
whisper_dictation
Private voice keyboard, AI chat, images, webcam, recordings, voice control with >= 4 GiB of VRAM.
Stars: 201
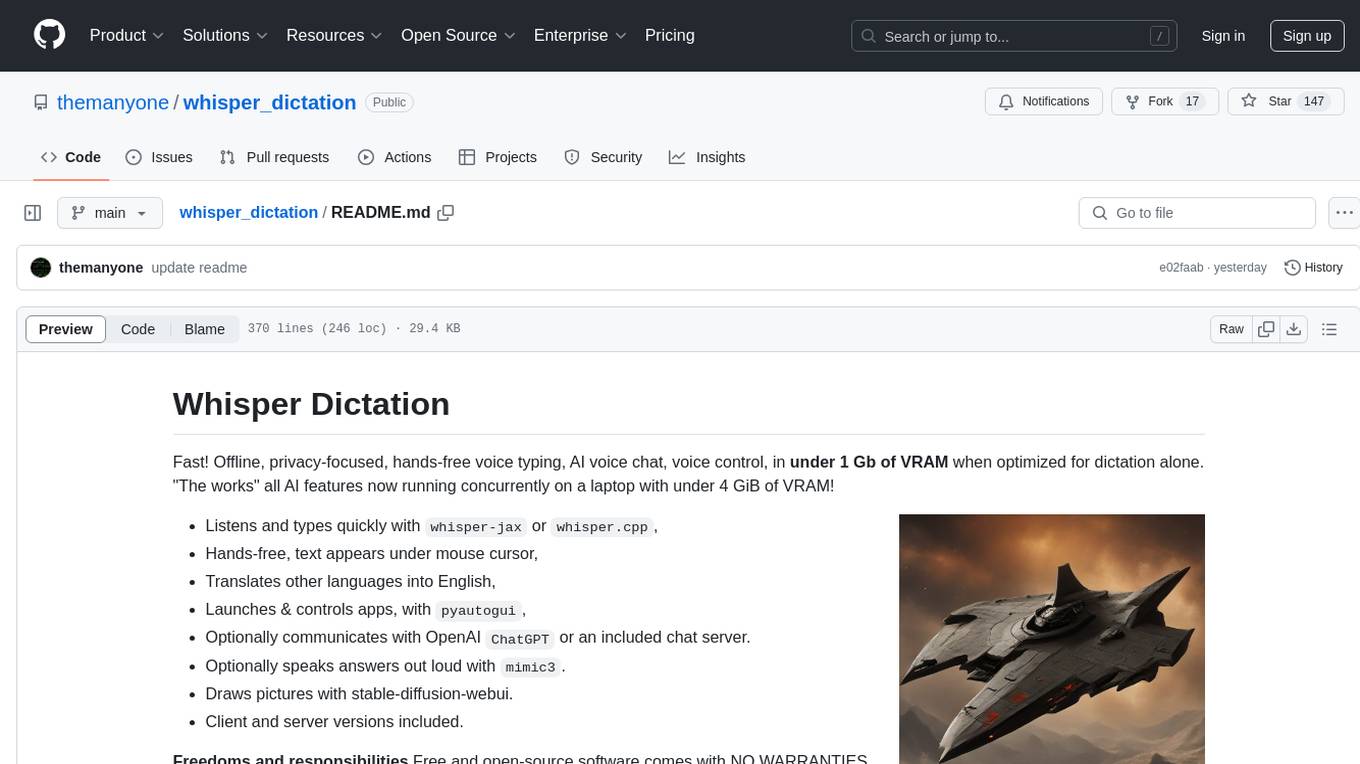
Whisper Dictation is a fast, offline, privacy-focused tool for voice typing, AI voice chat, voice control, and translation. It allows hands-free operation, launching and controlling apps, and communicating with OpenAI ChatGPT or a local chat server. The tool also offers the option to speak answers out loud and draw pictures. It includes client and server versions, inspired by the Star Trek series, and is designed to keep data off the internet and confidential. The project is optimized for dictation and translation tasks, with voice control capabilities and AI image generation using stable-diffusion API.
README:
Private voice keyboard, AI chat, images, webcam, recordings, voice control in >= 4 GiB of VRAM. "The works" all AI features now running concurrently on an old laptop from 2013.

- Hands-free recording with
record.py - Speech to text conversion by
whisper.cppWhisper.cpp - Translate various languages
- Voice-controlled webcam, audio recorder
- Launch & control apps, with
pyautogui - Optional OpenAI
ChatGPT, Google Gemini, more - Optionally speak answers out loud with
mimic3 - Draw pictures with stable-diffusion-webui
- Help! Get us a better video card (PayPal donation link)
Freedoms and responsibilities Free and open-source software comes with NO WARRANTIES. You have permission to copy and modify for individual needs in accordance with the included LICENSE.
The ship's computer. Inspired by the Star Trek television series. Talk to your computer. Have it answer back with clear, easy-to-understand speech. Network it throughout the ship. Use your voice to write Captain's Log entries when the internet is down, when satellites are busy, or in the far reaches of the galaxy, "where no man has gone before."
Translation. This app is optimized for dictation. It can do some translation into English. But that's not its primary task. To use it as a full-time translator, start whisper.cpp with --translate and language flags. Use ggml-medium.bin or larger language model in place of ggml-tiny.en.bin.
Voice control. The bot responds to commands.
Say, "Computer, on screen." A window opens up showing the webcam. Say "Computer, take a picture". A picture, "webcam/image().jpg" is saved. Say, "Computer, search the web for places to eat". A browser opens up with a list of local restaurants. Say, "Computer, say hello to our guest". After a brief pause, there is a reply, either from your local machine, ChatGPT, or a local area chat server that you set up. A voice, mimic3 says some variation of, "Hello. Pleased to meet you. Welcome to our shop. Let me know how I can be of assistance". It's unique each time. Say, "Computer, open terminal". A terminal window pops up. Say "Computer, draw a picture of a Klingon warship". An image of a warship appears with buttons to save, print, and navigate through previously-generated images.
Fewer dependencies. We saved over 1Gb of downloads and hours of setup by eliminating torch, cuda, cudnn, ffmpeg dependencies. Those older versions can be found in the legacy branch. Get just the main branch to save time.
git clone -b main --single-branch https://github.com/themanyone/whisper_dictation.git
GStreamer is necessary to record temporary audio clips for sending to your local whisper.cpp speech to text (STT) server. It should be available from various package managers.
The required ladspa-delay-so-delay-5s may be found in the gstreamer1-plugins-bad-free-extras package.
pip install -r whisper_dictation/requirements.txt
git clone https://github.com/ggerganov/whisper.cpp
cd whisper.cpp
GGML_CUDA=1 make -j # assuming CUDA is available. see docs
ln -s server ~/.local/bin/whisper_cpp_server # just put it somewhere in $PATHwhisper_cpp_server -l en -m models/ggml-tiny.en.bin --port 7777
./whisper_cpp_client.pyA sound level meter appears. Adjust ambient (quiet) volume to about 33% (-33dB).
If VRAM is scarce, quantize ggml-tiny.en.bin according to whisper.cpp docs. Or use -ng option to avoid using VRAM altogether. It will lose some performance. But it's not that noticeable with a fast CPU.
If whisper_cpp_server is slow or refuses to start, reboot. Or try and reload the crashed NVIDIA uvm module sudo modprobe -r nvidia_uvm && sudo modprobe nvidia_uvm.
Edit whisper_cpp_client.py client to change server locations from localhost to wherever they reside on the network. You can also change the port numbers. Just make sure servers and clients are in agreement on which port to use.
Test clients and servers.
./whisper.cpp -l en -m ./models/ggml-tiny.en.bin samples/jfk.wav
ln -sf $(pwd)/main whisper_cpp
ln -sf $(pwd)/server whisper_cpp_server
./whisper_cpp_server -l en -m models/ggml-tiny.en.bin --port 7777Hosting large language models provides some limited access to information, even if the internet is down. But don't trust the answers. Keep all logs and communications behind a good firewall for privacy. And network security is another topic...
Supposing any chat server will do. Many use llama.cpp behind the scenes. Since it is not susceptible to "pickle" code injection, we don't have to recommend special safetensors models. So we'll use that. Understand that this is for a local home server. Running a public server comes with a catalog of other concerns so those folks might prefer to host these in a container, and/or on somebody else's cloud.
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
GGML_CUDA=1 make -j # assuming CUDA is available. see docsFinding free models. Save hundreds on annual subscriptions by running your own AI servers for every task. Look at the leaderboard to see which models perform best in the categories you want. As a rule of thumb, quantized 7B models are about the maximum our 4GiB VRAM can handle. Search for quantized models in .gguf format, or try the ones on our page.
AI Safety. Monitor children's activities. Be aware that these models, made by the community, are under active development. They are not guaranteed safe for all ages.
High VRAM usage. Use a tool like nvtop (availabl from package managers) to keep an eye on available VRAM.
Context window. The context window is the size of input plus output. Running large models with a large context window (-ctx 8192), while sending graphics layers to the GPU (-ngl 33) for speed, uses lots of VRAM. They might even crash. With small models, it is okay to run the llama-server with -ngl 33 for high speed/high memory usage. With large (> 3GiB) models, use lower values, such as -ngl 17 and -ctx 512, or avoid -ngl altogether.
Help! Get this project off the ground with some better hardware (PayPal donation link).
./llama-server -m models/gemma-2-2b-it-q4_k_m.gguf -c 2048 -ngl 33 --port 8888Use the above API endpoint by simply saying "Computer... What is the capital of France!" etc. Or navigate to its handy web interface at http://localhost:8888 and dictate into that. From there you can adjust settings like temperature to make it more creative, or more strict with its fact checking and self censorship.
If AI is speaking, turn volume down or relocate the mic so it doesn't interact with itself.
Mimic3. If you follow the instructions to configure mimic3 as a service on any linux computer or Raspberry Pi on the network, Speech Dispatcher will speak answers out loud. It has an open port that other network users can use to enable speech on their devices. But they can also make it speak remotely. So it is essentially a Star Trek communicator that works over wifi. Follow the instructions for setting up mimic3 as a Systemd Service.
Developer notes. The mimic3-server is already lightening-fast on CPU. Do not bother compiling it with --cuda flag, which requires old onnxruntime-gpu that is not compatible with CUDA 12+ and won't compile with nvcc12... We got it working! And it just hogs all of VRAM and provides no noticeable speedup.
Female voice. For a pleasant, female voice, use mimic3-download to obtain en_US/vctk_low To accommodate this change, we already edited the params line in our mimic3_client.py, and commented the other line out, like so.
# params = { 'text': text, "lengthScale": "0.6" }
params = { 'text': text, "voice": "en_US/vctk_low" }
So just change it back if you want the default male voice, other languages, or to adjust speech characteristics to taste.
Export the OPENAI_API_KEY and it will give preference to answers from ChatGPT. Edit .bashrc, or another startup file:
export OPENAI_API_KEY=<my API key>We heard OpenAI also has enterprise endoints for ChatGPT that offer some privacy and security. But we have never been contacted by OpenAI and make no claims about its proprietary domains.
- Sign up for a GOOGLE_API_KEY
pip install -q -U google-generativeaiexport GENAI_KEY=<YOUR API_KEY>
Now with sdapi.py, images may be generated locally, or across the network. Requires stable-diffusion-webui. Start webui.sh on the server with --api options. Also use --medvram or --lowvram if your video is as bad as ours. If using remotely, configure our sdapi.py client with the server's address.
Start stable-diffusion webui
webui.sh --api --medvramThe computer responds to commands. You can also call her Samantha (Or Peter with for voice).
Mute button. There is no mute button. Say "pause dictation" to turn off text generation. It will keep listening to commands. Say, "Thank you", "resume dictation", or "Computer, type this out" to have it start typing again. Say "stop listening" or "stop dictation" to quit the program entirely. You could configure a button to mute your mic, but that is no longer necessary.
These actions are defined in whisper_dictation.py. See the source code for the full list. Feel free to edit them too!
Try saying:
- Computer, on screen. (or "start webcam"; opens a webcam window).
- Computer, take a picture. (saves to webcam/image.jpg)
- Computer, off screen. (or "stop webcam")
- Computer, record audio (records audio.mp3)
- Computer, open terminal.
- Computer, go to thenerdshow.com. (or any website).
- Computer, open a web browser. (opens the default homepage).
- Computer, show us a picture of a Klingon battle cruiser.
- Page up.
- Page down.
- Undo that.
- Copy that.
- Paste it.
- Pause dictation.
- Resume dictation.
- New paragraph. (also submits chat forms :)
- Samantha, tell me about the benefits of relaxation.**
- Peter, compose a Facebook post about the sunny weather we're having.
- Stop dictation. (quits program).
whisper_cpp_client.py: A small and efficient Python client that connects to a running Whisper.cpp server on the local machine or across the network.
record.py: Almost hands-free, sound-activated recorder. You can run it separately. It creates a file named audio.wav. Supply optional command line arguments to change the file name, quality, formats, add filters, etc. See ./record.py -h for help. Some formats require gst-plugins-bad or gst-plugins-ugly, depending on your distribution.
This update provides a powerful option that lets you insert various plugins, mixers, filters, controllers, and effects directly into the GStreamer pipeline. See the G-streamer documentation for details. Many audio and video plugins are available. Run gst-inspect-1.0 for a list. The following records in a high quality, lossless format with echo effect and dynamic range compression.
./record.py -gq 'audioecho delay=250000000 intensity=0.25 ! audiodynamic' echo.flac
on_screen.py A simple python library to show and take pictures from the webcam.
sdapi.py The client we made to connect to a running instance of stable-diffusion-webui. This is what gets called when you say, "Computer...Draw a picture of a horse."
Various test files, including:
mimic3_client.py: a client to query and test mimic3-server voice output servers.
test_cuda.py: torch, pytorch, cuda, and onnxruntime are no longer required for dictation. But you can still test them here, since mimic3 uses onnxruntime for text to speech.
Stable-Diffusion. Stable-Diffusion normally requires upwards of 16 GiB of VRAM. But we were able to get it running with a mere 2 GiB using the --medvram or --lowvram option with Stable Diffusion Web UI.
I want it to type slowly. We would love to have it type text slowly, but typing has become unbearably-slow on sites like Twitter and Facebook. The theory is they are using JavaScript to restrict input from bots. But it is annoying for fast typists too. If occasional slow typing doesn't bother you, change the code to use pyautogui.typewrite(t, typing_interval) for everything, and set a typing_interval to whatever speed you want.
Whisper Dictation is not optimized for making captions or transcripts of pre-recorded material. Use Whisper.cpp or whisper-jax for that. They too have a server with a web interface that makes transcripts for voice recordings and videos.
If you want real-time AI captions translating everyone's conversations in the room into English. If you want to watch videos with accents that are difficult to understand. Or if you just don't want to miss what the job interviewer asked you during that zoom call... WHAT???, check out my other project, Caption Anything. And generate captions as you record live "what you hear" from the audio monitor device (any sounds that are playing through the computer).
Browse Themanyone
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for whisper_dictation
Similar Open Source Tools
whisper_dictation
Whisper Dictation is a fast, offline, privacy-focused tool for voice typing, AI voice chat, voice control, and translation. It allows hands-free operation, launching and controlling apps, and communicating with OpenAI ChatGPT or a local chat server. The tool also offers the option to speak answers out loud and draw pictures. It includes client and server versions, inspired by the Star Trek series, and is designed to keep data off the internet and confidential. The project is optimized for dictation and translation tasks, with voice control capabilities and AI image generation using stable-diffusion API.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
AlwaysReddy
AlwaysReddy is a simple LLM assistant with no UI that you interact with entirely using hotkeys. It can easily read from or write to your clipboard, and voice chat with you via TTS and STT. Here are some of the things you can use AlwaysReddy for: - Explain a new concept to AlwaysReddy and have it save the concept (in roughly your words) into a note. - Ask AlwaysReddy "What is X called?" when you know how to roughly describe something but can't remember what it is called. - Have AlwaysReddy proofread the text in your clipboard before you send it. - Ask AlwaysReddy "From the comments in my clipboard, what do the r/LocalLLaMA users think of X?" - Quickly list what you have done today and get AlwaysReddy to write a journal entry to your clipboard before you shutdown the computer for the day.

call-gpt
Call GPT is a voice application that utilizes Deepgram for Speech to Text, elevenlabs for Text to Speech, and OpenAI for GPT prompt completion. It allows users to chat with ChatGPT on the phone, providing better transcription, understanding, and speaking capabilities than traditional IVR systems. The app returns responses with low latency, allows user interruptions, maintains chat history, and enables GPT to call external tools. It coordinates data flow between Deepgram, OpenAI, ElevenLabs, and Twilio Media Streams, enhancing voice interactions.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.

serena
Serena is a powerful coding agent that integrates with existing LLMs to provide essential semantic code retrieval and editing tools. It is free to use and does not require API keys or subscriptions. Serena can be used for coding tasks such as analyzing, planning, and editing code directly on your codebase. It supports various programming languages and offers semantic code analysis capabilities through language servers. Serena can be integrated with different LLMs using the model context protocol (MCP) or Agno framework. The tool provides a range of functionalities for code retrieval, editing, and execution, making it a versatile coding assistant for developers.
polis
Polis is an AI powered sentiment gathering platform that offers a more organic approach than surveys and requires less effort than focus groups. It provides a comprehensive wiki, main deployment at https://pol.is, discussions, issue tracking, and project board for users. Polis can be set up using Docker infrastructure and offers various commands for building and running containers. Users can test their instance, update the system, and deploy Polis for production. The tool also provides developer conveniences for code reloading, type checking, and database connections. Additionally, Polis supports end-to-end browser testing using Cypress and offers troubleshooting tips for common Docker and npm issues.
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.
tau
Tau is a framework for building low maintenance & highly scalable cloud computing platforms that software developers will love. It aims to solve the high cost and time required to build, deploy, and scale software by providing a developer-friendly platform that offers autonomy and flexibility. Tau simplifies the process of building and maintaining a cloud computing platform, enabling developers to achieve 'Local Coding Equals Global Production' effortlessly. With features like auto-discovery, content-addressing, and support for WebAssembly, Tau empowers users to create serverless computing environments, host frontends, manage databases, and more. The platform also supports E2E testing and can be extended using a plugin system called orbit.

aisuite
Aisuite is a simple, unified interface to multiple Generative AI providers. It allows developers to easily interact with various Language Model (LLM) providers like OpenAI, Anthropic, Azure, Google, AWS, and more through a standardized interface. The library focuses on chat completions and provides a thin wrapper around python client libraries, enabling creators to test responses from different LLM providers without changing their code. Aisuite maximizes stability by using HTTP endpoints or SDKs for making calls to the providers. Users can install the base package or specific provider packages, set up API keys, and utilize the library to generate chat completion responses from different models.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
redbox-copilot
Redbox Copilot is a retrieval augmented generation (RAG) app that uses GenAI to chat with and summarise civil service documents. It increases organisational memory by indexing documents and can summarise reports read months ago, supplement them with current work, and produce a first draft that lets civil servants focus on what they do best. The project uses a microservice architecture with each microservice running in its own container defined by a Dockerfile. Dependencies are managed using Python Poetry. Contributions are welcome, and the project is licensed under the MIT License.
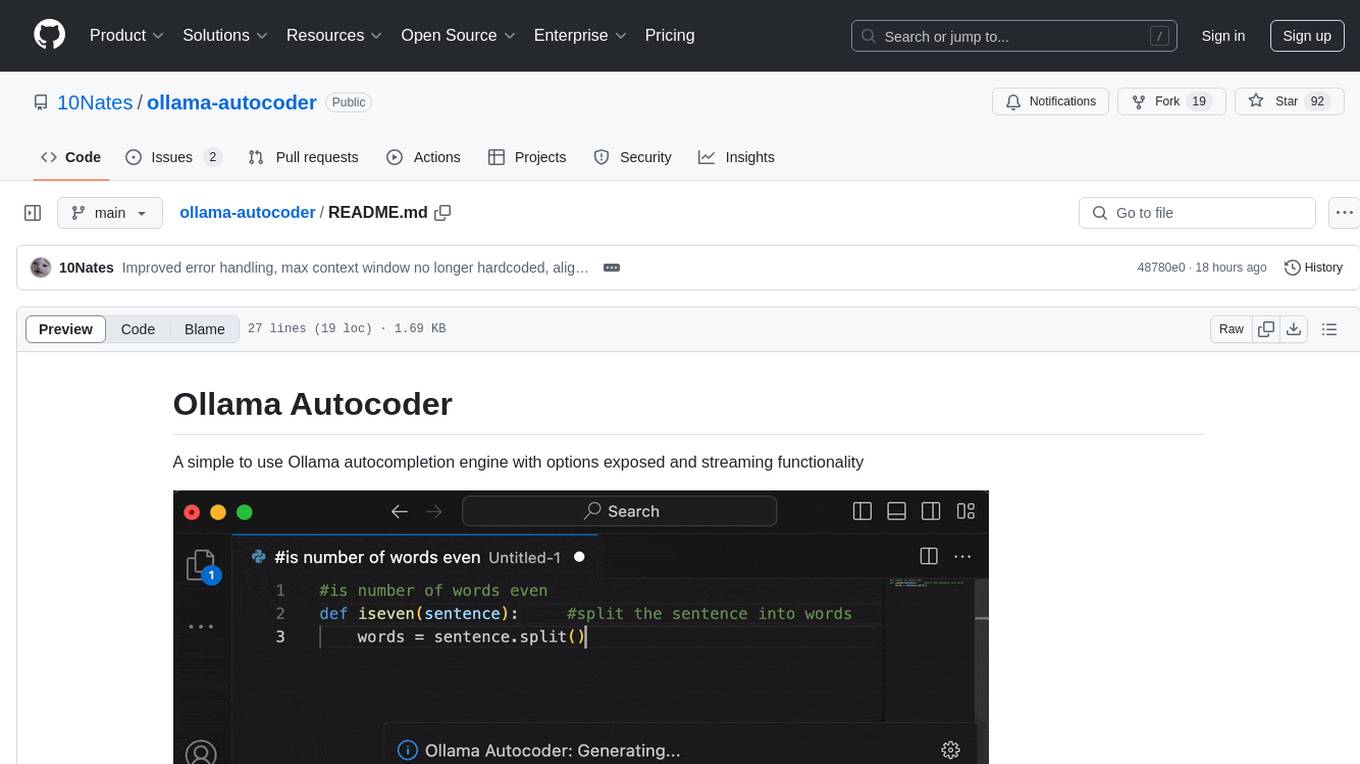
ollama-autocoder
Ollama Autocoder is a simple to use autocompletion engine that integrates with Ollama AI. It provides options for streaming functionality and requires specific settings for optimal performance. Users can easily generate text completions by pressing a key or using a command pallete. The tool is designed to work with Ollama API and a specified model, offering real-time generation of text suggestions.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.
For similar tasks

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.