
kobold_assistant
Like ChatGPT's voice conversations with an AI, but entirely offline/private/trade-secret-friendly, using local AI models such as LLama 2 and Whisper
Stars: 125
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
README:
NOTE: This was a fun project in the early ChatGPT days. Now, it's outdated. I'd recommend looking at open-webui + llama.cpp + openedai-speech.
A fully offline voice assistant interface to KoboldAI's large language model API. Can probably also work online with the KoboldAI horde and online speech-to-text and text-to-speech models, if you really want it to.
It's reasonably good; at least as good as Amazon Alexa, if not better. It uses the latest coqui "jenny" text to speech model, and openAI's whisper speech recognition, and additionally the model is prompted to know that it's getting text through speech recognition, so is cautious and clarifies if it's not sure what was heard. Unfortunately it has been known to go meta and suggest that you to adjust your microphone! ;)
The assistant is called Jenny by default, per the speech model.
You can tweak the assistant name, speech-to-text model, text-to-speech model, prompts, etc. through configuration, though the config system needs more work to be user-friendly and future-proof.
We have a channel on the Kobold-AI server. Please try to file real bugs and requests on github instead, but this is a good place to initially discuss possible bugs, chat about ideas, etc. https://discord.com/channels/849937185893384223/1110256272403599481
- Install as instructed below
- Make sure
KoboldAI(preferably) (a.k.a,KoboldAI-Client),KoboldCPPortext-generation-webuiare running, with a suitable LLM model loaded, and serving a KoboldAI compatible API athttp://localhost:5000/api/v1/generate(see Configuration, below, if you need to change this URL). See KoboldAI below, for a quickstart guide. - Run one or more of the commands below. If you get any errors about missing libraries, follow the instructions about that under Installation, below.
- Run
kobold-assistant serveafter installing. - Give it a while (at least a few minutes) to start up, especially the first time that you run it, as it downloads a few GB of AI models to do the text-to-speech and speech-to-text, and does some time-consuming generation work at startup, to save time later. It runs much more comfortably once it gets to the main conversational loop.
- While running, the system responds to special control commands. See Control Commands, below.
Run kobold-assistant list-mics to list available microphones that kobold-assistant can use, when listen for the user's instructions. See the Configuration and Troubleshooting sections below, for more details on list-mics and related settings.
- System packages:
- GCC (c compiler)
- portaudio development libraries
- ffmpeg
- KoboldAI, KoboldCPP, or text-generation-webui running locally
- For now, the only model known to work with this is stable-vicuna-13B-GPTQ. Any Alpaca-like or vicuna model will PROBABLY work. I'll add abstractions so that more models work, soon. Feel free to submit a PR with known-good models, or changes for multiple/other model support.
- Python >=3.7, <3.11
- Ubuntu/Debian
While running, there are two special commands that kobold-assistant responds to:
This tells the assistant to go to sleep (to stop listening) until a wake command is given (see below).
This tells the assistant to start listening again, after it has been told to go to sleep (see above).
-
On a Debian-like system (such as Debian, Ubuntu, Linux Mint, or Pop), run
apt-get install -y $(cat requirements.apt). For other distros, readrequirements.apt, figure out the equivalents for your distro (search your distro's packages), and ideally submit a PR with a similarrequirements.yourdistrofile and updatedREADME.mdfor your distro. -
On the first run, if you are missing portaudio or a C compiler, or if you have an nvidia CPU, you may find that you need a bunch of other packages or libraries, like nvidia's cudnn. These are required by third-party dependencies. Most are covered by the step above. Aside from that, just try to run it and install any missing libraries that it complains about per your distro instructions, and failing that, the nvidia instructions for your distro. If your distro isn't supported by nvidia, all bets are off -- you might be better running it as CPU-only.
I'll try tidy this up the dependency situation in future, using docker or something, so you don't have to worry about dependencies, and it "just works", but nvidia make you sign up to their website to get a few of them right now, so there's probably no easy answer at the moment. Sadly, I don't think this code will get away from any nvidia dependencies for a while.
- Download the
*.whlfile from the latest release on github (http://github.com/lee-b/kobold_assistant/) - Run
pip install *.whl.
To customize the configuration, run kobold_assistant default-config-path, and copy the the file at that path to ~/.config/kobold_assistant/settings.json, then edit it. You can also place config in /etc/kobold_assistant/settings.json.
The most important settings are as follows:
The KoboldAI API server endpoint, for generating text from a prompt using a large language model. Check the documentation and terminal output of KoboldAI-Client, KoboldCPP, Text-Generation-WebUI, or whichever other compatible server you're using.
The device number of the microphone to listen for instructions on.
Run kobold-assistant list-mics for a list. null means choose the default.
NOTE: The default (null) "should" auto-detect this for you; see the For now, see the SpeechRecognition library docs for details on exactly how this works.
Automatically determine the microphone volume based on ambient noise levels.
Energy level (mic volume) to use when NOT auto-calibrating (per above). Range is from 0 to 4000, with 1500 being reasonable for a well-calibrated mic.
Really, you should check the KoboldAI instructions, but as a quick guide to getting it running on Debian, Ubuntu, Linux Mint, Pop! OS, or similar Debian-based Linux distros, for the purposes of running this, here's how to do it, at present. No guarantees that this will continue to work.
ROUGH requirements (check the KoboldAI docs for better requirements): - nvidia card with CUDA and at least 12GB of Video RAM (VRAM) - A recent Debian-based distro - A GUI desktop session (this approach needs a browser)
NOTE: this is NOT the official KoboldAI version, but a development branch that supports 4bit quantized models. In future, it should be possible to use the official version instead, after this feature has been merged into it.
This example is for the lightest model to run, on machines with limited resources. See Known-good Models below, for other options, and adjust accordingly to your needs.
sudo apt-get update && sudo apt-get install -y nvidia-cuda-toolkit git git-lfs
git clone https://github.com/0cc4m/KoboldAI -b latestgptq --recurse-submodules
cd KoboldAI
./install_requirements.sh
cd KoboldAI/models
git clone https://huggingface.co/TheBloke/WizardLM-7B-uncensored-GPTQ TheBloke_WizardLM-7B-uncensored-GPTQ
cd TheBloke_WizardLM-7B-uncensored-GPTQ
ln -s WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors 4bit-128g.safetensors
cd ../..
./play.sh
- The final step, running
./play.sh, should launch your web browser. - In the browser, click
AI - Click
Load a model from its directory - Select the model that you cloned earlier,
stable-vicuna-13B-GPTQ - After selecting, some sliders appear at the bottom. Move the
GPU 0slider all the way to the right. NOTE: if this later fails to load, it's probably this slider that you need to change. Read the KoboldAI docs! - Click
Load. - If this loads load successfully, the Loading message should disappear within a minute or two at most.
- Now, in a separate terminal, run
kobold-assistant serve, per the docs above. stable-vicuna-13B-GPTQ-4bit.compat.no-act-order.safetensors 4bit-128g.safetensors
Any of these models will work. They're listed with the easiest model to run first, and the best (but more demanding) models last.
-
TheBloke_WizardLM-7B-uncensored-GPTQ- Should run within 8GB
- Obviously not as good as the more demanding models, but surprisingly similar to Alexa and other commercial offerings
- Run
ln -s WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors 4bit-128g.safetensorsin the model directory before attempting to load it.
-
TheBloke/stable-vicuna-13b- This should run in about 12GB
- Seems about equivalent to Alexa
- Run
ln -s stable-vicuna-13B-GPTQ-4bit.compat.no-act-order.safetensors 4bit-128g.safetensorsin the model directory before attempting to load it.
-
MetalX_GPT4-X-Alpasta-30b-4bit- This requires at least 24GB
- It's a capable, general model, which seems better than Alexa
- Run
ln -s gpt4-x-alpasta-30b-128g-4bit.safetensors 4bit-128g.safetensorsin the model directory before attempting to load it.
-
TheBloke/WizardLM-30B-Uncensored-GPTQ- This requires at least 24GB
- It's a capable, general model, which seems better than Alexa
- Run
ln -s WizardLM-30B-Uncensored-GPTQ-4bit.act-order.safetensors 4bit.safetensorsin the model directory before attempting to load it.
-
Any other 4bit, 128b safetensors llama-based model from huggingface should also work, using the above approaches.
-
TheBloke/vicuna-7b-1.1-GPTQ-4bit-128g- Seems to output ' \u200b' a lot, instead of a response.
To just use it, don't do this. See the installation instructions above! But, if you want to hack on this code:
- Install poetry per instructions
- Install and make default (via pyenv or whatever) python 3.9.16
- Run the following:
poetry build
poetry install
Now edit the files and poetry run kobold-assistant serve to test.
This is probably the speech recognition picking up environmental audio. Tell it to sleep and wake it later if you want it to not listen and respond, or else tune your microphone so that it doesn't pick up random environmental noises.
This is happens frequently right now, but is really just filler for the AI not responding with anything. Try rephrasing as instructed. Alternatively, you could avoid repeating yourself with an encouraging instruction like "Well, try your best."
This is a bug in the TTS library, if you press Ctrl-C while it's download a model because its downloads aren't atomic (it leaves half a download behind, then gets confused). To work around this, run rm -rf ~/.local/share/TTS, and it will download anew.
CHECK the MICROPHONE_DEVICE_INDEX setting. See Configuration, above.
This happens when the whisper text-to-speech model hallucinates, and kobold-assistant notices. Essentially, it just means that the text-to-speech model misheard you, or only heard noise and made a guess. Check the MICROPHONE_DEVICE_INDEX setting (or it may be listening for audio on a device that's not producing any audio!). Check your microphone settings (such as the microphone volume and noise cancellation options), and generally ensure that your microphone works: that it's not too quiet or too loud, and so on. OR, just try again: kobold-assistant will try to recover from this and just go on as if you didn't say anything yet. If this happens every time, though, you have a configuration issue.
There may be other hallucinations (random text detected that you didn't actually say) that whisper generates, that aren't currently detected. If you encounter any others, please file a PR or bug report. However, sometimes it will just mishear what you say; that much is normal. Try to perfect your microphone settings, and enunciate as clearly as you can.
WARNING:root:Speech-to-text engine failed to recognise audio, with error RuntimeError('cuDNN error: CUDNN_STATUS_INTERNAL_ERROR'). Retrying.
or:
WARNING:root:Speech-to-text engine failed to recognise audio, with error RuntimeError('GET was unable to find an engine to execute this computation'). Retrying.
I believe either of these warnings is your GPU running out of VRAM (or some other resource) that a model needs. Try allocating the layers differently in KoboldAI, setting CUDA_VISIBLE_DEVICES to allocate cards differently if you have multiple GPUs, changing the models used in kobold-assistant settings for speech-to-text and text-to-speech, or if all else fails, you may need to upgrade your system or buy/rent a different system.
- Submit a ticket! Just please try to be clear about what the problem is. See: https://www.mediawiki.org/wiki/How_to_report_a_bug for instance.
Pull requests welcome - don't be shy :)
- Lee Braiden [email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kobold_assistant
Similar Open Source Tools
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
whisper_dictation
Whisper Dictation is a fast, offline, privacy-focused tool for voice typing, AI voice chat, voice control, and translation. It allows hands-free operation, launching and controlling apps, and communicating with OpenAI ChatGPT or a local chat server. The tool also offers the option to speak answers out loud and draw pictures. It includes client and server versions, inspired by the Star Trek series, and is designed to keep data off the internet and confidential. The project is optimized for dictation and translation tasks, with voice control capabilities and AI image generation using stable-diffusion API.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
AlwaysReddy
AlwaysReddy is a simple LLM assistant with no UI that you interact with entirely using hotkeys. It can easily read from or write to your clipboard, and voice chat with you via TTS and STT. Here are some of the things you can use AlwaysReddy for: - Explain a new concept to AlwaysReddy and have it save the concept (in roughly your words) into a note. - Ask AlwaysReddy "What is X called?" when you know how to roughly describe something but can't remember what it is called. - Have AlwaysReddy proofread the text in your clipboard before you send it. - Ask AlwaysReddy "From the comments in my clipboard, what do the r/LocalLLaMA users think of X?" - Quickly list what you have done today and get AlwaysReddy to write a journal entry to your clipboard before you shutdown the computer for the day.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.
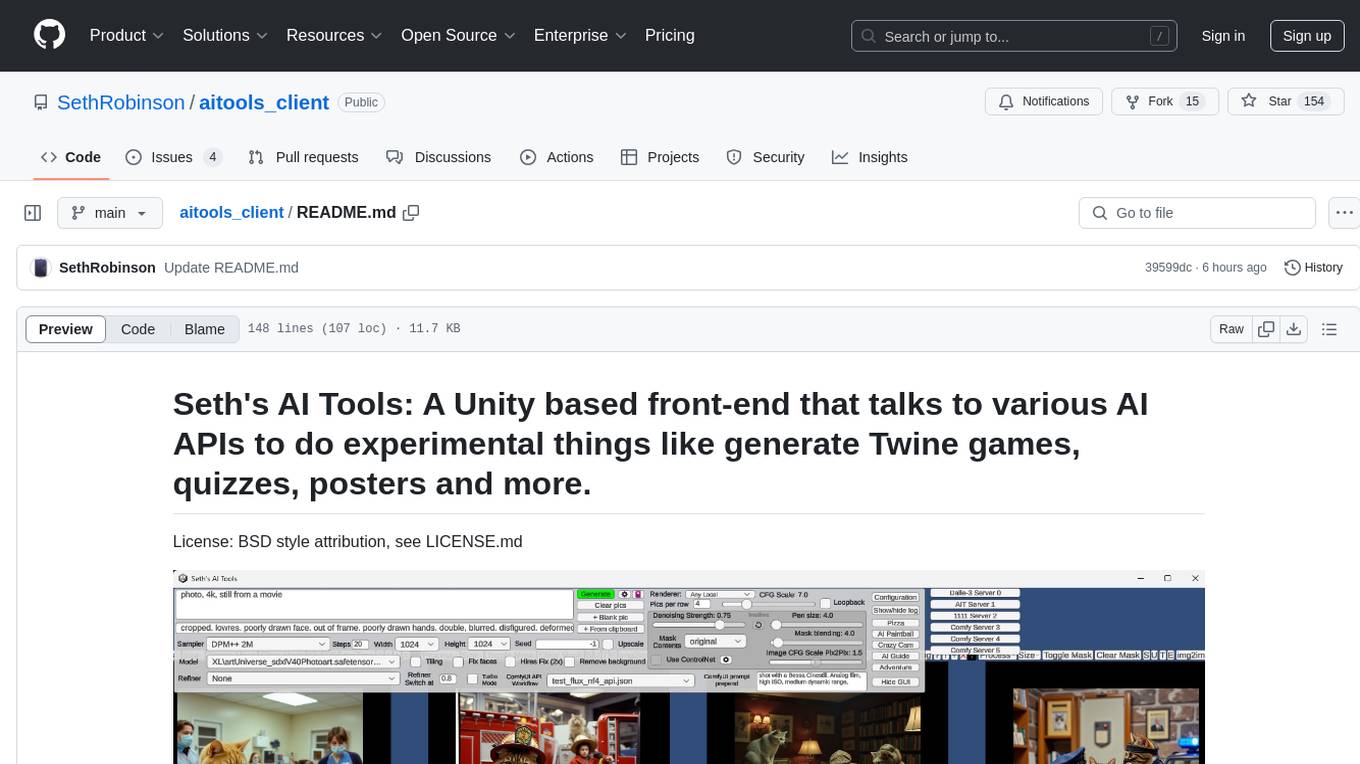
aitools_client
Seth's AI Tools is a Unity-based front-end that interfaces with various AI APIs to perform tasks such as generating Twine games, quizzes, posters, and more. The tool is a native Windows application that supports features like live update integration with image editors, text-to-image conversion, image processing, mask painting, and more. It allows users to connect to multiple servers for fast generation using GPUs and offers a neat workflow for evolving images in real-time. The tool respects user privacy by operating locally and includes built-in games and apps to test AI/SD capabilities. Additionally, it features an AI Guide for creating motivational posters and illustrated stories, as well as an Adventure mode with presets for generating web quizzes and Twine game projects.
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.
wtffmpeg
wtffmpeg is a command-line tool that uses a Large Language Model (LLM) to translate plain-English descriptions of video or audio tasks into actual, executable ffmpeg commands. It aims to streamline the process of generating ffmpeg commands by allowing users to describe what they want to do in natural language, review the generated command, optionally edit it, and then decide whether to run it. The tool provides an interactive REPL interface where users can input their commands, retain conversational context, and history, and control the level of interactivity. wtffmpeg is designed to assist users in efficiently working with ffmpeg commands, reducing the need to search for solutions, read lengthy explanations, and manually adjust commands.
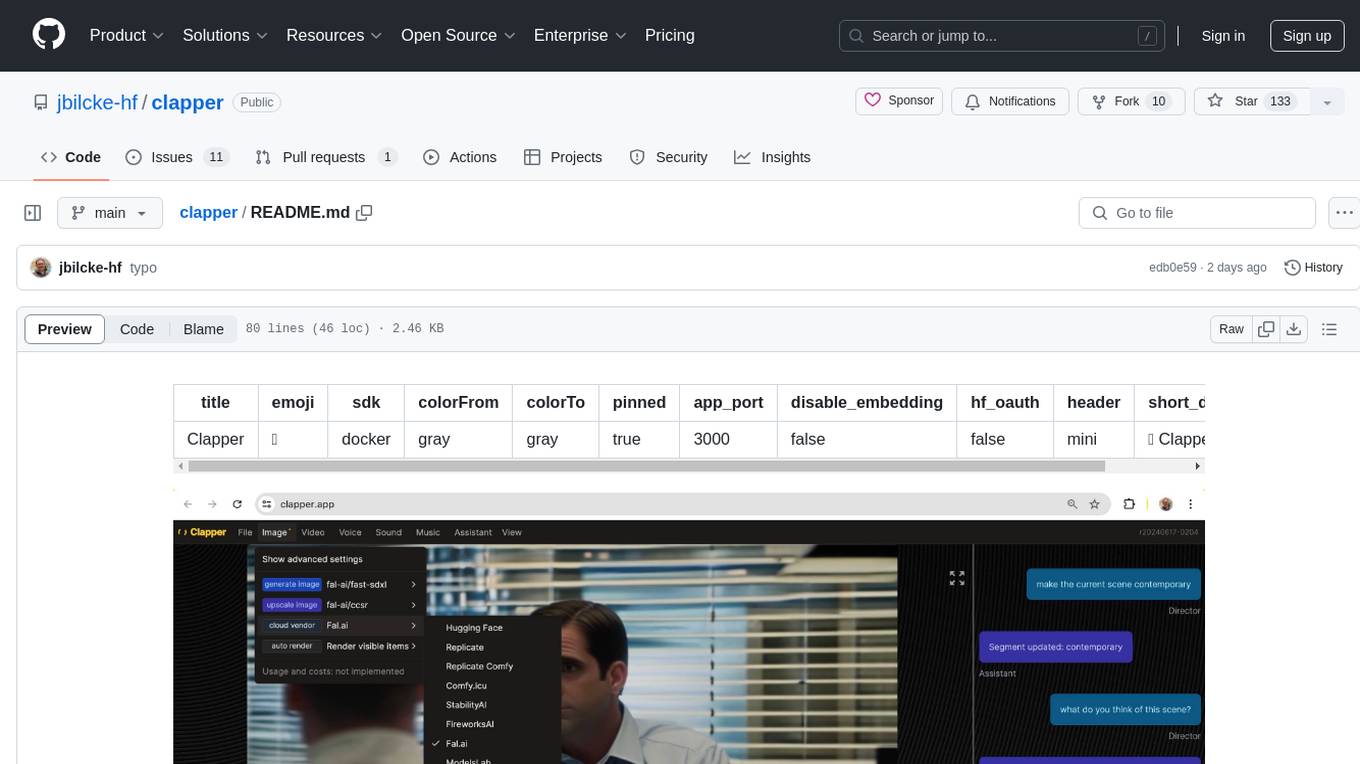
clapper
Clapper is an open-source AI story visualization tool that can interpret screenplays and render them into storyboards, videos, voice, sound, and music. It is currently in early development stages and not recommended for general use due to some non-functional features and lack of tutorials. A public alpha version is available on Hugging Face's platform. Users can sponsor specific features through bounties and developers can contribute to the project under the GPL v3 license. The tool lacks automated tests and code conventions like Prettier or a Linter.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
claude.vim
Claude.vim is a Vim plugin that integrates Claude, an AI pair programmer, into your Vim workflow. It allows you to chat with Claude about what to build or how to debug problems, and Claude offers opinions, proposes modifications, or even writes code. The plugin provides a chat/instruction-centric interface optimized for human collaboration, with killer features like access to chat history and vimdiff interface. It can refactor code, modify or extend selected pieces of code, execute complex tasks by reading documentation, cloning git repositories, and more. Note that it is early alpha software and expected to rapidly evolve.
wingman-ai
Wingman AI allows you to use your voice to talk to various AI providers and LLMs, process your conversations, and ultimately trigger actions such as pressing buttons or reading answers. Our _Wingmen_ are like characters and your interface to this world, and you can easily control their behavior and characteristics, even if you're not a developer. AI is complex and it scares people. It's also **not just ChatGPT**. We want to make it as easy as possible for you to get started. That's what _Wingman AI_ is all about. It's a **framework** that allows you to build your own Wingmen and use them in your games and programs. The idea is simple, but the possibilities are endless. For example, you could: * **Role play** with an AI while playing for more immersion. Have air traffic control (ATC) in _Star Citizen_ or _Flight Simulator_. Talk to Shadowheart in Baldur's Gate 3 and have her respond in her own (cloned) voice. * Get live data such as trade information, build guides, or wiki content and have it read to you in-game by a _character_ and voice you control. * Execute keystrokes in games/applications and create complex macros. Trigger them in natural conversations with **no need for exact phrases.** The AI understands the context of your dialog and is quite _smart_ in recognizing your intent. Say _"It's raining! I can't see a thing!"_ and have it trigger a command you simply named _WipeVisors_. * Automate tasks on your computer * improve accessibility * ... and much more

GlaDOS
This project aims to create a real-life version of GLaDOS, an aware, interactive, and embodied AI entity. It involves training a voice generator, developing a 'Personality Core,' implementing a memory system, providing vision capabilities, creating 3D-printable parts, and designing an animatronics system. The software architecture focuses on low-latency voice interactions, utilizing a circular buffer for data recording, text streaming for quick transcription, and a text-to-speech system. The project also emphasizes minimal dependencies for running on constrained hardware. The hardware system includes servo- and stepper-motors, 3D-printable parts for GLaDOS's body, animations for expression, and a vision system for tracking and interaction. Installation instructions cover setting up the TTS engine, required Python packages, compiling llama.cpp, installing an inference backend, and voice recognition setup. GLaDOS can be run using 'python glados.py' and tested using 'demo.ipynb'.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
For similar tasks
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
For similar jobs
alan-sdk-ios
Alan AI SDK for iOS is a powerful tool that allows developers to quickly create AI agents for their iOS apps. With Alan AI Platform, users can easily design, embed, and host conversational experiences in their applications. The platform offers a web-based IDE called Alan AI Studio for creating dialog scenarios, lightweight SDKs for embedding AI agents, and a backend powered by top-notch speech recognition and natural language understanding technologies. Alan AI enables human-like conversations and actions through voice commands, with features like on-the-fly updates, dialog flow testing, and analytics.
EvoMaster
EvoMaster is an open-source AI-driven tool that automatically generates system-level test cases for web/enterprise applications. It uses an Evolutionary Algorithm and Dynamic Program Analysis to evolve test cases, maximizing code coverage and fault detection. The tool supports REST, GraphQL, and RPC APIs, with whitebox testing for JVM-compiled languages. It generates JUnit tests, detects faults, handles SQL databases, and supports authentication. EvoMaster has been funded by the European Research Council and the Research Council of Norway.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.
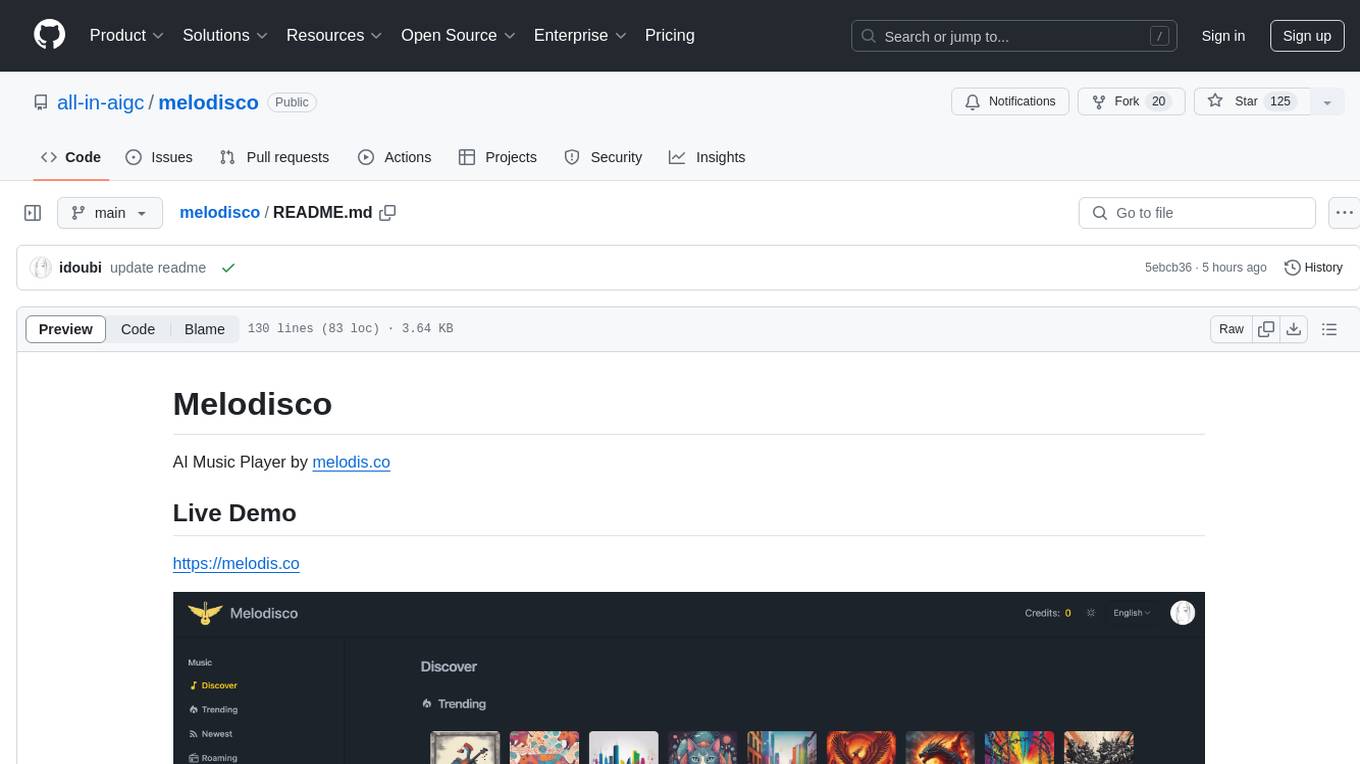
melodisco
Melodisco is an AI music player that allows users to listen to music and manage playlists. It provides a user-friendly interface for music playback and organization. Users can deploy Melodisco with Vercel or Docker for easy setup. Local development instructions are provided for setting up the project environment. The project credits various tools and libraries used in its development, such as Next.js, Tailwind CSS, and Stripe. Melodisco is a versatile tool for music enthusiasts looking for an AI-powered music player with features like authentication, payment integration, and multi-language support.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.

pgx
Pgx is a collection of GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL). It provides JAX-native game simulators for various games like Backgammon, Chess, Shogi, and Go, offering super fast parallel execution on accelerators and beautiful visualization in SVG format. Pgx focuses on faster implementations while also being sufficiently general, allowing environments to be converted to the AEC API of PettingZoo for running Pgx environments through the PettingZoo API.
sophia
Sophia is an open-source TypeScript platform designed for autonomous AI agents and LLM based workflows. It aims to automate processes, review code, assist with refactorings, and support various integrations. The platform offers features like advanced autonomous agents, reasoning/planning inspired by Google's Self-Discover paper, memory and function call history, adaptive iterative planning, and more. Sophia supports multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It provides a flexible platform for the TypeScript community to expand and support various use cases and integrations.
skyeye
SkyEye is an AI-powered Ground Controlled Intercept (GCI) bot designed for the flight simulator Digital Combat Simulator (DCS). It serves as an advanced replacement for the in-game E-2, E-3, and A-50 AI aircraft, offering modern voice recognition, natural-sounding voices, real-world brevity and procedures, a wide range of commands, and intelligent battlespace monitoring. The tool uses Speech-To-Text and Text-To-Speech technology, can run locally or on a cloud server, and is production-ready software used by various DCS communities.