
LLM_AppDev-HandsOn
Repository and hands-on workshop on how to develop applications with local LLMs
Stars: 383
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.
README:

2024-07-03: Streamlit app changes: The chatbot app code now uses Ollama embeddings and has a configurable system prompt.
This repository demonstrates how to build a simple LLM-based chatbot that can answer questions based on your documents (retrieval augmented generation - RAG) and how to deploy it using Podman or on the OpenShift Container Platform (k8s).
The corresponding workshop - first run at Red Hat Developers Hands-On Day 2023 in Darmstadt, Germany - teaches participants the basic concepts of LLMs & RAG, and how to adapt this example implementation to their own specific purpose GPT.
The software stack only uses open source tools streamlit, LlamaIndex and local open LLMs via Ollama. Real open AI for the GPU poor.
Everyone is invited to fork this repository, create their own specific purpose chatbot based on their documents, improve the setup or even hold your own workshop.
For the local setup a Mac M1 with 16GB unified memory and above are recommended. First download Ollama from ollama.ai and install it.
On Linux you can disable the Ollama service for better debugging:
sudo systemctl disable ollama
sudo systemctl stop ollama
and then manually run ollama serve.
For the local example have a look at the folder streamlit and install the requirements.
Create a virtual environment first:
python -m venv venv
source venv/bin/activate
Install the requirements:
pip install -r requirements.txt
Then start streamlit with:
streamlit run app.py
Modify the system prompt and copy different data sources to docs/ in order to create your own version of the chatbot.
You can set the ollama host via the enviroment variable OLLAMA_HOST.
You can download models locally with ollama pull zephyr or via API:
curl -X POST http://ollama:11434/api/pull -d '{"name": "zephyr"}'
First start the ollama service as described and download the Zephyr model. To test the ollama server you can call the generate API:
curl -X POST http://ollama:11434/api/generate -d '{"model": "zephyr", "prompt": "Why is the sky blue?"}'
All of these commands are also documented in our cheat sheet.

Build the container based on UBI9 Python 3.11:
podman build -t linuxbot-app .
If you're building on arm64 Mac and deploy on amd64 then generally don't forget to add --platform (in this case our base image is amd64 anyways):
podman build --platform="linux/amd64" -t linuxbot-app .
We will create a network for our linuxbot and ollama:
podman network create linuxbot
Check if DNS is enabled (it's not on the default net):
podman network inspect linuxbot
Now you can either start Ollama locally with ollama serve or start a Ollama container with
podman run --net linuxbot --name ollama -p 11434:11434 --rm docker.io/ollama/ollama:latest
Note: We just forward the port so we can curl it more easily locally as well.
Click to unfold the details for
GPU support
This ollama service won't have GPU support enabled and much slower compared to running it locally on a Mac M1 for example. In order to run this container with NVIDIA GPU support we recommend to use the NVIDIA Container Toolkit with Container Device Interface (CDI). Follow the instructions from NVIDIA then run podman with:
podman run --rm --net linuxbot --name ollama --device nvidia.com/gpu=all --security-opt=label=disable ollama
In order to test if your graphics card is recognized you can test it using a base image that contains nvidia-smi, e.g:
podman run --rm --device nvidia.com/gpu=all --security-opt=label=disable ubuntu nvidia-smi -L
For AMD graphic cards you need to forward the Kernel Fusion Driver (KFD) and Direct Rendering Infrastructure (DRI) to the container:
podman run -it --device=/dev/kfd --device=/dev/dri --security-opt=label=disable docker.io/ollama/ollama
Since we create the embeddings locally in the streamlit app we need to increase shared memory for Pytorch in order to get it running:
podman run --net linuxbot --name linuxbot-app -p 8080:8080 --shm-size=2gb -e OLLAMA_HOST=ollama -it --rm localhost/linuxbot-app
You can set the Ollama server via the environment variable OLLAMA_HOST, the default is localhost.
NOTE: It would be much better to generate the embeddings with the ollama service, this is not yet supported in LlamaIndex though.
Create a new project (namespace) for your workshop and deploy the ollama service in it:
oc new-project my-workshop
oc apply -f deployments/ollama.yaml
If you want to enable GPU support you have to have to install and instantiate the NVIDIA GPU Operator and Node Feature Discovery (NFD) Operator as described on the AI on OpenShift page, then deploy ollama-gpu.yaml instead.
oc apply -f deployments/ollama-gpu.yaml
The streamlit application (linuxbot) can deployed as:
oc apply -f deployments/linuxbot.yaml
We have published a preconfigured container image on quay.io/sroecker that is used in this deployment.
In order to debug your application and ollama service you can deploy a curl image like this:
oc run mycurl --image=curlimages/curl -it -- sh
oc attach mycurl -c mycurl -i -t
oc delete pod mycurl
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM_AppDev-HandsOn
Similar Open Source Tools
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.
ChatGPT-OpenAI-Smart-Speaker
ChatGPT Smart Speaker is a project that enables speech recognition and text-to-speech functionalities using OpenAI and Google Speech Recognition. It provides scripts for running on PC/Mac and Raspberry Pi, allowing users to interact with a smart speaker setup. The project includes detailed instructions for setting up the required hardware and software dependencies, along with customization options for the OpenAI model engine, language settings, and response randomness control. The Raspberry Pi setup involves utilizing the ReSpeaker hardware for voice feedback and light shows. The project aims to offer an advanced smart speaker experience with features like wake word detection and response generation using AI models.
redbox
Redbox is a retrieval augmented generation (RAG) app that uses GenAI to chat with and summarise civil service documents. It increases organisational memory by indexing documents and can summarise reports read months ago, supplement them with current work, and produce a first draft that lets civil servants focus on what they do best. The project uses a microservice architecture with each microservice running in its own container defined by a Dockerfile. Dependencies are managed using Python Poetry. Contributions are welcome, and the project is licensed under the MIT License. Security measures are in place to ensure user data privacy and considerations are being made to make the core-api secure.
aws-ai-stack
AWS AI Stack is a full-stack boilerplate project designed for building serverless AI applications on AWS. It provides a trusted AWS foundation for AI apps with access to powerful LLM models via Bedrock. The architecture is serverless, ensuring cost-efficiency by only paying for usage. The project includes features like AI Chat & Streaming Responses, Multiple AI Models & Data Privacy, Custom Domain Names, API & Event-Driven architecture, Built-In Authentication, Multi-Environment support, and CI/CD with Github Actions. Users can easily create AI Chat bots, authentication services, business logic, and async workers using AWS Lambda, API Gateway, DynamoDB, and EventBridge.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.
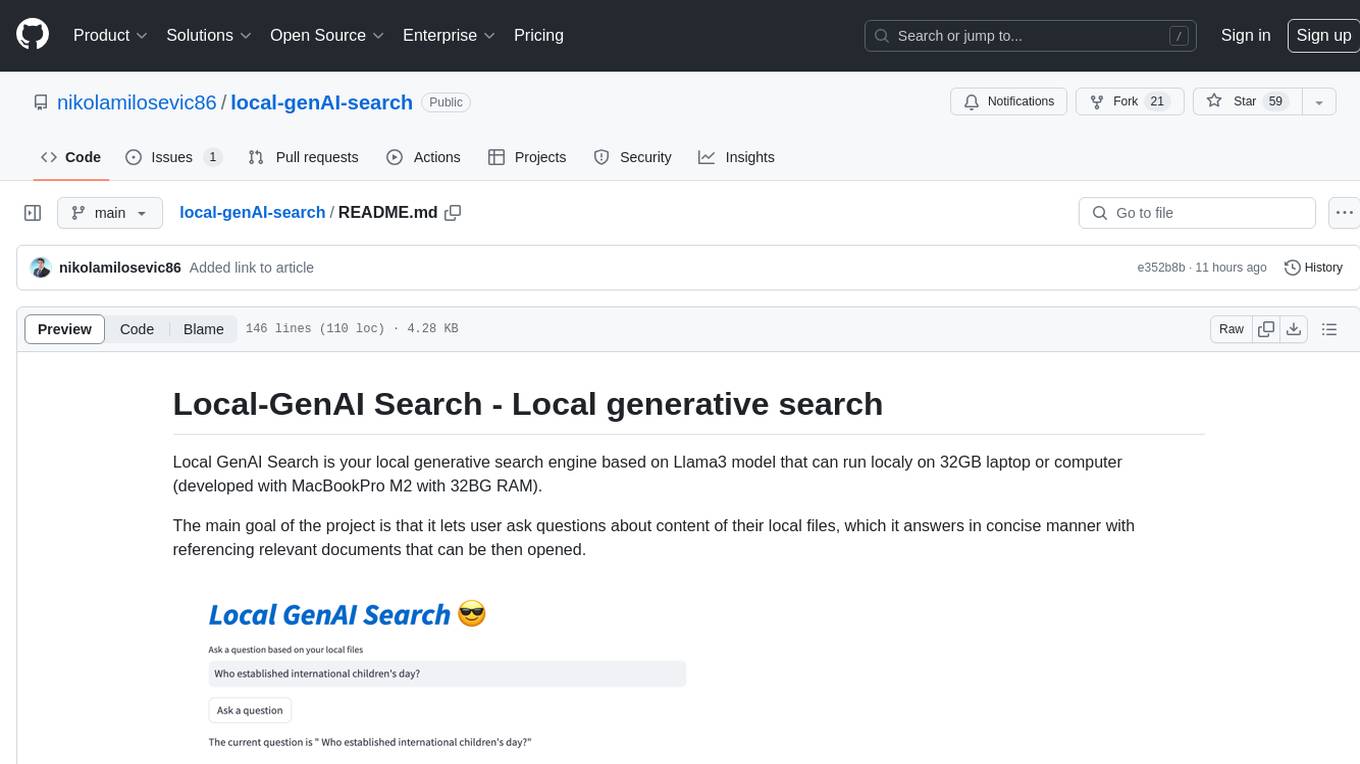
local-genAI-search
Local-GenAI Search is a local generative search engine powered by the Llama3 model, allowing users to ask questions about their local files and receive concise answers with relevant document references. It utilizes MS MARCO embeddings for semantic search and can run locally on a 32GB laptop or computer. The tool can be used to index local documents, search for information, and provide generative search services through a user interface.
leptonai
A Pythonic framework to simplify AI service building. The LeptonAI Python library allows you to build an AI service from Python code with ease. Key features include a Pythonic abstraction Photon, simple abstractions to launch models like those on HuggingFace, prebuilt examples for common models, AI tailored batteries, a client to automatically call your service like native Python functions, and Pythonic configuration specs to be readily shipped in a cloud environment.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
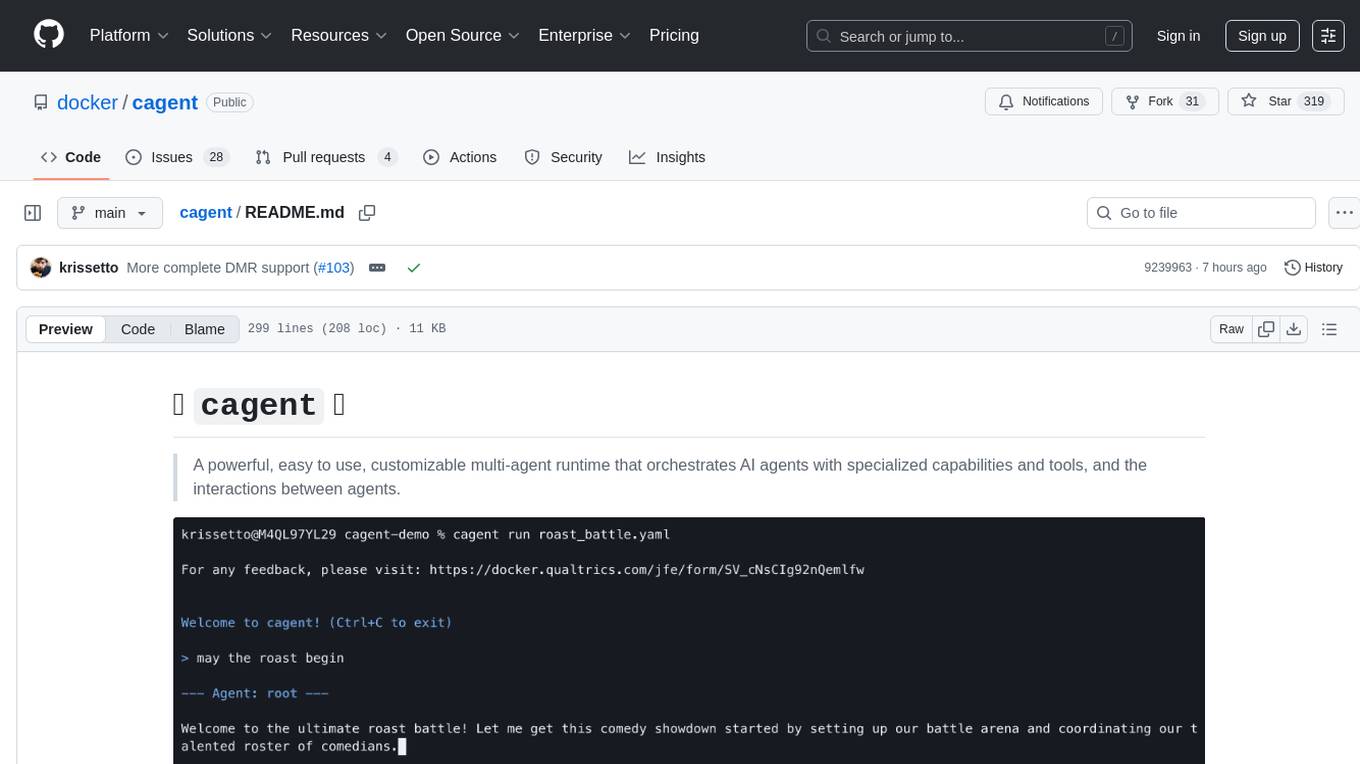
cagent
cagent is a powerful and easy-to-use multi-agent runtime that orchestrates AI agents with specialized capabilities and tools, allowing users to quickly build, share, and run a team of virtual experts to solve complex problems. It supports creating agents with YAML configuration, improving agents with MCP servers, and delegating tasks to specialists. Key features include multi-agent architecture, rich tool ecosystem, smart delegation, YAML configuration, advanced reasoning tools, and support for multiple AI providers like OpenAI, Anthropic, Gemini, and Docker Model Runner.
seer
Seer is a service that provides AI capabilities to Sentry by running inference on Sentry issues and providing user insights. It is currently in early development and not yet compatible with self-hosted Sentry instances. The tool requires access to internal Sentry resources and is intended for internal Sentry employees. Users can set up the environment, download model artifacts, integrate with local Sentry, run evaluations for Autofix AI agent, and deploy to a sandbox staging environment. Development commands include applying database migrations, creating new migrations, running tests, and more. The tool also supports VCRs for recording and replaying HTTP requests.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.
For similar tasks
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.

nlux
nlux is an open-source Javascript and React JS library that makes it super simple to integrate powerful large language models (LLMs) like ChatGPT into your web app or website. With just a few lines of code, you can add conversational AI capabilities and interact with your favourite LLM.
generative-ai-go
The Google AI Go SDK enables developers to use Google's state-of-the-art generative AI models (like Gemini) to build AI-powered features and applications. It supports use cases like generating text from text-only input, generating text from text-and-images input (multimodal), building multi-turn conversations (chat), and embedding.
awesome-langchain-zh
The awesome-langchain-zh repository is a collection of resources related to LangChain, a framework for building AI applications using large language models (LLMs). The repository includes sections on the LangChain framework itself, other language ports of LangChain, tools for low-code development, services, agents, templates, platforms, open-source projects related to knowledge management and chatbots, as well as learning resources such as notebooks, videos, and articles. It also covers other LLM frameworks and provides additional resources for exploring and working with LLMs. The repository serves as a comprehensive guide for developers and AI enthusiasts interested in leveraging LangChain and LLMs for various applications.

Large-Language-Model-Notebooks-Course
This practical free hands-on course focuses on Large Language models and their applications, providing a hands-on experience using models from OpenAI and the Hugging Face library. The course is divided into three major sections: Techniques and Libraries, Projects, and Enterprise Solutions. It covers topics such as Chatbots, Code Generation, Vector databases, LangChain, Fine Tuning, PEFT Fine Tuning, Soft Prompt tuning, LoRA, QLoRA, Evaluate Models, Knowledge Distillation, and more. Each section contains chapters with lessons supported by notebooks and articles. The course aims to help users build projects and explore enterprise solutions using Large Language Models.
ai-chatbot
Next.js AI Chatbot is an open-source app template for building AI chatbots using Next.js, Vercel AI SDK, OpenAI, and Vercel KV. It includes features like Next.js App Router, React Server Components, Vercel AI SDK for streaming chat UI, support for various AI models, Tailwind CSS styling, Radix UI for headless components, chat history management, rate limiting, session storage with Vercel KV, and authentication with NextAuth.js. The template allows easy deployment to Vercel and customization of AI model providers.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.
Awesome-AI-Data-Guided-Projects
A curated list of data science & AI guided projects to start building your portfolio. The repository contains guided projects covering various topics such as large language models, time series analysis, computer vision, natural language processing (NLP), and data science. Each project provides detailed instructions on how to implement specific tasks using different tools and technologies.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.