
abliterator
Simple Python library/structure to ablate features in LLMs which are supported by TransformerLens
Stars: 96
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.
README:
Simple Python library/structure to ablate features in LLMs which are supported by TransformerLens.
Most of its advantage in workflow comes from being able to enter temporary contexts, quickly cache activations with N samples, refusal direction calculation built-in, and tokenizer utilities. As well as wrapping around certain quirks of TransformerLens.
If you're interested in notebooking your own orthgonalized model, this library will help save you a LOT of time in performing and measuring experiments to find your best orthogonalization.
This is ultimately just bits and pieces to make it so to process and experiment with ablation direction turns into shorter, hopefully clearer code without losing track of where things are at; encapsulating a lot of useful logic that you'll find yourself writing if you're looking to do this more.
This library is so exceedingly barebones for right now, and documentation is slim at the moment (WYSIWYG!). Right now, it feels like a glorified IPython notebook rather than something more broadly useful. I want to publish this now to lay out the template, and hopefully bring this up to snuff over time. Ideally with the help of the community!
Right now, this works very well for my own personal workflow, but I would like to systematize and ideally automate this further, and broaden out from the pure "harmless / harmful" feature ablation, to augmentation, and adding additional features
import abliterator
model = "meta-llama/Meta-Llama-3-70B-Instruct" # the huggingface or path to the model you're interested in loading in
dataset = [abliterator.get_harmful_instructions(), abliterator.get_harmless_instructions()] # datasets to be used for caching and testing, split by harmful/harmless
device = 'cuda' # optional: defaults to cuda
n_devices = None # optional: when set to None, defaults to `device.cuda.device_count`
cache_fname = 'my_cached_point.pth' # optional: if you need to save where you left off, you can use `save_activations(filename)` which will write out a file. This is how you load that back in.
activation_layers = None # optional: defaults to ['resid_pre', 'resid_mid', 'resid_post'] which are the residual streams. Setting to None will cache ALL activation layer types
chat_template = None # optional: defaults to Llama-3 instruction template. You can use a format string e.g. ("<system>{instruction}<end><assistant>") or a custom class with format function -- it just needs an '.format(instruction="")` function. See abliterator.ChatTemplate for a very basic structure.
negative_toks = [4250] # optional, but highly recommended: ' cannot' in Llama's tokenizer. Tokens you don't want to be seeing. Defaults to my preset for Llama-3 models
positive_toks = [23371, 40914] # optional, but highly recommended: ' Sure' and 'Sure' in Llama's tokenizer. Tokens you want to be seeing, basically. Defaults to my preset for Llama-3 models
my_model = abliterator.ModelAbliterator(
model,
dataset,
device='cuda',
n_devices=None,
cache_fname=None,
activation_layers=['resid_pre', 'resid_post', 'attn_out', 'mlp_out'],
chat_template="<system>\n{instruction}<end><assistant>",
positive_toks=positive_toks,
negative_toks=negative_toks
)Once loaded in, run the model against N samples of harmful, and N samples of harmless so it has some data to work with:
my_model.cache_activations(N=512,reset=True,preserve_harmless=True)preserve_harmless=True is generally useful, as it keeps the "desired behaviour" unaltered from any stacked modifications if you run it after some mods.
Most of the advantage of this is a lot of groundwork has been laid to make it so you aren't repeating yourself 1000 times just to try one little experiment.
save_activations('file.pth') will save your cached activations, and any currently applied modifications to the model's weights to a file so you can restore them next time you load up with cache_fname='file.pth' in your ModelAbliterator initialization.
Speaking of modding, here's a simple representation of how to pick, test, and actually apply a direction from a layer's activations:
refusal_dirs = my_model.refusal_dirs()
testing_dir = refusal_dirs['blocks.18.hook_resid_pre']
my_model.test_dir(testing_dir, N=32, use_hooks=True) # I recommend use_hooks=True for large models as it can slow things down otherwise, but use_hooks=False can give you more precise scoring to an actual weights modificationtest_dir will apply your refusal_dir to the model temporarily, and run against N samples of test data, and return a composite (negative_score, positive_score) from those runs. Generally, you want negative_score to go down, positive_score to go up.
This is one of the functions included in the library, but it's also useful for showing how this can be generalized to test a whole bunch of directions.
def find_best_refusal_dir(N=4, use_hooks=True, invert=False):
dirs = self.refusal_dirs(invert=invert)
scores = []
for direction in tqdm(dirs.items()):
score = self.test_dir(direction[1],N=N,use_hooks=use_hooks)[0]
scores.append((score,direction))
return sorted(scores,key=lambda x:x[0])And now, to apply it!
my_amazing_dir = find_best_refusal_dir()[0]
my_model.apply_refusal_dirs([my_amazing_dir],layers=None)Note the layers=None. You can supply a list here to specify which layers you want to apply the refusal direction to. None will apply it to all writable layers.
Sometimes some layers are troublesome no matter what you do. If you're worried about accidentally replacing it, you can blacklist it to prevent any alteration from occurring:
my_model.blacklist_layer(27)
my_model.blacklist_layer([i for i in range(27,30)]) # it also accepts lists!And naturally, to undo this and make sure a layer can be overwritten:
my_model.whitelist_layer(27)
By default, all layers are whitelisted. I recommend blacklisting the first and last couple layers, as those can and will have dramatic effects on outputs.
Neither of these will provide success/failure states. They will just assure the desired state in running it at that instant.
Now to make sure you've not damaged the model dramatically after applying some stuff, you can do a test run:
with my_model: # loads a temporary context with the model
ortho.apply_refusal_dir([my_new_precious_dir]) # Because this was applied in the 'with my_model:', it will be unapplied after coming out.
print(my_model.mse_harmless(N=128)) # While we've got the dir applied, this tells you the Mean Squared Error using the current cached harmless runs as "ground truth" (loss function, effectively)ortho.test(N=16,batch_size = 4) # runs N samples from the harmful test set and prints them for the user. Good way to check the model hasn't completely derailed.
# Note that by default if a test run produces a negative token, it will stop the whole batch and move on to the next. (it will show lots of '!!!!' in Llama-3's case, as that's token ID 0)
ortho.generate("How much wood could a woodchuck chuck if a woodchuck could chuck wood?") # runs and prints the prompt!Documentation coming soon.
Functionality coming soon. For now, use PyTorch's saving method, or see my notebook for an idea of how to do this yourself.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for abliterator
Similar Open Source Tools
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.

llama-on-lambda
This project provides a proof of concept for deploying a scalable, serverless LLM Generative AI inference engine on AWS Lambda. It leverages the llama.cpp project to enable the usage of more accessible CPU and RAM configurations instead of limited and expensive GPU capabilities. By deploying a container with the llama.cpp converted models onto AWS Lambda, this project offers the advantages of scale, minimizing cost, and maximizing compute availability. The project includes AWS CDK code to create and deploy a Lambda function leveraging your model of choice, with a FastAPI frontend accessible from a Lambda URL. It is important to note that you will need ggml quantized versions of your model and model sizes under 6GB, as your inference RAM requirements cannot exceed 9GB or your Lambda function will fail.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
boxcars
Boxcars is a Ruby gem that enables users to create new systems with AI composability, incorporating concepts such as LLMs, Search, SQL, Rails Active Record, Vector Search, and more. It allows users to work with Boxcars, Trains, Prompts, Engines, and VectorStores to solve problems and generate text results. The gem is designed to be user-friendly for beginners and can be extended with custom concepts. Boxcars is actively seeking ways to enhance security measures to prevent malicious actions. Users can use Boxcars for tasks like running calculations, performing searches, generating Ruby code for math operations, and interacting with APIs like OpenAI, Anthropic, and Google SERP.
llama3-tokenizer-js
JavaScript tokenizer for LLaMA 3 designed for client-side use in the browser and Node, with TypeScript support. It accurately calculates token count, has 0 dependencies, optimized running time, and somewhat optimized bundle size. Compatible with most LLaMA 3 models. Can encode and decode text, but training is not supported. Pollutes global namespace with `llama3Tokenizer` in the browser. Mostly compatible with LLaMA 3 models released by Facebook in April 2024. Can be adapted for incompatible models by passing custom vocab and merge data. Handles special tokens and fine tunes. Developed by belladore.ai with contributions from xenova, blaze2004, imoneoi, and ConProgramming.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
Tiny-Predictive-Text
Tiny-Predictive-Text is a demonstration of predictive text without an LLM, using permy.link. It provides a detailed description of the tool, including its features, benefits, and how to use it. The tool is suitable for a variety of jobs, including content writers, editors, and researchers. It can be used to perform a variety of tasks, such as generating text, completing sentences, and correcting errors.

brokk
Brokk is a code assistant designed to understand code semantically, allowing LLMs to work effectively on large codebases. It offers features like agentic search, summarizing related classes, parsing stack traces, adding source for usages, and autonomously fixing errors. Users can interact with Brokk through different panels and commands, enabling them to manipulate context, ask questions, search codebase, run shell commands, and more. Brokk helps with tasks like debugging regressions, exploring codebase, AI-powered refactoring, and working with dependencies. It is particularly useful for making complex, multi-file edits with o1pro.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.
qlora-pipe
qlora-pipe is a pipeline parallel training script designed for efficiently training large language models that cannot fit on one GPU. It supports QLoRA, LoRA, and full fine-tuning, with efficient model loading and the ability to load any dataset that Axolotl can handle. The script allows for raw text training, resuming training from a checkpoint, logging metrics to Tensorboard, specifying a separate evaluation dataset, training on multiple datasets simultaneously, and supports various models like Llama, Mistral, Mixtral, Qwen-1.5, and Cohere (Command R). It handles pipeline- and data-parallelism using Deepspeed, enabling users to set the number of GPUs, pipeline stages, and gradient accumulation steps for optimal utilization.
nagato-ai
Nagato-AI is an intuitive AI Agent library that supports multiple LLMs including OpenAI's GPT, Anthropic's Claude, Google's Gemini, and Groq LLMs. Users can create agents from these models and combine them to build an effective AI Agent system. The library is named after the powerful ninja Nagato from the anime Naruto, who can control multiple bodies with different abilities. Nagato-AI acts as a linchpin to summon and coordinate AI Agents for specific missions. It provides flexibility in programming and supports tools like Coordinator, Researcher, Critic agents, and HumanConfirmInputTool.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
For similar tasks
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.
LLMFarm
LLMFarm is an iOS and MacOS app designed to work with large language models (LLM). It allows users to load different LLMs with specific parameters, test the performance of various LLMs on iOS and macOS, and identify the most suitable model for their projects. The tool is based on ggml and llama.cpp by Georgi Gerganov and incorporates sources from rwkv.cpp by saharNooby, Mia by byroneverson, and LlamaChat by alexrozanski. LLMFarm features support for MacOS (13+) and iOS (16+), various inferences and sampling methods, Metal compatibility (not supported on Intel Mac), model setting templates, LoRA adapters support, LoRA finetune support, LoRA export as model support, and more. It also offers a range of inferences including LLaMA, GPTNeoX, Replit, GPT2, Starcoder, RWKV, Falcon, MPT, Bloom, and others. Additionally, it supports multimodal models like LLaVA, Obsidian, and MobileVLM. Users can customize inference options through JSON files and access supported models for download.
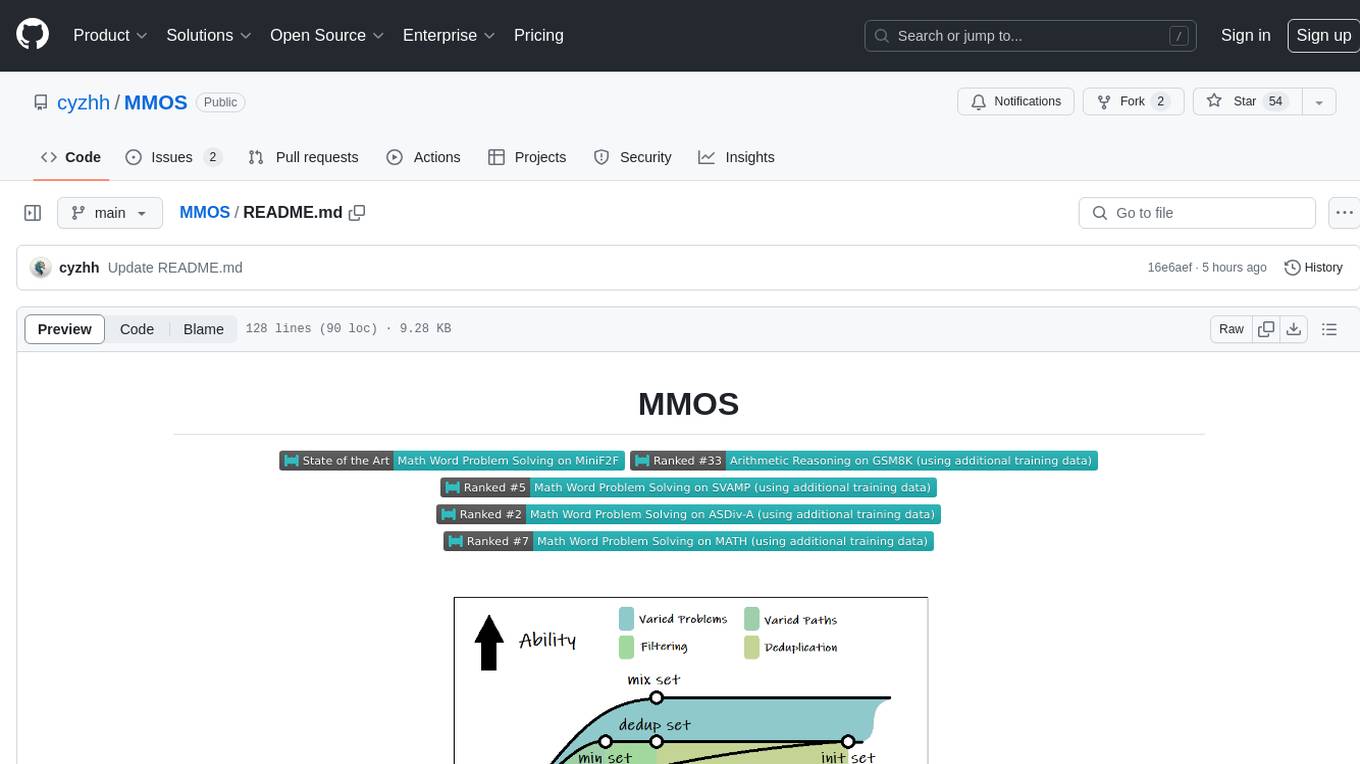
MMOS
MMOS (Mix of Minimal Optimal Sets) is a dataset designed for math reasoning tasks, offering higher performance and lower construction costs. It includes various models and data subsets for tasks like arithmetic reasoning and math word problem solving. The dataset is used to identify minimal optimal sets through reasoning paths and statistical analysis, with a focus on QA-pairs generated from open-source datasets. MMOS also provides an auto problem generator for testing model robustness and scripts for training and inference.
Korean-SAT-LLM-Leaderboard
The Korean SAT LLM Leaderboard is a benchmarking project that allows users to test their fine-tuned Korean language models on a 10-year dataset of the Korean College Scholastic Ability Test (CSAT). The project provides a platform to compare human academic ability with the performance of large language models (LLMs) on various question types to assess reading comprehension, critical thinking, and sentence interpretation skills. It aims to share benchmark data, utilize a reliable evaluation dataset curated by the Korea Institute for Curriculum and Evaluation, provide annual updates to prevent data leakage, and promote open-source LLM advancement for achieving top-tier performance on the Korean CSAT.

LMeterX
LMeterX is a professional large language model performance testing platform that supports model inference services based on large model inference frameworks and cloud services. It provides an intuitive Web interface for creating and managing test tasks, monitoring testing processes, and obtaining detailed performance analysis reports to support model deployment and optimization.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.