
pgx
♟️ Vectorized RL game environments in JAX
Stars: 390

Pgx is a collection of GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL). It provides JAX-native game simulators for various games like Backgammon, Chess, Shogi, and Go, offering super fast parallel execution on accelerators and beautiful visualization in SVG format. Pgx focuses on faster implementations while also being sufficiently general, allowing environments to be converted to the AEC API of PettingZoo for running Pgx environments through the PettingZoo API.
README:
![]()
A collection of GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL)


Brax, a JAX-native physics engine, provides extremely high-speed parallel simulation for RL in continuous state space. Then, what about RL in discrete state spaces like Chess, Shogi, and Go? Pgx provides a wide variety of JAX-native game simulators! Highlighted features include:
- ⚡ Super fast in parallel execution on accelerators
- 🎲 Various game support including Backgammon, Chess, Shogi, and Go
- 🖼️ Beautiful visualization in SVG format
Read the Full Documentation for more details
Pgx is available on PyPI. Note that your Python environment has jax and jaxlib installed, depending on your hardware specification.
$ pip install pgxThe following code snippet shows a simple example of using Pgx.
You can try it out in this Colab.
Note that all step functions in Pgx environments are JAX-native., i.e., they are all JIT-able.
Please refer to the documentation for more details.
import jax
import pgx
env = pgx.make("go_19x19")
init = jax.jit(jax.vmap(env.init))
step = jax.jit(jax.vmap(env.step))
batch_size = 1024
keys = jax.random.split(jax.random.PRNGKey(42), batch_size)
state = init(keys) # vectorized states
while not (state.terminated | state.truncated).all():
action = model(state.current_player, state.observation, state.legal_action_mask)
# step(state, action, keys) for stochastic envs
state = step(state, action) # state.rewards with shape (1024, 2)Pgx is a library that focuses on faster implementations rather than just the API itself. However, the API itself is also sufficiently general. For example, all environments in Pgx can be converted to the AEC API of PettingZoo, and you can run Pgx environments through the PettingZoo API. You can see the demonstration in this Colab.
📣 API v2 (v2.0.0)
Pgx has been updated from API v1 to v2 as of November 8, 2023 (release v2.0.0). As a result, the signature for Env.step has changed as follows:
-
v1:
step(state: State, action: Array) -
v2:
step(state: State, action: Array, key: Optional[PRNGKey] = None)
Also, pgx.experimental.auto_reset are changed to specify key as the third argument.
Purpose of the update: In API v1, even in environments with stochastic state transitions, the state transitions were deterministic, determined by the _rng_key inside the state. This was intentional, with the aim of increasing reproducibility. However, when using planning algorithms in this environment, there is a risk that information about the underlying true randomness could "leak." To make it easier for users to conduct correct experiments, Env.step has been changed to explicitly specify a key.
Impact of the update: Since the key is optional, it is still possible to execute as env.step(state, action) like API v1 in deterministic environments like Go and chess, so there is no impact on these games. As of v2.0.0, only 2048, backgammon, and MinAtar suite are affected by this change.
| Backgammon | Chess | Shogi | Go |
|---|---|---|---|
 
|
 
|
 
|
 
|
Use pgx.available_envs() -> Tuple[EnvId] to see the list of currently available games. Given an <EnvId>, you can create the environment via
>>> env = pgx.make(<EnvId>)| Game/EnvId | Visualization | Version | Five-word description by ChatGPT |
|---|---|---|---|
2048 "2048"
|
|
v2 |
Merge tiles to create 2048. |
Animal Shogi"animal_shogi"
|
 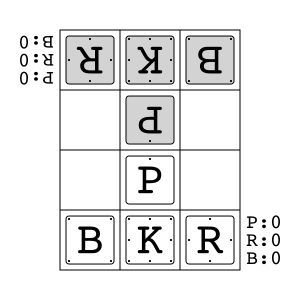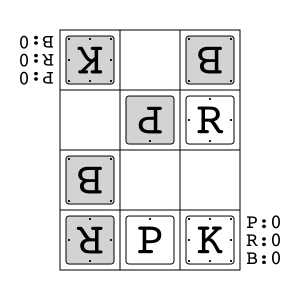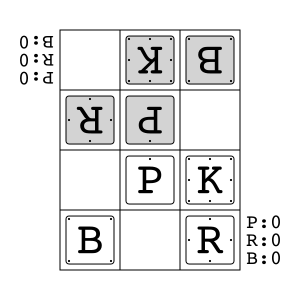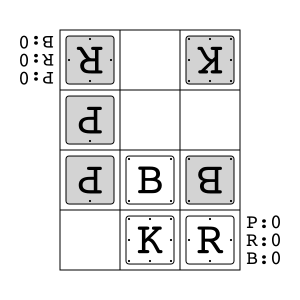
|
v2 |
Animal-themed child-friendly shogi. |
Backgammon"backgammon"
|
|
v2 |
Luck aids bearing off checkers. |
Bridge bidding"bridge_bidding"
|
 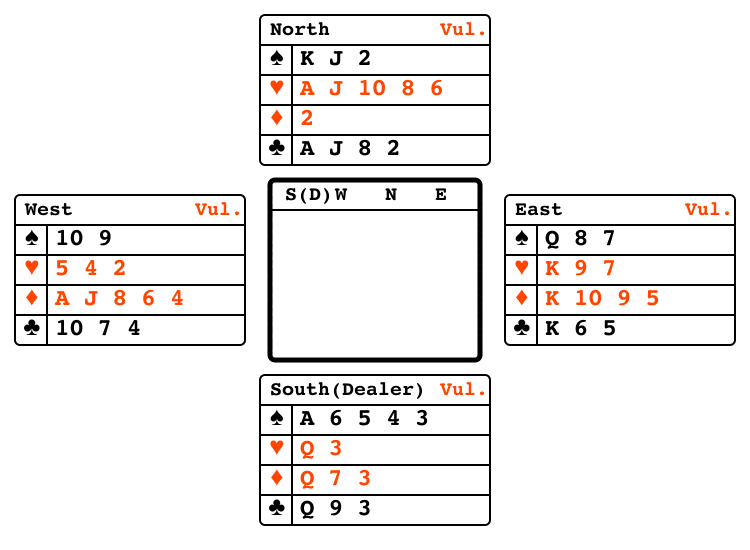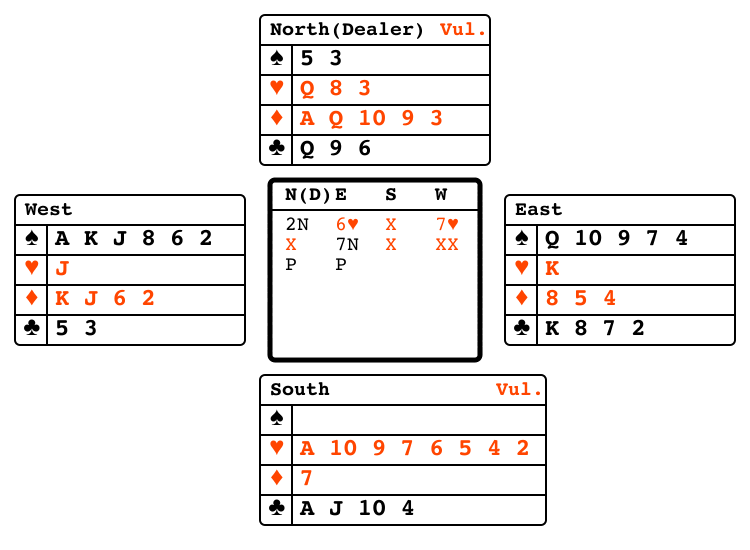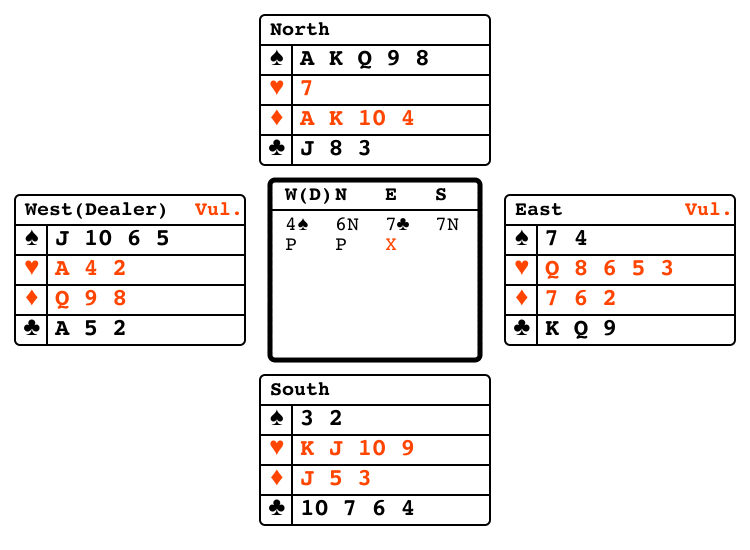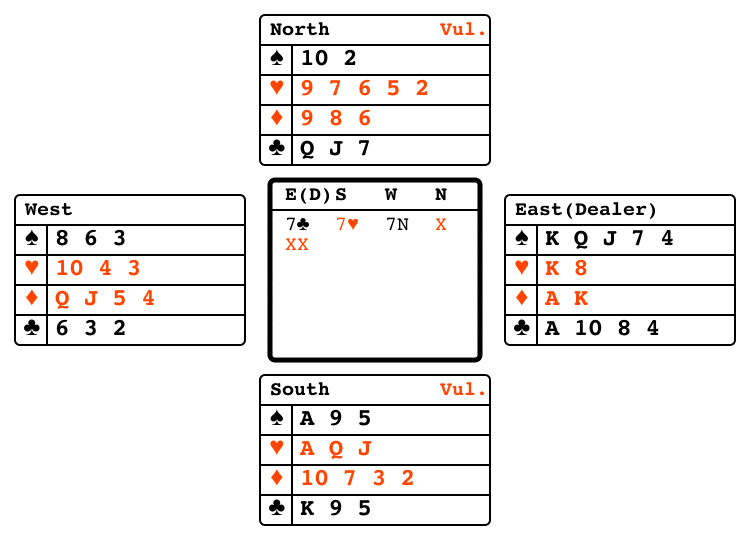
|
v1 |
Partners exchange information via bids. |
Chess"chess"
|
 
|
v2 |
Checkmate opponent's king to win. |
Connect Four"connect_four"
|
 
|
v0 |
Connect discs, win with four. |
Gardner Chess"gardner_chess"
|
|
v0 |
5x5 chess variant, excluding castling. |
Go"go_9x9" "go_19x19"
|
|
v0 |
Strategically place stones, claim territory. |
Hex"hex"
|
|
v0 |
Connect opposite sides, block opponent. |
Kuhn Poker"kuhn_poker"
|
|
v1 |
Three-card betting and bluffing game. |
Leduc hold'em"leduc_holdem"
|
|
v0 |
Two-suit, limited deck poker. |
MinAtar/Asterix"minatar-asterix"
|
 |
v1 |
Avoid enemies, collect treasure, survive. |
MinAtar/Breakout"minatar-breakout"
|
 |
v1 |
Paddle, ball, bricks, bounce, clear. |
MinAtar/Freeway"minatar-freeway"
|
 |
v1 |
Dodging cars, climbing up freeway. |
MinAtar/Seaquest"minatar-seaquest"
|
 |
v1 |
Underwater submarine rescue and combat. |
MinAtar/SpaceInvaders"minatar-space_invaders"
|
 |
v1 |
Alien shooter game, dodge bullets. |
Othello"othello"
|
|
v0 |
Flip and conquer opponent's pieces. |
Shogi"shogi"
|
|
v0 |
Japanese chess with captured pieces. |
Sparrow Mahjong"sparrow_mahjong"
|
 
|
v1 |
A simplified, children-friendly Mahjong. |
Tic-tac-toe"tic_tac_toe"
|
|
v0 |
Three in a row wins. |
Versioning policy
Each environment is versioned, and the version is incremented when there are changes that affect the performance of agents or when there are changes that are not backward compatible with the API. If you want to pursue complete reproducibility, we recommend that you check the version of Pgx and each environment as follows:
>>> pgx.__version__
'1.0.0'
>>> env.version
'v0'Pgx is intended to complement these JAX-native environments with (classic) board game suits:
- RobertTLange/gymnax: JAX implementation of popular RL environments (classic control, bsuite, MinAtar, etc) and meta RL tasks
- google/brax: Rigidbody physics simulation in JAX and continuous-space RL tasks (ant, fetch, humanoid, etc)
- instadeepai/jumanji: A suite of diverse and challenging RL environments in JAX (bin-packing, routing problems, etc)
- flairox/jaxmarl: Multi-Agent RL environments in JAX (simplified StarCraft, etc)
- corl-team/xland-minigrid: Meta-RL gridworld environments in JAX inspired by MiniGrid and XLand
- MichaelTMatthews/Craftax: (Crafter + NetHack) in JAX for open-ended RL
- epignatelli/navix: Re-implementation of MiniGrid in JAX
Combining Pgx with these JAX-native algorithms/implementations might be an interesting direction:
- Anakin framework: Highly efficient RL framework that works with JAX-native environments on TPUs
- deepmind/mctx: JAX-native MCTS implementations, including AlphaZero and MuZero
- deepmind/rlax: JAX-native RL components
- google/evojax: Hardware-Accelerated neuroevolution
- RobertTLange/evosax: JAX-native evolution strategy (ES) implementations
- adaptive-intelligent-robotics/QDax: JAX-native Quality-Diversity (QD) algorithms
- luchris429/purejaxrl: Jax-native RL implementations
If you use Pgx in your work, please cite our paper:
@inproceedings{koyamada2023pgx,
title={Pgx: Hardware-Accelerated Parallel Game Simulators for Reinforcement Learning},
author={Koyamada, Sotetsu and Okano, Shinri and Nishimori, Soichiro and Murata, Yu and Habara, Keigo and Kita, Haruka and Ishii, Shin},
booktitle={Advances in Neural Information Processing Systems},
pages={45716--45743},
volume={36},
year={2023}
}
Apache-2.0
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pgx
Similar Open Source Tools
pgx
Pgx is a collection of GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL). It provides JAX-native game simulators for various games like Backgammon, Chess, Shogi, and Go, offering super fast parallel execution on accelerators and beautiful visualization in SVG format. Pgx focuses on faster implementations while also being sufficiently general, allowing environments to be converted to the AEC API of PettingZoo for running Pgx environments through the PettingZoo API.
readme-ai
README-AI is a developer tool that auto-generates README.md files using a combination of data extraction and generative AI. It streamlines documentation creation and maintenance, enhancing developer productivity. This project aims to enable all skill levels, across all domains, to better understand, use, and contribute to open-source software. It offers flexible README generation, supports multiple large language models (LLMs), provides customizable output options, works with various programming languages and project types, and includes an offline mode for generating boilerplate README files without external API calls.

Noi
Noi is an AI-enhanced customizable browser designed to streamline digital experiences. It includes curated AI websites, allows adding any URL, offers prompts management, Noi Ask for batch messaging, various themes, Noi Cache Mode for quick link access, cookie data isolation, and more. Users can explore, extend, and empower their browsing experience with Noi.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.

onnxruntime-server
ONNX Runtime Server is a server that provides TCP and HTTP/HTTPS REST APIs for ONNX inference. It aims to offer simple, high-performance ML inference and a good developer experience. Users can provide inference APIs for ONNX models without writing additional code by placing the models in the directory structure. Each session can choose between CPU or CUDA, analyze input/output, and provide Swagger API documentation for easy testing. Ready-to-run Docker images are available, making it convenient to deploy the server.
llm_model_hub
Model Hub V2 is a one-stop platform for model fine-tuning, deployment, and debugging without code, providing users with a visual interface to quickly validate the effects of fine-tuning various open-source models, facilitating rapid experimentation and decision-making, and lowering the threshold for users to fine-tune large models. For detailed instructions, please refer to the Feishu documentation.
celeste-python
Celeste AI is a type-safe, modality/provider-agnostic tool that offers unified interface for various providers like OpenAI, Anthropic, Gemini, Mistral, and more. It supports multiple modalities including text, image, audio, video, and embeddings, with full Pydantic validation and IDE autocomplete. Users can switch providers instantly, ensuring zero lock-in and a lightweight architecture. The tool provides primitives, not frameworks, for clean I/O operations.
GPULlama3.java
GPULlama3.java powered by TornadoVM is a Java-native implementation of Llama3 that automatically compiles and executes Java code on GPUs via TornadoVM. It supports Llama3, Mistral, Qwen2.5, Qwen3, and Phi3 models in the GGUF format. The repository aims to provide GPU acceleration for Java code, enabling faster execution and high-performance access to off-heap memory. It offers features like interactive and instruction modes, flexible backend switching between OpenCL and PTX, and cross-platform compatibility with NVIDIA, Intel, and Apple GPUs.

tokscale
Tokscale is a high-performance CLI tool and visualization dashboard for tracking token usage and costs across multiple AI coding agents. It helps monitor and analyze token consumption from various AI coding tools, providing real-time pricing calculations using LiteLLM's pricing data. Inspired by the Kardashev scale, Tokscale measures token consumption as users scale the ranks of AI-augmented development. It offers interactive TUI mode, multi-platform support, real-time pricing, detailed breakdowns, web visualization, flexible filtering, and social platform features.
mcp-context-forge
MCP Context Forge is a powerful tool for generating context-aware data for machine learning models. It provides functionalities to create diverse datasets with contextual information, enhancing the performance of AI algorithms. The tool supports various data formats and allows users to customize the context generation process easily. With MCP Context Forge, users can efficiently prepare training data for tasks requiring contextual understanding, such as sentiment analysis, recommendation systems, and natural language processing.

oh-my-pi
oh-my-pi is an AI coding agent for the terminal, providing tools for interactive coding, AI-powered git commits, Python code execution, LSP integration, time-traveling streamed rules, interactive code review, task management, interactive questioning, custom TypeScript slash commands, universal config discovery, MCP & plugin system, web search & fetch, SSH tool, Cursor provider integration, multi-credential support, image generation, TUI overhaul, edit fuzzy matching, and more. It offers a modern terminal interface with smart session management, supports multiple AI providers, and includes various tools for coding, task management, code review, and interactive questioning.
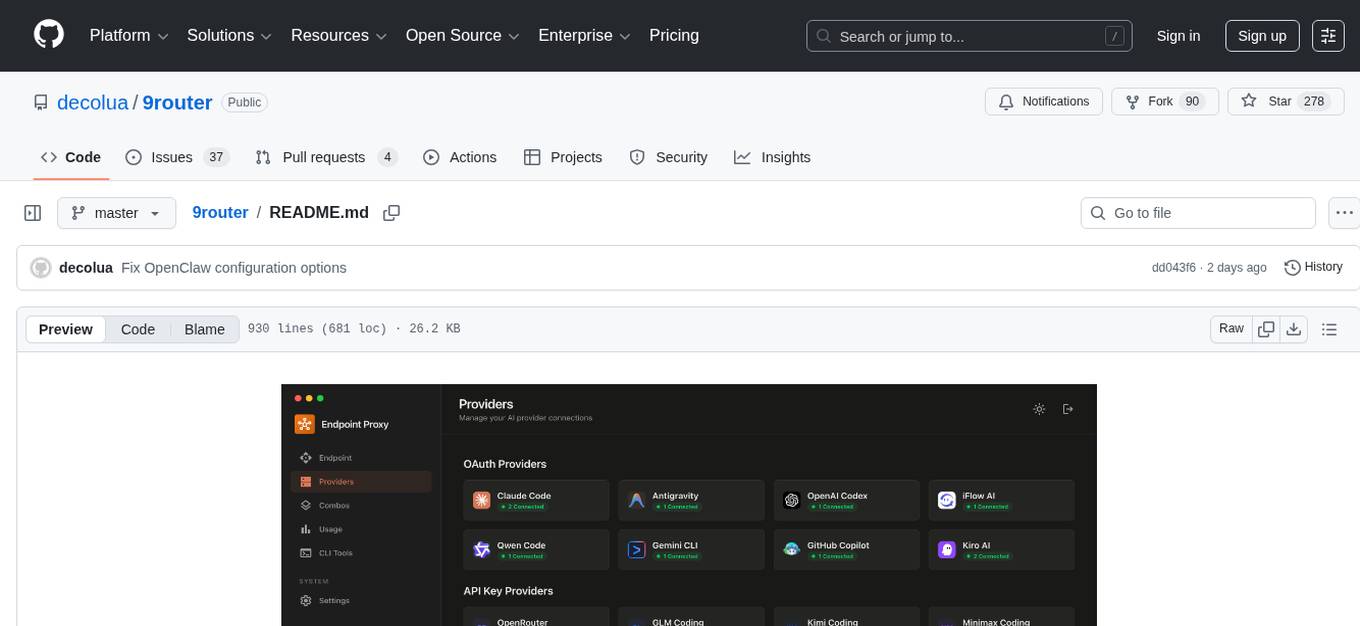
9router
9Router is a free AI router tool designed to help developers maximize their AI subscriptions, auto-route to free and cheap AI models with smart fallback, and avoid hitting limits and wasting money. It offers features like real-time quota tracking, format translation between OpenAI, Claude, and Gemini, multi-account support, auto token refresh, custom model combinations, request logging, cloud sync, usage analytics, and flexible deployment options. The tool supports various providers like Claude Code, Codex, Gemini CLI, GitHub Copilot, GLM, MiniMax, iFlow, Qwen, and Kiro, and allows users to create combos for different scenarios. Users can connect to the tool via CLI tools like Cursor, Claude Code, Codex, OpenClaw, and Cline, and deploy it on VPS, Docker, or Cloudflare Workers.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.
ai-news-radar
AI Signal Board is a high-quality AI/tech news aggregation project that supports static web page display, 24-hour incremental updates, WaytoAGI update logs, OPML RSS batch access, and failure source replacement and alerts. The project includes features such as multi-source web aggregation, OPML RSS ingestion, 24-hour two-mode UI, deduplication functionality, bilingual title rendering, WaytoAGI timeline, and RSS resilience. Users can easily update news data, view aggregated news from various sources, and customize their RSS subscriptions. The project does not require any API keys for core functionality and provides detailed instructions for configuration and usage.
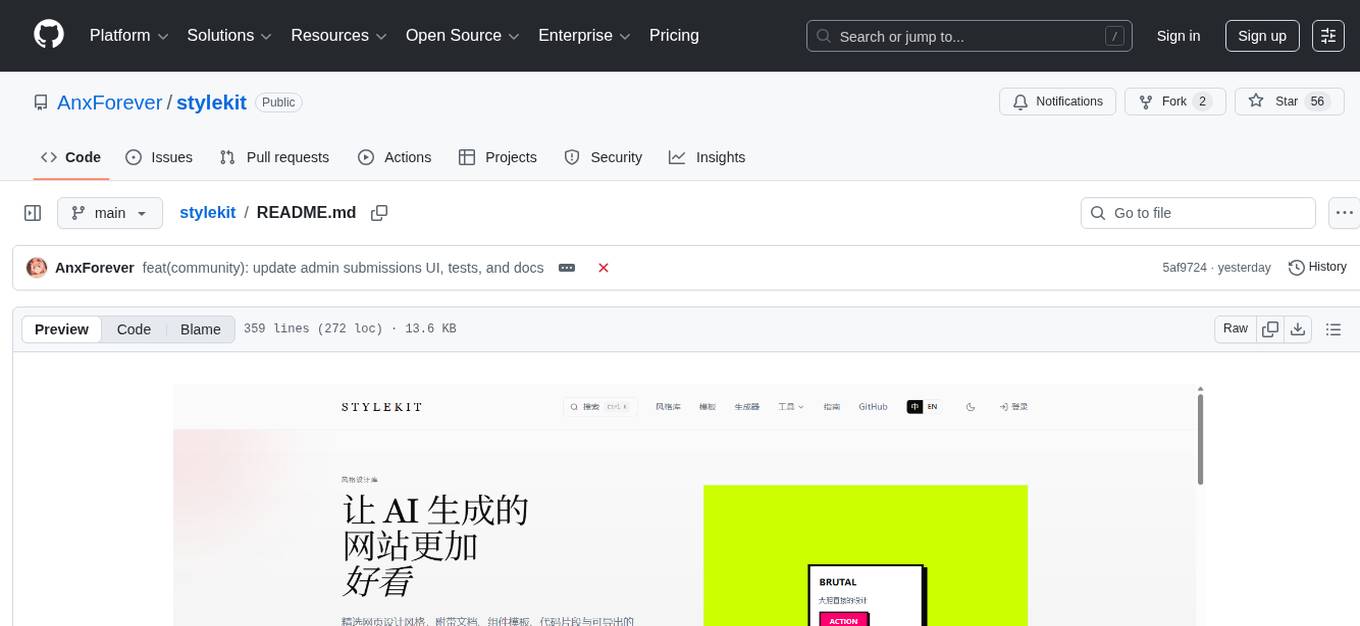
stylekit
StyleKit is a comprehensive design system toolkit that helps both humans and AI generate consistent, high-quality UI code. It provides structured style specifications, design tokens, component recipes, prompt templates, and export tools — everything needed to go from 'I want a glassmorphism SaaS dashboard' to production-ready frontend code. With 90+ visual styles, 20+ page templates, 25+ UI components, and AI-powered tools like Prompt Builder, Smart Recommender, Style Linter, Style Analyzer, and Style Blender, StyleKit offers a platform with GitHub OAuth, ratings & comments, style submissions, instant community availability, favorites, bilingual support, PWA, and dark/light mode themes.
yomitoku
YomiToku is a Japanese-focused AI document image analysis engine that provides full-text OCR and layout analysis capabilities for images. It recognizes, extracts, and converts text information and figures in images. It includes 4 AI models trained on Japanese datasets for tasks such as detecting text positions, recognizing text strings, analyzing layouts, and recognizing table structures. The models are specialized for Japanese document images, supporting recognition of over 7000 Japanese characters and analyzing layout structures specific to Japanese documents. It offers features like layout analysis, table structure analysis, and reading order estimation to extract information from document images without disrupting their semantic structure. YomiToku supports various output formats such as HTML, markdown, JSON, and CSV, and can also extract figures, tables, and images from documents. It operates efficiently in GPU environments, enabling fast and effective analysis of document transcriptions without requiring high-end GPUs.
For similar tasks
pgx
Pgx is a collection of GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL). It provides JAX-native game simulators for various games like Backgammon, Chess, Shogi, and Go, offering super fast parallel execution on accelerators and beautiful visualization in SVG format. Pgx focuses on faster implementations while also being sufficiently general, allowing environments to be converted to the AEC API of PettingZoo for running Pgx environments through the PettingZoo API.
For similar jobs
alan-sdk-ios
Alan AI SDK for iOS is a powerful tool that allows developers to quickly create AI agents for their iOS apps. With Alan AI Platform, users can easily design, embed, and host conversational experiences in their applications. The platform offers a web-based IDE called Alan AI Studio for creating dialog scenarios, lightweight SDKs for embedding AI agents, and a backend powered by top-notch speech recognition and natural language understanding technologies. Alan AI enables human-like conversations and actions through voice commands, with features like on-the-fly updates, dialog flow testing, and analytics.
EvoMaster
EvoMaster is an open-source AI-driven tool that automatically generates system-level test cases for web/enterprise applications. It uses an Evolutionary Algorithm and Dynamic Program Analysis to evolve test cases, maximizing code coverage and fault detection. The tool supports REST, GraphQL, and RPC APIs, with whitebox testing for JVM-compiled languages. It generates JUnit tests, detects faults, handles SQL databases, and supports authentication. EvoMaster has been funded by the European Research Council and the Research Council of Norway.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.
melodisco
Melodisco is an AI music player that allows users to listen to music and manage playlists. It provides a user-friendly interface for music playback and organization. Users can deploy Melodisco with Vercel or Docker for easy setup. Local development instructions are provided for setting up the project environment. The project credits various tools and libraries used in its development, such as Next.js, Tailwind CSS, and Stripe. Melodisco is a versatile tool for music enthusiasts looking for an AI-powered music player with features like authentication, payment integration, and multi-language support.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
pgx
Pgx is a collection of GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL). It provides JAX-native game simulators for various games like Backgammon, Chess, Shogi, and Go, offering super fast parallel execution on accelerators and beautiful visualization in SVG format. Pgx focuses on faster implementations while also being sufficiently general, allowing environments to be converted to the AEC API of PettingZoo for running Pgx environments through the PettingZoo API.
sophia
Sophia is an open-source TypeScript platform designed for autonomous AI agents and LLM based workflows. It aims to automate processes, review code, assist with refactorings, and support various integrations. The platform offers features like advanced autonomous agents, reasoning/planning inspired by Google's Self-Discover paper, memory and function call history, adaptive iterative planning, and more. Sophia supports multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It provides a flexible platform for the TypeScript community to expand and support various use cases and integrations.
skyeye
SkyEye is an AI-powered Ground Controlled Intercept (GCI) bot designed for the flight simulator Digital Combat Simulator (DCS). It serves as an advanced replacement for the in-game E-2, E-3, and A-50 AI aircraft, offering modern voice recognition, natural-sounding voices, real-world brevity and procedures, a wide range of commands, and intelligent battlespace monitoring. The tool uses Speech-To-Text and Text-To-Speech technology, can run locally or on a cloud server, and is production-ready software used by various DCS communities.