
you2txt
Turn any YouTube video into a txt file for your LLM training. First place in the NVIDIA + Vercel Hackathon 🥇.
Stars: 71

You2Txt is a tool developed for the Vercel + Nvidia 2-hour hackathon that converts any YouTube video into a transcribed .txt file. The project won first place in the hackathon and is hosted at you2txt.com. Due to rate limiting issues with YouTube requests, it is recommended to run the tool locally. The project was created using Next.js, Tailwind, v0, and Claude, and can be built and accessed locally for development purposes.
README:

I built You2Txt for the Vercel + Nvidia 2-hour hackathon. It turns any YouTube video into a transcribed .txt file.
This project won first place in the hackathon 🏆
It's hosted at you2txt.com. However, YouTube has been rate limiting requests coming from the lambda, so if you want to use it, you'll have more luck running it locally.
If there's interest, maybe I can set up a self-hosted proxy or raspberry pi for the requests (until that inevitably gets rate limited).
This project was made with Next.js, Tailwind (shadcn), v0, and Claude (through Cursor's composer).
yarnyarn devyarn buildThen open http://localhost:3000
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for you2txt
Similar Open Source Tools
you2txt
You2Txt is a tool developed for the Vercel + Nvidia 2-hour hackathon that converts any YouTube video into a transcribed .txt file. The project won first place in the hackathon and is hosted at you2txt.com. Due to rate limiting issues with YouTube requests, it is recommended to run the tool locally. The project was created using Next.js, Tailwind, v0, and Claude, and can be built and accessed locally for development purposes.
clippinator
Clippinator is a code assistant tool that helps users develop code autonomously by planning, writing, debugging, and testing projects. It consists of agents based on GPT-4 that work together to assist the user in coding tasks. The main agent, Taskmaster, delegates tasks to specialized subagents like Architect, Writer, Frontender, Editor, QA, and Devops. The tool provides project architecture, tools for file and terminal operations, browser automation with Selenium, linting capabilities, CI integration, and memory management. Users can interact with the tool to provide feedback and guide the coding process, making it a powerful tool when combined with human intervention.
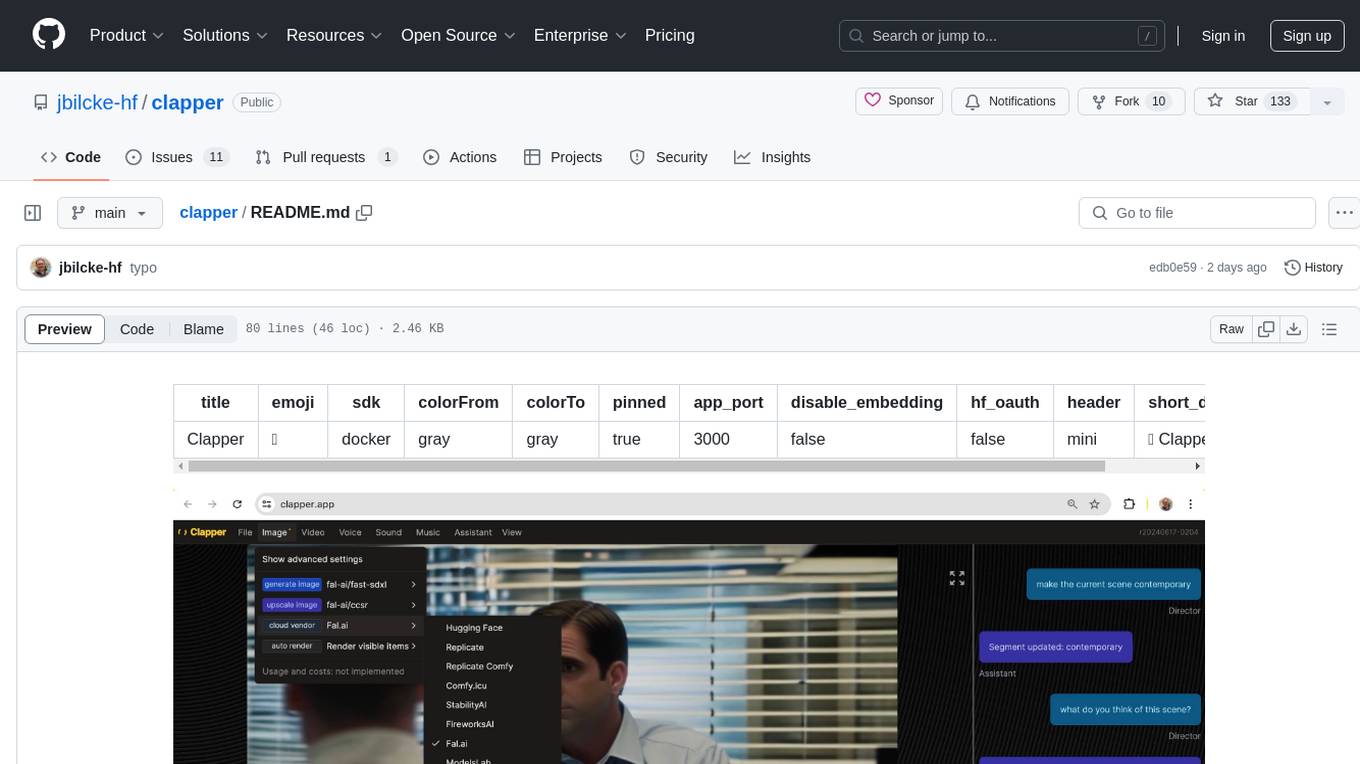
clapper
Clapper is an open-source AI story visualization tool that can interpret screenplays and render them into storyboards, videos, voice, sound, and music. It is currently in early development stages and not recommended for general use due to some non-functional features and lack of tutorials. A public alpha version is available on Hugging Face's platform. Users can sponsor specific features through bounties and developers can contribute to the project under the GPL v3 license. The tool lacks automated tests and code conventions like Prettier or a Linter.
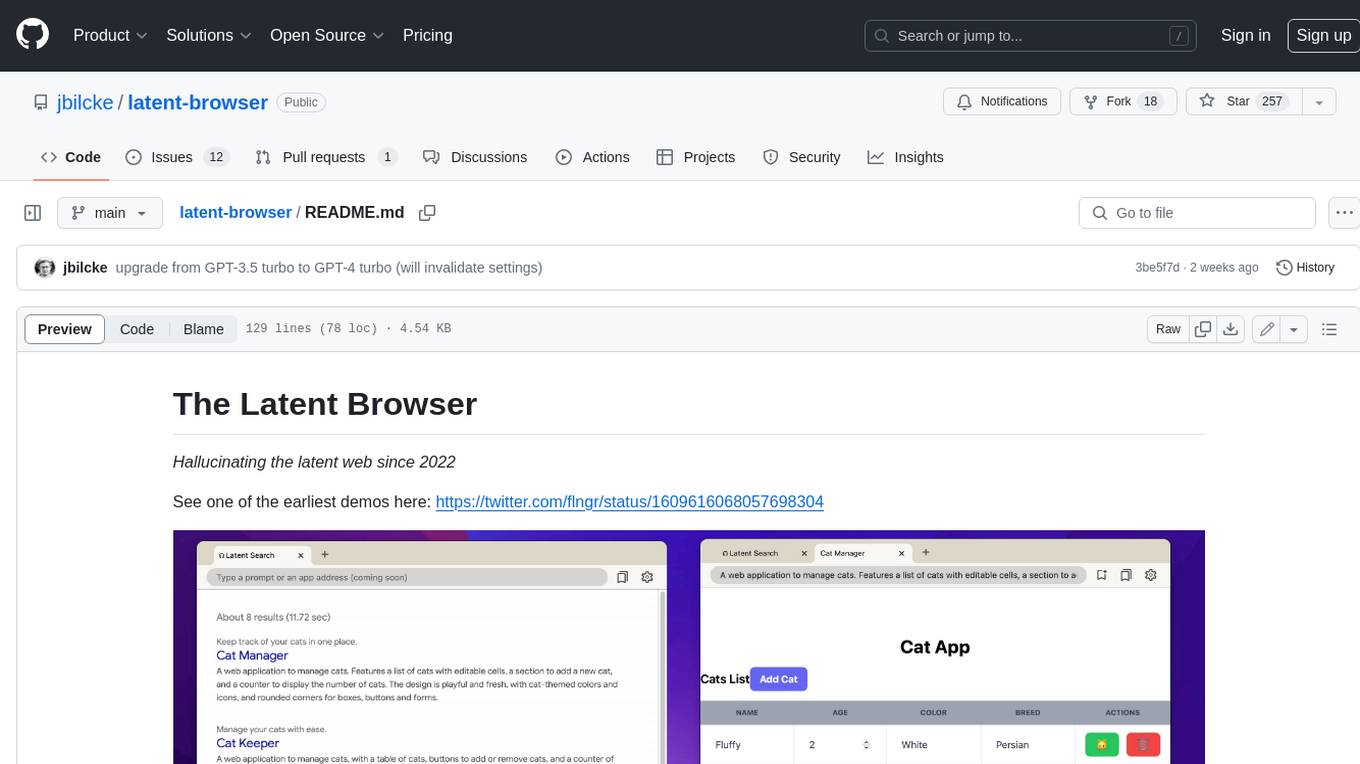
latent-browser
The Latent Browser is a desktop application designed like a web browser, which hallucinates web search results (the resultds are fictious and are generated by a LLM) and web pages. It is a web application designed to run locally on your machine and is 99% React, Tailwind, TypeScript, and NextJS. The runtime is Tauri, which is written in Rust. The Latent Browser is still under development and some things may be broken when you try it.
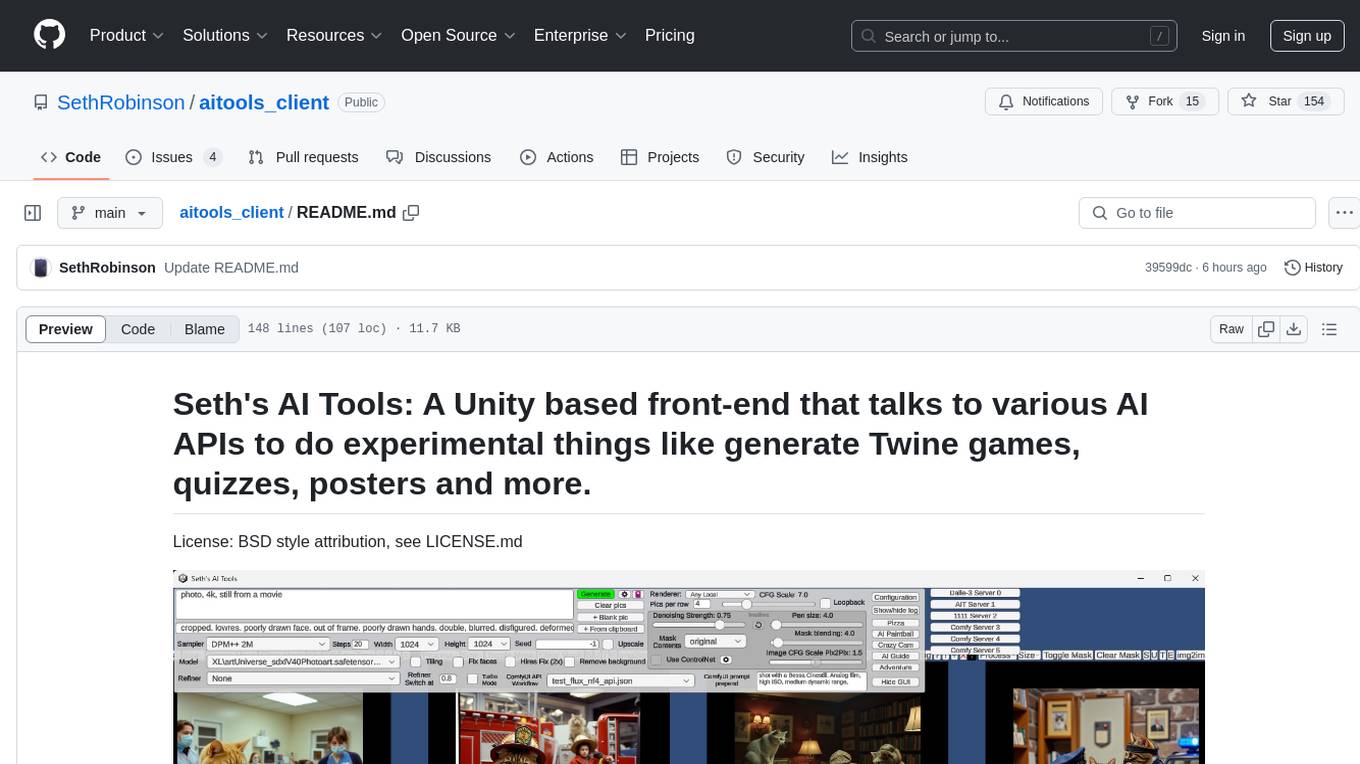
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.

sdk
Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.
lumentis
Lumentis is a tool that allows users to generate beautiful and comprehensive documentation from meeting transcripts and large documents with a single command. It reads transcripts, asks questions to understand themes and audience, generates an outline, and creates detailed pages with visual variety and styles. Users can switch models for different tasks, control the process, and deploy the generated docs to Vercel. The tool is designed to be open, clean, fast, and easy to use, with upcoming features including folders, PDFs, auto-transcription, website scraping, scientific papers handling, summarization, and continuous updates.
AI-Writing-Assistant
DeepWrite AI is an AI writing assistant tool created with the help of ChatGPT3. It is designed to generate perfect blog posts with utmost clarity. The tool is currently at version 1.0 with plans for further improvements. It is an open-source project, welcoming contributions. An extension has been developed for using the tool directly in Notepad, currently supported only on Calmly Writer. The tool requires installation and setup, utilizing technologies like React, Next, TailwindCSS, Node, and Express. For support, users can message the creator on Instagram. The creator, Sabir Khan, is an undergraduate student of Computer Science from Mumbai, known for frequently creating innovative projects.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
karakeep
Karakeep is a self-hostable bookmark-everything app with a touch of AI for data hoarders. It allows users to bookmark links, take notes, store images and pdfs, and offers features like automatic fetching, full-text search, AI-based tagging, OCR, rule-based engine, Chrome plugin, Firefox addon, iOS and Android apps, auto hoarding from RSS feeds, REST API, multi-language support, and more. The app is under heavy development and aims to provide a self-hosting first solution for managing bookmarks and content.
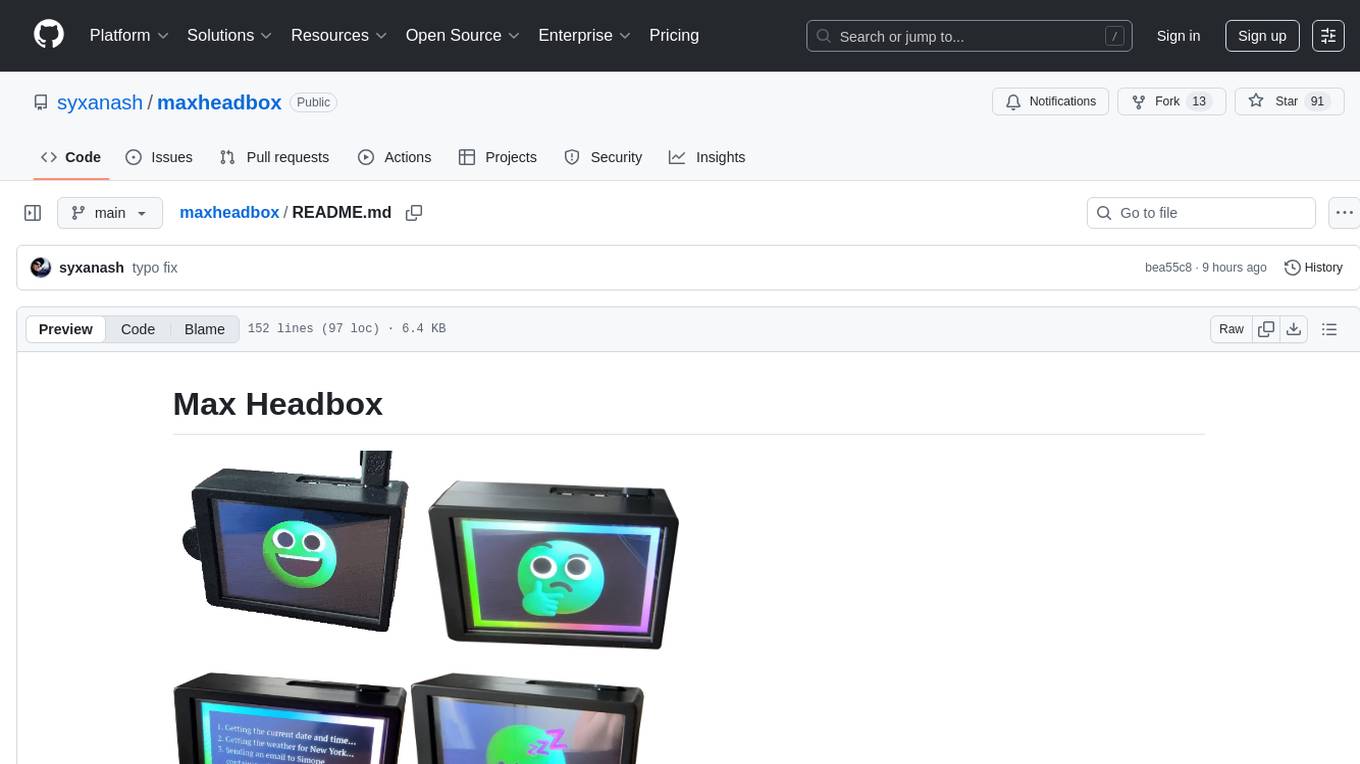
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.
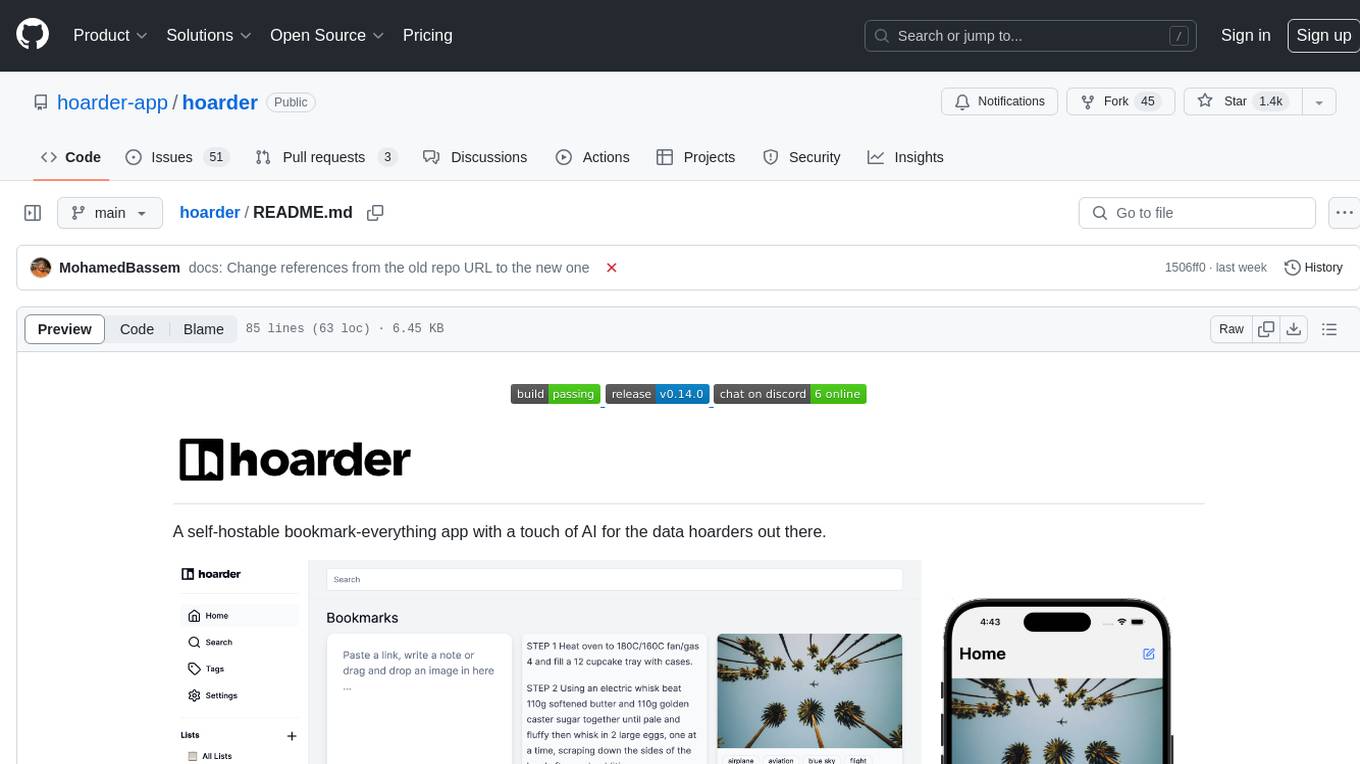
hoarder
A self-hostable bookmark-everything app with a touch of AI for data hoarders. Features include bookmarking links, taking notes, storing images, automatic fetching for link details, full-text search, AI-based automatic tagging, Chrome and Firefox plugins, iOS and Android apps, dark mode support, and self-hosting. Built to address the need for archiving and previewing links with automatic tagging. Developed by a systems engineer to stay connected with web development and cater to personal use cases.
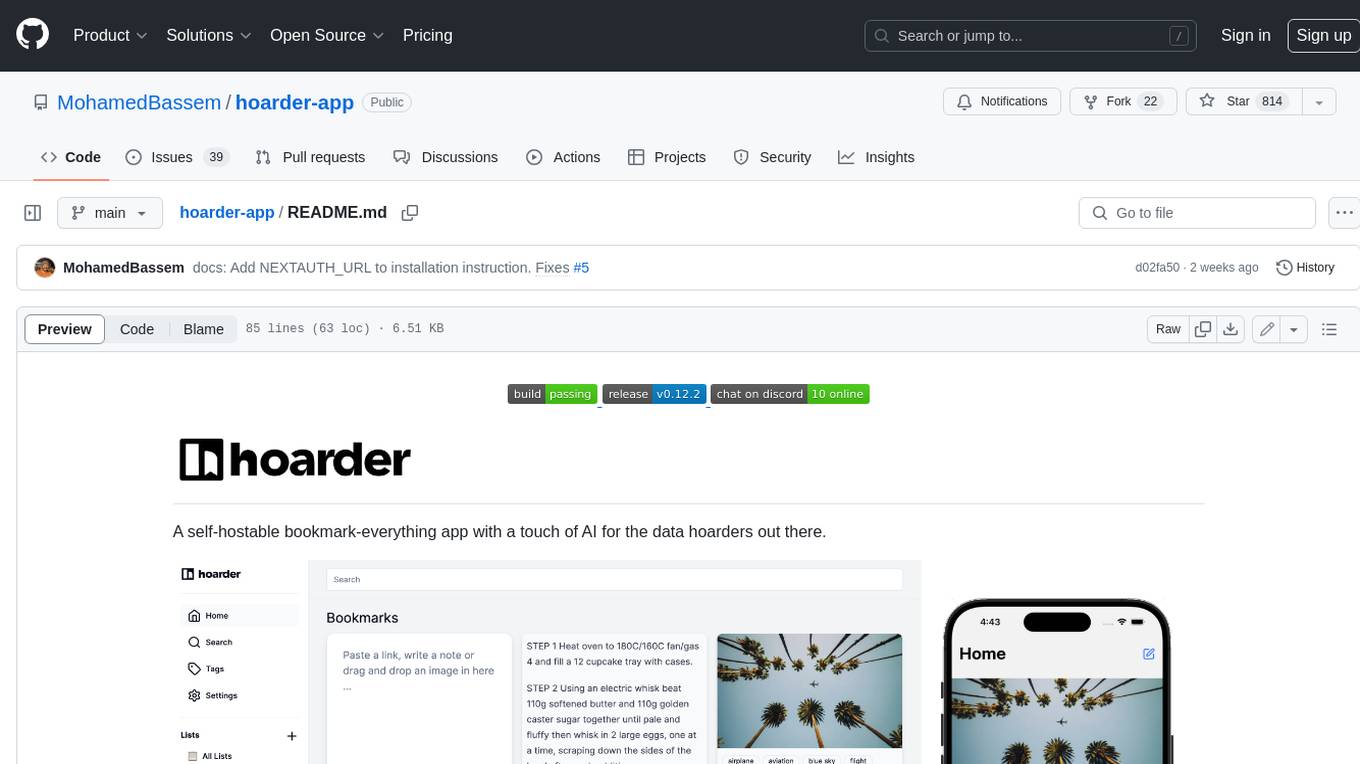
hoarder-app
Hoarder is a self-hostable bookmark manager with a focus on privacy and customization. It features automatic link previews, full-text search, AI-based tagging, and a variety of import and export options. Hoarder is designed to be easy to use and extensible, with a plugin system that allows users to add their own features and integrations.
For similar tasks

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.
Awesome-AI
Awesome AI is a repository that collects and shares resources in the fields of large language models (LLM), AI-assisted programming, AI drawing, and more. It explores the application and development of generative artificial intelligence. The repository provides information on various AI tools, models, and platforms, along with tutorials and web products related to AI technologies.
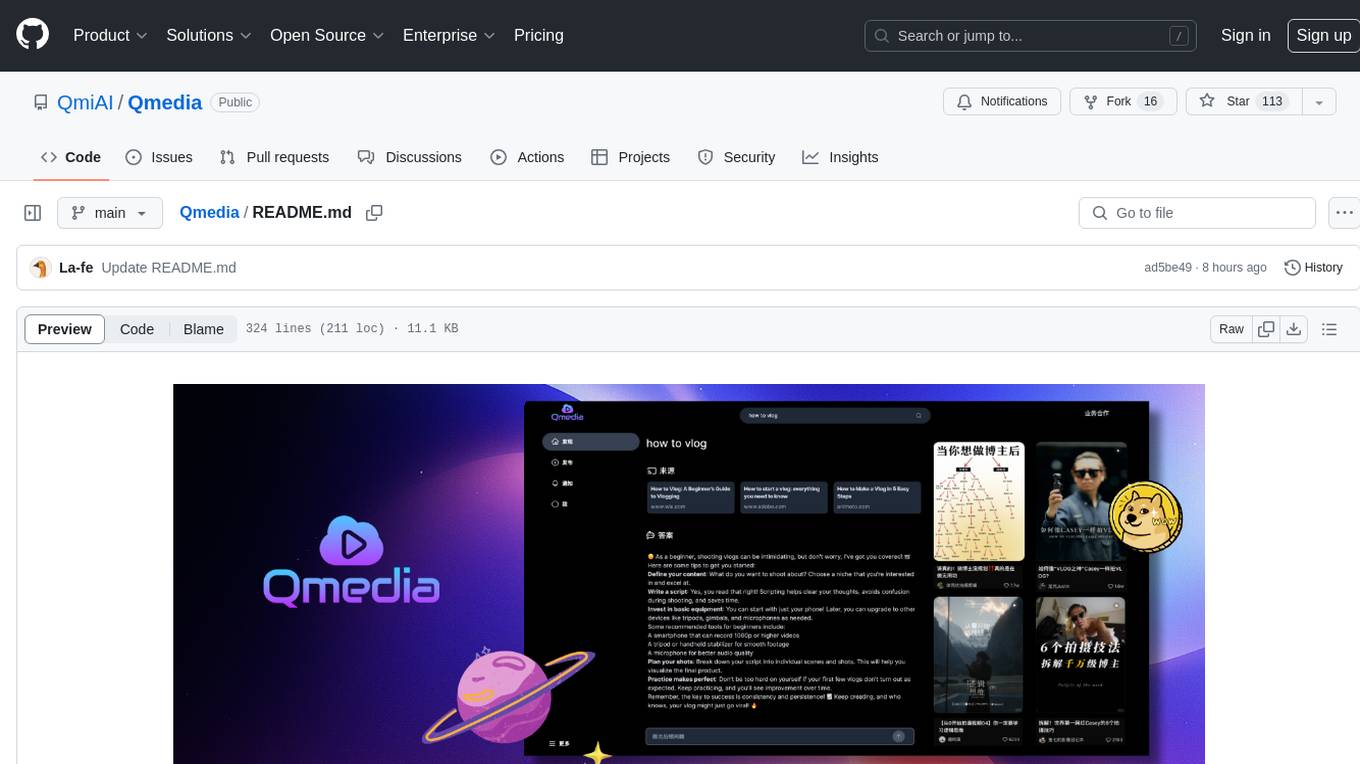
Qmedia
QMedia is an open-source multimedia AI content search engine designed specifically for content creators. It provides rich information extraction methods for text, image, and short video content. The tool integrates unstructured text, image, and short video information to build a multimodal RAG content Q&A system. Users can efficiently search for image/text and short video materials, analyze content, provide content sources, and generate customized search results based on user interests and needs. QMedia supports local deployment for offline content search and Q&A for private data. The tool offers features like content cards display, multimodal content RAG search, and pure local multimodal models deployment. Users can deploy different types of models locally, manage language models, feature embedding models, image models, and video models. QMedia aims to spark new ideas for content creation and share AI content creation concepts in an open-source manner.
aws-ai-intelligent-document-processing
This repository is part of Intelligent Document Processing with AWS AI Services workshop. It aims to automate the extraction of information from complex content in various document formats such as insurance claims, mortgages, healthcare claims, contracts, and legal contracts using AWS Machine Learning services like Amazon Textract and Amazon Comprehend. The repository provides hands-on labs to familiarize users with these AI services and build solutions to automate business processes that rely on manual inputs and intervention across different file types and formats.
Scrapegraph-LabLabAI-Hackathon
ScrapeGraphAI is a web scraping Python library that utilizes LangChain, LLM, and direct graph logic to create scraping pipelines. Users can specify the information they want to extract, and the library will handle the extraction process. The tool is designed to simplify web scraping tasks by providing a streamlined and efficient approach to data extraction.
parsera
Parsera is a lightweight Python library designed for scraping websites using LLMs. It offers simplicity and efficiency by minimizing token usage, enhancing speed, and reducing costs. Users can easily set up and run the tool to extract specific elements from web pages, generating JSON output with relevant data. Additionally, Parsera supports integration with various chat models, such as Azure, expanding its functionality and customization options for web scraping tasks.
Scrapegraph-demo
ScrapeGraphAI is a web scraping Python library that utilizes LangChain, LLM, and direct graph logic to create scraping pipelines. Users can specify the information they want to extract, and the library will handle the extraction process. This repository contains an official demo/trial for the ScrapeGraphAI library, showcasing its capabilities in web scraping tasks. The tool is designed to simplify the process of extracting data from websites by providing a user-friendly interface and powerful scraping functionalities.
you2txt
You2Txt is a tool developed for the Vercel + Nvidia 2-hour hackathon that converts any YouTube video into a transcribed .txt file. The project won first place in the hackathon and is hosted at you2txt.com. Due to rate limiting issues with YouTube requests, it is recommended to run the tool locally. The project was created using Next.js, Tailwind, v0, and Claude, and can be built and accessed locally for development purposes.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.