Best AI tools for< Test Model Performance >
20 - AI tool Sites
Plumb
Plumb is a no-code, node-based builder that empowers product, design, and engineering teams to create AI features together. It enables users to build, test, and deploy AI features with confidence, fostering collaboration across different disciplines. With Plumb, teams can ship prototypes directly to production, ensuring that the best prompts from the playground are the exact versions that go to production. It goes beyond automation, allowing users to build complex multi-tenant pipelines, transform data, and leverage validated JSON schema to create reliable, high-quality AI features that deliver real value to users. Plumb also makes it easy to compare prompt and model performance, enabling users to spot degradations, debug them, and ship fixes quickly. It is designed for SaaS teams, helping ambitious product teams collaborate to deliver state-of-the-art AI-powered experiences to their users at scale.
Encord
Encord is a complete data development platform designed for AI applications, specifically tailored for computer vision and multimodal AI teams. It offers tools to intelligently manage, clean, and curate data, streamline labeling and workflow management, and evaluate model performance. Encord aims to unlock the potential of AI for organizations by simplifying data-centric AI pipelines, enabling the building of better models and deploying high-quality production AI faster.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
Bifrost AI
Bifrost AI is a data generation engine designed for AI and robotics applications. It enables users to train and validate AI models faster by generating physically accurate synthetic datasets in 3D simulations, eliminating the need for real-world data. The platform offers pixel-perfect labels, scenario metadata, and a simulated 3D world to enhance AI understanding. Bifrost AI empowers users to create new scenarios and datasets rapidly, stress test AI perception, and improve model performance. It is built for teams at every stage of AI development, offering features like automated labeling, class imbalance correction, and performance enhancement.
Tricentis
Tricentis is an AI-powered testing tool that offers a comprehensive set of test automation capabilities to address various testing challenges. It provides end-to-end test automation solutions for a wide range of applications, including Salesforce, mobile testing, performance testing, and data integrity testing. Tricentis leverages advanced ML technologies to enable faster and smarter testing, ensuring quality at speed with reduced risk, time, and costs. The platform also offers continuous performance testing, change and data intelligence, and model-based, codeless test automation for mobile applications.
BugFree.ai
BugFree.ai is an AI-powered platform designed to help users practice system design and behavior interviews, similar to Leetcode. The platform offers a range of features to assist users in preparing for technical interviews, including mock interviews, real-time feedback, and personalized study plans. With BugFree.ai, users can improve their problem-solving skills and gain confidence in tackling complex interview questions.
Testmyprompt
Testmyprompt is an AI prompt software designed for AI Automation Agencies. It allows users to build and test AI prompts quickly and efficiently, saving significant time and ensuring consistency in prompt creation. The tool enables users to simulate thousands of conversations in seconds, import AI settings, add test questions with variations and success criteria, and analyze AI performance to identify areas of improvement. Testmyprompt helps users optimize their AI models for better performance and customer interaction.
Langtail
Langtail is a platform that helps developers build, test, and deploy AI-powered applications. It provides a suite of tools to help developers debug prompts, run tests, and monitor the performance of their AI models. Langtail also offers a community forum where developers can share tips and tricks, and get help from other users.
Narrow AI
Narrow AI is an AI application that autonomously writes, monitors, and optimizes prompts for any model, enabling users to ship AI features 10x faster at a fraction of the cost. It streamlines the workflow by allowing users to test new models in minutes, compare prompt performance, and deploy on the optimal model for their use case. Narrow AI helps users maximize efficiency by generating expert-level prompts, adapting prompts to new models, and optimizing prompts for quality, cost, and speed.
Prompt Dev Tool
Prompt Dev Tool is an AI application designed to boost prompt engineering efficiency by helping users create, test, and optimize AI prompts for better results. It offers an intuitive interface, real-time feedback, model comparison, variable testing, prompt iteration, and advanced analytics. The tool is suitable for both beginners and experts, providing detailed insights to enhance AI interactions and improve outcomes.
Prelaunch.com
Prelaunch.com is an AI-powered platform that provides bullet-proof insights from ready-to-buy customers for product development and market validation. It offers a range of features including performance dashboard, surveys, AI idea validation, AI market research, and next-gen focus groups. The platform helps businesses test and evaluate demand for products before production, ensuring optimal pricing, market positioning, and business model testing. Prelaunch.com leverages real-world audiences to gather genuine insights through surveys, interviews, and focus groups, enabling users to make informed decisions based on validated data.
ConsoleX
ConsoleX is an advanced AI tool that offers a wide range of functionalities to unlock infinite possibilities in the field of artificial intelligence. It provides users with a powerful platform to develop, test, and deploy AI models with ease. With cutting-edge features and intuitive interface, ConsoleX is designed to cater to the needs of both beginners and experts in the AI domain. Whether you are a data scientist, researcher, or developer, ConsoleX empowers you to explore the full potential of AI technology and drive innovation in your projects.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
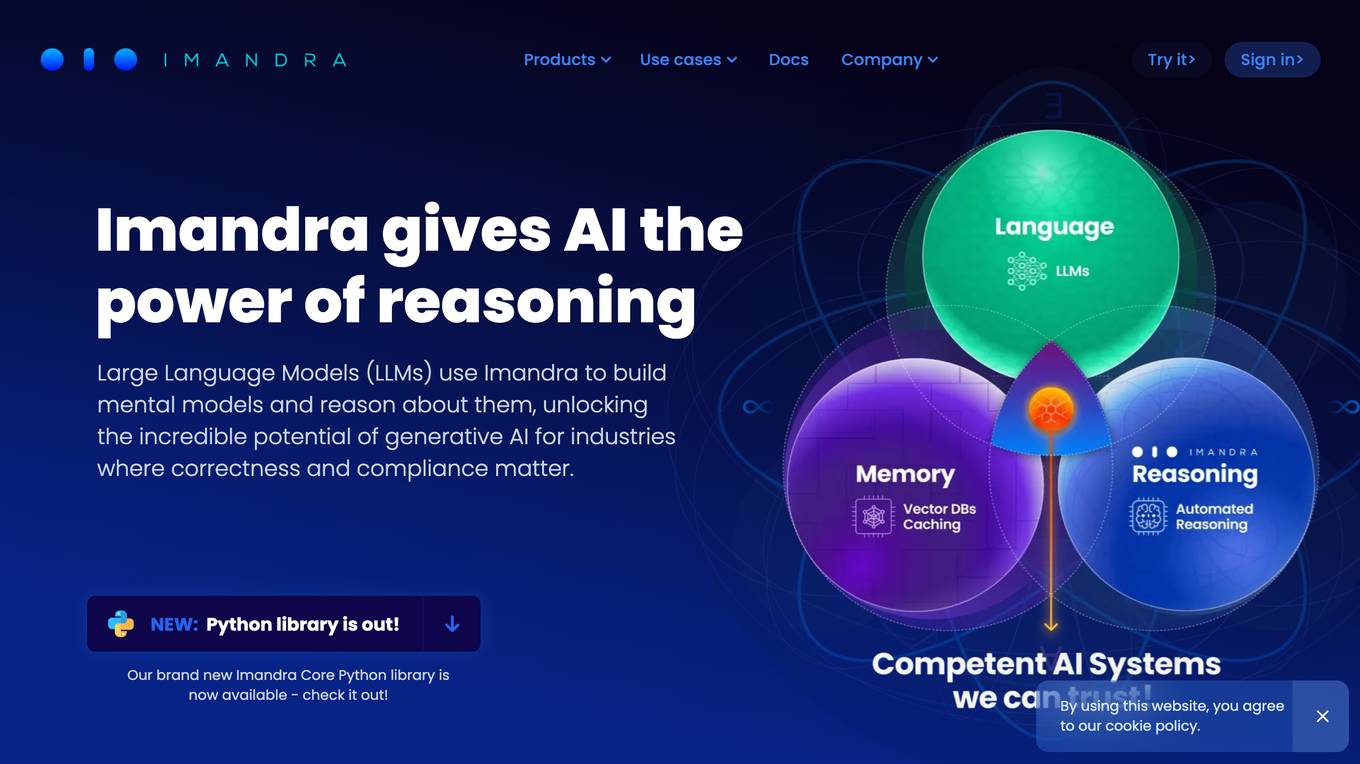
Imandra
Imandra is a company that provides automated logical reasoning for Large Language Models (LLMs). Imandra's technology allows LLMs to build mental models and reason about them, unlocking the potential of generative AI for industries where correctness and compliance matter. Imandra's platform is used by leading financial firms, the US Air Force, and DARPA.

Freeplay
Freeplay is a tool that helps product teams experiment, test, monitor, and optimize AI features for customers. It provides a single pane of glass for the entire team, lightweight developer SDKs for Python, Node, and Java, and deployment options to meet compliance needs. Freeplay also offers best practices for the entire AI development lifecycle.
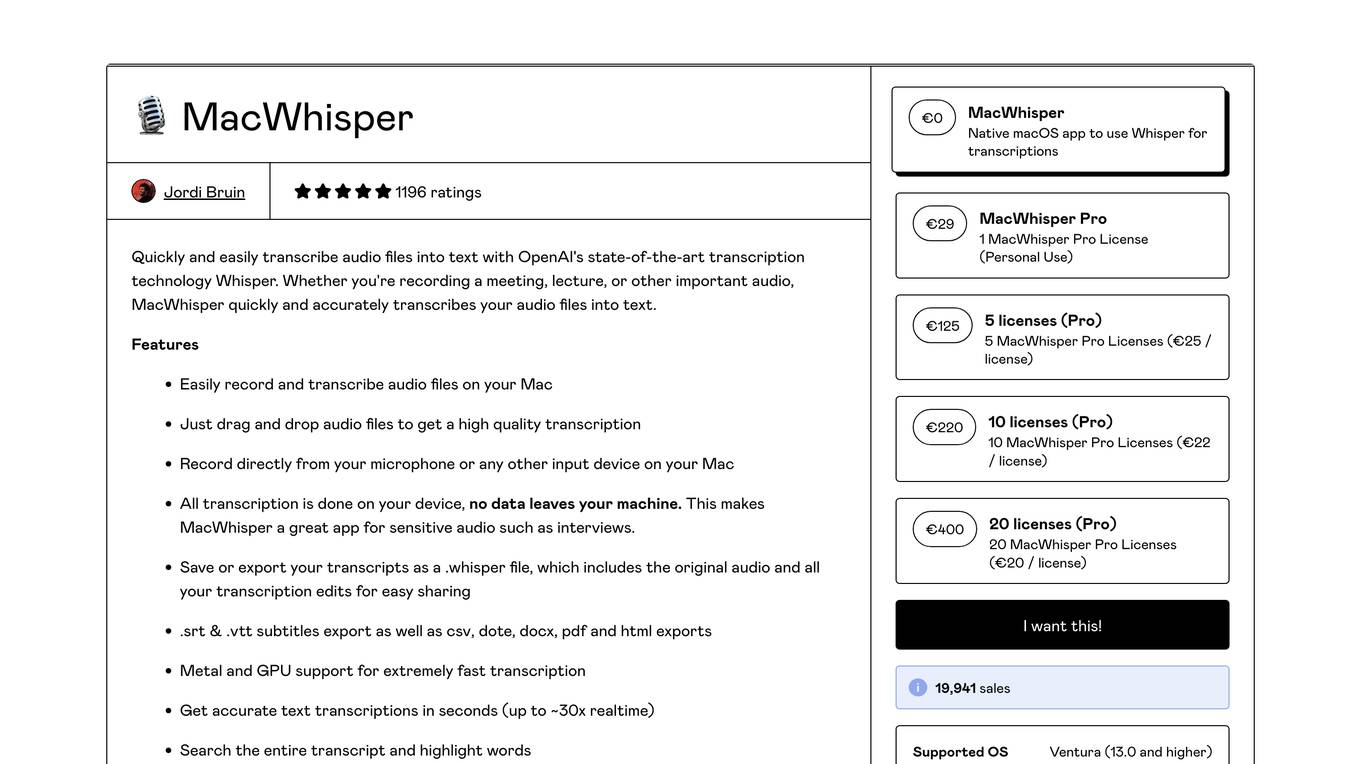
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.

LLM Clash
LLM Clash is a web-based application that allows users to compare the outputs of different large language models (LLMs) on a given task. Users can input a prompt and select which LLMs they want to compare. The application will then display the outputs of the LLMs side-by-side, allowing users to compare their strengths and weaknesses.
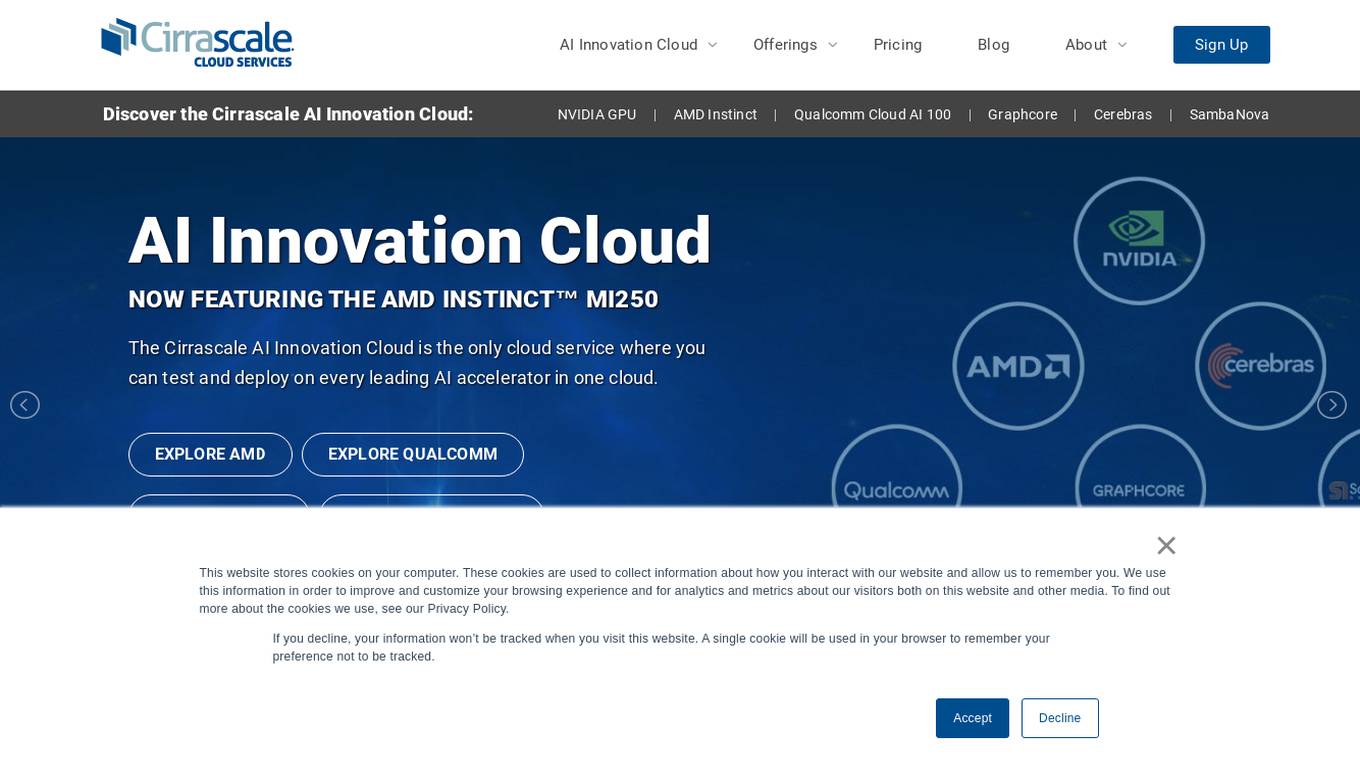
Cirrascale Cloud Services
Cirrascale Cloud Services is an AI tool that offers cloud solutions for Artificial Intelligence applications. The platform provides a range of cloud services and products tailored for AI innovation, including NVIDIA GPU Cloud, AMD Instinct Series Cloud, Qualcomm Cloud, Graphcore, Cerebras, and SambaNova. Cirrascale's AI Innovation Cloud enables users to test and deploy on leading AI accelerators in one cloud, democratizing AI by delivering high-performance AI compute and scalable deep learning solutions. The platform also offers professional and managed services, tailored multi-GPU server options, and high-throughput storage and networking solutions to accelerate development, training, and inference workloads.

Cerebium
Cerebium is a serverless AI infrastructure platform that allows teams to build, test, and deploy AI applications quickly and efficiently. With a focus on speed, performance, and cost optimization, Cerebium offers a range of features and tools to simplify the development and deployment of AI projects. The platform ensures high reliability, security, and compliance while providing real-time logging, cost tracking, and observability tools. Cerebium also offers GPU variety and effortless autoscaling to meet the diverse needs of developers and businesses.
5 - Open Source AI Tools
LLMFarm
LLMFarm is an iOS and MacOS app designed to work with large language models (LLM). It allows users to load different LLMs with specific parameters, test the performance of various LLMs on iOS and macOS, and identify the most suitable model for their projects. The tool is based on ggml and llama.cpp by Georgi Gerganov and incorporates sources from rwkv.cpp by saharNooby, Mia by byroneverson, and LlamaChat by alexrozanski. LLMFarm features support for MacOS (13+) and iOS (16+), various inferences and sampling methods, Metal compatibility (not supported on Intel Mac), model setting templates, LoRA adapters support, LoRA finetune support, LoRA export as model support, and more. It also offers a range of inferences including LLaMA, GPTNeoX, Replit, GPT2, Starcoder, RWKV, Falcon, MPT, Bloom, and others. Additionally, it supports multimodal models like LLaVA, Obsidian, and MobileVLM. Users can customize inference options through JSON files and access supported models for download.
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.
MMOS
MMOS (Mix of Minimal Optimal Sets) is a dataset designed for math reasoning tasks, offering higher performance and lower construction costs. It includes various models and data subsets for tasks like arithmetic reasoning and math word problem solving. The dataset is used to identify minimal optimal sets through reasoning paths and statistical analysis, with a focus on QA-pairs generated from open-source datasets. MMOS also provides an auto problem generator for testing model robustness and scripts for training and inference.
Korean-SAT-LLM-Leaderboard
The Korean SAT LLM Leaderboard is a benchmarking project that allows users to test their fine-tuned Korean language models on a 10-year dataset of the Korean College Scholastic Ability Test (CSAT). The project provides a platform to compare human academic ability with the performance of large language models (LLMs) on various question types to assess reading comprehension, critical thinking, and sentence interpretation skills. It aims to share benchmark data, utilize a reliable evaluation dataset curated by the Korea Institute for Curriculum and Evaluation, provide annual updates to prevent data leakage, and promote open-source LLM advancement for achieving top-tier performance on the Korean CSAT.

LMeterX
LMeterX is a professional large language model performance testing platform that supports model inference services based on large model inference frameworks and cloud services. It provides an intuitive Web interface for creating and managing test tasks, monitoring testing processes, and obtaining detailed performance analysis reports to support model deployment and optimization.
20 - OpenAI Gpts
Business Model Advisor
Business model expert, create detailed reports based on business ideas.
TuringGPT
The Turing Test, first named the imitation game by Alan Turing in 1950, is a measure of a machine's capacity to demonstrate intelligence that's either equal to or indistinguishable from human intelligence.



AdversarialGPT
Adversarial AI expert aiding in AI red teaming, informed by cutting-edge industry research (early dev)
Test Shaman
Test Shaman: Guiding software testing with Grug wisdom and humor, balancing fun with practical advice.
Raven's Progressive Matrices Test
Provides Raven's Progressive Matrices test with explanations and calculates your IQ score.

IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.
Test Case GPT
I will provide guidance on testing, verification, and validation for QA roles.

GRE Test Vocabulary Learning
Helps user learn essential vocabulary for GRE test with multiple choice questions