
mlc-llm
Universal LLM Deployment Engine with ML Compilation
Stars: 22012
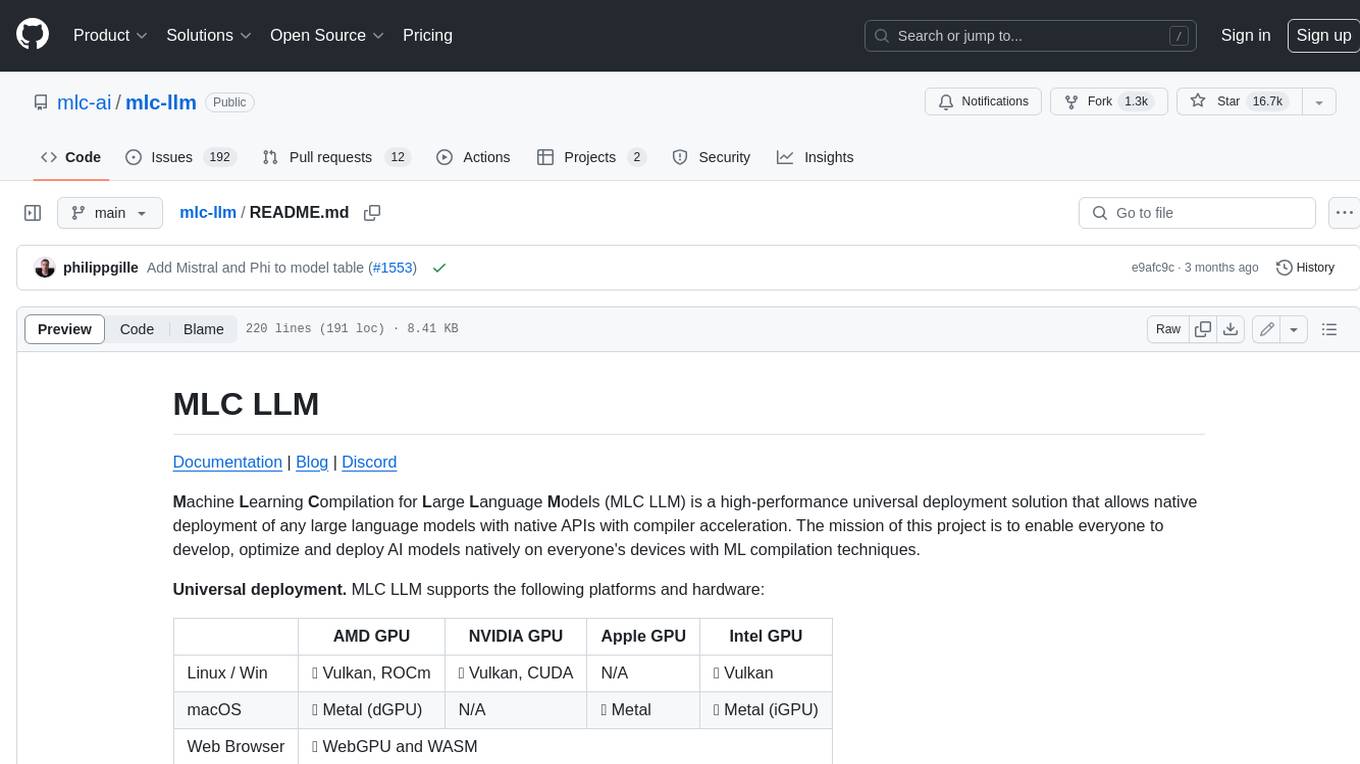
MLC LLM is a high-performance universal deployment solution that allows native deployment of any large language models with native APIs with compiler acceleration. It supports a wide range of model architectures and variants, including Llama, GPT-NeoX, GPT-J, RWKV, MiniGPT, GPTBigCode, ChatGLM, StableLM, Mistral, and Phi. MLC LLM provides multiple sets of APIs across platforms and environments, including Python API, OpenAI-compatible Rest-API, C++ API, JavaScript API and Web LLM, Swift API for iOS App, and Java API and Android App.
README:
MLC LLM is a machine learning compiler and high-performance deployment engine for large language models. The mission of this project is to enable everyone to develop, optimize, and deploy AI models natively on everyone's platforms.
| AMD GPU | NVIDIA GPU | Apple GPU | Intel GPU | |
|---|---|---|---|---|
| Linux / Win | ✅ Vulkan, ROCm | ✅ Vulkan, CUDA | N/A | ✅ Vulkan |
| macOS | ✅ Metal (dGPU) | N/A | ✅ Metal | ✅ Metal (iGPU) |
| Web Browser | ✅ WebGPU and WASM | |||
| iOS / iPadOS | ✅ Metal on Apple A-series GPU | |||
| Android | ✅ OpenCL on Adreno GPU | ✅ OpenCL on Mali GPU | ||
MLC LLM compiles and runs code on MLCEngine -- a unified high-performance LLM inference engine across the above platforms. MLCEngine provides OpenAI-compatible API available through REST server, python, javascript, iOS, Android, all backed by the same engine and compiler that we keep improving with the community.
Please visit our documentation to get started with MLC LLM.
Please consider citing our project if you find it useful:
@software{mlc-llm,
author = {{MLC team}},
title = {{MLC-LLM}},
url = {https://github.com/mlc-ai/mlc-llm},
year = {2023-2025}
}The underlying techniques of MLC LLM include:
References (Click to expand)
@inproceedings{tensorir,
author = {Feng, Siyuan and Hou, Bohan and Jin, Hongyi and Lin, Wuwei and Shao, Junru and Lai, Ruihang and Ye, Zihao and Zheng, Lianmin and Yu, Cody Hao and Yu, Yong and Chen, Tianqi},
title = {TensorIR: An Abstraction for Automatic Tensorized Program Optimization},
year = {2023},
isbn = {9781450399166},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3575693.3576933},
doi = {10.1145/3575693.3576933},
booktitle = {Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2},
pages = {804–817},
numpages = {14},
keywords = {Tensor Computation, Machine Learning Compiler, Deep Neural Network},
location = {Vancouver, BC, Canada},
series = {ASPLOS 2023}
}
@inproceedings{metaschedule,
author = {Shao, Junru and Zhou, Xiyou and Feng, Siyuan and Hou, Bohan and Lai, Ruihang and Jin, Hongyi and Lin, Wuwei and Masuda, Masahiro and Yu, Cody Hao and Chen, Tianqi},
booktitle = {Advances in Neural Information Processing Systems},
editor = {S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh},
pages = {35783--35796},
publisher = {Curran Associates, Inc.},
title = {Tensor Program Optimization with Probabilistic Programs},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/e894eafae43e68b4c8dfdacf742bcbf3-Paper-Conference.pdf},
volume = {35},
year = {2022}
}
@inproceedings{tvm,
author = {Tianqi Chen and Thierry Moreau and Ziheng Jiang and Lianmin Zheng and Eddie Yan and Haichen Shen and Meghan Cowan and Leyuan Wang and Yuwei Hu and Luis Ceze and Carlos Guestrin and Arvind Krishnamurthy},
title = {{TVM}: An Automated {End-to-End} Optimizing Compiler for Deep Learning},
booktitle = {13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18)},
year = {2018},
isbn = {978-1-939133-08-3},
address = {Carlsbad, CA},
pages = {578--594},
url = {https://www.usenix.org/conference/osdi18/presentation/chen},
publisher = {USENIX Association},
month = oct,
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mlc-llm
Similar Open Source Tools
mlc-llm
MLC LLM is a high-performance universal deployment solution that allows native deployment of any large language models with native APIs with compiler acceleration. It supports a wide range of model architectures and variants, including Llama, GPT-NeoX, GPT-J, RWKV, MiniGPT, GPTBigCode, ChatGLM, StableLM, Mistral, and Phi. MLC LLM provides multiple sets of APIs across platforms and environments, including Python API, OpenAI-compatible Rest-API, C++ API, JavaScript API and Web LLM, Swift API for iOS App, and Java API and Android App.
mlp-mixer-pytorch
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.
node-sdk
The ChatBotKit Node SDK is a JavaScript-based platform for building conversational AI bots and agents. It offers easy setup, serverless compatibility, modern framework support, customizability, and multi-platform deployment. With capabilities like multi-modal and multi-language support, conversation management, chat history review, custom datasets, and various integrations, this SDK enables users to create advanced chatbots for websites, mobile apps, and messaging platforms.
tambo
tambo ai is a React library that simplifies the process of building AI assistants and agents in React by handling thread management, state persistence, streaming responses, AI orchestration, and providing a compatible React UI library. It eliminates React boilerplate for AI features, allowing developers to focus on creating exceptional user experiences with clean React hooks that seamlessly integrate with their codebase.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
x
Ant Design X is a tool for crafting AI-driven interfaces effortlessly. It is built on the best practices of enterprise-level AI products, offering flexible and diverse atomic components for various AI dialogue scenarios. The tool provides out-of-the-box model integration with inference services compatible with OpenAI standards. It also enables efficient management of conversation data flows, supports rich template options, complete TypeScript support, and advanced theme customization. Ant Design X is designed to enhance development efficiency and deliver exceptional AI interaction experiences.
MarkLLM
MarkLLM is an open-source toolkit designed for watermarking technologies within large language models (LLMs). It simplifies access, understanding, and assessment of watermarking technologies, supporting various algorithms, visualization tools, and evaluation modules. The toolkit aids researchers and the community in ensuring the authenticity and origin of machine-generated text.
island-ai
island-ai is a TypeScript toolkit tailored for developers engaging with structured outputs from Large Language Models. It offers streamlined processes for handling, parsing, streaming, and leveraging AI-generated data across various applications. The toolkit includes packages like zod-stream for interfacing with LLM streams, stream-hooks for integrating streaming JSON data into React applications, and schema-stream for JSON streaming parsing based on Zod schemas. Additionally, related packages like @instructor-ai/instructor-js focus on data validation and retry mechanisms, enhancing the reliability of data processing workflows.
jsgrad
jsgrad is a modern ML library for JavaScript and TypeScript that aims to provide a fast and efficient way to run and train machine learning models. It is a rewrite of tinygrad in TypeScript, offering a clean and modern API with zero dependencies. The library supports multiple runtime backends such as WebGPU, WASM, and CLANG, making it versatile for various applications in browser and server environments. With a focus on simplicity and performance, jsgrad is designed to be easy to use for both model inference and training tasks.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.
daytona
Daytona is a secure and elastic infrastructure tool designed for running AI-generated code. It offers lightning-fast infrastructure with sub-90ms sandbox creation, separated and isolated runtime for executing AI code with zero risk, massive parallelization for concurrent AI workflows, programmatic control through various APIs, unlimited sandbox persistence, and OCI/Docker compatibility. Users can create sandboxes using Python or TypeScript SDKs, run code securely inside the sandbox, and clean up the sandbox after execution. Daytona is open source under the GNU Affero General Public License and welcomes contributions from developers.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.

CodeTF
CodeTF is a Python transformer-based library for code large language models (Code LLMs) and code intelligence. It provides an interface for training and inferencing on tasks like code summarization, translation, and generation. The library offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, CodeTF enables parsing of function names, comments, and variable names. It supports fast model serving, fine-tuning of LLMs, various code intelligence tasks, preprocessed datasets, model evaluation, pretrained and fine-tuned models, and utilities to manipulate source code. CodeTF aims to facilitate the integration of state-of-the-art Code LLMs into real-world applications, ensuring a user-friendly environment for code intelligence tasks.
mcp-go
MCP Go is a Go implementation of the Model Context Protocol (MCP), facilitating seamless integration between LLM applications and external data sources and tools. It handles complex protocol details and server management, allowing developers to focus on building tools. The tool is designed to be fast, simple, and complete, aiming to provide a high-level and easy-to-use interface for developing MCP servers. MCP Go is currently under active development, with core features working and advanced capabilities in progress.
For similar tasks
mlc-llm
MLC LLM is a high-performance universal deployment solution that allows native deployment of any large language models with native APIs with compiler acceleration. It supports a wide range of model architectures and variants, including Llama, GPT-NeoX, GPT-J, RWKV, MiniGPT, GPTBigCode, ChatGLM, StableLM, Mistral, and Phi. MLC LLM provides multiple sets of APIs across platforms and environments, including Python API, OpenAI-compatible Rest-API, C++ API, JavaScript API and Web LLM, Swift API for iOS App, and Java API and Android App.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
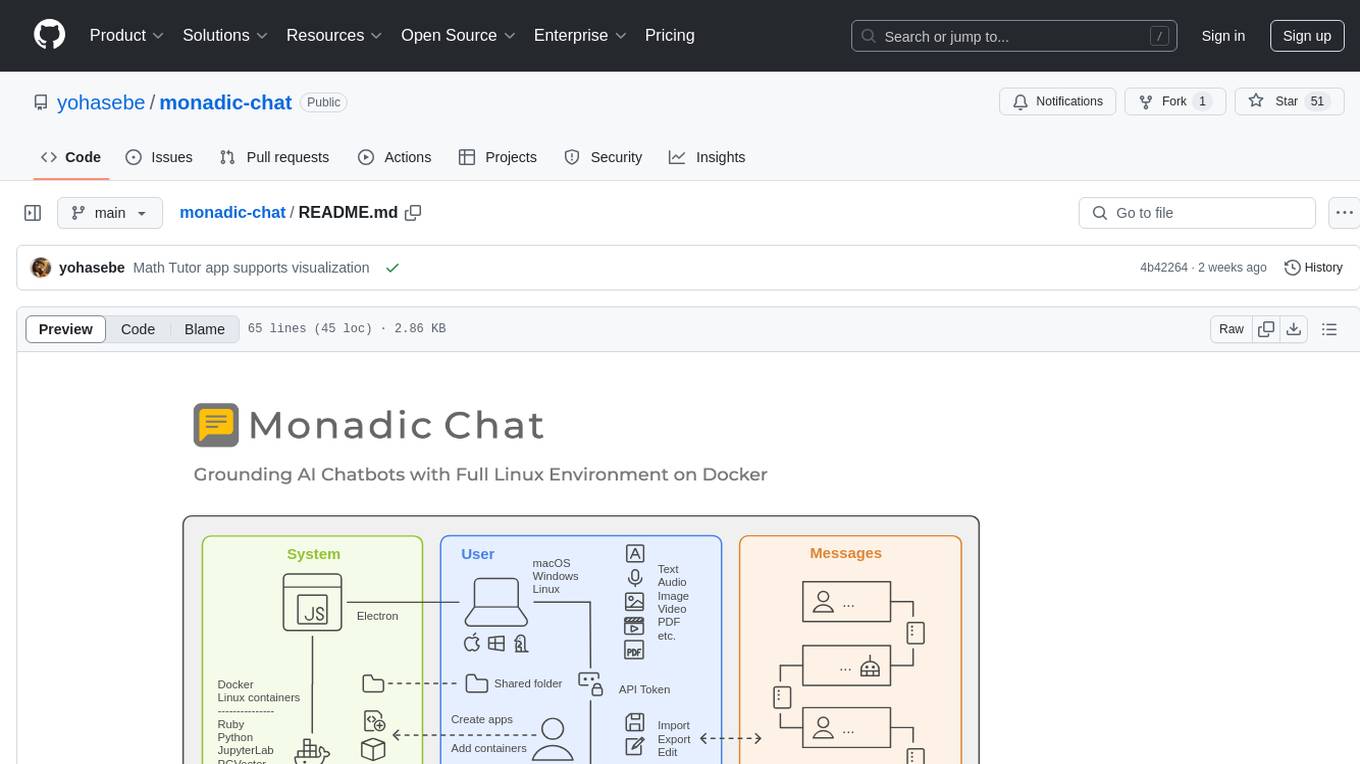
monadic-chat
Monadic Chat is a locally hosted web application designed to create and utilize intelligent chatbots. It provides a Linux environment on Docker to GPT and other LLMs, enabling the execution of advanced tasks that require external tools. The tool supports voice interaction, image and video recognition and generation, and AI-to-AI chat, making it useful for using AI and developing various applications. It is available for Mac, Windows, and Linux (Debian/Ubuntu) with easy-to-use installers.
ollama-playground
Ollama Projects is a repository containing code for various projects built using Ollama's open-source models. The projects include Chat with PDF, Chat with PDF Using Hybrid RAG, AI Scraper, Image Search, OCR, Object Detection, Emotion Detection, and AI Researcher. These projects showcase the capabilities of Ollama's models and provide insights into AI applications in different domains.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord
Tutorial
The Bookworm·Puyu large model training camp aims to promote the implementation of large models in more industries and provide developers with a more efficient platform for learning the development and application of large models. Within two weeks, you will learn the entire process of fine-tuning, deploying, and evaluating large models.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.
llm_interview_note
This repository provides a comprehensive overview of large language models (LLMs), covering various aspects such as their history, types, underlying architecture, training techniques, and applications. It includes detailed explanations of key concepts like Transformer models, distributed training, fine-tuning, and reinforcement learning. The repository also discusses the evaluation and limitations of LLMs, including the phenomenon of hallucinations. Additionally, it provides a list of related courses and references for further exploration.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.