
LMeterX
Professional Load Testing for Any LLM Services or Routers. 大模型推理服务压测工具,性能测试结果AI分析
Stars: 59

LMeterX is a professional large language model performance testing platform that supports model inference services based on large model inference frameworks and cloud services. It provides an intuitive Web interface for creating and managing test tasks, monitoring testing processes, and obtaining detailed performance analysis reports to support model deployment and optimization.
README:




LMeterX is a professional large language model performance testing platform that can be applied to model inference services based on large model inference frameworks (such as LiteLLM, vLLM, TensorRT-LLM, LMDeploy, and others), and also supports performance testing for cloud services like Azure OpenAI, AWS Bedrock, Google Vertex AI, and other major cloud providers. Through an intuitive Web interface, users can easily create and manage test tasks, monitor testing processes in real-time, and obtain detailed performance analysis reports, providing reliable data support for model deployment and performance optimization.

- Universal Framework Support - Compatible with mainstream inference frameworks (vLLM, LiteLLM, TensorRT-LLM) and cloud services (Azure, AWS, Google Cloud)
- Full Model Compatibility - Supports mainstream LLMs like GPT, Claude, and Llama with one-click stress testing
- High-Load Stress Testing - Simulates high-concurrency requests to accurately detect model performance limits
-
Multi-Scenario Coverage - Supports streaming/non-streaming, supports text/multimodal/custom datasets
- Professional Metrics - Core performance metrics including first token latency, throughput(RPS、TPS), and success rate
-
AI Smart Reports - AI-powered performance analysis
, multi-dimensional model comparison and visualization
- Web Console - One-stop management for task creation, stopping, status tracking, and full-chain log monitoring
- Enterprise-level Deployment - Docker containerization with elastic scaling and distributed deployment support
| Dimension | LMeterX | EvalScope | llmperf |
|---|---|---|---|
| Usage | Web UI for full-lifecycle task creation, monitoring & stop (load-test) | CLI for ModelScope ecosystem (eval & load-test) | CLI, Ray-based (load-test) |
| Concurrency & Stress | Multi-process / multi-task, enterprise-scale load testing | Command-line concurrency (--parallel, --rate) |
Command-line concurrency |
| Test Report | Multi-model / multi-version comparison, AI analysis, visual dashboard | Basic report + visual charts (requires gradio, plotly, etc.) | Simple report |
| Model & Data Support | OpenAI-compatible, custom data & model interfaces | OpenAI-compatible by default; extending APIs needs custom code | OpenAI-compatible |
| Deployment & Scaling | Docker / K8s ready, easy horizontal scaling |
pip install or source code |
Source code only |
LMeterX adopts a microservices architecture design, consisting of four core components:
- Backend Service: FastAPI-based REST API service responsible for task management and result storage
- Load Testing Engine: Locust-based load testing engine that executes actual performance testing tasks
- Frontend Interface: Modern Web interface based on React + TypeScript + Ant Design
- MySQL Database: Stores test tasks, result data, and configuration information

- Docker 20.10.0+
- Docker Compose 2.0.0+
- At least 4GB available memory
- At least 5GB available disk space
Complete Deployment Guide: See Complete Deployment Guide for detailed instructions on all deployment methods
Use pre-built Docker images to start all services with one click:
# Download and run one-click deployment script
curl -fsSL https://raw.githubusercontent.com/MigoXLab/LMeterX/main/quick-start.sh | bash# Download the deployment file docker-compose.yml
curl -fsSL -o docker-compose.yml https://raw.githubusercontent.com/MigoXLab/LMeterX/main/docker-compose.yml
# Start multiple instances using the --scale
# Start 2 backends + 2 engines (the number can be adjusted as needed)
docker compose up -d --scale backend=2 --scale engine=2- Access Web Interface: Open http://localhost:8080
-
Create Test Task: Navigate to Test Tasks → Create Task, configure LLM API request information, test data, and request-response field mapping
- 2.1 Basic Information: For
/chat/completionsAPI, you only need to configure API path, model, and response mode. You can also supplement the complete payload in request parameters. - 2.2 Data Payload: Select built-in text datasets/multimodal datasets as needed, or upload custom JSONL data files.
- 2.3 Field Mapping: Configure the prompt field path in payload, and response data paths for model output content, reasoning_content fields, usage fields, etc. This field mapping is crucial for updating request parameters with datasets and correctly parsing streaming/non-streaming responses.
- 2.1 Basic Information: For
- API Testing: In Test Tasks → Create Task, click the "Test" button in the Basic Information panel to quickly test API connectivity Note: For quick API response, it's recommended to use simple prompts when testing API connectivity.
- Real-time Monitoring: Navigate to Test Tasks → Logs/Monitoring Center to view full-chain test logs and troubleshoot exceptions
- Result Analysis: Navigate to Test Tasks → Results to view detailed performance results and export reports
- Result Comparison: Navigate to Model Arena to select multiple models or versions for multi-dimensional performance comparison
- AI Analysis: In Test Tasks → Results/Model Arena, after configuring AI analysis service, support intelligent performance evaluation for single/multiple tasks
# ================= Database Configuration =================
DB_HOST=mysql # Database host (container name or IP)
DB_PORT=3306 # Database port
DB_USER=lmeterx # Database username
DB_PASSWORD=lmeterx_password # Database password (use secrets management in production)
DB_NAME=lmeterx # Database name
# ================= Frontend Configuration =================
VITE_API_BASE_URL=/api # Base API URL for frontend requests (supports reverse proxy)
# ================= High-Concurrency Load Testing Deployment Requirements =================
# When concurrent users exceed this threshold, the system will automatically enable multi-process mode (requires multi-core CPU support)
MULTIPROCESS_THRESHOLD=1000
# Minimum number of concurrent users each child process should handle (prevents excessive processes and resource waste)
MIN_USERS_PER_PROCESS=600
# ⚠️ IMPORTANT NOTES:
# - When concurrency ≥ 1000, enabling multi-process mode is strongly recommended for performance.
# - Multi-process mode requires multi-core CPU resources — ensure your deployment environment meets these requirements.
# ================= Deployment Resource Limits =================
deploy:
resources:
limits:
cpus: '2.0' # Recommended minimum: 2 CPU cores (4+ cores recommended for high-concurrency scenarios)
memory: 2G # Memory limit — adjust based on actual load (minimum recommended: 2G)
We welcome all forms of contributions! Please read our Contributing Guide for details.
LMeterX adopts a modern technology stack to ensure system reliability and maintainability:
- Backend Service: Python + FastAPI + SQLAlchemy + MySQL
- Load Testing Engine: Python + Locust + Custom Extensions
- Frontend Interface: React + TypeScript + Ant Design + Vite
- Deployment & Operations: Docker + Docker Compose + Nginx
LMeterX/
├── backend/ # Backend service
├── st_engine/ # Load testing engine service
├── frontend/ # Frontend service
├── docs/ # Documentation directory
├── docker-compose.yml # Docker Compose configuration
├── Makefile # Run complete code checks
├── README.md # English README
- Fork the Project to your GitHub account
- Clone Your Fork, create a development branch for development
- Follow Code Standards, use clear commit messages (follow conventional commit standards)
-
Run Code Checks: Before submitting PR, ensure code checks, formatting, and tests all pass, you can run
make all - Write Clear Documentation: Write corresponding documentation for new features or changes
- Actively Participate in Review: Actively respond to feedback during the review process
- [ ] Support for client resource monitoring
- [ ] CLI command-line tool
- [ ] Support for
/v1/embeddingand/v1/rerankAPI stress testing
- Deployment Guide - Detailed deployment instructions and configuration guide
- Contributing Guide - How to participate in project development and contribute code
Thanks to all developers who have contributed to the LMeterX project:
- @LuckyYC - Project maintainer & Core developer
- @del-zhenwu - Core developer
This project is licensed under the Apache 2.0 License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LMeterX
Similar Open Source Tools
LMeterX
LMeterX is a professional large language model performance testing platform that supports model inference services based on large model inference frameworks and cloud services. It provides an intuitive Web interface for creating and managing test tasks, monitoring testing processes, and obtaining detailed performance analysis reports to support model deployment and optimization.
legacy-use
Legacy-use is a tool that transforms legacy applications into modern REST APIs using AI. It allows users to dynamically generate and customize API endpoints for legacy or desktop applications, access systems running legacy software, track and resolve issues with built-in observability tools, ensure secure and compliant automation, choose model providers independently, and deploy with enterprise-grade security and compliance. The tool provides a quick setup process, automatic API key generation, and supports Windows VM automation. It offers a user-friendly interface for adding targets, running jobs, and writing effective prompts. Legacy-use also supports various connectivity technologies like OpenVPN, Tailscale, WireGuard, VNC, RDP, and TeamViewer. Telemetry data is collected anonymously to improve the product, and users can opt-out of tracking. Optional configurations include enabling OpenVPN target creation and displaying backend endpoints documentation. Contributions to the project are welcome.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
astron-rpa
AstronRPA is an enterprise-grade Robotic Process Automation (RPA) desktop application that supports low-code/no-code development. It enables users to rapidly build workflows and automate desktop software and web pages. The tool offers comprehensive automation support for various applications, highly component-based design, enterprise-grade security and collaboration features, developer-friendly experience, native agent empowerment, and multi-channel trigger integration. It follows a frontend-backend separation architecture with components for system operations, browser automation, GUI automation, AI integration, and more. The tool is deployed via Docker and designed for complex RPA scenarios.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.

MassGen
MassGen is a cutting-edge multi-agent system that leverages the power of collaborative AI to solve complex tasks. It assigns a task to multiple AI agents who work in parallel, observe each other's progress, and refine their approaches to converge on the best solution to deliver a comprehensive and high-quality result. The system operates through an architecture designed for seamless multi-agent collaboration, with key features including cross-model/agent synergy, parallel processing, intelligence sharing, consensus building, and live visualization. Users can install the system, configure API settings, and run MassGen for various tasks such as question answering, creative writing, research, development & coding tasks, and web automation & browser tasks. The roadmap includes plans for advanced agent collaboration, expanded model, tool & agent integration, improved performance & scalability, enhanced developer experience, and a web interface.
leetcode-py
A Python package to generate professional LeetCode practice environments. Features automated problem generation from LeetCode URLs, beautiful data structure visualizations (TreeNode, ListNode, GraphNode), and comprehensive testing with 10+ test cases per problem. Built with professional development practices including CI/CD, type hints, and quality gates. The tool provides a modern Python development environment with production-grade features such as linting, test coverage, logging, and CI/CD pipeline. It also offers enhanced data structure visualization for debugging complex structures, flexible notebook support, and a powerful CLI for generating problems anywhere.
finite-monkey-engine
FiniteMonkey is an advanced vulnerability mining engine powered purely by GPT, requiring no prior knowledge base or fine-tuning. Its effectiveness significantly surpasses most current related research approaches. The tool is task-driven, prompt-driven, and focuses on prompt design, leveraging 'deception' and hallucination as key mechanics. It has helped identify vulnerabilities worth over $60,000 in bounties. The tool requires PostgreSQL database, OpenAI API access, and Python environment for setup. It supports various languages like Solidity, Rust, Python, Move, Cairo, Tact, Func, Java, and Fake Solidity for scanning. FiniteMonkey is best suited for logic vulnerability mining in real projects, not recommended for academic vulnerability testing. GPT-4-turbo is recommended for optimal results with an average scan time of 2-3 hours for medium projects. The tool provides detailed scanning results guide and implementation tips for users.
GMTalker
GMTalker is an interactive digital human rendered by Unreal Engine, developed by the Media Intelligence Team at Bright Laboratory. The system integrates speech recognition, speech synthesis, natural language understanding, and lip-sync animation driving. It supports rapid deployment on Windows with only 2GB of VRAM required. The project showcases two 3D cartoon digital human avatars suitable for presentations, expansions, and commercial integration.
bumblecore
BumbleCore is a hands-on large language model training framework that allows complete control over every training detail. It provides manual training loop, customizable model architecture, and support for mainstream open-source models. The framework follows core principles of transparency, flexibility, and efficiency. BumbleCore is suitable for deep learning researchers, algorithm engineers, learners, and enterprise teams looking for customization and control over model training processes.
zcf
ZCF (Zero-Config Claude-Code Flow) is a tool that provides zero-configuration, one-click setup for Claude Code with bilingual support, intelligent agent system, and personalized AI assistant. It offers an interactive menu for easy operations and direct commands for quick execution. The tool supports bilingual operation with automatic language switching and customizable AI output styles. ZCF also includes features like BMad Workflow for enterprise-grade workflow system, Spec Workflow for structured feature development, CCR (Claude Code Router) support for proxy routing, and CCometixLine for real-time usage tracking. It provides smart installation, complete configuration management, and core features like professional agents, command system, and smart configuration. ZCF is cross-platform compatible, supports Windows and Termux environments, and includes security features like dangerous operation confirmation mechanism.
afc-crs-all-you-need-is-a-fuzzing-brain
All You Need Is A Fuzzing Brain is an AI-driven automated vulnerability detection and remediation framework developed for the 2025 DARPA AIxCC finals. It leverages multiple LLM providers for intelligent vulnerability detection, offers 23+ specialized strategies for POV generation and patch synthesis, generates and validates patches automatically, integrates seamlessly with Google's fuzzing infrastructure, and supports vulnerability detection in C/C++ and Java. Users can perform tasks such as Delta Scan, Full Scan, and SARIF Analysis for specific commits, repository-wide analysis, and validation/patching from static analysis reports, respectively. The tool can be used via Docker or by installing from source, and citations are provided for research purposes.
superagentx
SuperAgentX is a lightweight open-source AI framework designed for multi-agent applications with Artificial General Intelligence (AGI) capabilities. It offers goal-oriented multi-agents with retry mechanisms, easy deployment through WebSocket, RESTful API, and IO console interfaces, streamlined architecture with no major dependencies, contextual memory using SQL + Vector databases, flexible LLM configuration supporting various Gen AI models, and extendable handlers for integration with diverse APIs and data sources. It aims to accelerate the development of AGI by providing a powerful platform for building autonomous AI agents capable of executing complex tasks with minimal human intervention.

executorch
ExecuTorch is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch Edge ecosystem and enables efficient deployment of PyTorch models to edge devices. Key value propositions of ExecuTorch are: * **Portability:** Compatibility with a wide variety of computing platforms, from high-end mobile phones to highly constrained embedded systems and microcontrollers. * **Productivity:** Enabling developers to use the same toolchains and SDK from PyTorch model authoring and conversion, to debugging and deployment to a wide variety of platforms. * **Performance:** Providing end users with a seamless and high-performance experience due to a lightweight runtime and utilizing full hardware capabilities such as CPUs, NPUs, and DSPs.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.

semantic-router
The Semantic Router is an intelligent routing tool that utilizes a Mixture-of-Models (MoM) approach to direct OpenAI API requests to the most suitable models based on semantic understanding. It enhances inference accuracy by selecting models tailored to different types of tasks. The tool also automatically selects relevant tools based on the prompt to improve tool selection accuracy. Additionally, it includes features for enterprise security such as PII detection and prompt guard to protect user privacy and prevent misbehavior. The tool implements similarity caching to reduce latency. The comprehensive documentation covers setup instructions, architecture guides, and API references.
For similar tasks
skyrim
Skyrim is a weather forecasting tool that enables users to run large weather models using consumer-grade GPUs. It provides access to state-of-the-art foundational weather models through a well-maintained infrastructure. Users can forecast weather conditions, such as wind speed and direction, by running simulations on their own GPUs or using modal volume or cloud services like s3 buckets. Skyrim supports various large weather models like Graphcast, Pangu, Fourcastnet, and DLWP, with plans for future enhancements like ensemble prediction and model quantization.
chinese-llm-benchmark
The Chinese LLM Benchmark is a continuous evaluation list of large models in CLiB, covering a wide range of commercial and open-source models from various companies and research institutions. It supports multidimensional evaluation of capabilities including classification, information extraction, reading comprehension, data analysis, Chinese encoding efficiency, and Chinese instruction compliance. The benchmark not only provides capability score rankings but also offers the original output results of all models for interested individuals to score and rank themselves.
gollm
gollm is a Go package designed to simplify interactions with Large Language Models (LLMs) for AI engineers and developers. It offers a unified API for multiple LLM providers, easy provider and model switching, flexible configuration options, advanced prompt engineering, prompt optimization, memory retention, structured output and validation, provider comparison tools, high-level AI functions, robust error handling and retries, and extensible architecture. The package enables users to create AI-powered golems for tasks like content creation workflows, complex reasoning tasks, structured data generation, model performance analysis, prompt optimization, and creating a mixture of agents.
LMeterX
LMeterX is a professional large language model performance testing platform that supports model inference services based on large model inference frameworks and cloud services. It provides an intuitive Web interface for creating and managing test tasks, monitoring testing processes, and obtaining detailed performance analysis reports to support model deployment and optimization.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.
CodeFuse-ModelCache
Codefuse-ModelCache is a semantic cache for large language models (LLMs) that aims to optimize services by introducing a caching mechanism. It helps reduce the cost of inference deployment, improve model performance and efficiency, and provide scalable services for large models. The project caches pre-generated model results to reduce response time for similar requests and enhance user experience. It integrates various embedding frameworks and local storage options, offering functionalities like cache-writing, cache-querying, and cache-clearing through RESTful API. The tool supports multi-tenancy, system commands, and multi-turn dialogue, with features for data isolation, database management, and model loading schemes. Future developments include data isolation based on hyperparameters, enhanced system prompt partitioning storage, and more versatile embedding models and similarity evaluation algorithms.
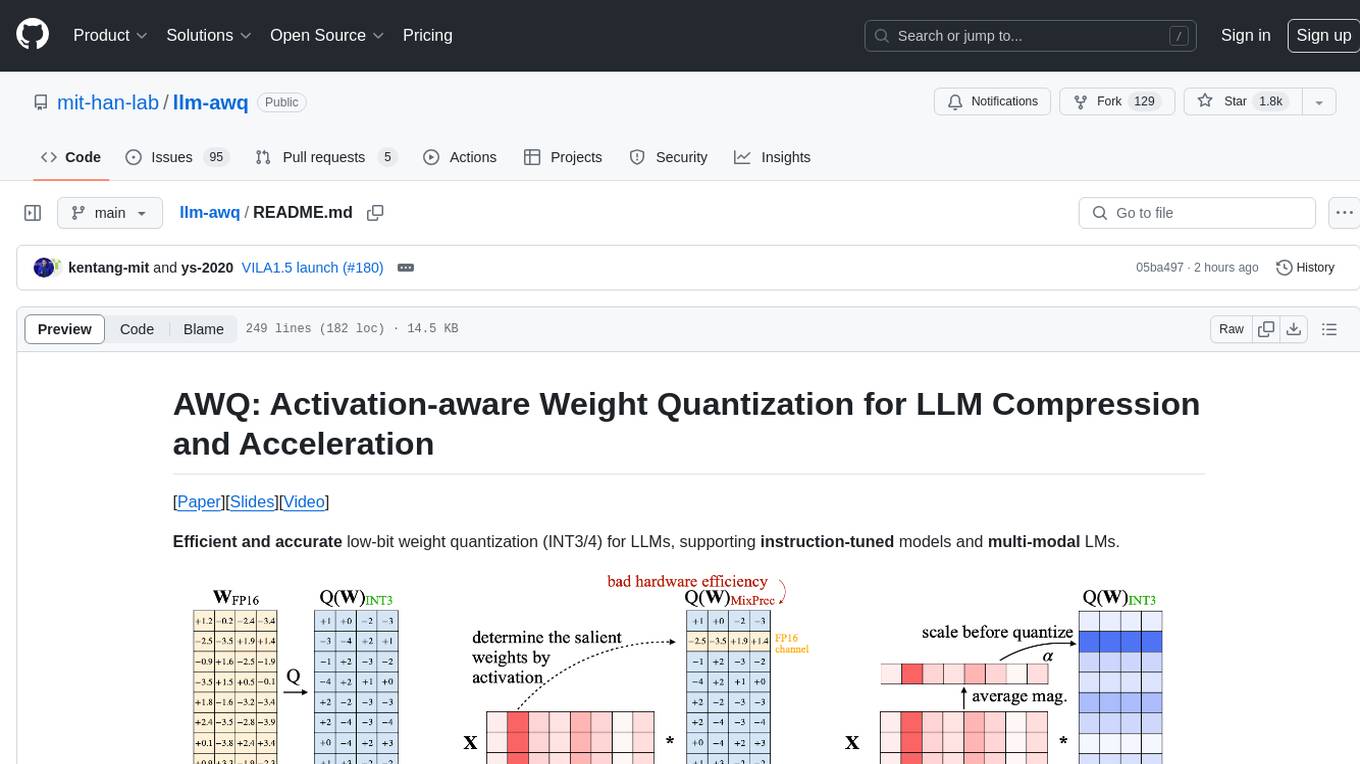
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
For similar jobs

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.
generative-bi-using-rag
Generative BI using RAG on AWS is a comprehensive framework designed to enable Generative BI capabilities on customized data sources hosted on AWS. It offers features such as Text-to-SQL functionality for querying data sources using natural language, user-friendly interface for managing data sources, performance enhancement through historical question-answer ranking, and entity recognition. It also allows customization of business information, handling complex attribution analysis problems, and provides an intuitive question-answering UI with a conversational approach for complex queries.

azure-functions-openai-extension
Azure Functions OpenAI Extension is a project that adds support for OpenAI LLM (GPT-3.5-turbo, GPT-4) bindings in Azure Functions. It provides NuGet packages for various functionalities like text completions, chat completions, assistants, embeddings generators, and semantic search. The project requires .NET 6 SDK or greater, Azure Functions Core Tools v4.x, and specific settings in Azure Function or local settings for development. It offers features like text completions, chat completion, assistants with custom skills, embeddings generators for text relatedness, and semantic search using vector databases. The project also includes examples in C# and Python for different functionalities.
edge2ai-workshop
The edge2ai-workshop repository provides a hands-on workshop for building an IoT Predictive Maintenance workflow. It includes lab exercises for setting up components like NiFi, Streams Processing, Data Visualization, and more on a single host. The repository also covers use cases such as credit card fraud detection. Users can follow detailed instructions, prerequisites, and connectivity guidelines to connect to their cluster and explore various services. Additionally, troubleshooting tips are provided for common issues like MiNiFi not sending messages or CEM not picking up new NARs.
cb-tumblebug
CB-Tumblebug (CB-TB) is a system for managing multi-cloud infrastructure consisting of resources from multiple cloud service providers. It provides an overview, features, and architecture. The tool supports various cloud providers and resource types, with ongoing development and localization efforts. Users can deploy a multi-cloud infra with GPUs, enjoy multiple LLMs in parallel, and utilize LLM-related scripts. The tool requires Linux, Docker, Docker Compose, and Golang for building the source. Users can run CB-TB with Docker Compose or from the Makefile, set up prerequisites, contribute to the project, and view a list of contributors. The tool is licensed under an open-source license.
yu-picture
The 'yu-picture' project is an educational project that provides complete video tutorials, text tutorials, resume writing, interview question solutions, and Q&A services to help you improve your project skills and enhance your resume. It is an enterprise-level intelligent collaborative cloud image library platform based on Vue 3 + Spring Boot + COS + WebSocket. The platform has a wide range of applications, including public image uploading and retrieval, image analysis for administrators, private image management for individual users, and real-time collaborative image editing for enterprises. The project covers file management, content retrieval, permission control, and real-time collaboration, using various programming concepts, architectural design methods, and optimization strategies to ensure high-speed iteration and stable operation.
AmazonSageMakerCourse
Amazon SageMaker Course is a comprehensive guide for AWS Certified Machine Learning Specialty (MLS-C01) that covers training, optimizing, deploying, and integrating machine learning models in the AWS cloud. The course includes hands-on experience with AWS built-in algorithms, Bring Your Own models, and ready-to-use AI capabilities. It also provides a complete guide to AWS Certified Machine Learning – Specialty certification, along with a high-quality timed practice test. Participants will learn how to integrate trained models into their applications and receive prompt support through the course Q&A forum and private messaging.
aimeos-headless
Aimeos headless distribution is an ultra-fast, cloud-native, and API-first headless ecommerce solution for Laravel. It offers a full-featured e-commerce package with features like JSON REST API, GraphQL API, multi-vendor support, subscriptions, block/tier pricing, admin backend, and more. The distribution is highly customizable, extensible, and suitable for multi-tenant e-commerce SaaS solutions. It supports multiple languages, AI-based text translation, and provides secure and high-quality source code. Aimeos is designed for AWS, Google, Azure, and Kubernetes based clouds, and can handle a wide range of products efficiently.