
haystack-core-integrations
Additional packages (components, document stores and the likes) to extend the capabilities of Haystack
Stars: 181
This repository contains integrations to extend the capabilities of Haystack version 2.0 and onwards. The code in this repo is maintained by deepset, see each integration's `README` file for details around installation, usage and support.
README:
This repository contains integrations to extend the capabilities of Haystack. The code in this repo is maintained by deepset, see each integration's README file for details around installation, usage and support.
You will need hatch to work on or create new integrations, open this link
and follow the install instructions for your operating system and platform.
All the integrations are self contained, so the first step before working on one is to cd into the proper folder.
For example, to run the tests suite for the Chroma document store, from the root of the repo:
$ cd integrations/chroma
$ hatch run test:allHatch will take care of setting up an isolated Python environment and run the tests.
Please check out our Contribution Guidelines for all the details.
![]()













































[!NOTE] Only maintainers can release new versions of integrations. If you're a community contributor and want to release a new version of an integration, reach out to a maintainer.
To release a new version of an integration to PyPI tag the commit with the right version number and push the tag to GitHub. The GitHub Actions workflow will take care of the rest.
-
Tag the commit with the right version number
The tag needs to have the following format:
git tag integrations/<INTEGRATION_FOLDER_NAME>-<version>For example, if we want to release version 1.0.99 of the google-vertex-haystack integration we'd have to push the tag:
git tag integrations/google_vertex-v1.0.99 -
Push the tag to GitHub
git push --tags origin -
Wait for the CI to do its magic
If the release is successful, the HaystackBot will push a commit on main to update the changelog.
[!IMPORTANT] To ensure the changelog is accurate, it's recommended to tag a commit that includes the actual changes for the integration (usually the PR merge commit). Tagging a commit that doesn't contain those changes can lead to an incorrect changelog.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for haystack-core-integrations
Similar Open Source Tools
haystack-core-integrations
This repository contains integrations to extend the capabilities of Haystack version 2.0 and onwards. The code in this repo is maintained by deepset, see each integration's `README` file for details around installation, usage and support.
goat
GOAT (Great Onchain Agent Toolkit) is an open-source framework designed to simplify the process of making AI agents perform onchain actions by providing a provider-agnostic solution that abstracts away the complexities of interacting with blockchain tools such as wallets, token trading, and smart contracts. It offers a catalog of ready-made blockchain actions for agent developers and allows dApp/smart contract developers to develop plugins for easy access by agents. With compatibility across popular agent frameworks, support for multiple blockchains and wallet providers, and customizable onchain functionalities, GOAT aims to streamline the integration of blockchain capabilities into AI agents.


AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
AITreasureBox
AITreasureBox is a comprehensive collection of AI tools and resources designed to simplify and accelerate the development of AI projects. It provides a wide range of pre-trained models, datasets, and utilities that can be easily integrated into various AI applications. With AITreasureBox, developers can quickly prototype, test, and deploy AI solutions without having to build everything from scratch. Whether you are working on computer vision, natural language processing, or reinforcement learning projects, AITreasureBox has something to offer for everyone. The repository is regularly updated with new tools and resources to keep up with the latest advancements in the field of artificial intelligence.
Awesome-LLM-Resources-List
Awesome LLM Resources is a curated collection of resources for Large Language Models (LLMs) covering various aspects such as serverless hosting, accessing off-the-shelf models via API, local inference, LLM serving frameworks, open-source LLM web chat UIs, renting GPUs for fine-tuning, fine-tuning with no-code UI, fine-tuning frameworks, OS agentic/AI workflow, AI agents, co-pilots, voice API, open-source TTS models, OS RAG frameworks, research papers on chain-of-thought prompting, CoT implementations, CoT fine-tuned models & datasets, and more.
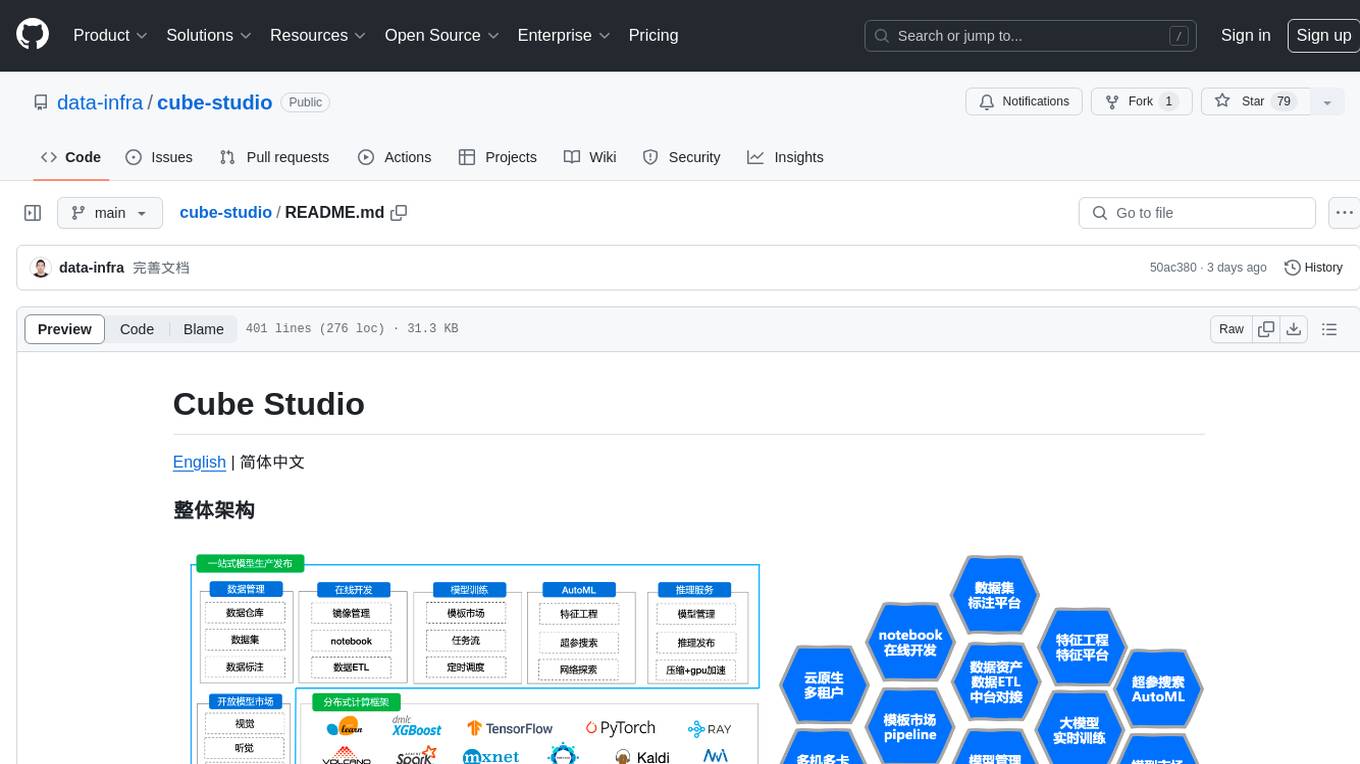
cube-studio
Cube Studio is an open-source all-in-one cloud-native machine learning platform that provides various functionalities such as project group management, network configuration, user management, role management, billing functions, SSO single sign-on, support for multiple computing power types, support for multiple resource groups and clusters, edge cluster support, serverless cluster mode support, database storage support, machine resource management, storage disk management, internationalization capabilities, data map management, data calculation, ETL orchestration, data set management, data annotation, image/audio/text dataset support, feature processing, traditional machine learning algorithms, distributed deep learning frameworks, distributed acceleration frameworks, model evaluation, model format conversion, model registration, model deployment, distributed media processing, custom operators, automatic learning, custom training images, automatic parameter tuning, TensorBoard jobs, internal services, model management, inference services, monitoring, model application management, model marketplace, model development, model fine-tuning, web model deployment, automated annotation, dataset SDK, notebook SDK, pipeline training SDK, inference service SDK, large model distributed training, large model inference, large model fine-tuning, intelligent conversation, private knowledge base, model deployment for WeChat public accounts, enterprise WeChat group chatbot integration, DingTalk group chatbot integration, and more. Cube Studio offers template-based functionality for data import/export, data processing, feature processing, machine learning frameworks, machine learning algorithms, deep learning frameworks, model processing, model serving, monitoring, and more.
Awesome-RL-for-LRMs
This repository contains a collection of awesome resources for reinforcement learning in language models. It includes tutorials, code implementations, research papers, and tools to help researchers and practitioners explore and apply reinforcement learning techniques in natural language processing tasks. Whether you are a beginner or an expert in the field, this repository aims to provide valuable insights and guidance to enhance your understanding and implementation of reinforcement learning in language models.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.
cgft-llm
The cgft-llm repository is a collection of video tutorials and documentation for implementing large models. It provides guidance on topics such as fine-tuning llama3 with llama-factory, lightweight deployment and quantization using llama.cpp, speech generation with ChatTTS, introduction to Ollama for large model deployment, deployment tools for vllm and paged attention, and implementing RAG with llama-index. Users can find detailed code documentation and video tutorials for each project in the repository.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
ms-copilot-play
Microsoft Copilot Play is a Cloudflare Worker service that accelerates Microsoft Copilot functionalities in China. It allows high-speed access to Microsoft Copilot features like chatting, notebook, plugins, image generation, and sharing. The service filters out meaningless requests used for statistics, saving up to 80% of Cloudflare Worker requests. Users can deploy the service easily with Cloudflare Worker, ensuring fast and unlimited access with no additional operations. The service leverages the power of Microsoft Copilot, based on OpenAI GPT-4, and utilizes Bing search to answer questions.
For similar tasks
haystack-core-integrations
This repository contains integrations to extend the capabilities of Haystack version 2.0 and onwards. The code in this repo is maintained by deepset, see each integration's `README` file for details around installation, usage and support.
AI-Office-Translator
AI-Office-Translator is a free, fully localized, user-friendly translation tool that helps you translate Office files (Word, PowerPoint, and Excel) between different languages. It supports .docx, .pptx, and .xlsx files and allows translation between English, Chinese, and Japanese. Users can run the tool after installing CUDA, downloading Ollama dependencies and models, setting up a virtual environment (optional), and installing requirements. The tool provides a UI where users can select languages, models, upload files for translation, start translation, and download translated files. It also supports an online mode with API key integration. The software is open-source under GPL-3.0 license and only provides AI translation services, with users expected to engage in legal translation activities.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.
RWKV-LM
RWKV is an RNN with Transformer-level LLM performance, which can also be directly trained like a GPT transformer (parallelizable). And it's 100% attention-free. You only need the hidden state at position t to compute the state at position t+1. You can use the "GPT" mode to quickly compute the hidden state for the "RNN" mode. So it's combining the best of RNN and transformer - **great performance, fast inference, saves VRAM, fast training, "infinite" ctx_len, and free sentence embedding** (using the final hidden state).

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.
VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.