
llama-api-server
A OpenAI API compatible REST server for llama.
Stars: 204
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
README:
![]()
This project is under active deployment. Breaking changes could be made any time.
Llama as a Service! This project try to build a REST-ful API server compatible to OpenAI API using open source backends like llama/llama2.
With this project, many common GPT tools/framework can compatible with your own model.
Follow instruction in this collab notebook to play it online. Thanks anythingbutme for building it!
If you you don't have quantized llama.cpp, you need to follow instruction to prepare model.
If you you don't have quantize pyllama, you need to follow instruction to prepare model.
Use following script to download package from PyPI and generates model config file config.yml and security token file tokens.txt.
pip install llama-api-server
# to run wth pyllama
pip install llama-api-server[pyllama]
cat > config.yml << EOF
models:
completions:
# completions and chat_completions use same model
text-ada-002:
type: llama_cpp
params:
path: /absolute/path/to/your/7B/ggml-model-q4_0.bin
text-davinci-002:
type: pyllama_quant
params:
path: /absolute/path/to/your/pyllama-7B4b.pt
text-davinci-003:
type: pyllama
params:
ckpt_dir: /absolute/path/to/your/7B/
tokenizer_path: /absolute/path/to/your/tokenizer.model
# keep to 1 instance to speed up loading of model
embeddings:
text-embedding-davinci-002:
type: pyllama_quant
params:
path: /absolute/path/to/your/pyllama-7B4b.pt
min_instance: 1
max_instance: 1
idle_timeout: 3600
text-embedding-ada-002:
type: llama_cpp
params:
path: /absolute/path/to/your/7B/ggml-model-q4_0.bin
EOF
echo "SOME_TOKEN" > tokens.txt
# start web server
python -m llama_api_server
# or visible across the network
python -m llama_api_server --host=0.0.0.0
export OPENAI_API_KEY=SOME_TOKEN
export OPENAI_API_BASE=http://127.0.0.1:5000/v1
openai api completions.create -e text-ada-002 -p "hello?"
# or using chat
openai api chat_completions.create -e text-ada-002 -g user "hello?"
# or calling embedding
curl -X POST http://127.0.0.1:5000/v1/embeddings -H 'Content-Type: application/json' -d '{"model":"text-embedding-ada-002", "input":"It is good."}' -H "Authorization: Bearer SOME_TOKEN"
- [X] openai-python
- [X] OPENAI_API_TYPE=default
- [X] OPENAI_API_TYPE=azure
- [X] llama-index
- [X] Completions
- [X] set
temperature,top_p, andtop_k - [X] set
max_tokens - [X] set
echo - [ ] set
stop - [ ] set
stream - [ ] set
n - [ ] set
presence_penaltyandfrequency_penalty - [ ] set
logit_bias
- [X] set
- [X] Embeddings
- [X] batch process
- [X] Chat
- [ ] Prefix cache for chat
- [ ] List model
- [X] llama.cpp via llamacpp-python
- [X] llama via pyllama
- [X] Without Quantization
- [X] With Quantization
- [X] Support LLAMA2
- [X] Performance parameters like
n_batchandn_thread - [X] Token auth
- [ ] Documents
- [ ] Intergration tests
- [ ] A tool to download/prepare pretrain model
- [ ] Make config.ini and token file configable
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llama-api-server
Similar Open Source Tools
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
Free-GPT4-WEB-API
FreeGPT4-WEB-API is a Python server that allows you to have a self-hosted GPT-4 Unlimited and Free WEB API, via the latest Bing's AI. It uses Flask and GPT4Free libraries. GPT4Free provides an interface to the Bing's GPT-4. The server can be configured by editing the `FreeGPT4_Server.py` file. You can change the server's port, host, and other settings. The only cookie needed for the Bing model is `_U`.
ollama4j
Ollama4j is a Java library that serves as a wrapper or binding for the Ollama server. It facilitates communication with the Ollama server and provides models for deployment. The tool requires Java 11 or higher and can be installed locally or via Docker. Users can integrate Ollama4j into Maven projects by adding the specified dependency. The tool offers API specifications and supports various development tasks such as building, running unit tests, and integration tests. Releases are automated through GitHub Actions CI workflow. Areas of improvement include adhering to Java naming conventions, updating deprecated code, implementing logging, using lombok, and enhancing request body creation. Contributions to the project are encouraged, whether reporting bugs, suggesting enhancements, or contributing code.
Qmedia
QMedia is an open-source multimedia AI content search engine designed specifically for content creators. It provides rich information extraction methods for text, image, and short video content. The tool integrates unstructured text, image, and short video information to build a multimodal RAG content Q&A system. Users can efficiently search for image/text and short video materials, analyze content, provide content sources, and generate customized search results based on user interests and needs. QMedia supports local deployment for offline content search and Q&A for private data. The tool offers features like content cards display, multimodal content RAG search, and pure local multimodal models deployment. Users can deploy different types of models locally, manage language models, feature embedding models, image models, and video models. QMedia aims to spark new ideas for content creation and share AI content creation concepts in an open-source manner.
ChatGPT-Next-Web
ChatGPT Next Web is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro models. It allows users to deploy their private ChatGPT applications with ease. The tool offers features like one-click deployment, compact client for Linux/Windows/MacOS, compatibility with self-deployed LLMs, privacy-first approach with local data storage, markdown support, responsive design, fast loading speed, prompt templates, awesome prompts, chat history compression, multilingual support, and more.
genius-ai
Genius is a modern Next.js 14 SaaS AI platform that provides a comprehensive folder structure for app development. It offers features like authentication, dashboard management, landing pages, API integration, and more. The platform is built using React JS, Next JS, TypeScript, Tailwind CSS, and integrates with services like Netlify, Prisma, MySQL, and Stripe. Genius enables users to create AI-powered applications with functionalities such as conversation generation, image processing, code generation, and more. It also includes features like Clerk authentication, OpenAI integration, Replicate API usage, Aiven database connectivity, and Stripe API/webhook setup. The platform is fully configurable and provides a seamless development experience for building AI-driven applications.
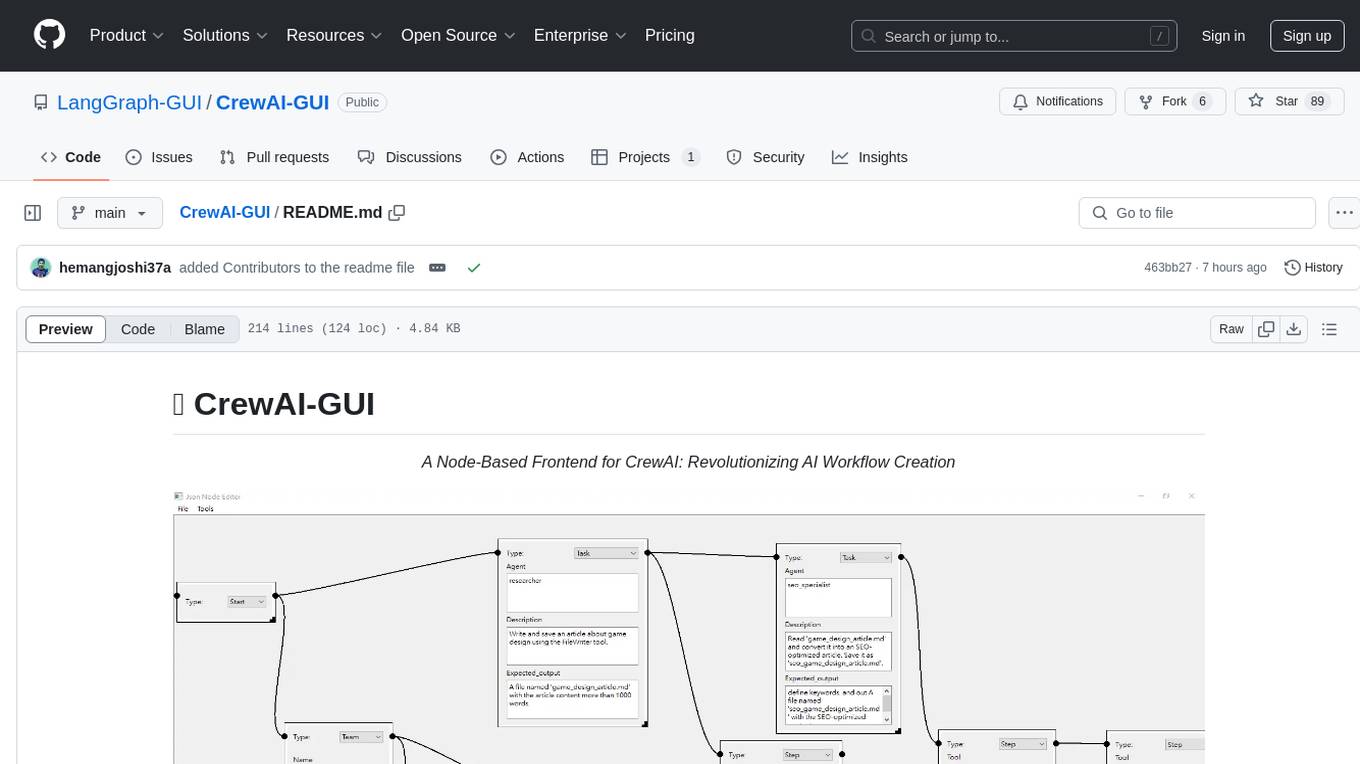
CrewAI-GUI
CrewAI-GUI is a Node-Based Frontend tool designed to revolutionize AI workflow creation. It empowers users to design complex AI agent interactions through an intuitive drag-and-drop interface, export designs to JSON for modularity and reusability, and supports both GPT-4 API and Ollama for flexible AI backend. The tool ensures cross-platform compatibility, allowing users to create AI workflows on Windows, Linux, or macOS efficiently.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
NextChat
NextChat is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro. It offers a compact client for Linux, Windows, and MacOS, with features like self-deployed LLMs compatibility, privacy-first data storage, markdown support, responsive design, and fast loading speed. Users can create, share, and debug chat tools with prompt templates, access various prompts, compress chat history, and use multiple languages. The tool also supports enterprise-level privatization and customization deployment, with features like brand customization, resource integration, permission control, knowledge integration, security auditing, private deployment, and continuous updates.

mcpm.sh
MCPM is an open source CLI tool for managing MCP servers, providing a simplified global configuration approach to install servers once, organize them with profiles, and integrate them into any MCP client. Features include server discovery, direct execution, sharing capabilities, and client integration tools. It eliminates the complexity of v1's target-based system in favor of a clean global workspace model. The tool is designed to be AI agent friendly with comprehensive automation support and a rich CLI interface.

TalkWithGemini
Talk With Gemini is a web application that allows users to deploy their private Gemini application for free with one click. It supports Gemini Pro and Gemini Pro Vision models. The application features talk mode for direct communication with Gemini, visual recognition for understanding picture content, full Markdown support, automatic compression of chat records, privacy and security with local data storage, well-designed UI with responsive design, fast loading speed, and multi-language support. The tool is designed to be user-friendly and versatile for various deployment options and language preferences.
llm-x
LLM X is a ChatGPT-style UI for the niche group of folks who run Ollama (think of this like an offline chat gpt server) locally. It supports sending and receiving images and text and works offline through PWA (Progressive Web App) standards. The project utilizes React, Typescript, Lodash, Mobx State Tree, Tailwind css, DaisyUI, NextUI, Highlight.js, React Markdown, kbar, Yet Another React Lightbox, Vite, and Vite PWA plugin. It is inspired by ollama-ui's project and Perplexity.ai's UI advancements in the LLM UI space. The project is still under development, but it is already a great way to get started with building your own LLM UI.
pebble
Pebbling is an open-source protocol for agent-to-agent communication, enabling AI agents to collaborate securely using Decentralised Identifiers (DIDs) and mutual TLS (mTLS). It provides a lightweight communication protocol built on JSON-RPC 2.0, ensuring reliable and secure conversations between agents. Pebbling allows agents to exchange messages safely, connect seamlessly regardless of programming language, and communicate quickly and efficiently. It is designed to pave the way for the next generation of collaborative AI systems, promoting secure and effortless communication between agents across different environments.
duolingo-clone
Lingo is an interactive platform for language learning that provides a modern UI/UX experience. It offers features like courses, quests, and a shop for users to engage with. The tech stack includes React JS, Next JS, Typescript, Tailwind CSS, Vercel, and Postgresql. Users can contribute to the project by submitting changes via pull requests. The platform utilizes resources from CodeWithAntonio, Kenney Assets, Freesound, Elevenlabs AI, and Flagpack. Key dependencies include @clerk/nextjs, @neondatabase/serverless, @radix-ui/react-avatar, and more. Users can follow the project creator on GitHub and Twitter, as well as subscribe to their YouTube channel for updates. To learn more about Next.js, users can refer to the Next.js documentation and interactive tutorial.

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.
Shellsage
Shell Sage is an intelligent terminal companion and AI-powered terminal assistant that enhances the terminal experience with features like local and cloud AI support, context-aware error diagnosis, natural language to command translation, and safe command execution workflows. It offers interactive workflows, supports various API providers, and allows for custom model selection. Users can configure the tool for local or API mode, select specific models, and switch between modes easily. Currently in alpha development, Shell Sage has known limitations like limited Windows support and occasional false positives in error detection. The roadmap includes improvements like better context awareness, Windows PowerShell integration, Tmux integration, and CI/CD error pattern database.
For similar tasks
mlc-llm
MLC LLM is a high-performance universal deployment solution that allows native deployment of any large language models with native APIs with compiler acceleration. It supports a wide range of model architectures and variants, including Llama, GPT-NeoX, GPT-J, RWKV, MiniGPT, GPTBigCode, ChatGLM, StableLM, Mistral, and Phi. MLC LLM provides multiple sets of APIs across platforms and environments, including Python API, OpenAI-compatible Rest-API, C++ API, JavaScript API and Web LLM, Swift API for iOS App, and Java API and Android App.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
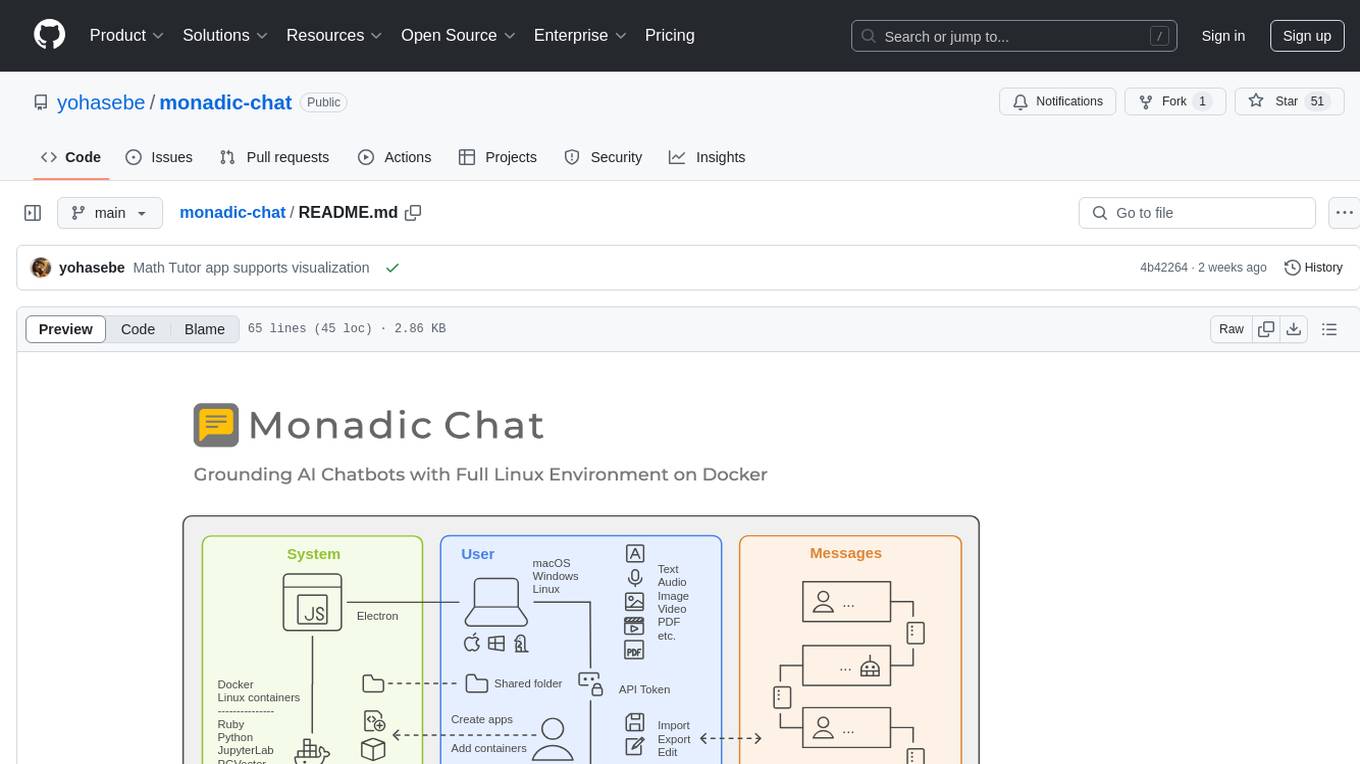
monadic-chat
Monadic Chat is a locally hosted web application designed to create and utilize intelligent chatbots. It provides a Linux environment on Docker to GPT and other LLMs, enabling the execution of advanced tasks that require external tools. The tool supports voice interaction, image and video recognition and generation, and AI-to-AI chat, making it useful for using AI and developing various applications. It is available for Mac, Windows, and Linux (Debian/Ubuntu) with easy-to-use installers.
ollama-playground
Ollama Projects is a repository containing code for various projects built using Ollama's open-source models. The projects include Chat with PDF, Chat with PDF Using Hybrid RAG, AI Scraper, Image Search, OCR, Object Detection, Emotion Detection, and AI Researcher. These projects showcase the capabilities of Ollama's models and provide insights into AI applications in different domains.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord
Tutorial
The Bookworm·Puyu large model training camp aims to promote the implementation of large models in more industries and provide developers with a more efficient platform for learning the development and application of large models. Within two weeks, you will learn the entire process of fine-tuning, deploying, and evaluating large models.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.
llm_interview_note
This repository provides a comprehensive overview of large language models (LLMs), covering various aspects such as their history, types, underlying architecture, training techniques, and applications. It includes detailed explanations of key concepts like Transformer models, distributed training, fine-tuning, and reinforcement learning. The repository also discusses the evaluation and limitations of LLMs, including the phenomenon of hallucinations. Additionally, it provides a list of related courses and references for further exploration.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.