
mllm
Fast Multimodal LLM on Mobile Devices
Stars: 1029
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
README:
![]()
- Plain C/C++ implementation without dependencies
- Optimized for multimodal LLMs like Qwen2-VL and LLaVA
- Supported: ARM NEON, x86 AVX2, Qualcomm NPU (QNN), etc
- Various quantization schemes
- End-to-end Android app demo
- Advanced support: MoE, Prompt Cache, etc..
mllm is a lightweight, fast, and easy-to-use (multimodal) on-device LLM inference engine for mobile devices (mainly supporting CPU/NPU), initiated by the research groups led by Mengwei Xu (BUPT) and Xuanzhe Liu (PKU).
- [2025 August 28] 🔥🔥🔥 Support for MLLM V1 is ending soon. Before its retirement, V1 will integrate the following features: GPT-OSS and NPU QWEN2-VL. MLLM will then transition to V2, which can be viewed on the V2 branch.
V2 will include brand-new capabilities:
- A more Pythonic model authoring approach with eager execution
- Compilation support and MLLM IR for easier NPU integration
- Support for parallel execution of multiple models
- A more refined engineering implementation
- [2024 November 21] Support new model: Phi 3 Vision https://github.com/UbiquitousLearning/mllm/pull/186
- [2024 August 30] Support new model: MiniCPM 2B https://github.com/UbiquitousLearning/mllm/pull/132
- [2024 August 15] Support new model: Phi 3 mini https://github.com/UbiquitousLearning/mllm/pull/119
- [2024 Aug 10] Supporting Qualcomm NPU: https://github.com/UbiquitousLearning/mllm/pull/112 | try it out | paper
- Android Demo
- Support models
- Quick Start
- Customization
- Roadmap
- Documentation
- Contribution
- Acknowledgments
- License
| Android Intent Invocation | Image Understanding |
| Chat CPU | Chat NPU |
| Model | CPU FP32 |
CPU INT4 |
Hexagon NPU INT8 |
|---|---|---|---|
| LLaMA 2 7B | ✔️ | ✔️ | |
| LLaMA 3 1B | ✔️ | ✔️ | |
| LLaMA 3 3B | ✔️ | ✔️ | |
| Alpaca 7B | ✔️ | ✔️ | |
| TinyLLaMA 1.1B | ✔️ | ✔️ | |
| LLaVA 7B | ✔️ | ✔️ | |
| Gemma 2B | ✔️ | ✔️ | |
| Gemma 2 2B | ✔️ | ✔️ | |
| Qwen 1.5 0.5B | ✔️ | ✔️ | |
| Qwen 1.5 1.8B | ✔️ | ✔️ | ✔️ |
| Qwen 2.5 1.5B | ✔️ | ✔️ | |
| Qwen 3 0.6B | ✔️ | ✔️ | |
| Mistral 7B | ✔️ | ✔️ | |
| Yi 6B | ✔️ | ✔️ | |
| StableLM 2 1.6B | ✔️ | ✔️ | |
| OPT 1.3B | ✔️ | ✔️ | |
| Phi 3 mini 3.8B | ✔️ | ✔️ | |
| MiniCPM 2B | ✔️ | ✔️ | |
| MiniCPM 3 4B | ✔️ | ✔️ | |
| MiniCPM MoE 8x2B | ✔️ | ✔️ | |
| SmolLM 1.7B | ✔️ | ✔️ | |
| DCLM 1B | ✔️ | ✔️ | |
| OpenELM 1.1B | ✔️ | ✔️ | |
| PhoneLM 1.5B | ✔️ | ✔️ | ✔️ |
| Model | CPU FP32 |
CPU INT4 |
|---|---|---|
| Fuyu 8B | ✔️ | ✔️ |
| Vision Transformer | ✔️ | ✔️ |
| CLIP | ✔️ | ✔️ |
| ImageBind (3 modalities) | ✔️ | ✔️ |
| LLaVA 7B | ✔️ | ✔️ |
| Phi-3-Vision | ✔️ | ✔️ |
| Qwen2-VL 2B | ✔️ | ✔️ |
git clone https://github.com/UbiquitousLearning/mllm
cd mllmBuilding mllm requires following tools:
- gcc(11.4+) / clang (11.0+)
- CMake >= 3.18
- Android NDK Toolchains >= 26
Note that building OpenMP libs on macOS may fail due to Apple LLVM compiler, so we disable OpenMP on macOS by default, you may experience slower performance on macOS. Build mllm is more recommended on Linux.
NOTE: The QNN backend is preliminary version which can do end-to-end inference. It is still under active development for better performance and more supported models.
We support running Qwen-1.5-1.8B-Chat using Qualcomm QNN to get Hexagon NPU acceleration on devices with Snapdragon 8 Gen3. The details of QNN environment set up and design is here. The prefilling stage is performered by QNN & CPU, and the inference stage is performed by CPU.
Build the target with QNN backend.
cd ../script
./build_qnn_android.shDownload the model from here, or using the following instructions
mkdir ../models && cd ../models
# Download int8 model used by npu & q4k model used by cpu
wget https://huggingface.co/mllmTeam/qwen-1.5-1.8b-chat-mllm/resolve/main/qwen-1.5-1.8b-chat-int8.mllm?download=true -O qwen-1.5-1.8b-chat-int8.mllm
wget https://huggingface.co/mllmTeam/qwen-1.5-1.8b-chat-mllm/resolve/main/qwen-1.5-1.8b-chat-q4k.mllm?download=true -O qwen-1.5-1.8b-chat-q4k.mllmRun on an android phone with at least 16GB of memory.
cd ../script
./run_qwen_npu.shThere are two arguments in the executable. -s is for the sequence length of prefilling, the default value is 64 in the demo we provided. -c for type of QNN prefilling options, when it is set to 1, the input will be splited into many chunks of sequence 32 and be executed in a pipeline. When it is set to 0, the input will be executed in one chunk.
Result are as followed:
> ./main_qwen_npu -s 64 -c 1
[Q] <|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Give me a short introduction to large language model.<|im_end|>
<|im_start|>assistant
[A] A short introduction to a large language model is a type of artificial intelligence language model that is designed to understand and generate human language text. These models are typically trained on large amounts of text data, such as books, articles, and other written materials, to learn the patterns and structures of human language. They use a combination of natural language processing (NLP)
export ANDROID_NDK=/path/to/your/ndk
cd scripts
./build_android.shDownload the model from here, or using the following instructions
mkdir ../models && cd ../models
# Download fuyu-8b-q4_k.mllm
wget https://huggingface.co/mllmTeam/fuyu-8b-mllm/resolve/main/fuyu-8b-q4_k.mllm?download=true -O fuyu-8b-q4_k.mllmRun on an android phone with at least 12GB of memory.
cd ../script
./run_fuyu.shResult are as followed:
> ./demo_fuyu
[Q] [../assets/bus.png]Generate a coco-style caption.
[A] A blue bus driving down▁the▁road next▁to a sidewalk.
[Q] [../assets/two_cats.jpg]What's this?
[A] Two cats laying on▁top▁of a pink blanket.
Download model from here, or using the following instructions
mkdir ../models && cd ../models
# Dowload llama-2-7b-chat-q4_k.mllm
wget https://huggingface.co/mllmTeam/llama-2-7b-mllm/resolve/main/llama-2-7b-chat-q4_k.mllm?download=true -O llama-2-7b-chat-q4_k.mllmRun on an android phone with at least 12GB of memory.
cd ../script
./run_llama.shResult are as followed:
> ./demo_llama
[Q] Hello, who are you?
[A]
I am a bot, I'm here to help answer your questions and provide information. I'm just an AI, I don't have personal experiences or feelings like humans do, but I'm here to help you with any questions you may have. Is there something specific you would like to know or talk about?
[Q] What can you do?
[A]
I can help with a wide range of tasks, including:
* Answering questions on various topics, such as science, history, technology, and more.
* Providing information on different subjects, such as culture, entertainment, and lifestyle.
* Helping with language-related tasks, such as translating text or improving grammar and syntax.
* Generating text, such as articles, stories, or even entire books.
* Assisting with coding
[Q] Please introduce Beijing University of Posts and Telecommunications.
[A]
Beijing University of Posts and Telecommunications (BUPT) is a public research university located in Beijing, China. It was established in 1955 and is one of the top universities in China, with a strong focus on engineering, technology, and telecommunications.
BUPT offers a wide range of undergraduate and graduate programs in fields such as computer science, electrical engineering, software engineering, and communication engineering. The university
Download model from here, or using the following instructions
mkdir ../models && cd ../models
# Download imagebind_huge-q4_k.mllm
wget https://huggingface.co/mllmTeam/imagebind_huge-mllm/resolve/main/imagebind_huge-q4_k.mllm?download=true -O imagebind_huge-q4_k.mllm Run on an android phone with at least 4GB of memory.
cd ../script
./run_imagebind.shResult are as followed:
> ./demo_imagebind
vision X text :
0.9985647 0.0013827 0.0000526
0.0000365 0.9998636 0.0000999
0.0000115 0.0083149 0.9916736
vision X audio :
0.8054272 0.1228001 0.0717727
0.0673458 0.8429284 0.0897258
0.0021967 0.0015335 0.9962698
cd scripts
./build.shcd ./bin
./demo_fuyu -m ../models/fuyu-8b-q4_k.mllm -v ../vocab/fuyu_vocab.mllmcd ./bin
./demo_llama -m ../models/llama-2-7b-chat-q4_k.mllm -v ../vocab/llama2_vocab.mllmcd ./bin
./demo_imagebind -m ../models/imagebind_huge-q4_k.mllm -v ../vocab/clip_vocab.mllmYou can download models from here, or you can convert a pytorch/safetensor model to mllm model by yourself.
cd tools/convertor
pip install -r ./requirements.txt
# for one file pytorch model
python converter.py --input_model=model.pth --output_model=model.mllm --type=torch
# for multi-file pytorch model
python converter.py --input_model=pytorch_model.bin.index.json --output_model=model.mllm --type=torch
# for one file safetensor model
python converter.py --input_model=model.bin --output_model=model.mllm --type=safetensor
# for multi-file safetensor model
python converter.py --input_model=model.safetensors.index.json --output_model=model.mllm --type=safetensorYou can convert vocabulary to mllm vocabulary as followed.
cd tools/convertor
python vocab.py --input_file=tokenizer.json --output_file=vocab.mllm --type=UnigramYou can quantize mllm model to int4 model by yourself. mllm only support two quantize modes: Q4_0 and Q4_K.
cd bin
./quantize model.mllm model_q4_k.mllm Q4_K- More backends like QNN
- More models like PandaGPT
- More optimizations like LUT-GEMM
- More..
See the documentation here for more information
Read the contribution before you contribute.
mllm reuses many low-level kernel implementation from ggml on ARM CPU. It also utilizes stb and wenet for pre-processing images and audios. mllm also has benefitted from following projects: llama.cpp and MNN.
This project is licensed under the terms of the MIT License. Please see the LICENSE file in the root directory for the full text of the MIT License.
Certain component(wenet) of this project is licensed under the Apache License 2.0. These component is clearly identified in their respective subdirectories along with a copy of the Apache License 2.0. For the full text of the Apache License 2.0, please refer to the LICENSE-APACHE file located in the relevant subdirectories.
@article{xu2025fast,
title={Fast On-device LLM Inference with NPUs},
author={Xu, Daliang and Zhang, Hao and Yang, Liming and Liu, Ruiqi and Huang, Gang and Xu, Mengwei and Liu, Xuanzhe},
booktitle={International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)},
year={2025}
}
@misc{yi2023mllm,
title = {mllm: fast and lightweight multimodal LLM inference engine for mobile and edge devices},
author = {Rongjie Yi and Xiang Li and Zhenyan Lu and Hao Zhang and Daliang Xu and Liming Yang and Weikai Xie and Chenghua Wang and Xuanzhe Liu and Mengwei Xu},
year = {2023},
publisher = {mllm Team},
url = {https://github.com/UbiquitousLearning/mllm}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mllm
Similar Open Source Tools
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
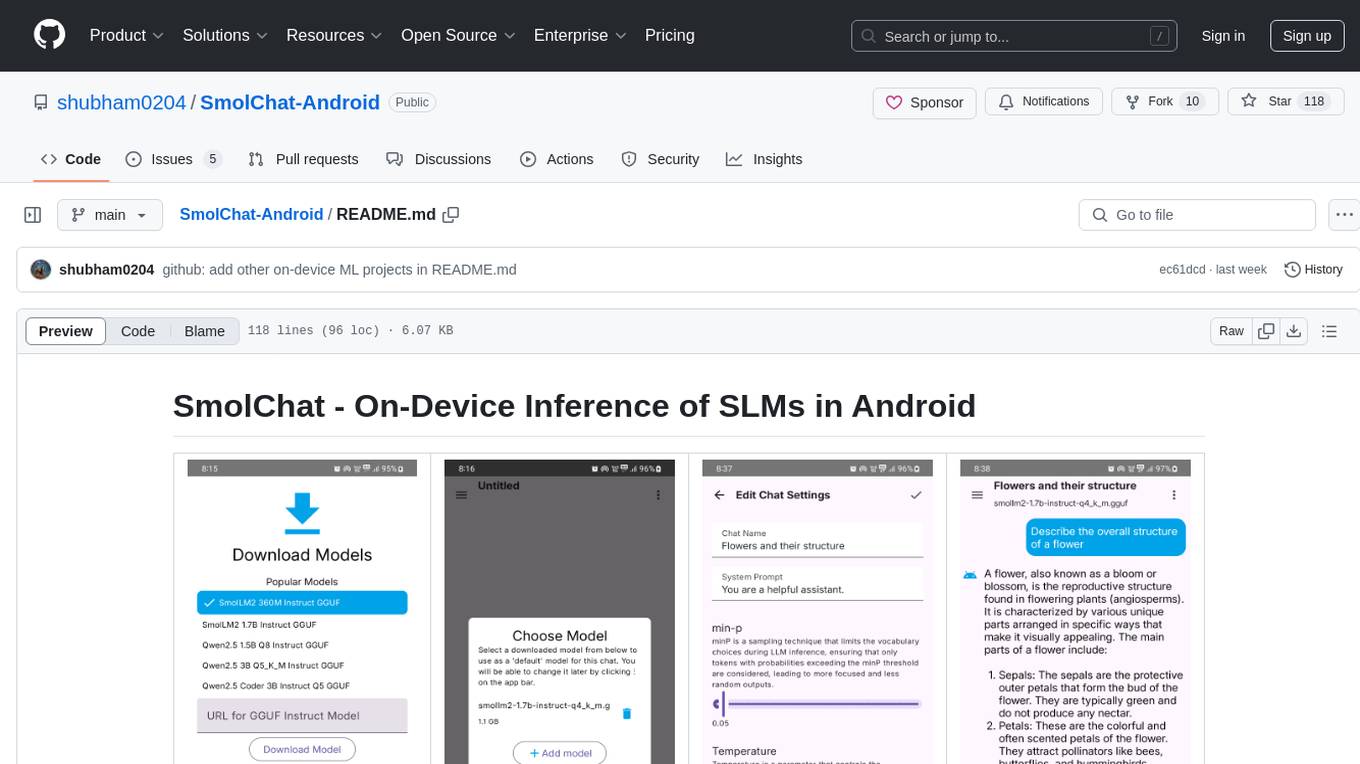
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.

chatluna
Chatluna is a machine learning model plugin that provides chat services with large language models. It is highly extensible, supports multiple output formats, and offers features like custom conversation presets, rate limiting, and context awareness. Users can deploy Chatluna under Koishi without additional configuration. The plugin supports various models/platforms like OpenAI, Azure OpenAI, Google Gemini, and more. It also provides preset customization using YAML files and allows for easy forking and development within Koishi projects. However, the project lacks web UI, HTTP server, and project documentation, inviting contributions from the community.
nestia
Nestia is a set of helper libraries for NestJS, providing super-fast/easy decorators, advanced WebSocket routes, Swagger generator, SDK library generator for clients, mockup simulator for client applications, automatic E2E test functions generator, test program utilizing e2e test functions, benchmark program using e2e test functions, super A.I. chatbot by Swagger document, Swagger-UI with online TypeScript editor, and a CLI tool. It enhances performance significantly and offers a collection of typed fetch functions with DTO structures like tRPC, along with a mockup simulator that is fully automated.
nekro-agent
Nekro Agent is an AI chat plugin and proxy execution bot that is highly scalable, offers high freedom, and has minimal deployment requirements. It features context-aware chat for group/private chats, custom character settings, sandboxed execution environment, interactive image resource handling, customizable extension development interface, easy deployment with docker-compose, integration with Stable Diffusion for AI drawing capabilities, support for various file types interaction, hot configuration updates and command control, native multimodal understanding, visual application management control panel, CoT (Chain of Thought) support, self-triggered timers and holiday greetings, event notification understanding, and more. It allows for third-party extensions and AI-generated extensions, and includes features like automatic context trigger based on LLM, and a variety of basic commands for bot administrators.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
GPTQModel
GPTQModel is an easy-to-use LLM quantization and inference toolkit based on the GPTQ algorithm. It provides support for weight-only quantization and offers features such as dynamic per layer/module flexible quantization, sharding support, and auto-heal quantization errors. The toolkit aims to ensure inference compatibility with HF Transformers, vLLM, and SGLang. It offers various model supports, faster quant inference, better quality quants, and security features like hash check of model weights. GPTQModel also focuses on faster quantization, improved quant quality as measured by PPL, and backports bug fixes from AutoGPTQ.
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
dagger
Dagger is an open-source runtime for composable workflows, ideal for systems requiring repeatability, modularity, observability, and cross-platform support. It features a reproducible execution engine, a universal type system, a powerful data layer, native SDKs for multiple languages, an open ecosystem, an interactive command-line environment, batteries-included observability, and seamless integration with various platforms and frameworks. It also offers LLM augmentation for connecting to LLM endpoints. Dagger is suitable for AI agents and CI/CD workflows.
jadx-mcp-server
JADX-MCP-SERVER is a standalone Python server that interacts with JADX-AI-MCP Plugin to analyze Android APKs using LLMs like Claude. It enables live communication with decompiled Android app context, uncovering vulnerabilities, parsing manifests, and facilitating reverse engineering effortlessly. The tool combines JADX-AI-MCP and JADX MCP SERVER to provide real-time reverse engineering support with LLMs, offering features like quick analysis, vulnerability detection, AI code modification, static analysis, and reverse engineering helpers. It supports various MCP tools for fetching class information, text, methods, fields, smali code, AndroidManifest.xml content, strings.xml file, resource files, and more. Tested on Claude Desktop, it aims to support other LLMs in the future, enhancing Android reverse engineering and APK modification tools connectivity for easier reverse engineering purely from vibes.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.
rig
Rig is a Rust library designed for building scalable, modular, and user-friendly applications powered by large language models (LLMs). It provides full support for LLM completion and embedding workflows, offers simple yet powerful abstractions for LLM providers like OpenAI and Cohere, as well as vector stores such as MongoDB and in-memory storage. With Rig, users can easily integrate LLMs into their applications with minimal boilerplate code.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.
For similar tasks
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
llm_interview_note
This repository provides a comprehensive overview of large language models (LLMs), covering various aspects such as their history, types, underlying architecture, training techniques, and applications. It includes detailed explanations of key concepts like Transformer models, distributed training, fine-tuning, and reinforcement learning. The repository also discusses the evaluation and limitations of LLMs, including the phenomenon of hallucinations. Additionally, it provides a list of related courses and references for further exploration.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.
FlowDown-App
FlowDown is a blazing fast and smooth client app for using AI/LLM. It is lightweight and efficient with markdown support, universal compatibility, blazing fast text rendering, automated chat titles, and privacy by design. There are two editions available: FlowDown and FlowDown Community, with various features like chat with AI, fast markdown, privacy by design, bring your own LLM, offline LLM w/ MLX, visual LLM, web search, attachments, and language localization. FlowDown Community is now open-source, empowering developers to build interactive and responsive AI client apps.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.
haystack-core-integrations
This repository contains integrations to extend the capabilities of Haystack version 2.0 and onwards. The code in this repo is maintained by deepset, see each integration's `README` file for details around installation, usage and support.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.