
DI-engine
OpenDILab Decision AI Engine. The Most Comprehensive Reinforcement Learning Framework B.P.
Stars: 2887

README:








![]()
![]()

![]()
![]()
![]()










Updated on 2024.06.27 DI-engine-v0.5.2
Documentation | 中文文档 | Tutorials | Feature | Task & Middleware | TreeTensor | Roadmap
DI-engine is a generalized decision intelligence engine for PyTorch and JAX.
It provides python-first and asynchronous-native task and middleware abstractions, and modularly integrates several of the most important decision-making concepts: Env, Policy and Model. Based on the above mechanisms, DI-engine supports various deep reinforcement learning algorithms with superior performance, high efficiency, well-organized documentation and unittest:
- Most basic DRL algorithms: such as DQN, Rainbow, PPO, TD3, SAC, R2D2, IMPALA
- Multi-agent RL algorithms: such as QMIX, WQMIX, MAPPO, HAPPO, ACE
- Imitation learning algorithms (BC/IRL/GAIL): such as GAIL, SQIL, Guided Cost Learning, Implicit BC
- Offline RL algorithms: BCQ, CQL, TD3BC, Decision Transformer, EDAC, Diffuser, Decision Diffuser, SO2
- Model-based RL algorithms: SVG, STEVE, MBPO, DDPPO, DreamerV3
- Exploration algorithms: HER, RND, ICM, NGU
- LLM + RL Algorithms: PPO-max, DPO, PromptPG
- Other algorithms: such as PER, PLR, PCGrad
- MCTS + RL algorithms: AlphaZero, MuZero, please refer to LightZero
- Generative Model + RL algorithms: Diffusion-QL, QGPO, SRPO, please refer to GenerativeRL
DI-engine aims to standardize different Decision Intelligence environments and applications, supporting both academic research and prototype applications. Various training pipelines and customized decision AI applications are also supported:
(Click to Collapse)
-
Traditional academic environments
- DI-zoo: various decision intelligence demonstrations and benchmark environments with DI-engine.
-
Tutorial courses
- PPOxFamily: PPO x Family DRL Tutorial Course
-
Real world decision AI applications
- DI-star: Decision AI in StarCraftII
- PsyDI: Towards a Multi-Modal and Interactive Chatbot for Psychological Assessments
- DI-drive: Auto-driving platform
- DI-sheep: Decision AI in 3 Tiles Game
- DI-smartcross: Decision AI in Traffic Light Control
- DI-bioseq: Decision AI in Biological Sequence Prediction and Searching
- DI-1024: Deep Reinforcement Learning + 1024 Game
-
Research paper
- InterFuser: [CoRL 2022] Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer
- ACE: [AAAI 2023] ACE: Cooperative Multi-agent Q-learning with Bidirectional Action-Dependency
- GoBigger: [ICLR 2023] Multi-Agent Decision Intelligence Environment
- DOS: [CVPR 2023] ReasonNet: End-to-End Driving with Temporal and Global Reasoning
- LightZero: [NeurIPS 2023 Spotlight] A lightweight and efficient MCTS/AlphaZero/MuZero algorithm toolkit
- SO2: [AAAI 2024] A Perspective of Q-value Estimation on Offline-to-Online Reinforcement Learning
- LMDrive: [CVPR 2024] LMDrive: Closed-Loop End-to-End Driving with Large Language Models
- SmartRefine: [CVPR 2024] SmartRefine: A Scenario-Adaptive Refinement Framework for Efficient Motion Prediction
- ReZero: Boosting MCTS-based Algorithms by Backward-view and Entire-buffer Reanalyze
- UniZero: Generalized and Efficient Planning with Scalable Latent World Models
-
Docs and Tutorials
- DI-engine-docs: Tutorials, best practice and the API reference.
- awesome-model-based-RL: A curated list of awesome Model-Based RL resources
- awesome-exploration-RL: A curated list of awesome exploration RL resources
- awesome-decision-transformer: A curated list of Decision Transformer resources
- awesome-RLHF: A curated list of reinforcement learning with human feedback resources
- awesome-multi-modal-reinforcement-learning: A curated list of Multi-Modal Reinforcement Learning resources
- awesome-diffusion-model-in-rl: A curated list of Diffusion Model in RL resources
- awesome-ui-agents: A curated list of of awesome UI agents resources, encompassing Web, App, OS, and beyond
- awesome-AI-based-protein-design: a collection of research papers for AI-based protein design
- awesome-end-to-end-autonomous-driving: A curated list of awesome End-to-End Autonomous Driving resources
- awesome-driving-behavior-prediction: A collection of research papers for Driving Behavior Prediction
On the low-level end, DI-engine comes with a set of highly re-usable modules, including RL optimization functions, PyTorch utilities and auxiliary tools.
BTW, DI-engine also has some special system optimization and design for efficient and robust large-scale RL training:
(Click for Details)
- treevalue: Tree-nested data structure
- DI-treetensor: Tree-nested PyTorch tensor Lib
- DI-toolkit: A simple toolkit package for decision intelligence
- DI-orchestrator: RL Kubernetes Custom Resource and Operator Lib
- DI-hpc: RL HPC OP Lib
- DI-store: RL Object Store
Have fun with exploration and exploitation.
- Introduction to DI-engine
- Outline
- Installation
- Quick Start
- Feature
- Feedback and Contribution
- Supporters
- Citation
- License
You can simply install DI-engine from PyPI with the following command:
pip install DI-engineIf you use Anaconda or Miniconda, you can install DI-engine from conda-forge through the following command:
conda install -c opendilab di-engineFor more information about installation, you can refer to installation.
And our dockerhub repo can be found here,we prepare base image and env image with common RL environments.
(Click for Details)
- base: opendilab/ding:nightly
- rpc: opendilab/ding:nightly-rpc
- atari: opendilab/ding:nightly-atari
- mujoco: opendilab/ding:nightly-mujoco
- dmc: opendilab/ding:nightly-dmc2gym
- metaworld: opendilab/ding:nightly-metaworld
- smac: opendilab/ding:nightly-smac
- grf: opendilab/ding:nightly-grf
- cityflow: opendilab/ding:nightly-cityflow
- evogym: opendilab/ding:nightly-evogym
- d4rl: opendilab/ding:nightly-d4rl
The detailed documentation are hosted on doc | 中文文档.
DI-engine Huggingface Kickoff (colab)
How to migrate a new RL Env | 如何迁移一个新的强化学习环境
How to customize the neural network model | 如何定制策略使用的神经网络模型
(Click to Collapse)
discrete means discrete action space, which is only label in normal DRL algorithms (1-23)
means continuous action space, which is only label in normal DRL algorithms (1-23)
means hybrid (discrete + continuous) action space (1-23)
Distributed Reinforcement Learning|分布式强化学习
Multi-Agent Reinforcement Learning|多智能体强化学习
Exploration Mechanisms in Reinforcement Learning|强化学习中的探索机制
Offiline Reinforcement Learning|离线强化学习
Model-Based Reinforcement Learning|基于模型的强化学习
means other sub-direction algorithms, usually as plugin-in in the whole pipeline
P.S: The .py file in Runnable Demo can be found in dizoo
| No. | Algorithm | Label | Doc and Implementation | Runnable Demo |
|---|---|---|---|---|
| 1 | DQN |
DQN doc DQN中文文档 policy/dqn |
python3 -u cartpole_dqn_main.py / ding -m serial -c cartpole_dqn_config.py -s 0 | |
| 2 | C51 |
C51 doc policy/c51 |
ding -m serial -c cartpole_c51_config.py -s 0 | |
| 3 | QRDQN |
QRDQN doc policy/qrdqn |
ding -m serial -c cartpole_qrdqn_config.py -s 0 | |
| 4 | IQN |
IQN doc policy/iqn |
ding -m serial -c cartpole_iqn_config.py -s 0 | |
| 5 | FQF |
FQF doc policy/fqf |
ding -m serial -c cartpole_fqf_config.py -s 0 | |
| 6 | Rainbow |
Rainbow doc policy/rainbow |
ding -m serial -c cartpole_rainbow_config.py -s 0 | |
| 7 | SQL |
|
SQL doc policy/sql |
ding -m serial -c cartpole_sql_config.py -s 0 |
| 8 | R2D2 |
|
R2D2 doc policy/r2d2 |
ding -m serial -c cartpole_r2d2_config.py -s 0 |
| 9 | PG |
PG doc policy/pg |
ding -m serial -c cartpole_pg_config.py -s 0 | |
| 10 | PromptPG | policy/prompt_pg | ding -m serial_onpolicy -c tabmwp_pg_config.py -s 0 | |
| 11 | A2C |
A2C doc policy/a2c |
ding -m serial -c cartpole_a2c_config.py -s 0 | |
| 12 | PPO/MAPPO |
|
PPO doc policy/ppo |
python3 -u cartpole_ppo_main.py / ding -m serial_onpolicy -c cartpole_ppo_config.py -s 0 |
| 13 | PPG |
PPG doc policy/ppg |
python3 -u cartpole_ppg_main.py | |
| 14 | ACER |
|
ACER doc policy/acer |
ding -m serial -c cartpole_acer_config.py -s 0 |
| 15 | IMPALA |
|
IMPALA doc policy/impala |
ding -m serial -c cartpole_impala_config.py -s 0 |
| 16 | DDPG/PADDPG |
|
DDPG doc policy/ddpg |
ding -m serial -c pendulum_ddpg_config.py -s 0 |
| 17 | TD3 |
|
TD3 doc policy/td3 |
python3 -u pendulum_td3_main.py / ding -m serial -c pendulum_td3_config.py -s 0 |
| 18 | D4PG |
D4PG doc policy/d4pg |
python3 -u pendulum_d4pg_config.py | |
| 19 | SAC/[MASAC] |
|
SAC doc policy/sac |
ding -m serial -c pendulum_sac_config.py -s 0 |
| 20 | PDQN | policy/pdqn | ding -m serial -c gym_hybrid_pdqn_config.py -s 0 | |
| 21 | MPDQN | policy/pdqn | ding -m serial -c gym_hybrid_mpdqn_config.py -s 0 | |
| 22 | HPPO | policy/ppo | ding -m serial_onpolicy -c gym_hybrid_hppo_config.py -s 0 | |
| 23 | BDQ | policy/bdq | python3 -u hopper_bdq_config.py | |
| 24 | MDQN | policy/mdqn | python3 -u asterix_mdqn_config.py | |
| 25 | QMIX |
QMIX doc policy/qmix |
ding -m serial -c smac_3s5z_qmix_config.py -s 0 | |
| 26 | COMA |
COMA doc policy/coma |
ding -m serial -c smac_3s5z_coma_config.py -s 0 | |
| 27 | QTran | policy/qtran | ding -m serial -c smac_3s5z_qtran_config.py -s 0 | |
| 28 | WQMIX |
WQMIX doc policy/wqmix |
ding -m serial -c smac_3s5z_wqmix_config.py -s 0 | |
| 29 | CollaQ |
CollaQ doc policy/collaq |
ding -m serial -c smac_3s5z_collaq_config.py -s 0 | |
| 30 | MADDPG |
MADDPG doc policy/ddpg |
ding -m serial -c ptz_simple_spread_maddpg_config.py -s 0 | |
| 31 | GAIL |
GAIL doc reward_model/gail |
ding -m serial_gail -c cartpole_dqn_gail_config.py -s 0 | |
| 32 | SQIL |
SQIL doc entry/sqil |
ding -m serial_sqil -c cartpole_sqil_config.py -s 0 | |
| 33 | DQFD |
DQFD doc policy/dqfd |
ding -m serial_dqfd -c cartpole_dqfd_config.py -s 0 | |
| 34 | R2D3 |
R2D3 doc R2D3中文文档 policy/r2d3 |
python3 -u pong_r2d3_r2d2expert_config.py | |
| 35 | Guided Cost Learning |
Guided Cost Learning中文文档 reward_model/guided_cost |
python3 lunarlander_gcl_config.py | |
| 36 | TREX |
TREX doc reward_model/trex |
python3 mujoco_trex_main.py | |
| 37 | Implicit Behavorial Cloning (DFO+MCMC) |
policy/ibc model/template/ebm |
python3 d4rl_ibc_main.py -s 0 -c pen_human_ibc_mcmc_config.py | |
| 38 | BCO | entry/bco | python3 -u cartpole_bco_config.py | |
| 39 | HER |
HER doc reward_model/her |
python3 -u bitflip_her_dqn.py | |
| 40 | RND |
RND doc reward_model/rnd |
python3 -u cartpole_rnd_onppo_config.py | |
| 41 | ICM |
ICM doc ICM中文文档 reward_model/icm |
python3 -u cartpole_ppo_icm_config.py | |
| 42 | CQL |
CQL doc policy/cql |
python3 -u d4rl_cql_main.py | |
| 43 | TD3BC |
TD3BC doc policy/td3_bc |
python3 -u d4rl_td3_bc_main.py | |
| 44 | Decision Transformer | policy/dt | python3 -u d4rl_dt_mujoco.py | |
| 45 | EDAC |
EDAC doc policy/edac |
python3 -u d4rl_edac_main.py | |
| 46 | QGPO |
QGPO doc policy/qgpo |
python3 -u ding/example/qgpo.py | |
| 47 | MBSAC(SAC+MVE+SVG) |
|
policy/mbpolicy/mbsac | python3 -u pendulum_mbsac_mbpo_config.py \ python3 -u pendulum_mbsac_ddppo_config.py |
| 48 | STEVESAC(SAC+STEVE+SVG) |
|
policy/mbpolicy/mbsac | python3 -u pendulum_stevesac_mbpo_config.py |
| 49 | MBPO |
MBPO doc world_model/mbpo |
python3 -u pendulum_sac_mbpo_config.py | |
| 50 | DDPPO | world_model/ddppo | python3 -u pendulum_mbsac_ddppo_config.py | |
| 51 | DreamerV3 | world_model/dreamerv3 | python3 -u cartpole_balance_dreamer_config.py | |
| 52 | PER | worker/replay_buffer | rainbow demo |
|
| 53 | GAE | rl_utils/gae | ppo demo |
|
| 54 | ST-DIM | torch_utils/loss/contrastive_loss | ding -m serial -c cartpole_dqn_stdim_config.py -s 0 | |
| 55 | PLR |
PLR doc data/level_replay/level_sampler |
python3 -u bigfish_plr_config.py -s 0 | |
| 56 | PCGrad | torch_utils/optimizer_helper/PCGrad | python3 -u multi_mnist_pcgrad_main.py -s 0 |
(Click to Collapse)






































means discrete action space
means continuous action space
means hybrid (discrete + continuous) action space
means multi-agent RL environment
means environment which is related to exploration and sparse reward
means offline RL environment
means Imitation Learning or Supervised Learning Dataset
means environment that allows agent VS agent battle
P.S. some enviroments in Atari, such as MontezumaRevenge, are also the sparse reward type.
DI-engine utilizes TreeTensor as the basic data container in various components, which is ease of use and consistent across different code modules such as environment definition, data processing and DRL optimization. Here are some concrete code examples:
-
TreeTensor can easily extend all the operations of
torch.Tensorto nested data:(Click for Details)
import treetensor.torch as ttorch # create random tensor data = ttorch.randn({'a': (3, 2), 'b': {'c': (3, )}}) # clone+detach tensor data_clone = data.clone().detach() # access tree structure like attribute a = data.a c = data.b.c # stack/cat/split stacked_data = ttorch.stack([data, data_clone], 0) cat_data = ttorch.cat([data, data_clone], 0) data, data_clone = ttorch.split(stacked_data, 1) # reshape data = data.unsqueeze(-1) data = data.squeeze(-1) flatten_data = data.view(-1) # indexing data_0 = data[0] data_1to2 = data[1:2] # execute math calculations data = data.sin() data.b.c.cos_().clamp_(-1, 1) data += data ** 2 # backward data.requires_grad_(True) loss = data.arctan().mean() loss.backward() # print shape print(data.shape) # result # <Size 0x7fbd3346ddc0> # ├── 'a' --> torch.Size([1, 3, 2]) # └── 'b' --> <Size 0x7fbd3346dd00> # └── 'c' --> torch.Size([1, 3])
-
TreeTensor can make it simple yet effective to implement classic deep reinforcement learning pipeline
(Click for Details)
import torch import treetensor.torch as ttorch B = 4 def get_item(): return { 'obs': { 'scalar': torch.randn(12), 'image': torch.randn(3, 32, 32), }, 'action': torch.randint(0, 10, size=(1,)), 'reward': torch.rand(1), 'done': False, } data = [get_item() for _ in range(B)] # execute `stack` op - def stack(data, dim): - elem = data[0] - if isinstance(elem, torch.Tensor): - return torch.stack(data, dim) - elif isinstance(elem, dict): - return {k: stack([item[k] for item in data], dim) for k in elem.keys()} - elif isinstance(elem, bool): - return torch.BoolTensor(data) - else: - raise TypeError("not support elem type: {}".format(type(elem))) - stacked_data = stack(data, dim=0) + data = [ttorch.tensor(d) for d in data] + stacked_data = ttorch.stack(data, dim=0) # validate - assert stacked_data['obs']['image'].shape == (B, 3, 32, 32) - assert stacked_data['action'].shape == (B, 1) - assert stacked_data['reward'].shape == (B, 1) - assert stacked_data['done'].shape == (B,) - assert stacked_data['done'].dtype == torch.bool + assert stacked_data.obs.image.shape == (B, 3, 32, 32) + assert stacked_data.action.shape == (B, 1) + assert stacked_data.reward.shape == (B, 1) + assert stacked_data.done.shape == (B,) + assert stacked_data.done.dtype == torch.bool
-
File an issue on Github
-
Open or participate in our forum
-
Discuss on DI-engine discord server
-
Discuss on DI-engine slack communication channel
-
Discuss on DI-engine's WeChat group (i.e. add us on WeChat: ding314assist)

-
Contact our email ([email protected])
-
Contributes to our future plan Roadmap

We appreciate all the feedbacks and contributions to improve DI-engine, both algorithms and system designs. And CONTRIBUTING.md offers some necessary information.
@misc{ding,
title={DI-engine: A Universal AI System/Engine for Decision Intelligence},
author={Niu, Yazhe and Xu, Jingxin and Pu, Yuan and Nie, Yunpeng and Zhang, Jinouwen and Hu, Shuai and Zhao, Liangxuan and Zhang, Ming and Liu, Yu},
publisher={GitHub},
howpublished={\url{https://github.com/opendilab/DI-engine}},
year={2021},
}DI-engine released under the Apache 2.0 license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DI-engine
Similar Open Source Tools

EmoLLM
EmoLLM is a series of large-scale psychological health counseling models that can support **understanding-supporting-helping users** in the psychological health counseling chain, which is fine-tuned from `LLM` instructions. Welcome everyone to star~⭐⭐. The currently open source `LLM` fine-tuning configurations are as follows:
cgft-llm
The cgft-llm repository is a collection of video tutorials and documentation for implementing large models. It provides guidance on topics such as fine-tuning llama3 with llama-factory, lightweight deployment and quantization using llama.cpp, speech generation with ChatTTS, introduction to Ollama for large model deployment, deployment tools for vllm and paged attention, and implementing RAG with llama-index. Users can find detailed code documentation and video tutorials for each project in the repository.
LLMs-from-scratch-CN
This repository is a Chinese translation of the GitHub project 'LLMs-from-scratch', including detailed markdown notes and related Jupyter code. The translation process aims to maintain the accuracy of the original content while optimizing the language and expression to better suit Chinese learners' reading habits. The repository features detailed Chinese annotations for all Jupyter code, aiding users in practical implementation. It also provides various supplementary materials to expand knowledge. The project focuses on building Large Language Models (LLMs) from scratch, covering fundamental constructions like Transformer architecture, sequence modeling, and delving into deep learning models such as GPT and BERT. Each part of the project includes detailed code implementations and learning resources to help users construct LLMs from scratch and master their core technologies.
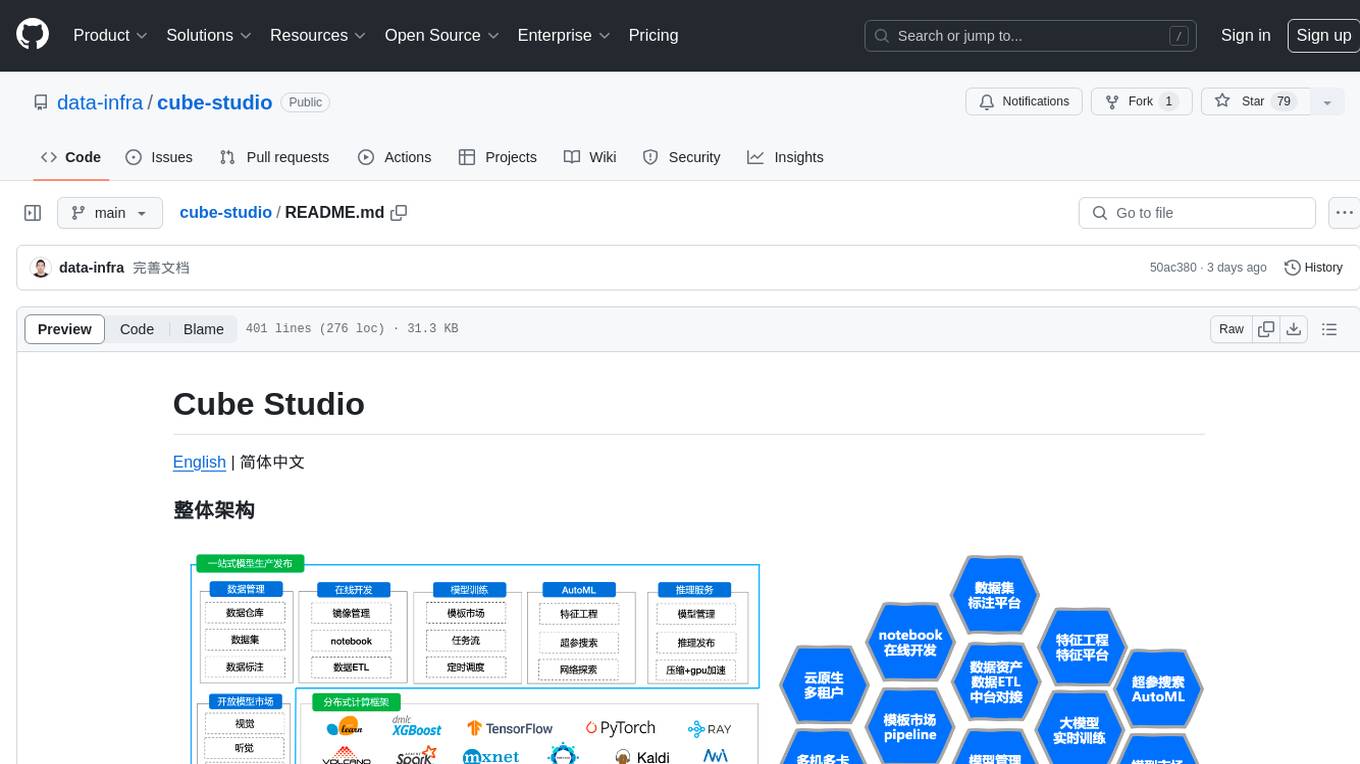
cube-studio
Cube Studio is an open-source all-in-one cloud-native machine learning platform that provides various functionalities such as project group management, network configuration, user management, role management, billing functions, SSO single sign-on, support for multiple computing power types, support for multiple resource groups and clusters, edge cluster support, serverless cluster mode support, database storage support, machine resource management, storage disk management, internationalization capabilities, data map management, data calculation, ETL orchestration, data set management, data annotation, image/audio/text dataset support, feature processing, traditional machine learning algorithms, distributed deep learning frameworks, distributed acceleration frameworks, model evaluation, model format conversion, model registration, model deployment, distributed media processing, custom operators, automatic learning, custom training images, automatic parameter tuning, TensorBoard jobs, internal services, model management, inference services, monitoring, model application management, model marketplace, model development, model fine-tuning, web model deployment, automated annotation, dataset SDK, notebook SDK, pipeline training SDK, inference service SDK, large model distributed training, large model inference, large model fine-tuning, intelligent conversation, private knowledge base, model deployment for WeChat public accounts, enterprise WeChat group chatbot integration, DingTalk group chatbot integration, and more. Cube Studio offers template-based functionality for data import/export, data processing, feature processing, machine learning frameworks, machine learning algorithms, deep learning frameworks, model processing, model serving, monitoring, and more.
haystack-core-integrations
This repository contains integrations to extend the capabilities of Haystack version 2.0 and onwards. The code in this repo is maintained by deepset, see each integration's `README` file for details around installation, usage and support.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.
goat
GOAT (Great Onchain Agent Toolkit) is an open-source framework designed to simplify the process of making AI agents perform onchain actions by providing a provider-agnostic solution that abstracts away the complexities of interacting with blockchain tools such as wallets, token trading, and smart contracts. It offers a catalog of ready-made blockchain actions for agent developers and allows dApp/smart contract developers to develop plugins for easy access by agents. With compatibility across popular agent frameworks, support for multiple blockchains and wallet providers, and customizable onchain functionalities, GOAT aims to streamline the integration of blockchain capabilities into AI agents.

MEGREZ
MEGREZ is a modern and elegant open-source high-performance computing platform that efficiently manages GPU resources. It allows for easy container instance creation, supports multiple nodes/multiple GPUs, modern UI environment isolation, customizable performance configurations, and user data isolation. The platform also comes with pre-installed deep learning environments, supports multiple users, features a VSCode web version, resource performance monitoring dashboard, and Jupyter Notebook support.
erp-pro
ERP-Pro is an intelligent manufacturing integrated platform developed using Springboot (microservices) + UNI-APP + Ant Design Vue's zero-code development mode. It includes over 50 electronic processes, CRM, PM, ERP, MES, ADM, OA, EHR, AI, projects, malls, finance, multi-shift attendance, payroll, recruitment, cloud after-sales, forums, surveys, report design, workflow, Saas, and more. It aims to create the first set of zero-code, most comprehensive, and most cost-effective intelligent manufacturing industry supply chain integrated management software on the web.
widgets
Widgets is a desktop component front-end open source component. The project is still being continuously improved. The desktop component client can be downloaded and run in two ways: 1. https://www.microsoft.com/store/productId/9NPR50GQ7T53 2. https://widgetjs.cn After cloning the code, you need to download the dependency in the project directory: `shell pnpm install` and run: `shell pnpm serve`
TigerBot
TigerBot is a cutting-edge foundation for your very own LLM, providing a world-class large model for innovative Chinese-style contributions. It offers various upgrades and features, such as search mode enhancements, support for large context lengths, and the ability to play text-based games. TigerBot is suitable for prompt-based game engine development, interactive game design, and real-time feedback for playable games.

awesome-ai-painting
This repository, named 'awesome-ai-painting', is a comprehensive collection of resources related to AI painting. It is curated by a user named 秋风, who is an AI painting enthusiast with a background in the AIGC industry. The repository aims to help more people learn AI painting and also documents the user's goal of creating 100 AI products, with current progress at 4/100. The repository includes information on various AI painting products, tutorials, tools, and models, providing a valuable resource for individuals interested in AI painting and related technologies.