
Video-ChatGPT
[ACL 2024 🔥] Video-ChatGPT is a video conversation model capable of generating meaningful conversation about videos. It combines the capabilities of LLMs with a pretrained visual encoder adapted for spatiotemporal video representation. We also introduce a rigorous 'Quantitative Evaluation Benchmarking' for video-based conversational models.
Stars: 1324
Video-ChatGPT is a video conversation model that aims to generate meaningful conversations about videos by combining large language models with a pretrained visual encoder adapted for spatiotemporal video representation. It introduces high-quality video-instruction pairs, a quantitative evaluation framework for video conversation models, and a unique multimodal capability for video understanding and language generation. The tool is designed to excel in tasks related to video reasoning, creativity, spatial and temporal understanding, and action recognition.
README:

Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models [ACL 2024 🔥]
Muhammad Maaz* , Hanoona Rasheed* , Salman Khan and Fahad Khan
* Equally contributing first authors
| Demo | Paper | Demo Clips | Offline Demo | Training | Video Instruction Data | Quantitative Evaluation | Qualitative Analysis |
|---|---|---|---|---|---|---|---|

|
|
Offline Demo | Training | Video Instruction Dataset | Quantitative Evaluation | Qualitative Analysis |
- Mar-28-25: Mobile-VideoGPT is released. It achieves excellent results on multiple benchmarks with 2x higher throughput. Check it out Mobile-VideoGPT 🔥🔥
- Jun-14-24: VideoGPT+ is released. It achieves SoTA results on multiple benchmarks. Check it out at VideoGPT+ 🔥🔥
- Jun-14-24: Semi-automatic video annotation pipeline is released. Check it out at GitHub, HuggingFace. 🔥🔥
- Jun-14-24: VCGBench-Diverse Benchmarks are released. It provides 4,354 human annotated QA pairs across 18 video categories to extensively evaluate the performance of a video-conversation model. Check it out at GitHub, HuggingFace. 🔥🔥
- May-16-24: Video-ChatGPT is accepted at ACL 2024! 🎊🎊
- Sep-30-23: Our VideoInstruct100K dataset can be downloaded from HuggingFace/VideoInstruct100K. 🔥🔥
- Jul-15-23: Our quantitative evaluation benchmark for Video-based Conversational Models now has its own dedicated website: https://mbzuai-oryx.github.io/Video-ChatGPT. 🔥🔥
- Jun-28-23: Updated GitHub readme featuring benchmark comparisons of Video-ChatGPT against recent models - Video Chat, Video LLaMA, and LLaMA Adapter. Amid these advanced conversational models, Video-ChatGPT continues to deliver state-of-the-art performance.:fire::fire:
- Jun-08-23 : Released the training code, offline demo, instructional data and technical report. All the resources including models, datasets and extracted features are available here. 🔥🔥
- May-21-23 : Video-ChatGPT: demo released.
🔥🔥 You can try our demo using the provided examples or by uploading your own videos HERE. 🔥🔥
🔥🔥 Or click the image to try the demo! 🔥🔥
![]() You can access all the videos we demonstrate on here.
You can access all the videos we demonstrate on here.
Video-ChatGPT is a video conversation model capable of generating meaningful conversation about videos. It combines the capabilities of LLMs with a pretrained visual encoder adapted for spatiotemporal video representation.

- We introduce 100K high-quality video-instruction pairs together with a novel annotation framework that is scalable and generates a diverse range of video-specific instruction sets of high-quality.
- We develop the first quantitative video conversation evaluation framework for benchmarking video conversation models.
- Unique multimodal (vision-language) capability combining video understanding and language generation that is comprehensively evaluated using quantitative and qualitiative comparisons on video reasoning, creativitiy, spatial and temporal understanding, and action recognition tasks.

We recommend setting up a conda environment for the project:
conda create --name=video_chatgpt python=3.10
conda activate video_chatgpt
git clone https://github.com/mbzuai-oryx/Video-ChatGPT.git
cd Video-ChatGPT
pip install -r requirements.txt
export PYTHONPATH="./:$PYTHONPATH"Additionally, install FlashAttention for training,
pip install ninja
git clone https://github.com/HazyResearch/flash-attention.git
cd flash-attention
git checkout v1.0.7
python setup.py installTo run the demo offline, please refer to the instructions in offline_demo.md.
For training instructions, check out train_video_chatgpt.md.
We are releasing our 100,000 high-quality video instruction dataset that was used for training our Video-ChatGPT model. You can download the dataset from here. More details on our human-assisted and semi-automatic annotation framework for generating the data are available at VideoInstructionDataset.md.
Our paper introduces a new Quantitative Evaluation Framework for Video-based Conversational Models. To explore our benchmarks and understand the framework in greater detail, please visit our dedicated website: https://mbzuai-oryx.github.io/Video-ChatGPT.
For detailed instructions on performing quantitative evaluation, please refer to QuantitativeEvaluation.md.
Video-based Generative Performance Benchmarking and Zero-Shot Question-Answer Evaluation tables are provided for a detailed performance overview.
| Model | MSVD-QA | MSRVTT-QA | TGIF-QA | Activity Net-QA | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Score | Accuracy | Score | Accuracy | Score | Accuracy | Score | |
| FrozenBiLM | 32.2 | -- | 16.8 | -- | 41.0 | -- | 24.7 | -- |
| Video Chat | 56.3 | 2.8 | 45.0 | 2.5 | 34.4 | 2.3 | 26.5 | 2.2 |
| LLaMA Adapter | 54.9 | 3.1 | 43.8 | 2.7 | - | - | 34.2 | 2.7 |
| Video LLaMA | 51.6 | 2.5 | 29.6 | 1.8 | - | - | 12.4 | 1.1 |
| Video-ChatGPT | 64.9 | 3.3 | 49.3 | 2.8 | 51.4 | 3.0 | 35.2 | 2.7 |
| Evaluation Aspect | Video Chat | LLaMA Adapter | Video LLaMA | Video-ChatGPT |
|---|---|---|---|---|
| Correctness of Information | 2.23 | 2.03 | 1.96 | 2.40 |
| Detail Orientation | 2.50 | 2.32 | 2.18 | 2.52 |
| Contextual Understanding | 2.53 | 2.30 | 2.16 | 2.62 |
| Temporal Understanding | 1.94 | 1.98 | 1.82 | 1.98 |
| Consistency | 2.24 | 2.15 | 1.79 | 2.37 |
A Comprehensive Evaluation of Video-ChatGPT's Performance across Multiple Tasks.







- LLaMA: A great attempt towards open and efficient LLMs!
- Vicuna: Has the amazing language capabilities!
- LLaVA: our architecture is inspired from LLaVA.
- Thanks to our colleagues at MBZUAI for their essential contribution to the video annotation task, including Salman Khan, Fahad Khan, Abdelrahman Shaker, Shahina Kunhimon, Muhammad Uzair, Sanoojan Baliah, Malitha Gunawardhana, Akhtar Munir, Vishal Thengane, Vignagajan Vigneswaran, Jiale Cao, Nian Liu, Muhammad Ali, Gayal Kurrupu, Roba Al Majzoub, Jameel Hassan, Hanan Ghani, Muzammal Naseer, Akshay Dudhane, Jean Lahoud, Awais Rauf, Sahal Shaji, Bokang Jia, without which this project would not be possible.
If you're using Video-ChatGPT in your research or applications, please cite using this BibTeX:
@inproceedings{Maaz2023VideoChatGPT,
title={Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models},
author={Maaz, Muhammad and Rasheed, Hanoona and Khan, Salman and Khan, Fahad Shahbaz},
booktitle={Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)},
year={2024}
}
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

Looking forward to your feedback, contributions, and stars! 🌟 Please raise any issues or questions here.
![]()
![]()
![]()
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Video-ChatGPT
Similar Open Source Tools
Video-ChatGPT
Video-ChatGPT is a video conversation model that aims to generate meaningful conversations about videos by combining large language models with a pretrained visual encoder adapted for spatiotemporal video representation. It introduces high-quality video-instruction pairs, a quantitative evaluation framework for video conversation models, and a unique multimodal capability for video understanding and language generation. The tool is designed to excel in tasks related to video reasoning, creativity, spatial and temporal understanding, and action recognition.

sktime
sktime is a Python library for time series analysis that provides a unified interface for various time series learning tasks such as classification, regression, clustering, annotation, and forecasting. It offers time series algorithms and tools compatible with scikit-learn for building, tuning, and validating time series models. sktime aims to enhance the interoperability and usability of the time series analysis ecosystem by empowering users to apply algorithms across different tasks and providing interfaces to related libraries like scikit-learn, statsmodels, tsfresh, PyOD, and fbprophet.


Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.
skpro
skpro is a library for supervised probabilistic prediction in python. It provides `scikit-learn`-like, `scikit-base` compatible interfaces to: * tabular **supervised regressors for probabilistic prediction** \- interval, quantile and distribution predictions * tabular **probabilistic time-to-event and survival prediction** \- instance-individual survival distributions * **metrics to evaluate probabilistic predictions** , e.g., pinball loss, empirical coverage, CRPS, survival losses * **reductions** to turn `scikit-learn` regressors into probabilistic `skpro` regressors, such as bootstrap or conformal * building **pipelines and composite models** , including tuning via probabilistic performance metrics * symbolic **probability distributions** with value domain of `pandas.DataFrame`-s and `pandas`-like interface
vlmrun-cookbook
VLM Run Cookbook is a repository containing practical examples and tutorials for extracting structured data from images, videos, and documents using Vision Language Models (VLMs). It offers comprehensive Colab notebooks demonstrating real-world applications of VLM Run, with complete code and documentation for easy adaptation. The examples cover various domains such as financial documents and TV news analysis.
claude-code-ultimate-guide
The Claude Code Ultimate Guide is an exhaustive documentation resource that takes users from beginner to power user in using Claude Code. It includes production-ready templates, workflow guides, a quiz, and a cheatsheet for daily use. The guide covers educational depth, methodologies, and practical examples to help users understand concepts and workflows. It also provides interactive onboarding, a repository structure overview, and learning paths for different user levels. The guide is regularly updated and offers a unique 257-question quiz for comprehensive assessment. Users can also find information on agent teams coverage, methodologies, annotated templates, resource evaluations, and learning paths for different roles like junior developer, senior developer, power user, and product manager/devops/designer.
LlamaV-o1
LlamaV-o1 is a Large Multimodal Model designed for spontaneous reasoning tasks. It outperforms various existing models on multimodal reasoning benchmarks. The project includes a Step-by-Step Visual Reasoning Benchmark, a novel evaluation metric, and a combined Multi-Step Curriculum Learning and Beam Search Approach. The model achieves superior performance in complex multi-step visual reasoning tasks in terms of accuracy and efficiency.
awesome-ai-efficiency
Awesome AI Efficiency is a curated list of resources dedicated to enhancing efficiency in AI systems. The repository covers various topics essential for optimizing AI models and processes, aiming to make AI faster, cheaper, smaller, and greener. It includes topics like quantization, pruning, caching, distillation, factorization, compilation, parameter-efficient fine-tuning, speculative decoding, hardware optimization, training techniques, inference optimization, sustainability strategies, and scalability approaches.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

mindnlp
MindNLP is an open-source NLP library based on MindSpore. It provides a platform for solving natural language processing tasks, containing many common approaches in NLP. It can help researchers and developers to construct and train models more conveniently and rapidly. Key features of MindNLP include: * Comprehensive data processing: Several classical NLP datasets are packaged into a friendly module for easy use, such as Multi30k, SQuAD, CoNLL, etc. * Friendly NLP model toolset: MindNLP provides various configurable components. It is friendly to customize models using MindNLP. * Easy-to-use engine: MindNLP simplified complicated training process in MindSpore. It supports Trainer and Evaluator interfaces to train and evaluate models easily. MindNLP supports a wide range of NLP tasks, including: * Language modeling * Machine translation * Question answering * Sentiment analysis * Sequence labeling * Summarization MindNLP also supports industry-leading Large Language Models (LLMs), including Llama, GLM, RWKV, etc. For support related to large language models, including pre-training, fine-tuning, and inference demo examples, you can find them in the "llm" directory. To install MindNLP, you can either install it from Pypi, download the daily build wheel, or install it from source. The installation instructions are provided in the documentation. MindNLP is released under the Apache 2.0 license. If you find this project useful in your research, please consider citing the following paper: @misc{mindnlp2022, title={{MindNLP}: a MindSpore NLP library}, author={MindNLP Contributors}, howpublished = {\url{https://github.com/mindlab-ai/mindnlp}}, year={2022} }

prism-insight
PRISM-INSIGHT is a comprehensive stock analysis and trading simulation system based on AI agents. It automatically captures daily surging stocks via Telegram channel, generates expert-level analyst reports, and performs trading simulations. The system utilizes OpenAI GPT-4.1 for in-depth stock analysis and GPT-5 for investment strategy simulation. It also interacts with users via Anthropic Claude for Telegram conversations. The system architecture includes AI analysis agents, stock tracking, PDF conversion, and Telegram bot functionalities. Users can customize criteria for identifying surging stocks, modify AI prompts, and adjust chart styles. The project is open-source under the MIT license, and all investment decisions based on the analysis are the responsibility of the user.

Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
lap
Lap is a lightning-fast, cross-platform photo manager that prioritizes user privacy and local AI processing. It allows users to organize and browse their photos efficiently, with features like natural language search, smart face recognition, and similar image search. Lap does not require importing photos, syncs seamlessly with the file system, and supports multiple libraries. Built for performance with a Rust core and lazy loading, Lap offers a delightful user experience with beautiful design, customization options, and multi-language support. It is a great alternative to cloud-based photo services, offering excellent organization, performance, and no vendor lock-in.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.
For similar tasks

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
starter-applets
This repository contains the source code for Google AI Studio's starter apps — a collection of small apps that demonstrate how Gemini can be used to create interactive experiences. These apps are built to run inside AI Studio, but the versions included here can run standalone using the Gemini API. The apps cover spatial understanding, video analysis, and map exploration, showcasing Gemini's capabilities in these areas. Developers can use these starter applets to kickstart their projects and learn how to leverage Gemini for spatial reasoning and interactive experiences.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
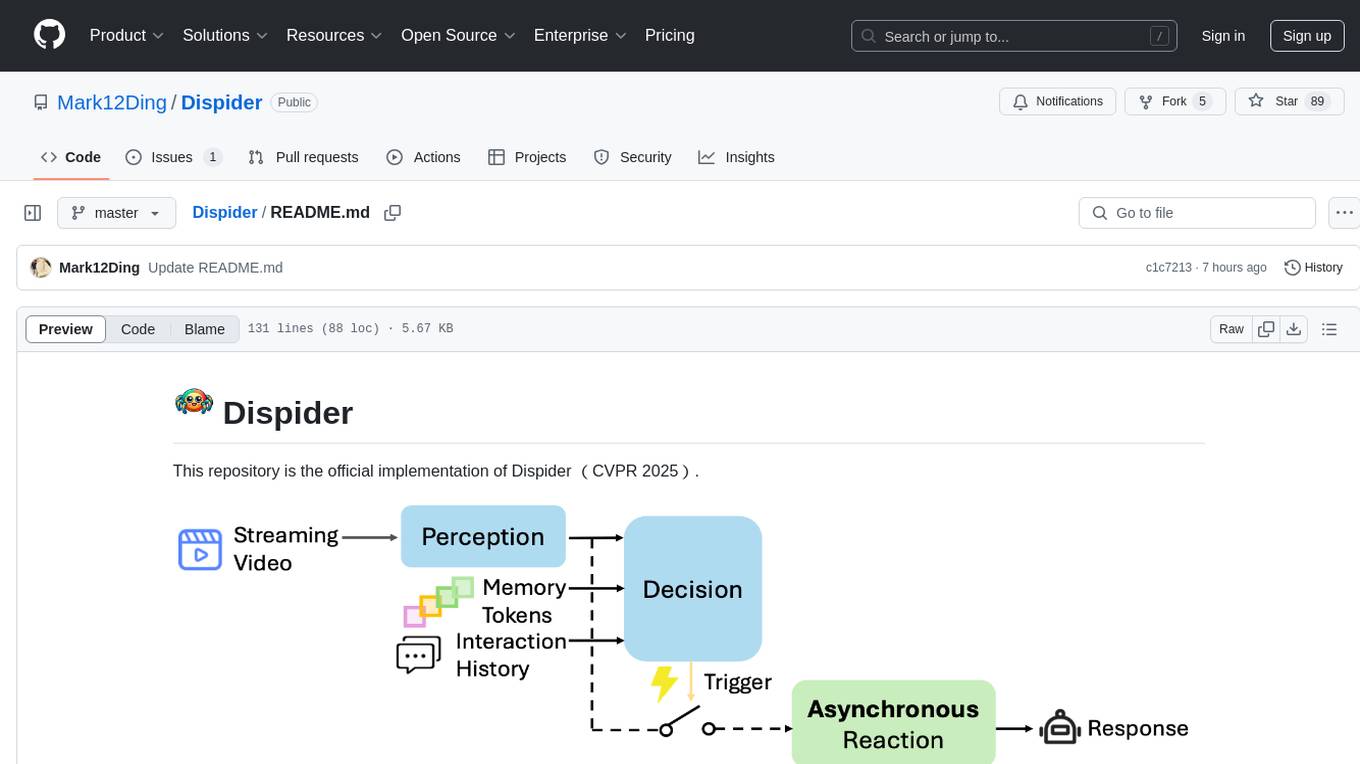
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.