
BreezeApp
BreezeAPP 是一款為 Android 和 iOS 平台開發的純手機 AI 應用程式。從 App Store下載,即可在不連網的狀態下享受多項 AI 功能。源碼由聯發創新基地(MediaTek Research)提供。我們旨在推廣兩個概念: 人人都可以在自己的手機上自由選擇並運行不同的LLM - one is free to choose one's own LLM to run on a phone,以及任何app開發者都可以輕鬆寫作創意的純手機AI應用 - any dev can create purely phone-based AI apps easily。
Stars: 84
BreezeApp is a community-driven platform for running AI capabilities locally on Android devices. It offers a privacy-focused solution where all AI features work offline, showcasing text-based chat interface, voice input/output support, and image understanding capabilities. The app supports multiple backends for different components and aims to make powerful AI models accessible to users. Users can contribute to the project by reporting issues, suggesting features, submitting pull requests, and sharing feedback. The architecture follows a service-based approach with service implementations for each AI capability. BreezeApp is a research project that may require specific hardware support or proprietary components, providing open-source alternatives where possible.
README:

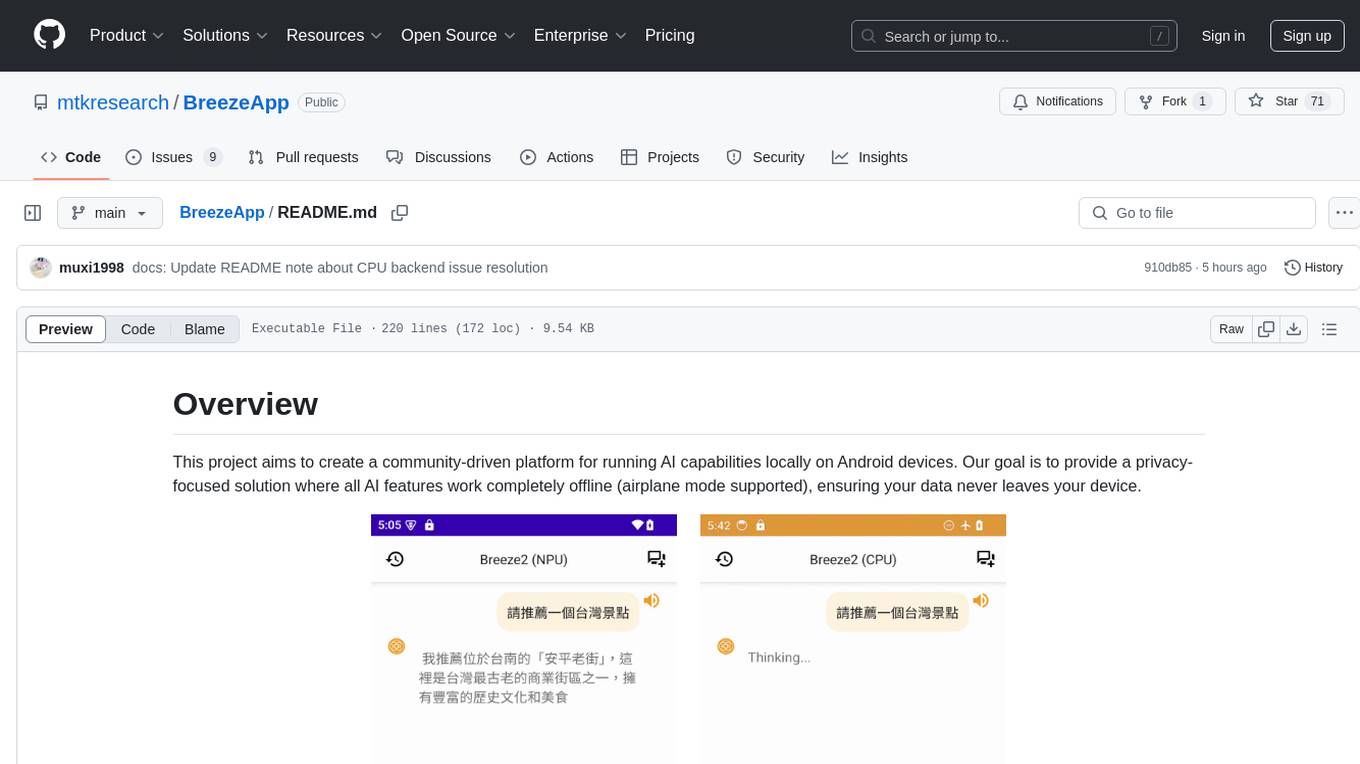
聊天機器人


左:NPU 後端 右:CPU 後端
語音轉文字
(準備中)
文字轉語音

|
範例一
範例二 |
對圖詢問
(準備中)
BreezeAPP 是一款專為 Android 和 iOS 平台開發的純手機 AI 應用程式。用戶只需從 App Store 直接下載,即可在不須連網的離線狀態下享受多項功能,包含了語音轉文字、文字轉語音、文字聊天機器人,以及對圖像進行問答。目前,BreezeApp 支援聯發科技創新基地開發的 Breeze 2 系列模型,未來還會持續更新支援更新、更好的模型。
我們是聯發創新基地 (MediaTek Research)。聯發創新基地是AI Alliance 的成員。
我們開發這個應用的主要目的,是為了改變大眾對運行大型語言模型(LLM) 的普遍認知。目前,許多人認為LLM的功能只能在昂貴的設備上使用,而且受限於設備提供商的選擇。我們希望提升大眾意識並推廣這樣一個概念:任何人都可以在自己的手機上自由選擇並運行不同的LLM。
我們開發這個應用的另一個主要目的,是通過開源我們的 Kotlin 源代碼,來消除 app 開發者在創建手機 AI 應用時可能遇到的障礙,藉此激發app開發者做出更多有創意的手機應用。我們期待未來能與 app 開發者展開更多合作。
如果您對 BreezeApp 有興趣,歡迎通過以下郵箱與我們聯繫:[email protected]
- 下載最新版 APK
- 應用程式包含應用內模型下載功能,首次啟動時會自動提示您下載所需模型。
-
💬 基於文字的聊天介面
-
🗣️ 語音輸入/輸出支援
-
📸 圖像理解能力
-
🔄 多後端支援:
模型類型 本地 CPU 聯發科 NPU 預設 LLM ✅ ✅ - VLM 🚧 ❌ - ASR 🚧 ❌ - TTS ✅ ❌ -
| 模型類型 | 可用模型 |
|---|---|
| LLM | Breeze 2 |
| VLM | Breeze 2 |
| ASR | Breeze 2 |
| TTS | Breeze 2 |
目前僅在 Pixel 7a (8GB) 和 Samsung Flip 4 上測試通過,我們希望能收到更多用戶在不同設備上的實際使用反饋。
想要建構和貢獻程式碼?查看我們的安裝指南獲取詳細說明。
我們正在尋找貢獻者協助以下任務:
-
推廣
- 擴大BreezeApp的能見度
- 多語言支持
-
效能優化
- 分析應用程式並加強記憶體管理
- 優化各種裝置上的推理速度
- 減少應用程式大小和資源消耗
-
程式碼品質
- 重構程式碼以提高可維護性
- 新增單元和整合測試
- 實現更好的錯誤處理和日誌記錄
-
裝置相容性
- 在更多 Android 裝置上測試
- 識別並修復裝置特定問題
- 支援不同的螢幕尺寸和長寬比
-
使用者體驗
- 在模型推理期間提高 UI 回應性
- 增強無障礙功能
- 創建更直觀的入門流程
-
文件
- 改進程式碼文件
- 創建開發者教程
- 在用戶指南中新增截圖和演示
如果您有興趣處理這些任務中的任何一項,請查看我們的問題追蹤器或開啟一個新問題,在提交 PR 之前討論您的方法。
歡迎貢獻!請查看我們的貢獻指南開始。
本專案的授權條款尚未確定 - 詳情請查看 LICENSE 檔案。
- Executorch 提供 LLM/VLM 框架
- k2-fsa/sherpa-onnx 提供 ASR/TTS 功能
- MediaTek Research 提供核心 AI 引擎
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for BreezeApp
Similar Open Source Tools
BreezeApp
BreezeApp is a community-driven platform for running AI capabilities locally on Android devices. It offers a privacy-focused solution where all AI features work offline, showcasing text-based chat interface, voice input/output support, and image understanding capabilities. The app supports multiple backends for different components and aims to make powerful AI models accessible to users. Users can contribute to the project by reporting issues, suggesting features, submitting pull requests, and sharing feedback. The architecture follows a service-based approach with service implementations for each AI capability. BreezeApp is a research project that may require specific hardware support or proprietary components, providing open-source alternatives where possible.
Awesome-AI-GPTs
Awesome AI GPTs is an open repository that collects resources and fun ways to use OpenAI GPTs. It includes databases, search tools, open-source projects, articles, attack and defense strategies, installation of custom plugins, knowledge bases, and community interactions related to GPTs. Users can find curated lists, leaked prompts, and various GPT applications in this repository. The project aims to empower users with AI capabilities and foster collaboration in the AI community.
HMusic
HMusic is an intelligent music player that supports Xiaomi AI speakers. It offers dual modes: xiaomusic server mode and Xiaomi IoT direct connection mode. Users can choose between these modes based on their preferences and needs. The direct connection mode is suitable for regular users who want a plug-and-play experience, while the xiaomusic mode is ideal for users with NAS/servers who require advanced features like a local music library, playlists, and progress control. The tool provides functionalities such as music search, playback, and volume control, catering to a wide range of music enthusiasts.
MaixPy
MaixPy is a Python SDK that enables users to easily create AI vision projects on edge devices. It provides a user-friendly API for accessing NPU, making it suitable for AI Algorithm Engineers, STEM teachers, Makers, Engineers, Students, Enterprises, and Contestants. The tool supports Python programming, MaixVision Workstation, AI vision, video streaming, voice recognition, and peripheral usage. It also offers an online AI training platform called MaixHub. MaixPy is designed for new hardware platforms like MaixCAM, offering improved performance and features compared to older versions. The ecosystem includes hardware, software, tools, documentation, and a cloud platform.
llumen
Llumen is a self-hosted interface optimized for modest hardware like Raspberry Pi, old laptops, and minimal VPS. It offers privacy without complexity, providing essential features with minimal resource demands. Users can enjoy sub-second cold starts, real-time token streaming, various chat modes, rich media support, and a universal API for OpenAI-compatible providers. The tool has a small footprint with a binary size of around 17MB and RAM usage under 128MB. Llumen aims to simplify the setup process and offer a user-friendly experience for individuals seeking a privacy-focused solution.
axonhub
AxonHub is an all-in-one AI development platform that serves as an AI gateway allowing users to switch between model providers without changing any code. It provides features like vendor lock-in prevention, integration simplification, observability enhancement, and cost control. Users can access any model using any SDK with zero code changes. The platform offers full request tracing, enterprise RBAC, smart load balancing, and real-time cost tracking. AxonHub supports multiple databases, provides a unified API gateway, and offers flexible model management and API key creation for authentication. It also integrates with various AI coding tools and SDKs for seamless usage.
general
General is a DART & Flutter library created by AZKADEV to speed up development on various platforms and CLI easily. It allows access to features such as camera, fingerprint, SMS, and MMS. The library is designed for Dart language and provides functionalities for app background, text to speech, speech to text, and more.

ai-dev-kit
The AI Dev Kit is a comprehensive toolkit designed to enhance AI-driven development on Databricks. It provides trusted sources for AI coding assistants like Claude Code and Cursor to build faster and smarter on Databricks. The kit includes features such as Spark Declarative Pipelines, Databricks Jobs, AI/BI Dashboards, Unity Catalog, Genie Spaces, Knowledge Assistants, MLflow Experiments, Model Serving, Databricks Apps, and more. Users can choose from different adventures like installing the kit, using the visual builder app, teaching AI assistants Databricks patterns, executing Databricks actions, or building custom integrations with the core library. The kit also includes components like databricks-tools-core, databricks-mcp-server, databricks-skills, databricks-builder-app, and ai-dev-project.
ReGraph
ReGraph is a decentralized AI compute marketplace that connects hardware providers with developers who need inference and training resources. It democratizes access to AI computing power by creating a global network of distributed compute nodes. It is cost-effective, decentralized, easy to integrate, supports multiple models, and offers pay-as-you-go pricing.
omi
Omi is an open-source AI wearable that provides automatic, high-quality transcriptions of meetings, chats, and voice memos. It revolutionizes how conversations are captured and managed by connecting to mobile devices. The tool offers features for seamless documentation and integration with third-party services.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.
langtrace
Langtrace is an open source observability software that lets you capture, debug, and analyze traces and metrics from all your applications that leverage LLM APIs, Vector Databases, and LLM-based Frameworks. It supports Open Telemetry Standards (OTEL), and the traces generated adhere to these standards. Langtrace offers both a managed SaaS version (Langtrace Cloud) and a self-hosted option. The SDKs for both Typescript/Javascript and Python are available, making it easy to integrate Langtrace into your applications. Langtrace automatically captures traces from various vendors, including OpenAI, Anthropic, Azure OpenAI, Langchain, LlamaIndex, Pinecone, and ChromaDB.
openakita
OpenAkita is a self-evolving AI Agent framework that autonomously learns new skills, performs daily self-checks and repairs, accumulates experience from task execution, and persists until the task is done. It auto-generates skills, installs dependencies, learns from mistakes, and remembers preferences. The framework is standards-based, multi-platform, and provides a Setup Center GUI for intuitive installation and configuration. It features self-learning and evolution mechanisms, a Ralph Wiggum Mode for persistent execution, multi-LLM endpoints, multi-platform IM support, desktop automation, multi-agent architecture, scheduled tasks, identity and memory management, a tool system, and a guided wizard for setup.
Auto-Claude
Auto Claude is an autonomous multi-agent coding framework that plans, builds, and validates software for users. It provides features such as autonomous tasks handling planning, implementation, and validation, parallel execution with multiple agent terminals, isolated workspaces for safe changes, self-validating quality assurance, AI-powered merge for conflict resolution, memory layer for smarter builds, GitHub/GitLab integration, cross-platform native desktop apps, auto-updates, and more. The tool offers a visual Kanban board for task management, AI-powered terminals for parallel work, AI-assisted feature planning, insights chat interface, ideation for code improvements, performance issues, and vulnerabilities discovery, and changelog generation from completed tasks. It follows a three-layer security model with OS sandbox, filesystem restrictions, and dynamic command allowlist, ensuring security through VirusTotal scans, SHA256 checksums, and code-signing for macOS releases.
Kai
Kai is a cross-platform open-source AI interface that runs on Android, iOS, Windows, Mac, Linux, and Web. It supports encrypted local history storage, text to speech output, seamless switch between services, and file attachments. Users can enable or disable tools like Get Local Time, Get Location, Send Notification, Create Calendar Event, Check Recent SMS, and Send SMS. The tool is designed to provide various AI services and features for different platforms.
For similar tasks
BreezeApp
BreezeApp is a community-driven platform for running AI capabilities locally on Android devices. It offers a privacy-focused solution where all AI features work offline, showcasing text-based chat interface, voice input/output support, and image understanding capabilities. The app supports multiple backends for different components and aims to make powerful AI models accessible to users. Users can contribute to the project by reporting issues, suggesting features, submitting pull requests, and sharing feedback. The architecture follows a service-based approach with service implementations for each AI capability. BreezeApp is a research project that may require specific hardware support or proprietary components, providing open-source alternatives where possible.
Airports
This repository contains raw airport files intended as a starting point to create new airport files for the game Endless ATC. Users can contribute by customizing airport files and submitting pull requests. The repository also welcomes markdown files with gameplay and development tips. Contributors are encouraged to join the Discord server for assistance and information.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.