
inference-speed-tests
Local LLM inference speed tests on various devices
Stars: 54
This repository contains inference speed tests on Local Large Language Models on various devices. It provides results for different models tested on Macbook Pro and Mac Studio. Users can contribute their own results by running models with the provided prompt and adding the tokens-per-second output. Note that the results are not verified.
README:
Inference speed tests on Local Large Language Models on various devices. Feel free to contribute your results.
Note: None of the following results are verified
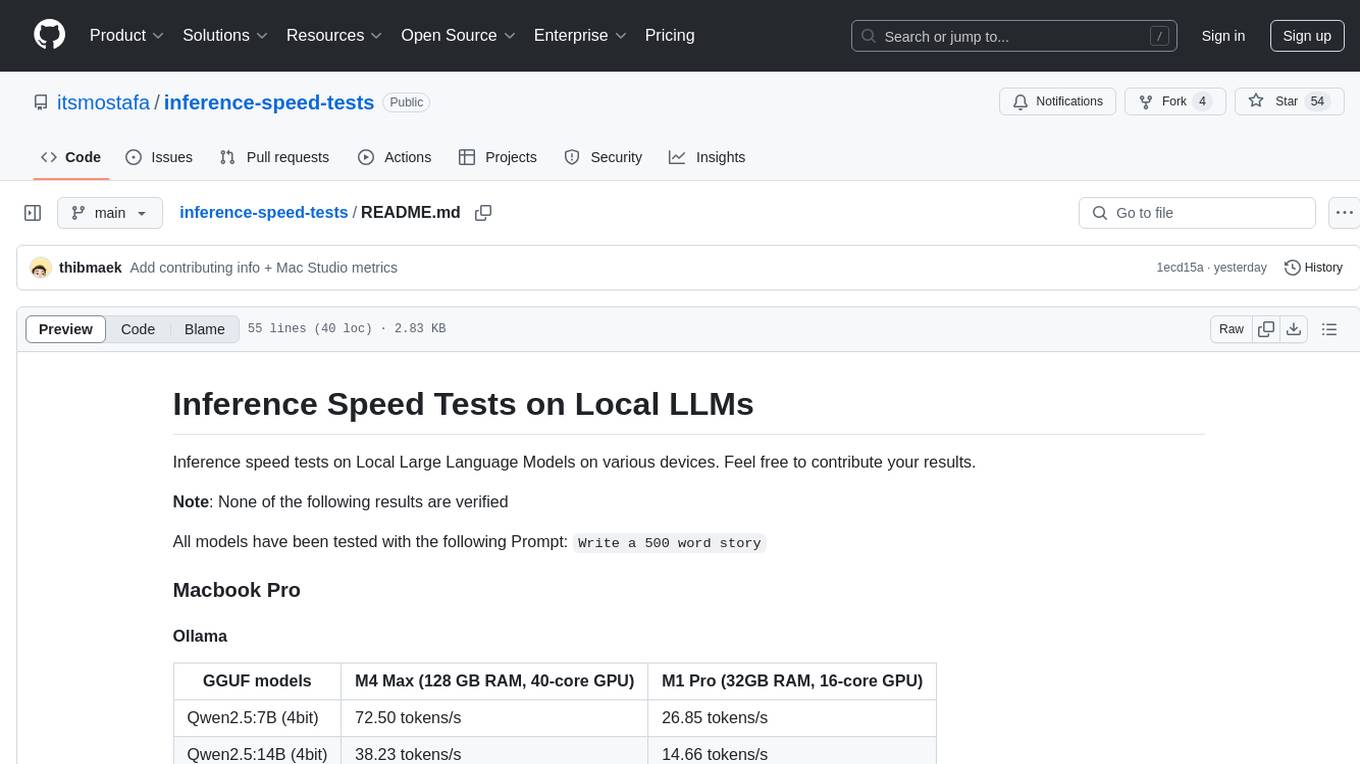
All models have been tested with the following Prompt: Write a 500 word story
| GGUF models | M4 Max (128 GB RAM, 40-core GPU) | M1 Pro (32GB RAM, 16-core GPU) |
|---|---|---|
| Qwen2.5:7B (4bit) | 72.50 tokens/s | 26.85 tokens/s |
| Qwen2.5:14B (4bit) | 38.23 tokens/s | 14.66 tokens/s |
| Qwen2.5:32B (4bit) | 19.35 tokens/s | 6.95 tokens/s |
| Qwen2.5:72B (4bit) | 8.76 tokens/s | Didn't Test |
| MLX models | M4 Max (128 GB RAM, 40-core GPU) | M1 Pro (32GB RAM, 16-core GPU) |
|---|---|---|
| Qwen2.5-7B-Instruct (4bit) | 101.87 tokens/s | 38.99 tokens/s |
| Qwen2.5-14B-Instruct (4bit) | 52.22 tokens/s | 18.88 tokens/s |
| Qwen2.5-32B-Instruct (4bit) | 24.46 tokens/s | 9.10 tokens/s |
| Qwen2.5-32B-Instruct (8bit) | 13.75 tokens/s | Won’t Complete (Crashed) |
| Qwen2.5-72B-Instruct (4bit) | 10.86 tokens/s | Didn't Test |
| GGUF models | M4 Max (128 GB RAM, 40-core GPU) | M1 Pro (32GB RAM, 16-core GPU) |
|---|---|---|
| Qwen2.5-7B-Instruct (4bit) | 71.73 tokens/s | 26.12 tokens/s |
| Qwen2.5-14B-Instruct (4bit) | 39.04 tokens/s | 14.67 tokens/s |
| Qwen2.5-32B-Instruct (4bit) | 19.56 tokens/s | 4.53 tokens/s |
| Qwen2.5-72B-Instruct (4bit) | 8.31 tokens/s | Didn't Test |
| GGUF models | M1 Max (32GB RAM, 23-core GPU) |
|---|---|
| mistral-small:23b (4bit) | 15.11 tokens/s |
| llama3.1:8b (4bit) | 38.73 tokens/s |
| llama3.2-vision:9b (4bit) | 39.05 tokens/s |
| deepseek-r1:14b (4bit) | 21.16 tokens/s |
- Run your model with the verbose flag (e.g
ollama run mistral-small --verbose) - Enter the prompt
Write a 500 word story - In the column of your device add the TPS (tokens-per-second) output of
eval ratein Ollama - If your device is not in the list add it
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for inference-speed-tests
Similar Open Source Tools
inference-speed-tests
This repository contains inference speed tests on Local Large Language Models on various devices. It provides results for different models tested on Macbook Pro and Mac Studio. Users can contribute their own results by running models with the provided prompt and adding the tokens-per-second output. Note that the results are not verified.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

awesome-llm
Awesome LLM is a curated list of resources related to Large Language Models (LLMs), including models, projects, datasets, benchmarks, materials, papers, posts, GitHub repositories, HuggingFace repositories, and reading materials. It provides detailed information on various LLMs, their parameter sizes, announcement dates, and contributors. The repository covers a wide range of LLM-related topics and serves as a valuable resource for researchers, developers, and enthusiasts interested in the field of natural language processing and artificial intelligence.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

LLMs
LLMs is a Chinese large language model technology stack for practical use. It includes high-availability pre-training, SFT, and DPO preference alignment code framework. The repository covers pre-training data cleaning, high-concurrency framework, SFT dataset cleaning, data quality improvement, and security alignment work for Chinese large language models. It also provides open-source SFT dataset construction, pre-training from scratch, and various tools and frameworks for data cleaning, quality optimization, and task alignment.
rookie_text2data
A natural language to SQL plugin powered by large language models, supporting seamless database connection for zero-code SQL queries. The plugin is designed to facilitate communication and learning among users. It supports MySQL database and various large models for natural language processing. Users can quickly install the plugin, authorize a database address, import the plugin, select a model, and perform natural language SQL queries.
cs-books
CS Books is a curated collection of computer science resources organized by topics and real-world applications. It provides a dual academic/practical focus for students, researchers, and industry professionals. The repository contains a variety of books covering topics such as computer architecture, computer programming, artificial intelligence, data science, cloud computing, edge computing, embedded systems, signal processing, automotive, cybersecurity, game development, healthcare, and robotics. Each section includes a curated list of books with reference links to their Google Drive folders, allowing users to access valuable resources in these fields.
chat-master
ChatMASTER is a self-built backend conversation service based on AI large model APIs, supporting synchronous and streaming responses with perfect printer effects. It supports switching between mainstream models such as DeepSeek, Kimi, Doubao, OpenAI, Claude3, Yiyan, Tongyi, Xinghuo, ChatGLM, Shusheng, and more. It also supports loading local models and knowledge bases using Ollama and Langchain, as well as online API interfaces like Coze and Gitee AI. The project includes Java server-side, web-side, mobile-side, and management background configuration. It provides various assistant types for prompt output and allows creating custom assistant templates in the management background. The project uses technologies like Spring Boot, Spring Security + JWT, Mybatis-Plus, Lombok, Mysql & Redis, with easy-to-understand code and comprehensive permission control using JWT authentication system for multi-terminal support.

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.
web-builder
Web Builder is a low-code front-end framework based on Material for Angular, offering a rich component library for excellent digital innovation experience. It allows rapid construction of modern responsive UI, multi-theme, multi-language web pages through drag-and-drop visual configuration. The framework includes a beautiful admin theme, complete front-end solutions, and AI integration in the Pro version for optimizing copy, creating components, and generating pages with a single sentence.

phoenix
Phoenix is a tool that provides MLOps and LLMOps insights at lightning speed with zero-config observability. It offers a notebook-first experience for monitoring models and LLM Applications by providing LLM Traces, LLM Evals, Embedding Analysis, RAG Analysis, and Structured Data Analysis. Users can trace through the execution of LLM Applications, evaluate generative models, explore embedding point-clouds, visualize generative application's search and retrieval process, and statistically analyze structured data. Phoenix is designed to help users troubleshoot problems related to retrieval, tool execution, relevance, toxicity, drift, and performance degradation.
Awesome-LLM-Tabular
This repository is a curated list of research papers that explore the integration of Large Language Model (LLM) technology with tabular data. It aims to provide a comprehensive resource for researchers and practitioners interested in this emerging field. The repository includes papers on a wide range of topics, including table-to-text generation, table question answering, and tabular data classification. It also includes a section on related datasets and resources.
For similar tasks
inference-speed-tests
This repository contains inference speed tests on Local Large Language Models on various devices. It provides results for different models tested on Macbook Pro and Mac Studio. Users can contribute their own results by running models with the provided prompt and adding the tokens-per-second output. Note that the results are not verified.
ai-models
The `ai-models` command is a tool used to run AI-based weather forecasting models. It provides functionalities to install, run, and manage different AI models for weather forecasting. Users can easily install and run various models, customize model settings, download assets, and manage input data from different sources such as ECMWF, CDS, and GRIB files. The tool is designed to optimize performance by running on GPUs and provides options for better organization of assets and output files. It offers a range of command line options for users to interact with the models and customize their forecasting tasks.
ramalama
The Ramalama project simplifies working with AI by utilizing OCI containers. It automatically detects GPU support, pulls necessary software in a container, and runs AI models. Users can list, pull, run, and serve models easily. The tool aims to support various GPUs and platforms in the future, making AI setup hassle-free.
local-assistant-examples
The Local Assistant Examples repository is a collection of educational examples showcasing the use of large language models (LLMs). It was initially created for a blog post on building a RAG model locally, and has since expanded to include more examples and educational material. Each example is housed in its own folder with a dedicated README providing instructions on how to run it. The repository is designed to be simple and educational, not for production use.
nosia
Nosia is a platform that allows users to run an AI model on their own data. It is designed to be easy to install and use. Users can follow the provided guides for quickstart, API usage, upgrading, starting, stopping, and troubleshooting. The platform supports custom installations with options for remote Ollama instances, custom completion models, and custom embeddings models. Advanced installation instructions are also available for macOS with a Debian or Ubuntu VM setup. Users can access the platform at 'https://nosia.localhost' and troubleshoot any issues by checking logs and job statuses.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.