
Qmedia
An open-source AI content search engine designed specifically for content creators. Supports extraction of text, images, and short videos. Allows full local deployment (web app, RAG server, LLM server). Supports multi-modal RAG content Q&A.
Stars: 537
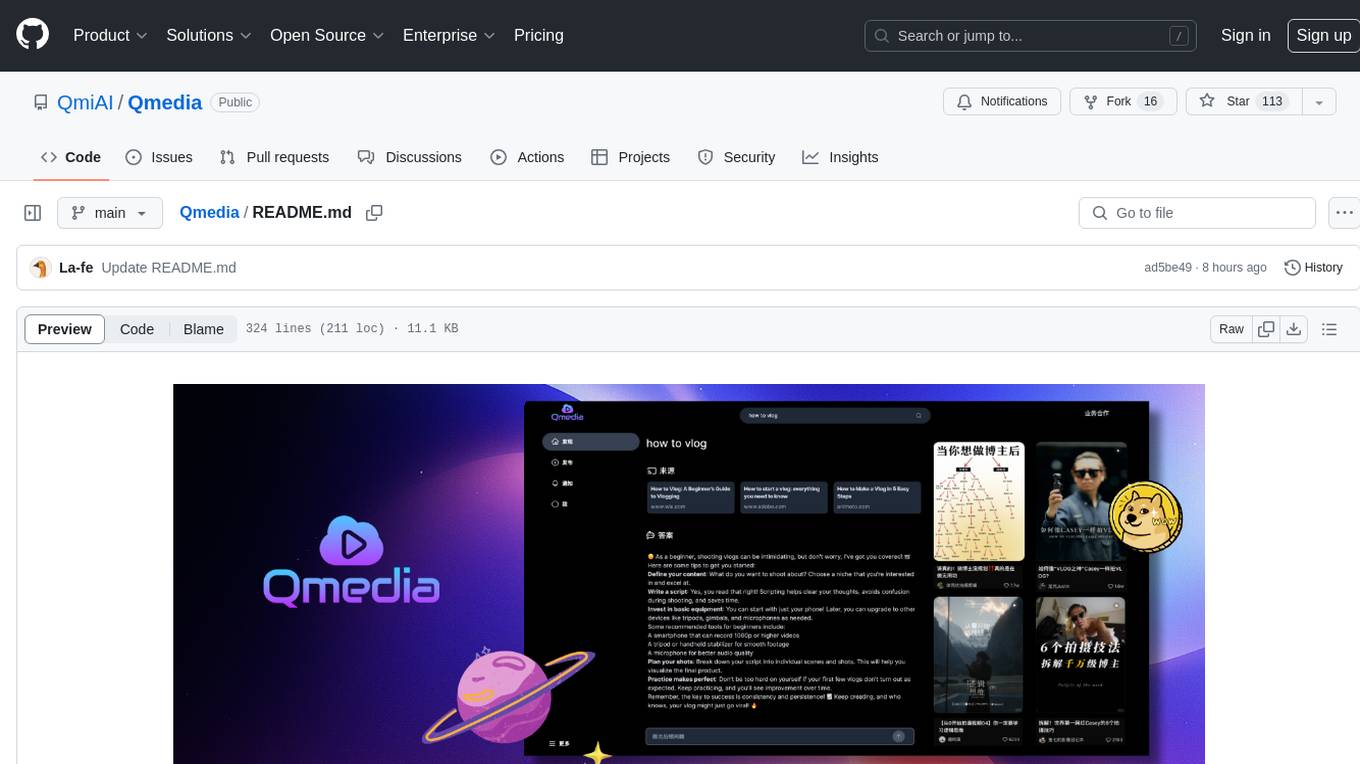
QMedia is an open-source multimedia AI content search engine designed specifically for content creators. It provides rich information extraction methods for text, image, and short video content. The tool integrates unstructured text, image, and short video information to build a multimodal RAG content Q&A system. Users can efficiently search for image/text and short video materials, analyze content, provide content sources, and generate customized search results based on user interests and needs. QMedia supports local deployment for offline content search and Q&A for private data. The tool offers features like content cards display, multimodal content RAG search, and pure local multimodal models deployment. Users can deploy different types of models locally, manage language models, feature embedding models, image models, and video models. QMedia aims to spark new ideas for content creation and share AI content creation concepts in an open-source manner.
README:


- Search for image/text and short video materials.
- Efficiently analyze image/text and short video content, integrating scattered information.
- Provide content sources and decompose image/text and short video information, presenting information through content cards.
- Generate customized search results based on user interests and needs from image/text and short video content.
- Local deployment, enabling offline content search and Q&A for private data.
Directory
QMedia is an open-source multimedia AI content search engine , provides rich information extraction methods for text/image and short video content. It integrates unstructured text/image and short video information to build a multimodal RAG content Q&A system. The aim is to share and exchange ideas on AI content creation in an open-source manner. issues
Share QMedia with your friends.
Spark new ideas for content creation
 |
Join our Discord community! |
|---|---|
 |
Join our WeChat group ! |
-
- Display image/text and video content in the form of cards
-
Web Serviceinspired by XHS web version, implemented using the technology stack of Typescript, Next.js, TailwindCSS, and Shadcn/UI -
RAG Search/Q&A ServiceandImage/Text/Video Model Serviceimplemented using the Python framework and LlamaIndex applications - Web Service,
RAG Search/Q&A Service, andImage/Text/Video Model Servicecan be deployed separately for flexible deployment based on user resources, and can be embedded into other systems for image/text and video content extraction.

-
- Search for image/text and short video materials.
- Extract useful information from image/text and short video content based on user queries to generate high-quality answers.
- Present content sources and the breakdown of image/text and short video information through content cards.
- Retrieval and Q&A rely on the breakdown of image/text and short video content, including image style, text layout, short video transcription, video summaries, etc.
- Support Google content search.

-
Deployment of various types of models locally Separation from the RAG application layer, making it easy to replace different models Local model lifecycle management, configurable for manual or automatic release to reduce server load
Language Models:
- Support local Ollama model switching.
- llama3:8b-instruct Lightweight local deployment of LLM models.
- llama3:70b-instruct Eighth place in open-source LLM models.
Feature Embedding Models:
- Image Embedding: CLIP Encoder Convert images to text feature encoding.
- Text Embedding: BGE Encoder Multilingual embedded model, converting text to feature encoding, with local models aligned to GPT Encoder.
Image Models:
- Image Text OCR Recognition: Qanything Local Knowledge Base Q&A System OCR
-
Visual Understanding Models:
- [ ] llava-llama3: Ollama's locally deployed GPT-4V level visual understanding model.
Video Models
- Video Transcription:
- Faster Whisper: Quickly extract video transcription content, can run on local CPU.
- LLM-based Short Video Content Summarization
- [ ] Identification of highlights in short videos
- [ ] Recognition of short video style types
- [ ] Analysis and breakdown of short video content
- Support local Ollama model switching.
- [ ] Image/Text Short Video Content Analysis and Viral Content Breakdown
- [ ] Search for Similar Image/Text/Video
- [ ] Card Image/Text Content Generation
- [ ] Short Video Content Editing
QMedia services: Depending on resource availability, they can be deployed locally or the model services can be deployed in the cloud
-
Multimodal Model Service
mm_server:-
Multimodal model deployment and API calls
-
Ollama LLM models
-
Image models
-
Video models
-
Feature embedding models
-
-
Content Search and Q&A Service
mmrag_server:-
Content Card Display and Query
-
Image/Text/Short Video Content Extraction, Embedding, and Storage Service
-
Multimodal Data RAG Retrieval Service
-
Content Q&A Service
-
- Web Service
qmedia_web: Language: TypeScript Framework: Next.js Styling: Tailwind CSS Components: shadcn/ui
mm_server + qmedia_web + mmrag_server
Web Page Content Display, Content RAG Search and Q&A, Model Service
- Service Startup Process:
# Start mm_server service
cd mm_server
source activate qllm
python main.py
# Start mmrag_server service
cd mmrag_server
source activate qmedia
python main.py
# Start qmedia_web service
cd qmedia_web
pnpm dev- Using Functions via the Web Page
During the startup phase,
mmrag_serverwill read pseudo data fromassets/mediasandassets/mm_pseudo_data.json, and callmm_serverto extract and structure the information from text/image and short videos intonodeinformation, which is then stored in thedb. The retrieval and Q&A will be based on the data in thedb.
# assets file structure
assets
├── mm_pseudo_data.json # Content card data
└── medias # Image/Video filesReplace the contents in assets and delete the historically stored db file.
assets/medias contains image/video files, which can be replaced with your own image/video files.
assets/mm_pseudo_data.json contains content card data, which can be replaced with your own content card data. After running the service, the model will automatically extract the information and store it in the db.
Can use the mm_server local image/text/video information extraction service independently.
It can be used as a standalone image encoding, text encoding, video transcription extraction, and image OCR service, accessible via API in any scenario.
# Start mm_server service independently
cd mm_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110API Content:

Can use mm_server + qmedia_web together to perform content extraction and RAG retrieval in a pure Python environment via APIs.
# Start mmrag_server service independently
cd mmrag_server
python main.py
# uvicorn main:app --reload --host localhost --port 50110API Content:

QMedia is licensed under MIT License
Thanks to QAnything for strong OCR models.
Thanks to llava-llama3 for strong llm vision models.
Thanks to Ghibli Image Generator for api support.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Qmedia
Similar Open Source Tools
Qmedia
QMedia is an open-source multimedia AI content search engine designed specifically for content creators. It provides rich information extraction methods for text, image, and short video content. The tool integrates unstructured text, image, and short video information to build a multimodal RAG content Q&A system. Users can efficiently search for image/text and short video materials, analyze content, provide content sources, and generate customized search results based on user interests and needs. QMedia supports local deployment for offline content search and Q&A for private data. The tool offers features like content cards display, multimodal content RAG search, and pure local multimodal models deployment. Users can deploy different types of models locally, manage language models, feature embedding models, image models, and video models. QMedia aims to spark new ideas for content creation and share AI content creation concepts in an open-source manner.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.

aderyn
Aderyn is a powerful Solidity static analyzer designed to help protocol engineers and security researchers find vulnerabilities in Solidity code bases. It provides off-the-shelf support for Foundry and Hardhat projects, allows for custom frameworks through a configuration file, and generates reports in Markdown, JSON, and Sarif formats. Users can install Aderyn using Cyfrinup, curl, Homebrew, or npm, and quickly identify vulnerabilities in their Solidity code. The tool also offers a VS Code extension for seamless integration with the IDE.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.
llama-assistant
Llama Assistant is an AI-powered assistant that helps with daily tasks, such as voice recognition, natural language processing, summarizing text, rephrasing sentences, answering questions, and more. It runs offline on your local machine, ensuring privacy by not sending data to external servers. The project is a work in progress with regular feature additions.

easy-dataset
Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.
Free-GPT4-WEB-API
FreeGPT4-WEB-API is a Python server that allows you to have a self-hosted GPT-4 Unlimited and Free WEB API, via the latest Bing's AI. It uses Flask and GPT4Free libraries. GPT4Free provides an interface to the Bing's GPT-4. The server can be configured by editing the `FreeGPT4_Server.py` file. You can change the server's port, host, and other settings. The only cookie needed for the Bing model is `_U`.
llama-assistant
Llama Assistant is a local AI assistant that respects your privacy. It is an AI-powered assistant that can recognize your voice, process natural language, and perform various actions based on your commands. It can help with tasks like summarizing text, rephrasing sentences, answering questions, writing emails, and more. The assistant runs offline on your local machine, ensuring privacy by not sending data to external servers. It supports voice recognition, natural language processing, and customizable UI with adjustable transparency. The project is a work in progress with new features being added regularly.
educhain
Educhain is a powerful Python package that leverages Generative AI to create engaging and personalized educational content. It enables users to generate multiple-choice questions, create lesson plans, and support various LLM models. Users can export questions to JSON, PDF, and CSV formats, customize prompt templates, and generate questions from text, PDF, URL files, youtube videos, and images. Educhain outperforms traditional methods in content generation speed and quality. It offers advanced configuration options and has a roadmap for future enhancements, including integration with popular Learning Management Systems and a mobile app for content generation on-the-go.
LongLLaVA
LongLLaVA is a tool for scaling multi-modal LLMs to 1000 images efficiently via hybrid architecture. It includes stages for single-image alignment, instruction-tuning, and multi-image instruction-tuning, with evaluation through a command line interface and model inference. The tool aims to achieve GPT-4V level capabilities and beyond, providing reproducibility of results and benchmarks for efficiency and performance.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.

DB-GPT
DB-GPT is a personal database administrator that can solve database problems by reading documents, using various tools, and writing analysis reports. It is currently undergoing an upgrade. **Features:** * **Online Demo:** * Import documents into the knowledge base * Utilize the knowledge base for well-founded Q&A and diagnosis analysis of abnormal alarms * Send feedbacks to refine the intermediate diagnosis results * Edit the diagnosis result * Browse all historical diagnosis results, used metrics, and detailed diagnosis processes * **Language Support:** * English (default) * Chinese (add "language: zh" in config.yaml) * **New Frontend:** * Knowledgebase + Chat Q&A + Diagnosis + Report Replay * **Extreme Speed Version for localized llms:** * 4-bit quantized LLM (reducing inference time by 1/3) * vllm for fast inference (qwen) * Tiny LLM * **Multi-path extraction of document knowledge:** * Vector database (ChromaDB) * RESTful Search Engine (Elasticsearch) * **Expert prompt generation using document knowledge** * **Upgrade the LLM-based diagnosis mechanism:** * Task Dispatching -> Concurrent Diagnosis -> Cross Review -> Report Generation * Synchronous Concurrency Mechanism during LLM inference * **Support monitoring and optimization tools in multiple levels:** * Monitoring metrics (Prometheus) * Flame graph in code level * Diagnosis knowledge retrieval (dbmind) * Logical query transformations (Calcite) * Index optimization algorithms (for PostgreSQL) * Physical operator hints (for PostgreSQL) * Backup and Point-in-time Recovery (Pigsty) * **Continuously updated papers and experimental reports** This project is constantly evolving with new features. Don't forget to star ⭐ and watch 👀 to stay up to date.

gpustack
GPUStack is an open-source GPU cluster manager designed for running large language models (LLMs). It supports a wide variety of hardware, scales with GPU inventory, offers lightweight Python package with minimal dependencies, provides OpenAI-compatible APIs, simplifies user and API key management, enables GPU metrics monitoring, and facilitates token usage and rate metrics tracking. The tool is suitable for managing GPU clusters efficiently and effectively.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.
For similar tasks

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.
Awesome-AI
Awesome AI is a repository that collects and shares resources in the fields of large language models (LLM), AI-assisted programming, AI drawing, and more. It explores the application and development of generative artificial intelligence. The repository provides information on various AI tools, models, and platforms, along with tutorials and web products related to AI technologies.
Qmedia
QMedia is an open-source multimedia AI content search engine designed specifically for content creators. It provides rich information extraction methods for text, image, and short video content. The tool integrates unstructured text, image, and short video information to build a multimodal RAG content Q&A system. Users can efficiently search for image/text and short video materials, analyze content, provide content sources, and generate customized search results based on user interests and needs. QMedia supports local deployment for offline content search and Q&A for private data. The tool offers features like content cards display, multimodal content RAG search, and pure local multimodal models deployment. Users can deploy different types of models locally, manage language models, feature embedding models, image models, and video models. QMedia aims to spark new ideas for content creation and share AI content creation concepts in an open-source manner.
aws-ai-intelligent-document-processing
This repository is part of Intelligent Document Processing with AWS AI Services workshop. It aims to automate the extraction of information from complex content in various document formats such as insurance claims, mortgages, healthcare claims, contracts, and legal contracts using AWS Machine Learning services like Amazon Textract and Amazon Comprehend. The repository provides hands-on labs to familiarize users with these AI services and build solutions to automate business processes that rely on manual inputs and intervention across different file types and formats.
Scrapegraph-LabLabAI-Hackathon
ScrapeGraphAI is a web scraping Python library that utilizes LangChain, LLM, and direct graph logic to create scraping pipelines. Users can specify the information they want to extract, and the library will handle the extraction process. The tool is designed to simplify web scraping tasks by providing a streamlined and efficient approach to data extraction.
parsera
Parsera is a lightweight Python library designed for scraping websites using LLMs. It offers simplicity and efficiency by minimizing token usage, enhancing speed, and reducing costs. Users can easily set up and run the tool to extract specific elements from web pages, generating JSON output with relevant data. Additionally, Parsera supports integration with various chat models, such as Azure, expanding its functionality and customization options for web scraping tasks.
Scrapegraph-demo
ScrapeGraphAI is a web scraping Python library that utilizes LangChain, LLM, and direct graph logic to create scraping pipelines. Users can specify the information they want to extract, and the library will handle the extraction process. This repository contains an official demo/trial for the ScrapeGraphAI library, showcasing its capabilities in web scraping tasks. The tool is designed to simplify the process of extracting data from websites by providing a user-friendly interface and powerful scraping functionalities.

you2txt
You2Txt is a tool developed for the Vercel + Nvidia 2-hour hackathon that converts any YouTube video into a transcribed .txt file. The project won first place in the hackathon and is hosted at you2txt.com. Due to rate limiting issues with YouTube requests, it is recommended to run the tool locally. The project was created using Next.js, Tailwind, v0, and Claude, and can be built and accessed locally for development purposes.
For similar jobs
luna-ai
Luna AI is a virtual streamer driven by a 'brain' composed of ChatterBot, GPT, Claude, langchain, chatglm, text-generation-webui, 讯飞星火, 智谱AI. It can interact with viewers in real-time during live streams on platforms like Bilibili, Douyin, Kuaishou, Douyu, or chat with you locally. Luna AI uses natural language processing and text-to-speech technologies like Edge-TTS, VITS-Fast, elevenlabs, bark-gui, VALL-E-X to generate responses to viewer questions and can change voice using so-vits-svc, DDSP-SVC. It can also collaborate with Stable Diffusion for drawing displays and loop custom texts. This project is completely free, and any identical copycat selling programs are pirated, please stop them promptly.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.
Qmedia
QMedia is an open-source multimedia AI content search engine designed specifically for content creators. It provides rich information extraction methods for text, image, and short video content. The tool integrates unstructured text, image, and short video information to build a multimodal RAG content Q&A system. Users can efficiently search for image/text and short video materials, analyze content, provide content sources, and generate customized search results based on user interests and needs. QMedia supports local deployment for offline content search and Q&A for private data. The tool offers features like content cards display, multimodal content RAG search, and pure local multimodal models deployment. Users can deploy different types of models locally, manage language models, feature embedding models, image models, and video models. QMedia aims to spark new ideas for content creation and share AI content creation concepts in an open-source manner.
ai-shifu
AI-Shifu is an AI-led chat flow tool powered by LLM that provides an interactive and immersive experience for users. It allows users to follow a preset chat flow while being able to ask questions and affect the conversation. The tool can make personalized outputs based on user identity, interests, and preferences, making users feel like they are receiving one-on-one service. It is suitable for education, storytelling, product guides, surveys, and game NPC scenarios.
saga
SAGA is a novel-writing system that leverages a knowledge graph and specialized agents to autonomously create and refine stories. It handles complex narrative structures while maintaining coherence and consistency. Features include a Knowledge Graph using Neo4j, Modular Agent Architecture, LLM Integration, Configurable Generation Parameters, Robust Testing Framework, Code Quality enforcement, Vector Search, and Agentic Planning. The system structure includes components for specialized agents, core components, data access, documentation, initialization scripts, Pydantic models, output directory, orchestrator logic, text processing tools, UI components, utility functions, and more.
sora-prompt
Sora Prompt Collection is a repository dedicated to inspiring AI-driven video creation with Sora, an AI model that can create realistic and imaginative scenes from text instructions. The repository provides prompt words and video generation tips to help users quickly start using Sora for text-to-video, animation, video editing, image generation, and more. It offers a variety of examples ranging from stylish urban scenes to fantastical creatures in vibrant settings. Users can find prompt examples based on different video styles and modify them as needed.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.