Best AI tools for< Benchmark Model >
20 - AI tool Sites

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.

Gorilla
Gorilla is an AI tool that integrates a large language model (LLM) with massive APIs to enable users to interact with a wide range of services. It offers features such as training the model to support parallel functions, benchmarking LLMs on function-calling capabilities, and providing a runtime for executing LLM-generated actions like code and API calls. Gorilla is open-source and focuses on enhancing interaction between apps and services with human-out-of-loop functionality.
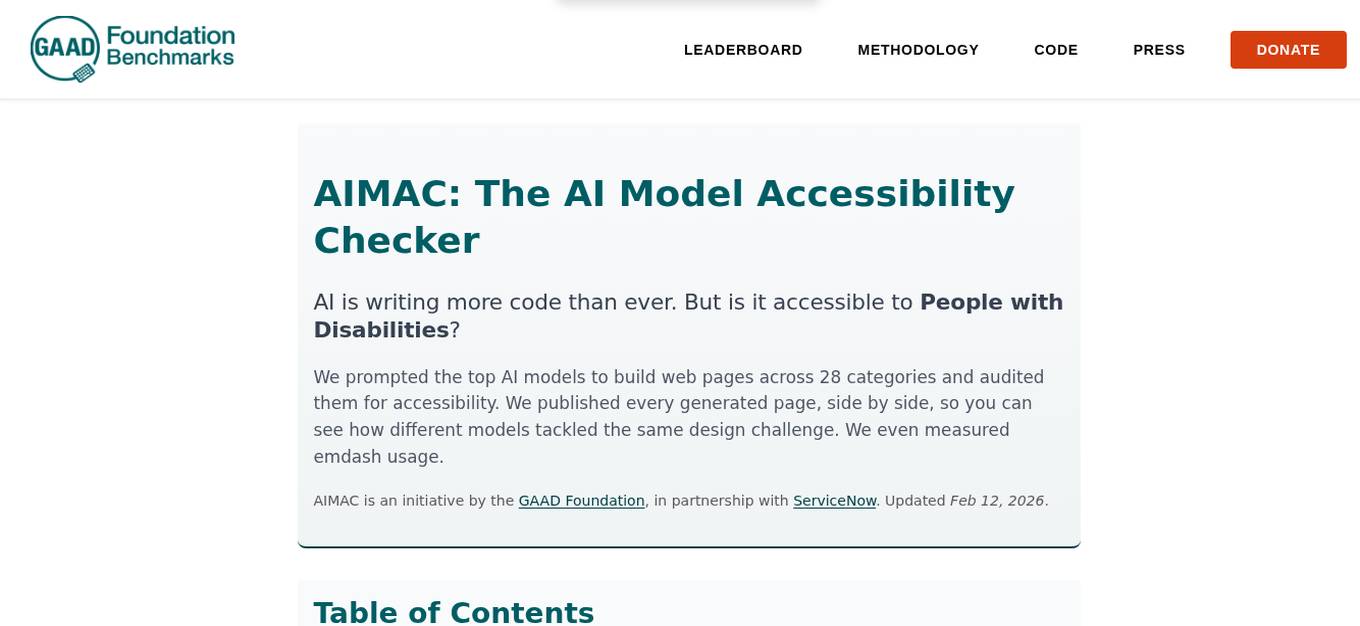
AIMAC Leaderboard
AIMAC Leaderboard is an AI Model Accessibility Checker that evaluates the accessibility of web pages generated by AI models across 28 categories. It compares top AI models side by side, auditing them for accessibility and measuring their performance. The initiative aims to ensure that AI models write accessible code by default. The project is a collaboration between the GAAD Foundation and ServiceNow, providing insights into how different models handle the same design challenges.
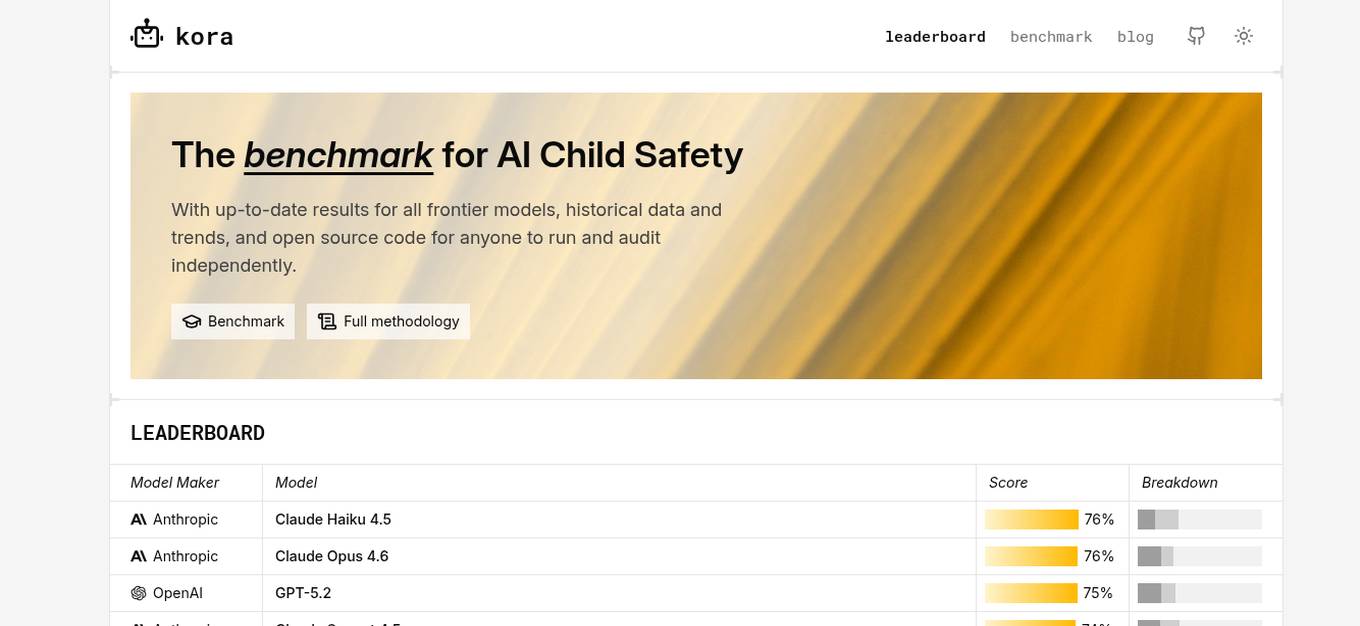
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.
Embedl
Embedl is an AI tool that specializes in developing advanced solutions for efficient AI deployment in embedded systems. With a focus on deep learning optimization, Embedl offers a cost-effective solution that reduces energy consumption and accelerates product development cycles. The platform caters to industries such as automotive, aerospace, and IoT, providing cutting-edge AI products that drive innovation and competitive advantage.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
Spotrank.ai
Spotrank.ai is an AI-powered platform that provides advanced analytics and insights for businesses and individuals. It leverages artificial intelligence algorithms to analyze data and generate valuable reports to help users make informed decisions. The platform offers a user-friendly interface and customizable features to cater to diverse needs across various industries. Spotrank.ai is designed to streamline data analysis processes and enhance decision-making capabilities through cutting-edge AI technology.
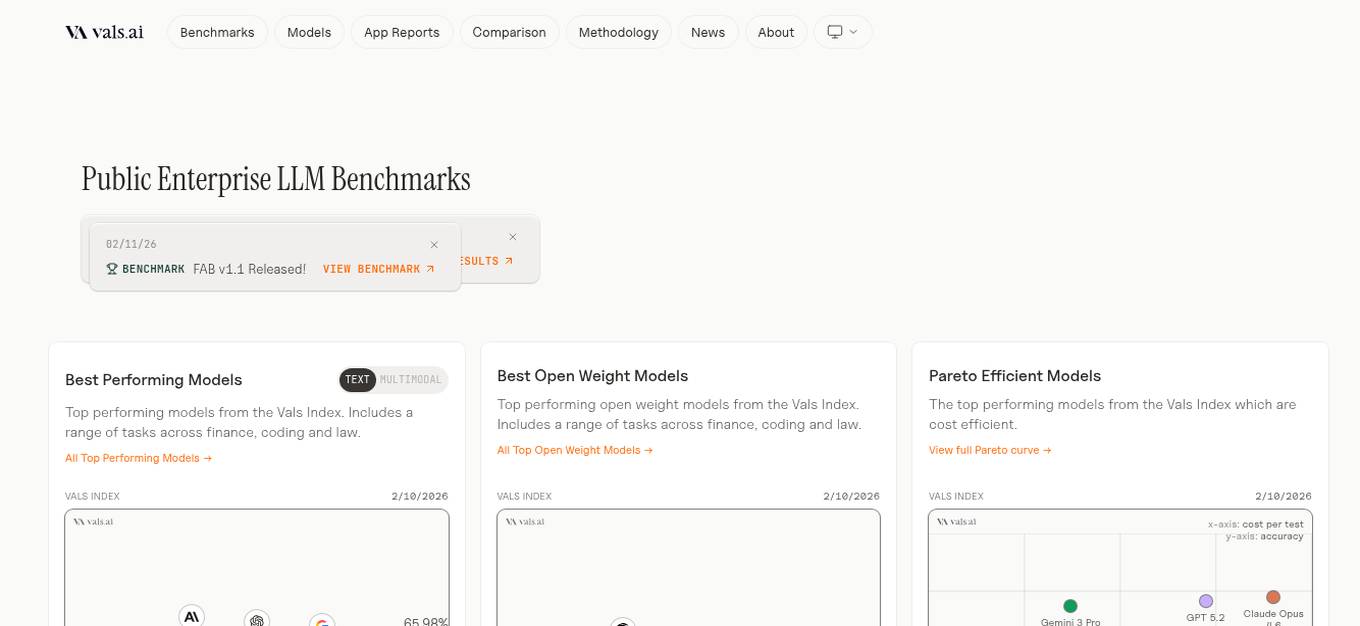
Vals AI
Vals AI is an advanced AI tool that provides benchmark reports and comparisons for various models in the fields of finance, coding, and law. The platform offers insights into the performance of different AI models across different tasks and industries. Vals AI aims to bridge the gap in model benchmarking and provide valuable information for users looking to evaluate and compare AI models for specific tasks.
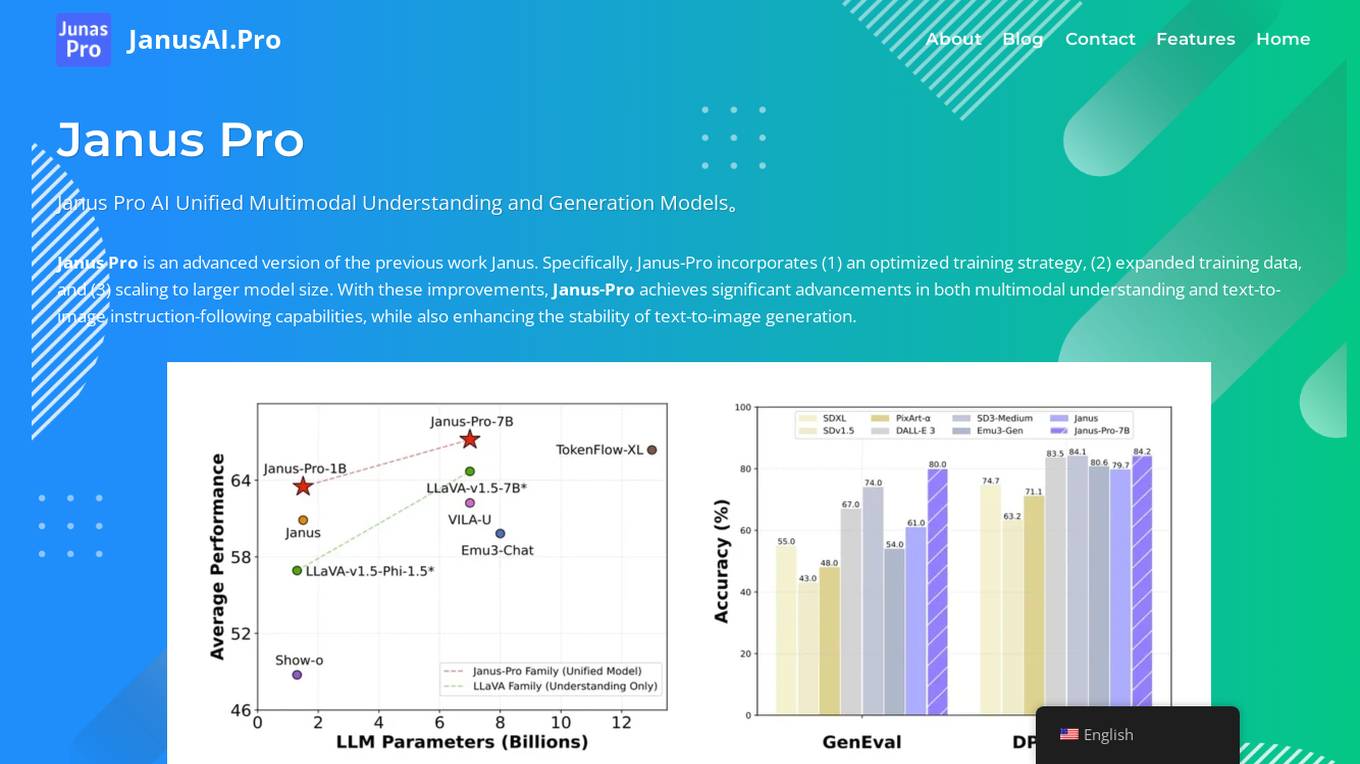
Janus Pro AI
Janus Pro AI is an advanced unified multimodal AI model that combines image understanding and generation capabilities. It incorporates optimized training strategies, expanded training data, and larger model scaling to achieve significant advancements in both multimodal understanding and text-to-image generation tasks. Janus Pro features a decoupled visual encoding system, outperforming leading models like DALL-E 3 and Stable Diffusion in benchmark tests. It offers open-source compatibility, vision processing specifications, cost-effective scalability, and an optimized training framework.

Waikay
Waikay is an AI tool designed to help individuals, businesses, and agencies gain transparency into what AI knows about their brand. It allows users to manage reputation risks, optimize strategic positioning, and benchmark against competitors with actionable insights. By providing a comprehensive analysis of AI mentions, citations, implied facts, and competition, Waikay ensures a 360-degree view of model understanding. Users can easily track their brand's digital footprint, compare with competitors, and monitor their brand and content across leading AI search platforms.
Hailo Community
Hailo Community is an AI tool designed for developers and enthusiasts working with Raspberry Pi and Hailo-8L AI Kit. The platform offers resources, benchmarks, and support for training custom models, optimizing AI tasks, and troubleshooting errors related to Hailo and Raspberry Pi integration.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.

Reflection 70B
Reflection 70B is a next-gen open-source LLM powered by Llama 70B, offering groundbreaking self-correction capabilities that outsmart GPT-4. It provides advanced AI-powered conversations, assists with various tasks, and excels in accuracy and reliability. Users can engage in human-like conversations, receive assistance in research, coding, creative writing, and problem-solving, all while benefiting from its innovative self-correction mechanism. Reflection 70B sets new standards in AI performance and is designed to enhance productivity and decision-making across multiple domains.
Perspect
Perspect is an AI-powered platform designed for high-performance software teams. It offers real-time insights into team contributions and impact, optimizing developer experience, and rewarding high-performers. With 50+ integrations, Perspect enables visualization of impact, benchmarking performance, and uses machine learning models to identify and eliminate blockers. The platform is deeply integrated with web3 wallets and offers built-in reward mechanisms. Managers can align resources around crucial KPIs, identify top talent, and prevent burnout. Perspect aims to enhance team productivity and employee retention through AI and ML technologies.
Lucid Engine
Lucid Engine is an AI tool designed to optimize digital presence for better visibility in AI-generated answers. It helps users track their citations across AI search engines, benchmark competitors, and prioritize actions to improve recommendations. The tool offers features such as Visibility Audit, Competitor Radar, and Action Backlog to enhance AI visibility and competitiveness. Lucid Engine provides real-time monitoring of strategic prompts across multiple AI engines, enabling users to stay ahead of competitors and model shifts.

JaanchAI
JaanchAI is an AI-powered tool that provides valuable insights for e-commerce businesses. It utilizes artificial intelligence algorithms to analyze data and trends in the e-commerce industry, helping businesses make informed decisions to optimize their operations and increase sales. With JaanchAI, users can gain a competitive edge by leveraging advanced analytics and predictive modeling techniques tailored for the e-commerce sector.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Seek AI
Seek AI is a generative AI-powered database query tool that helps businesses break through information barriers. It is the #1 most accurate model on the Yale Spider benchmark and offers a variety of features to help businesses modernize their analytics, including auto-verification with confidence estimation, natural language summary, and embedded AI data analyst.

Contra
Contra is a professional network designed for the jobs and skills of the future. It serves as a commission-free freelance network where users can grow their careers, manage freelance projects, get verified as experts, find jobs from innovative companies, and handle administrative tasks efficiently. Contra also offers tools for companies to organize their workforce, manage team projects, hire contractors, and handle global payments and tax compliance. Additionally, Contra Labs provides resources for creative human data and AI creativity benchmarking.
Aider
Aider is an AI pair programming tool that allows users to collaborate with Language Model Models (LLMs) to edit code in their local git repository. It supports popular languages like Python, JavaScript, TypeScript, PHP, HTML, and CSS. Aider can handle complex requests, automatically commit changes, and work well in larger codebases by using a map of the entire git repository. Users can edit files while chatting with Aider, add images and URLs to the chat, and even code using their voice. Aider has received positive feedback from users for its productivity-enhancing features and performance on software engineering benchmarks.
1 - Open Source AI Tools
abliterator
abliterator.py is a simple Python library/structure designed to ablate features in large language models (LLMs) supported by TransformerLens. It provides capabilities to enter temporary contexts, cache activations with N samples, calculate refusal directions, and includes tokenizer utilities. The library aims to streamline the process of experimenting with ablation direction turns by encapsulating useful logic and minimizing code complexity. While currently basic and lacking comprehensive documentation, the library serves well for personal workflows and aims to expand beyond feature ablation to augmentation and additional features over time with community support.
10 - OpenAI Gpts

HVAC Apex
Benchmark HVAC GPT model with unmatched expertise and forward-thinking solutions, powered by OpenAI
SaaS Navigator
A strategic SaaS analyst for CXOs, with a focus on market trends and benchmarks.


Transfer Pricing Advisor
Guides businesses in managing global tax liabilities efficiently.
Salary Guides
I provide monthly salary data in euros, using a structured format for global job roles.
Performance Testing Advisor
Ensures software performance meets organizational standards and expectations.