
llama-gpt
A self-hosted, offline, ChatGPT-like chatbot. Powered by Llama 2. 100% private, with no data leaving your device. New: Code Llama support!
Stars: 10296
LlamaGPT is a self-hosted, offline, ChatGPT-like chatbot, powered by Llama 2. It is 100% private, with no data leaving your device. It supports various models, including Nous Hermes Llama 2 7B/13B/70B Chat and Code Llama 7B/13B/34B Chat. You can install LlamaGPT on your umbrelOS home server, M1/M2 Mac, or anywhere else with Docker. It also provides an OpenAI-compatible API for easy integration. LlamaGPT is still under development, with plans to add more features such as custom model loading and model switching.
README:

A self-hosted, offline, ChatGPT-like chatbot, powered by Llama 2. 100% private, with no data leaving your device.
New: Support for Code Llama models and Nvidia GPUs.
umbrel.com (we're hiring) »



- Demo
- Supported Models
- How to install
- OpenAI-compatible API
- Benchmarks
- Roadmap and contributing
- Acknowledgements
https://github.com/getumbrel/llama-gpt/assets/10330103/5d1a76b8-ed03-4a51-90bd-12ebfaf1e6cd
Currently, LlamaGPT supports the following models. Support for running custom models is on the roadmap.
| Model name | Model size | Model download size | Memory required |
|---|---|---|---|
| Nous Hermes Llama 2 7B Chat (GGML q4_0) | 7B | 3.79GB | 6.29GB |
| Nous Hermes Llama 2 13B Chat (GGML q4_0) | 13B | 7.32GB | 9.82GB |
| Nous Hermes Llama 2 70B Chat (GGML q4_0) | 70B | 38.87GB | 41.37GB |
| Code Llama 7B Chat (GGUF Q4_K_M) | 7B | 4.24GB | 6.74GB |
| Code Llama 13B Chat (GGUF Q4_K_M) | 13B | 8.06GB | 10.56GB |
| Phind Code Llama 34B Chat (GGUF Q4_K_M) | 34B | 20.22GB | 22.72GB |
Running LlamaGPT on an umbrelOS home server is one click. Simply install it from the Umbrel App Store.
Make sure your have Docker and Xcode installed.
Then, clone this repo and cd into it:
git clone https://github.com/getumbrel/llama-gpt.git
cd llama-gpt
Run LlamaGPT with the following command:
./run-mac.sh --model 7b
You can access LlamaGPT at http://localhost:3000.
To run 13B or 70B chat models, replace
7bwith13bor70brespectively. To run 7B, 13B or 34B Code Llama models, replace7bwithcode-7b,code-13borcode-34brespectively.
To stop LlamaGPT, do Ctrl + C in Terminal.
You can run LlamaGPT on any x86 or arm64 system. Make sure you have Docker installed.
Then, clone this repo and cd into it:
git clone https://github.com/getumbrel/llama-gpt.git
cd llama-gpt
Run LlamaGPT with the following command:
./run.sh --model 7b
Or if you have an Nvidia GPU, you can run LlamaGPT with CUDA support using the --with-cuda flag, like:
./run.sh --model 7b --with-cuda
You can access LlamaGPT at http://localhost:3000.
To run 13B or 70B chat models, replace
7bwith13bor70brespectively. To run Code Llama 7B, 13B or 34B models, replace7bwithcode-7b,code-13borcode-34brespectively.
To stop LlamaGPT, do Ctrl + C in Terminal.
Note: On the first run, it may take a while for the model to be downloaded to the
/modelsdirectory. You may also see lots of output like this for a few minutes, which is normal:llama-gpt-llama-gpt-ui-1 | [INFO wait] Host [llama-gpt-api-13b:8000] not yet available...After the model has been automatically downloaded and loaded, and the API server is running, you'll see an output like:
llama-gpt-ui_1 | ready - started server on 0.0.0.0:3000, url: http://localhost:3000You can then access LlamaGPT at http://localhost:3000.
First, make sure you have a running Kubernetes cluster and kubectl is configured to interact with it.
Then, clone this repo and cd into it.
To deploy to Kubernetes first create a namespace:
kubectl create ns llamaThen apply the manifests under the /deploy/kubernetes directory with
kubectl apply -k deploy/kubernetes/. -n llamaExpose your service however you would normally do that.
Thanks to llama-cpp-python, a drop-in replacement for OpenAI API is available at http://localhost:3001. Open http://localhost:3001/docs to see the API documentation.
We've tested LlamaGPT models on the following hardware with the default system prompt, and user prompt: "How does the universe expand?" at temperature 0 to guarantee deterministic results. Generation speed is averaged over the first 10 generations.
Feel free to add your own benchmarks to this table by opening a pull request.
| Device | Generation speed |
|---|---|
| M1 Max MacBook Pro (64GB RAM) | 54 tokens/sec |
| GCP c2-standard-16 vCPU (64 GB RAM) | 16.7 tokens/sec |
| Ryzen 5700G 4.4GHz 4c (16 GB RAM) | 11.50 tokens/sec |
| GCP c2-standard-4 vCPU (16 GB RAM) | 4.3 tokens/sec |
| Umbrel Home (16GB RAM) | 2.7 tokens/sec |
| Raspberry Pi 4 (8GB RAM) | 0.9 tokens/sec |
| Device | Generation speed |
|---|---|
| M1 Max MacBook Pro (64GB RAM) | 20 tokens/sec |
| GCP c2-standard-16 vCPU (64 GB RAM) | 8.6 tokens/sec |
| GCP c2-standard-4 vCPU (16 GB RAM) | 2.2 tokens/sec |
| Umbrel Home (16GB RAM) | 1.5 tokens/sec |
| Device | Generation speed |
|---|---|
| M1 Max MacBook Pro (64GB RAM) | 4.8 tokens/sec |
| GCP e2-standard-16 vCPU (64 GB RAM) | 1.75 tokens/sec |
| GCP c2-standard-16 vCPU (64 GB RAM) | 1.62 tokens/sec |
| Device | Generation speed |
|---|---|
| M1 Max MacBook Pro (64GB RAM) | 41 tokens/sec |
| Device | Generation speed |
|---|---|
| M1 Max MacBook Pro (64GB RAM) | 25 tokens/sec |
| Device | Generation speed |
|---|---|
| M1 Max MacBook Pro (64GB RAM) | 10.26 tokens/sec |
We're looking to add more features to LlamaGPT. You can see the roadmap here. The highest priorities are:
- [x] Moving the model out of the Docker image and into a separate volume.
- [x] Add Metal support for M1/M2 Macs.
- [x] Add support for Code Llama models.
- [x] Add CUDA support for NVIDIA GPUs.
- [ ] Add ability to load custom models.
- [ ] Allow users to switch between models.
If you're a developer who'd like to help with any of these, please open an issue to discuss the best way to tackle the challenge. If you're looking to help but not sure where to begin, check out these issues that have specifically been marked as being friendly to new contributors.
A massive thank you to the following developers and teams for making LlamaGPT possible:
- Mckay Wrigley for building Chatbot UI.
- Georgi Gerganov for implementing llama.cpp.
- Andrei for building the Python bindings for llama.cpp.
- NousResearch for fine-tuning the Llama 2 7B and 13B models.
- Phind for fine-tuning the Code Llama 34B model.
- Tom Jobbins for quantizing the Llama 2 models.
- Meta for releasing Llama 2 and Code Llama under a permissive license.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama-gpt
Similar Open Source Tools
llama-gpt
LlamaGPT is a self-hosted, offline, ChatGPT-like chatbot, powered by Llama 2. It is 100% private, with no data leaving your device. It supports various models, including Nous Hermes Llama 2 7B/13B/70B Chat and Code Llama 7B/13B/34B Chat. You can install LlamaGPT on your umbrelOS home server, M1/M2 Mac, or anywhere else with Docker. It also provides an OpenAI-compatible API for easy integration. LlamaGPT is still under development, with plans to add more features such as custom model loading and model switching.
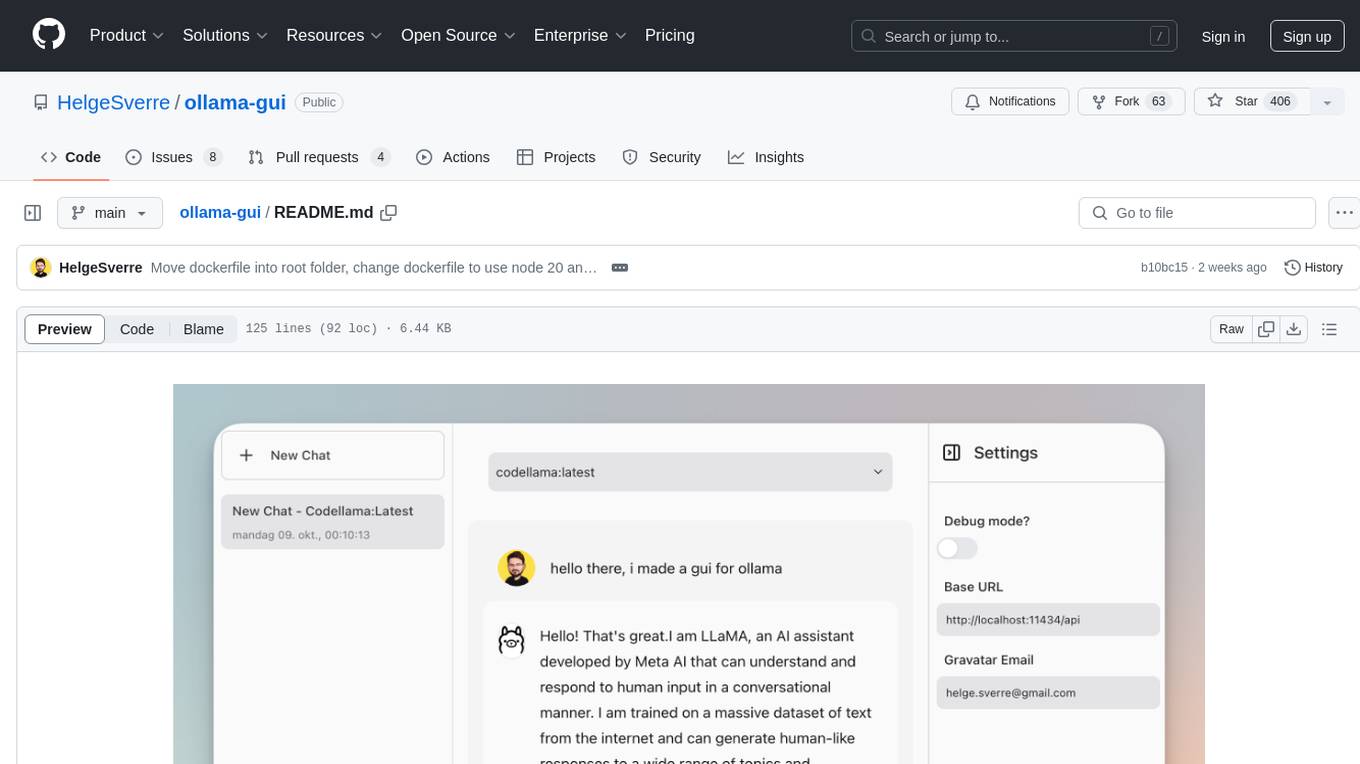
ollama-gui
Ollama GUI is a web interface for ollama.ai, a tool that enables running Large Language Models (LLMs) on your local machine. It provides a user-friendly platform for chatting with LLMs and accessing various models for text generation. Users can easily interact with different models, manage chat history, and explore available models through the web interface. The tool is built with Vue.js, Vite, and Tailwind CSS, offering a modern and responsive design for seamless user experience.
TinyLLM
TinyLLM is a project that helps build a small locally hosted language model with a web interface using consumer-grade hardware. It supports multiple language models, builds a local OpenAI API web service, and serves a Chatbot web interface with customizable prompts. The project requires specific hardware and software configurations for optimal performance. Users can run a local language model using inference servers like vLLM, llama-cpp-python, and Ollama. The Chatbot feature allows users to interact with the language model through a web-based interface, supporting features like summarizing websites, displaying news headlines, stock prices, weather conditions, and using vector databases for queries.

vscode-unify-chat-provider
The 'vscode-unify-chat-provider' repository is a tool that integrates multiple LLM API providers into VS Code's GitHub Copilot Chat using the Language Model API. It offers free tier access to mainstream models, perfect compatibility with major LLM API formats, deep adaptation to API features, best performance with built-in parameters, out-of-the-box configuration, import/export support, great UX, and one-click use of various models. The tool simplifies model setup, migration, and configuration for users, providing a seamless experience within VS Code for utilizing different language models.
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
cortex.cpp
Cortex.cpp is an open-source platform designed as the brain for robots, offering functionalities such as vision, speech, language, tabular data processing, and action. It provides an AI platform for running AI models with multi-engine support, hardware optimization with automatic GPU detection, and an OpenAI-compatible API. Users can download models from the Hugging Face model hub, run models, manage resources, and access advanced features like multiple quantizations and engine management. The tool is under active development, promising rapid improvements for users.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.
Topu-ai
TOPU Md is a simple WhatsApp user bot created by Topu Tech. It offers various features such as multi-device support, AI photo enhancement, downloader commands, hidden NSFW commands, logo commands, anime commands, economy menu, various games, and audio/video editor commands. Users can fork the repo, get a session ID by pairing code, and deploy on Heroku. The bot requires Node version 18.x or higher for optimal performance. Contributions to TOPU-MD are welcome, and the tool is safe for use on WhatsApp and Heroku. The tool is licensed under the MIT License and is designed to enhance the WhatsApp experience with diverse features.
dora
Dataflow-oriented robotic application (dora-rs) is a framework that makes creation of robotic applications fast and simple. Building a robotic application can be summed up as bringing together hardwares, algorithms, and AI models, and make them communicate with each others. At dora-rs, we try to: make integration of hardware and software easy by supporting Python, C, C++, and also ROS2. make communication low latency by using zero-copy Arrow messages. dora-rs is still experimental and you might experience bugs, but we're working very hard to make it stable as possible.
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
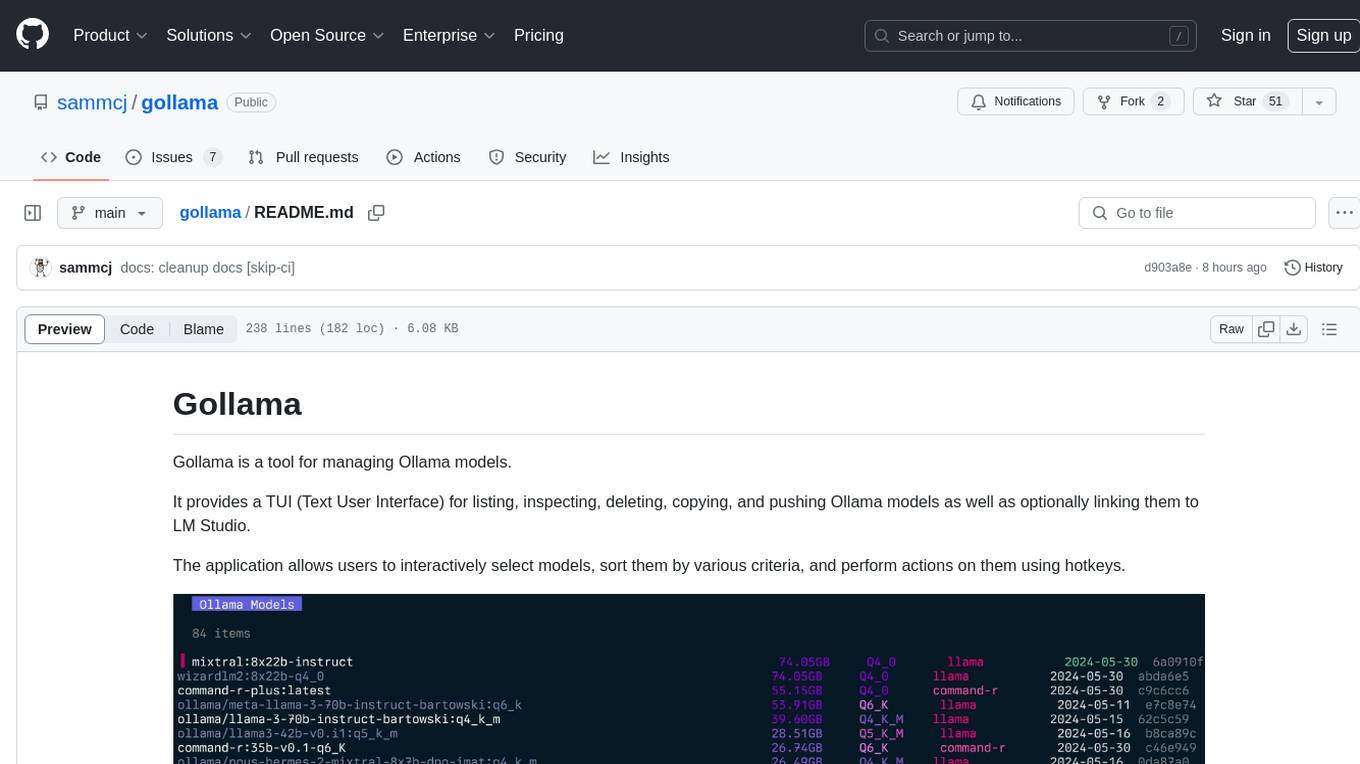
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.