chatbot. It also offers support for different modes like Copilot and Bing, along with plugins for various tasks. The tool covers historical information about Rome, the Lazio region, and provides troubleshooting tips for common issues encountered while using the tool.
gemini_multipdf_chat
Gemini PDF Chatbot is a Streamlit-based application that allows users to chat with a conversational AI model trained on PDF documents. The chatbot extracts information from uploaded PDF files and answers user questions based on the provided context. It features PDF upload, text extraction, conversational AI using the Gemini model, and a chat interface. Users can deploy the application locally or to the cloud, and the project structure includes main application script, environment variable file, requirements, and documentation. Dependencies include PyPDF2, langchain, Streamlit, google.generativeai, and dotenv.
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.
AI-Playground
AI Playground is an open-source project and AI PC starter app designed for AI image creation, image stylizing, and chatbot functionalities on a PC powered by an Intel Arc GPU. It leverages libraries from GitHub and Huggingface, providing users with the ability to create AI-generated content and interact with chatbots. The tool requires specific hardware specifications and offers packaged installers for ease of setup. Users can also develop the project environment, link it to the development environment, and utilize alternative models for different AI tasks.
Virtual_Avatar_ChatBot
Virtual_Avatar_ChatBot is a free AI Chatbot with visual movement that runs on your local computer with minimal GPU requirement. It supports various features like Oogbabooga, betacharacter.ai, and Locall LLM. The tool requires Windows 7 or above, Python, C++ Compiler, Git, and other dependencies. Users can contribute to the open-source project by reporting bugs, creating pull requests, or suggesting new features. The goal is to enhance Voicevox functionality, support local LLM inference, and give the waifu access to the internet. The project references various tools like desktop-waifu, CharacterAI, Whisper, PYVTS, COQUI-AI, VOICEVOX, and VOICEVOX API.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.