
Tutorial
LLM&VLM Tutorial
Stars: 1629
The Bookworm·Puyu large model training camp aims to promote the implementation of large models in more industries and provide developers with a more efficient platform for learning the development and application of large models. Within two weeks, you will learn the entire process of fine-tuning, deploying, and evaluating large models.
README:
闯关手册:https://aicarrier.feishu.cn/wiki/QtJnweAW1iFl8LkoMKGcsUS9nld
| 关卡名称 | 资料 | 闯关激励 | |
|---|---|---|---|
| 第 1 关 | Linux 前置基础 | 任务、文档、视频 | 50元算力点 |
| 第 2 关 | Python 前置基础 | 任务、文档、视频 | 50元算力点 |
| 第 3 关 | Git 前置基础 | 任务、文档、视频 | 50元算力点 |
| 第 4 关 | 玩转「HF/魔搭/魔乐」等平台 | 任务、文档、视频 | 50元算力点 |
| 关卡名称 | 资料 | 闯关激励 | |
|---|---|---|---|
| 第 1 关 | 书生大模型全链路开源体系 | 任务、视频 | 100元算力点 |
| 第 2 关 | 玩转书生「多模态对话」和「AI搜索」产品 | 任务、文档、视频 | 100元算力点 |
| 第 3 关 | 浦语提示词工程实践 | 任务、文档、视频 | 100元算力点 |
| 第 4 关 | InternLM + LlamaIndex RAG 实践 | 任务、文档、视频 | 100元算力点 |
| 第 5 关 | XTuner 微调个人小助手认知 | 任务、文档、视频 | 100元算力点 |
| 第 6 关 | OpenCompass 评测书生大模型实践 | 任务、文档、视频 | 100元算力点 |
| 关卡名称 | 资料 | 闯关激励 | |
|---|---|---|---|
| 第 1 关 | 探索书生大模型能力边界 | 任务 | 100元算力点 |
| 第 2 关 | Lagent:从零搭建你的 Multi-Agent | 任务、文档、视频 | 100元算力点 |
| 第 3 关 | LMDeploy 量化部署进阶实践 | 任务、文档、视频 | 100元算力点 |
| 第 4 关 | InternVL 多模态模型部署微调实践 | 任务、文档、视频 | 100元算力点 |
| 第 5 关 | 茴香豆:企业级知识库问答工具 | 任务、文档、视频 | 100元算力点 |
| 第 6 关 | MindSearch深度解析及实践 | 任务、文档 | 100元算力点 |
| 关卡名称 | 资料 | |
|---|---|---|
| 第 1 关 | 书生大模型遇见 coze/dify/flowise | [文档]、[视频] |
完成进阶岛闯关将获得精美的结营证书~
在大模型技术的浪潮中,面对混杂的众多信息,如何获取有效、可信的学习资源成为了一项挑战。
为此,我们推出“书生共学计划”,鼓励大家将实战营活动分享给你身边有需要的小伙伴,让每一位热爱技术的朋友都能在这个复杂的信息环境中找到自己的航向,帮助他们在大模型的学习之路上少走弯路。
参与方法
- 启航准备:通过填写问卷报名加入实战营,开启你的学习之旅。
- 专属海报:访问书生共学计划活动页面(https://colearn.intern-ai.org.cn/co ),系统将自动生成你的专属海报
- 招募同行者:将海报分享给你身边的小伙伴,邀请他们报名实战营,共享知识的力量。
独家奖励等你拿
- 每邀请 1 位同学填写报名问卷即可获得 50 算力点。
- 成功邀请 3 人,解锁 InternStudio 平台 24GB A100 及 80GB 存储使用权限。
- 成功邀请 6 人,解锁 InternStudio 平台 40GB A100 及 120GB 存储使用权限。
- 成功邀请 16 人,解锁 InternStudio 平台 80GB A100 及 200GB 存储使用权限。
展现你的影响力,成为知识的使者 这不仅是一个促进个人学习和成长的机遇,更是一个帮助他人、为自己赢得认可和资源的舞台。通过你的分享,我们可以一起帮助更多的人接触和了解前沿技术,期待你的加入。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Tutorial
Similar Open Source Tools
Tutorial
The Bookworm·Puyu large model training camp aims to promote the implementation of large models in more industries and provide developers with a more efficient platform for learning the development and application of large models. Within two weeks, you will learn the entire process of fine-tuning, deploying, and evaluating large models.
chat-master
ChatMASTER is a self-built backend conversation service based on AI large model APIs, supporting synchronous and streaming responses with perfect printer effects. It supports switching between mainstream models such as DeepSeek, Kimi, Doubao, OpenAI, Claude3, Yiyan, Tongyi, Xinghuo, ChatGLM, Shusheng, and more. It also supports loading local models and knowledge bases using Ollama and Langchain, as well as online API interfaces like Coze and Gitee AI. The project includes Java server-side, web-side, mobile-side, and management background configuration. It provides various assistant types for prompt output and allows creating custom assistant templates in the management background. The project uses technologies like Spring Boot, Spring Security + JWT, Mybatis-Plus, Lombok, Mysql & Redis, with easy-to-understand code and comprehensive permission control using JWT authentication system for multi-terminal support.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
BreezeApp
BreezeApp is a community-driven platform for running AI capabilities locally on Android devices. It offers a privacy-focused solution where all AI features work offline, showcasing text-based chat interface, voice input/output support, and image understanding capabilities. The app supports multiple backends for different components and aims to make powerful AI models accessible to users. Users can contribute to the project by reporting issues, suggesting features, submitting pull requests, and sharing feedback. The architecture follows a service-based approach with service implementations for each AI capability. BreezeApp is a research project that may require specific hardware support or proprietary components, providing open-source alternatives where possible.
job-hunting
Job Hunting is a browser extension designed to enhance the job searching experience on popular recruitment platforms in China. It aims to improve job listing visibility, provide personalized job search capabilities, analyze job data, facilitate job discussions, and offer company insights. The extension offers features such as job card display, company reputation checks, quick company information lookup, job and company data storage, job and company tagging, data analysis, data sharing, personal job preferences, automation tasks, discussion forums, data backup and recovery, and data sharing plans. It supports platforms like BOSS 直聘, 前程无忧, 智联招聘, 拉钩网, and 猎聘网, and provides visualizations for job posting trends and company data.
WeClone
WeClone is a tool that fine-tunes large language models using WeChat chat records. It utilizes approximately 20,000 integrated and effective data points, resulting in somewhat satisfactory outcomes that are occasionally humorous. The tool's effectiveness largely depends on the quantity and quality of the chat data provided. It requires a minimum of 16GB of GPU memory for training using the default chatglm3-6b model with LoRA method. Users can also opt for other models and methods supported by LLAMA Factory, which consume less memory. The tool has specific hardware and software requirements, including Python, Torch, Transformers, Datasets, Accelerate, and other optional packages like CUDA and Deepspeed. The tool facilitates environment setup, data preparation, data preprocessing, model downloading, parameter configuration, model fine-tuning, and inference through a browser demo or API service. Additionally, it offers the ability to deploy a WeChat chatbot, although users should be cautious due to the risk of account suspension by WeChat.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.
2024-AICS-EXP
This repository contains the complete archive of the 2024 version of the 'Intelligent Computing System' experiment at the University of Chinese Academy of Sciences. The experiment content for 2024 has undergone extensive adjustments to the knowledge system and experimental topics, including the transition from TensorFlow to PyTorch, significant modifications to previous code, and the addition of experiments with large models. The project is continuously updated in line with the course progress, currently up to the seventh experiment. Updates include the addition of experiments like YOLOv5 in Experiment 5-3, updates to theoretical teaching materials, and fixes for bugs in Experiment 6 code. The repository also includes experiment manuals, questions, and answers for various experiments, with some data sets hosted on Baidu Cloud due to size limitations on GitHub.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.
dive-into-llms
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.
PocketFlow
Pocket Flow is a 100-line minimalist LLM framework designed for (Multi-)Agents, Workflow, RAG, etc. It provides a core abstraction for LLM projects by focusing on computation and communication through a graph structure and shared store. The framework aims to support the development of LLM Agents, such as Cursor AI, by offering a minimal and low-level approach that is well-suited for understanding and usage. Users can install Pocket Flow via pip or by copying the source code, and detailed documentation is available on the project website.
FlipAttack
FlipAttack is a jailbreak attack tool designed to exploit black-box Language Model Models (LLMs) by manipulating text inputs. It leverages insights into LLMs' autoregressive nature to construct noise on the left side of the input text, deceiving the model and enabling harmful behaviors. The tool offers four flipping modes to guide LLMs in denoising and executing malicious prompts effectively. FlipAttack is characterized by its universality, stealthiness, and simplicity, allowing users to compromise black-box LLMs with just one query. Experimental results demonstrate its high success rates against various LLMs, including GPT-4o and guardrail models.
For similar tasks
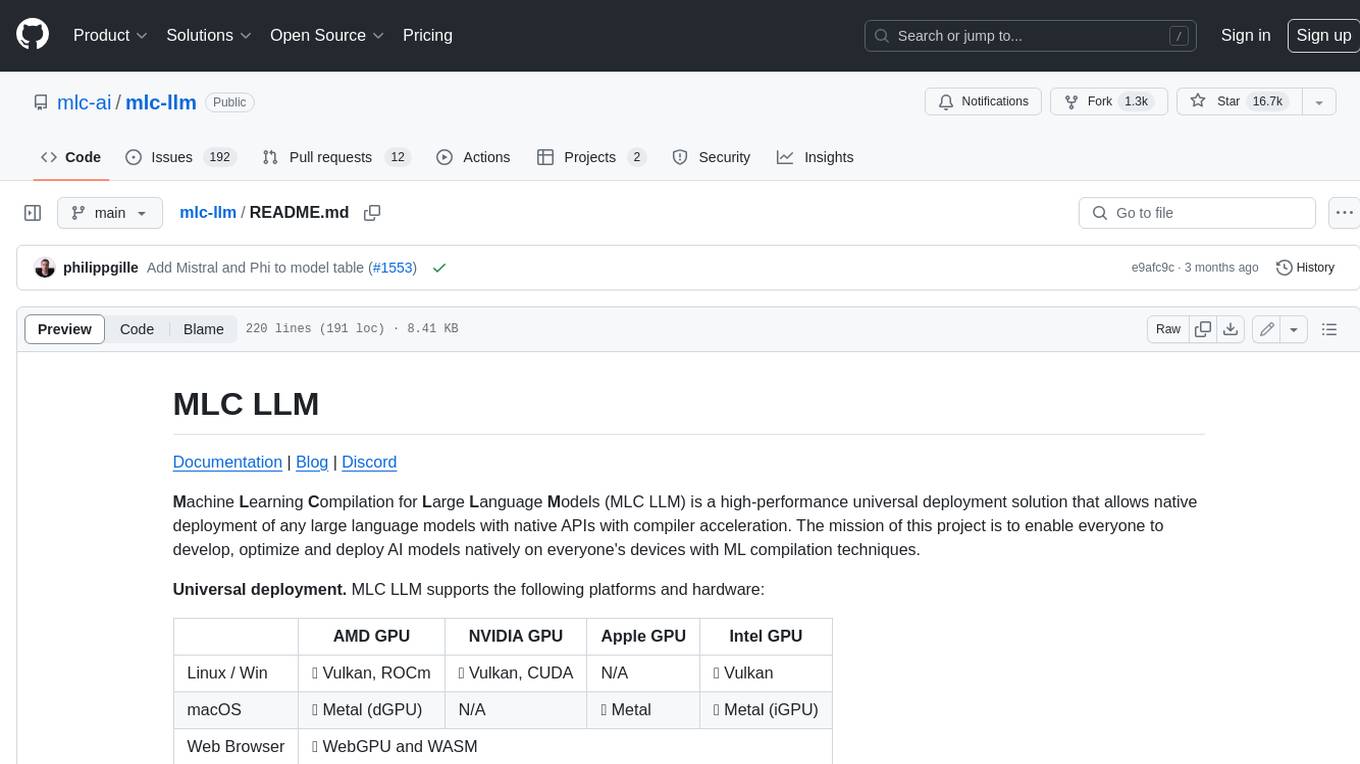
mlc-llm
MLC LLM is a high-performance universal deployment solution that allows native deployment of any large language models with native APIs with compiler acceleration. It supports a wide range of model architectures and variants, including Llama, GPT-NeoX, GPT-J, RWKV, MiniGPT, GPTBigCode, ChatGLM, StableLM, Mistral, and Phi. MLC LLM provides multiple sets of APIs across platforms and environments, including Python API, OpenAI-compatible Rest-API, C++ API, JavaScript API and Web LLM, Swift API for iOS App, and Java API and Android App.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord
Tutorial
The Bookworm·Puyu large model training camp aims to promote the implementation of large models in more industries and provide developers with a more efficient platform for learning the development and application of large models. Within two weeks, you will learn the entire process of fine-tuning, deploying, and evaluating large models.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.
llm_interview_note
This repository provides a comprehensive overview of large language models (LLMs), covering various aspects such as their history, types, underlying architecture, training techniques, and applications. It includes detailed explanations of key concepts like Transformer models, distributed training, fine-tuning, and reinforcement learning. The repository also discusses the evaluation and limitations of LLMs, including the phenomenon of hallucinations. Additionally, it provides a list of related courses and references for further exploration.
SeaLLMs
SeaLLMs are a family of language models optimized for Southeast Asian (SEA) languages. They were pre-trained from Llama-2, on a tailored publicly-available dataset, which comprises texts in Vietnamese 🇻🇳, Indonesian 🇮🇩, Thai 🇹🇭, Malay 🇲🇾, Khmer🇰🇭, Lao🇱🇦, Tagalog🇵🇭 and Burmese🇲🇲. The SeaLLM-chat underwent supervised finetuning (SFT) and specialized self-preferencing DPO using a mix of public instruction data and a small number of queries used by SEA language native speakers in natural settings, which **adapt to the local cultural norms, customs, styles and laws in these areas**. SeaLLM-13b models exhibit superior performance across a wide spectrum of linguistic tasks and assistant-style instruction-following capabilities relative to comparable open-source models. Moreover, they outperform **ChatGPT-3.5** in non-Latin languages, such as Thai, Khmer, Lao, and Burmese.
PhoGPT
PhoGPT is an open-source 4B-parameter generative model series for Vietnamese, including the base pre-trained monolingual model PhoGPT-4B and its chat variant, PhoGPT-4B-Chat. PhoGPT-4B is pre-trained from scratch on a Vietnamese corpus of 102B tokens, with an 8192 context length and a vocabulary of 20K token types. PhoGPT-4B-Chat is fine-tuned on instructional prompts and conversations, demonstrating superior performance. Users can run the model with inference engines like vLLM and Text Generation Inference, and fine-tune it using llm-foundry. However, PhoGPT has limitations in reasoning, coding, and mathematics tasks, and may generate harmful or biased responses.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.