
LLMinator
Gradio based tool to run opensource LLM models directly from Huggingface
Stars: 53

LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.
README:
An easy-to-use tool made with Gradio, LangChain, and Torch.
- Context-aware Streaming Chatbot.
- Inbuilt code syntax highlighting.
- Load any LLM repo directly from HuggingFace.
- Supports both CPU & CUDA modes.
- Enable LLM inference with llama.cpp using llama-cpp-python
- Convert models(Safetensors, pt to gguf etc)
To use LLMinator, follow these simple steps:
```
git clone https://github.com/Aesthisia/LLMinator.git
cd LLMinator
pip install -r requirements.txt
```
Build LLMinator with llama.cpp:
-
Using
make:-
On Linux or MacOS:
make
-
On Windows:
- Download the latest fortran version of w64devkit.
- Extract
w64devkiton your pc. - Run
w64devkit.exe. - Use the
cdcommand to reach theLLMinatorfolder. - From here you can run:
make
-
-
Using
CMake:mkdir build cd build cmake ..
- Run the LLMinator tool using the command
python webui.py. - Access the web interface by opening the http://127.0.0.1:7860 in your browser.
- Start interacting with the chatbot and experimenting with LLMs!
| Argument Command | Default | Description |
|---|---|---|
| --host | 127.0.0.1 | Host or IP address on which the server will listen for incoming connections |
| --port | 7860 | Launch gradio with given server port |
| --share | False | This generates a public shareable link that you can send to anybody |
-
Compatible Versions: This project is compatible with Python versions 3.8+ to 3.11. Ensure you have one of these versions installed on your system. You can check your Python version by running
python --versionorpython3 --versionin your terminal.
- Cmake Dependency: If you plan to build the project using Cmake, make sure you have Cmake installed.
-
C Compiler: Additionally, you'll need a C compiler such as GCC. These are typically included with most Linux distributions. You can check this by running
gcc --versionin your terminal. Installation instructions for your specific operating system can be found online.
- Visual Studio Installer: If you're using Visual Studio Code for development, you'll need the C++ development workload installed. You can achieve this through the Visual Studio Installer
- CUDA Installation: To leverage GPU acceleration, you'll need CUDA installed on your system. Download instructions are available on the NVIDIA website.
-
Torch Compatibility: After installing CUDA, confirm CUDA availability with
torch.cuda.is_available(). When using a GPU, ensure you follow the project's specificllama-cpp-pythoninstallation configuration for CUDA support.
If you encounter any errors or issues, feel free to file a detailed report in the project's repository. We're always happy to help! When reporting an issue, please provide as much information as possible, including the error message, logs, the steps you took, and your system configuration. This makes it easier for us to diagnose and fix the problem quickly.
We welcome contributions from the community to enhance LLMinator further. If you'd like to contribute, please follow these guidelines:
- Fork the LLMinator repository on GitHub.
- Create a new branch for your feature or bug fix.
- Test your changes thoroughly.
- Submit a pull request, providing a clear description of the changes you've made.
Reach out to us: [email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLMinator
Similar Open Source Tools
LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.
xlang
XLang™ is a cutting-edge language designed for AI and IoT applications, offering exceptional dynamic and high-performance capabilities. It excels in distributed computing and seamless integration with popular languages like C++, Python, and JavaScript. Notably efficient, running 3 to 5 times faster than Python in AI and deep learning contexts. Features optimized tensor computing architecture for constructing neural networks through tensor expressions. Automates tensor data flow graph generation and compilation for specific targets, enhancing GPU performance by 6 to 10 times in CUDA environments.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.
mdserve
Markdown preview server for AI coding agents. mdserve is a tool that allows AI agents to write markdown and see it rendered live in the browser. It features zero configuration, single binary installation, instant live reload via WebSocket, ephemeral sessions, and agent-friendly content support. It is not a documentation site generator, static site server, or general-purpose markdown authoring tool. mdserve is designed for AI coding agents to produce content like tables, diagrams, and code blocks.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
browser
Lightpanda Browser is an open-source headless browser designed for fast web automation, AI agents, LLM training, scraping, and testing. It features ultra-low memory footprint, exceptionally fast execution, and compatibility with Playwright and Puppeteer through CDP. Built for performance, Lightpanda offers Javascript execution, support for Web APIs, and is optimized for minimal memory usage. It is a modern solution for web scraping and automation tasks, providing a lightweight alternative to traditional browsers like Chrome.
ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image, video, audio, and 3D processing, along with features like smart memory management, model loading, embeddings/textual inversion, and offline usage. Users can experiment with different models, create complex workflows, and optimize their processes efficiently.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
vim-ollama
The 'vim-ollama' plugin for Vim adds Copilot-like code completion support using Ollama as a backend, enabling intelligent AI-based code completion and integrated chat support for code reviews. It does not rely on cloud services, preserving user privacy. The plugin communicates with Ollama via Python scripts for code completion and interactive chat, supporting Vim only. Users can configure LLM models for code completion tasks and interactive conversations, with detailed installation and usage instructions provided in the README.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.

mattermost-plugin-agents
The Mattermost Agents Plugin integrates AI capabilities directly into your Mattermost workspace, allowing users to run local LLMs on their infrastructure or connect to cloud providers. It offers multiple AI assistants with specialized personalities, thread and channel summarization, action item extraction, meeting transcription, semantic search, smart reactions, direct conversations with AI assistants, and flexible LLM support. The plugin comes with comprehensive documentation, installation instructions, system requirements, and development guidelines for users to interact with AI features and configure LLM providers.
ChatGPT
The ChatGPT API Free Reverse Proxy provides free self-hosted API access to ChatGPT (`gpt-3.5-turbo`) with OpenAI's familiar structure, eliminating the need for code changes. It offers streaming response, API endpoint compatibility, and complimentary access without an API key. Installation options include Docker, PC/Server, and Termux on Android devices. The API can be accessed through a self-hosted local server or a pre-hosted API with an API key obtained from the Discord server. Usage examples are provided for Python and Node.js, and the project is licensed under AGPL-3.0.
mint-bench
MINT benchmark aims to evaluate LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback.
For similar tasks
Ollama-Colab-Integration
Ollama Colab Integration V4 is a tool designed to enhance the interaction and management of large language models. It allows users to quantize models within their notebook environment, access a variety of models through a user-friendly interface, and manage public endpoints efficiently. The tool also provides features like LiteLLM proxy control, model insights, and customizable model file templating. Users can troubleshoot model loading issues, CPU fallback strategies, and manage VRAM and RAM effectively. Additionally, the tool offers functionalities for downloading model files from Hugging Face, model conversion with high precision, model quantization using Q and Kquants, and securely uploading converted models to Hugging Face.
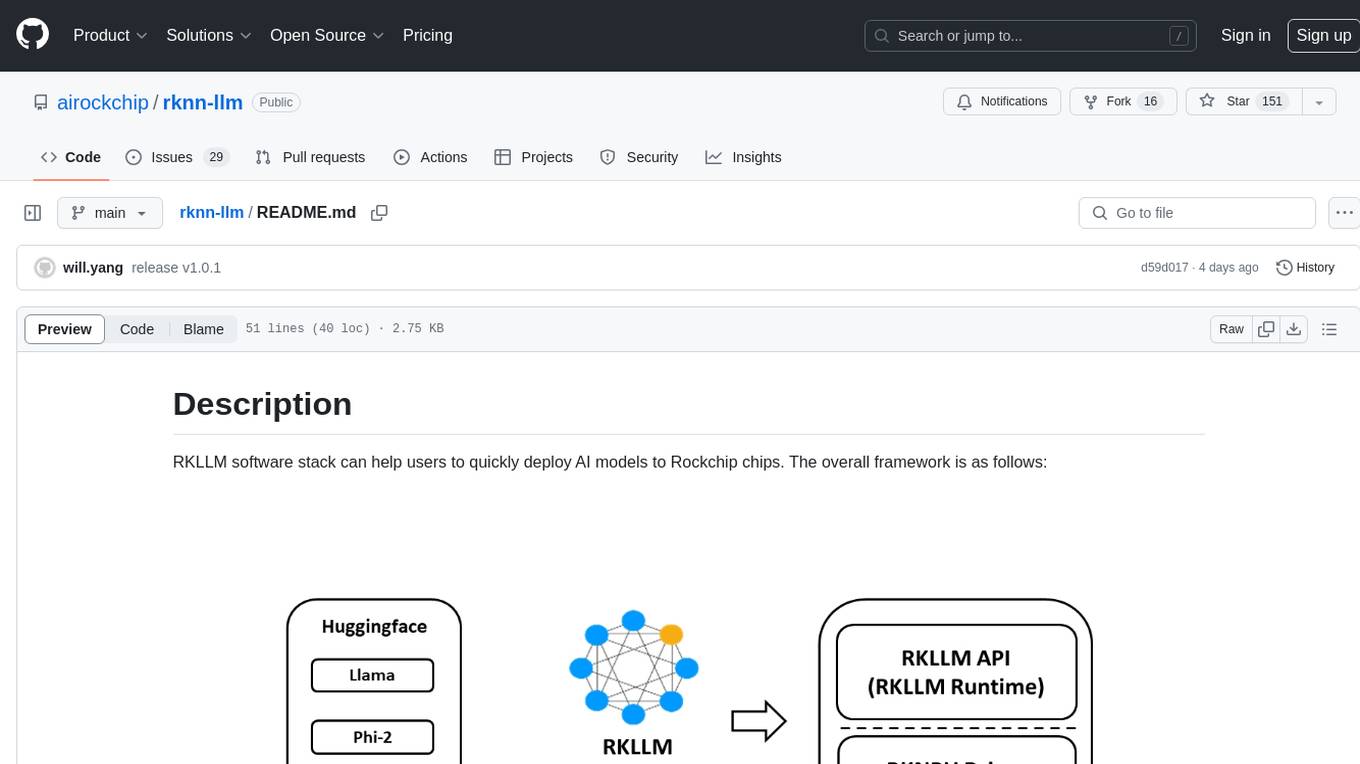
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.
LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
lm.rs
lm.rs is a tool that allows users to run inference on Language Models locally on the CPU using Rust. It supports LLama3.2 1B and 3B models, with a WebUI also available. The tool provides benchmarks and download links for models and tokenizers, with recommendations for quantization options. Users can convert models from Google/Meta on huggingface using provided scripts. The tool can be compiled with cargo and run with various arguments for model weights, tokenizer, temperature, and more. Additionally, a backend for the WebUI can be compiled and run to connect via the web interface.
LiteRT
LiteRT is Google's open-source high-performance runtime for on-device AI, previously known as TensorFlow Lite. The repository is currently not intended for open-source development, but aims to evolve to allow direct building and contributions. LiteRT supports Python versions 3.9, 3.10, 3.11 on Linux and MacOS. It ensures compatibility with existing .tflite file extension and format, offering conversion tools and continued active development under the name LiteRT.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.