
LLMs-from-scratch-CN
LLMs-from-scratch项目中文翻译
Stars: 130
This repository is a Chinese translation of the GitHub project 'LLMs-from-scratch', including detailed markdown notes and related Jupyter code. The translation process aims to maintain the accuracy of the original content while optimizing the language and expression to better suit Chinese learners' reading habits. The repository features detailed Chinese annotations for all Jupyter code, aiding users in practical implementation. It also provides various supplementary materials to expand knowledge. The project focuses on building Large Language Models (LLMs) from scratch, covering fundamental constructions like Transformer architecture, sequence modeling, and delving into deep learning models such as GPT and BERT. Each part of the project includes detailed code implementations and learning resources to help users construct LLMs from scratch and master their core technologies.
README:



原项目与地址:《LLMs-from-scratch》
本项目是对GitHub项目《LLMs-from-scratch》内容的中文翻译,包括详细的markdown 笔记和相关的jupyter 代码。翻译过程中,我们尽可能保持原意的准确性,同时对部分内容进行了语序和表达的优化,以更贴合中文学习者的阅读习惯。需要特别说明的是,原作者为该项目的主要贡献者,本汉化版本仅作为学习辅助资料,不对原内容进行修改或延伸。
由于个人能力有限,翻译中可能存在不完善之处,欢迎提出宝贵意见并多多包涵 希望通过这一翻译项目,更多中文学习者能够从中受益,也希望为国内社区的 LLM 学习和研究贡献一份力量。
本项目的特色: jupyter代码均有详细中文注释,帮助大家更快上手实践。 诸多的附加材料可以拓展知识
本项目所用徽章来自互联网,如侵犯了您的图片版权请联系我们删除,谢谢。
提到大语言模型(LLMs),我们可能会将其视为独立于传统机器学习的领域,但实际上,LLMs 是机器学习的一个重要分支。在深度学习尚未广泛应用之前,机器学习在许多领域(如语音识别、自然语言处理、计算机视觉等)的作用相对有限,因为这些领域往往需要大量的专业知识来应对复杂的现实问题。然而,近几年深度学习的快速发展彻底改变了这一状况,使 LLMs 成为推动人工智能技术革命的关键力量。
原项目与地址:《LLMs-from-scratch》 https://github.com/rasbt/LLMs-from-scratch.git
在 《LLMs-from-scratch》项目中,不仅关注 LLMs 的基础构建,如 Transformer 架构、序列建模 等,还深入探索了 GPT、BERT 等深度学习模型 的底层实现。项目中的每一部分均配备详细的代码实现和学习资源,帮助学习者从零开始构建 LLMs,全面掌握其核心技术。
- 英文原版地址:原版地址
- 教材网址:原版教材
- 汉化地址:https://github.com/MLNLP-World/LLMs-from-scratch-CN.git
此外,本门课程还有相应的代码实现。每章都有相应的jupyter记事本,提供模型的完整python代码,所有的资源都可在网上免费获取。
这个仓库包含了开发、预训练和微调一个类似GPT的LLM(大语言模型)的代码,是《从零构建大模型》这本书的官方代码仓库,书籍链接:从零构建大模型。

在《从零构建大模型》这本书中,您将逐步了解大语言模型(LLMs)如何从内到外工作,自己动手编写代码,逐步构建一个LLM。在这本书中,我将通过清晰的文字、图示和示例,带您完成构建自己LLM的每一个阶段。
本书描述的训练和开发自己的小型功能性模型的方法,旨在教育用途,类似于用于创建大规模基础模型(如ChatGPT背后的模型)的方法。此外,本书还包括加载更大预训练模型权重进行微调的代码。
- 官方源代码仓库链接
- 汉化版本汉化仓库链接
- 出版商网站上的书籍链接
- Amazon.com上的书籍页面链接
- ISBN 9781633437166

要下载此仓库的副本,请点击下载ZIP按钮,或者在终端中执行以下命令:
git clone --depth 1 https://github.com/rasbt/LLMs-from-scratch.git要下载此仓库汉化版本,请点击下载ZIP按钮,或者在终端中执行以下命令:
git clone --depth 1 https://github.com/MLNLP-World/LLMs-from-scratch-CN.git(如果您是从Manning网站下载的代码包,请访问官方代码仓库 https://github.com/rasbt/LLMs-from-scratch 获取最新的更新 或者汉化版本https://github.com/MLNLP-World/LLMs-from-scratch-CN.git)
请注意,本文档是一个Markdown (.md) 文件。如果您是从Manning网站下载的代码包并在本地查看它,建议使用Markdown编辑器或预览器进行正确查看。如果您尚未安装Markdown编辑器,MarkText 是一个不错的免费选项。
您也可以通过浏览器访问GitHub上的代码仓库,或者汉化版浏览器会自动渲染Markdown。
[!TIP] 如果您需要安装Python和Python包以及设置代码环境的指导,建议阅读README.md 文件,该文件位于setup目录中。
| 章节标题 | 主要代码(快速访问) | 所有代码及补充内容 | 翻译者 | 校对者 |
|---|---|---|---|---|
| 安装建议 | - | - |  |
 |
| 第1章:理解大型语言模型 | 无代码 | - | |
|
| 第2章:处理文本数据 | - ch02.ipynb - dataloader.ipynb(总结) - exercise-solutions.ipynb |
ch02 | |
|
| 第3章:编码注意力机制 | - ch03.ipynb - multihead-attention.ipynb(总结) - exercise-solutions.ipynb |
ch03 | |
|
| 第4章:从零开始实现 GPT 模型 | - ch04.ipynb - gpt.py(总结) - exercise-solutions.ipynb |
ch04 | |
|
| 第5章:在无标注数据上进行预训练 | - ch05.ipynb - gpt_train.py(总结) - gpt_generate.py(总结) - exercise-solutions.ipynb |
ch05 | |
 |
| 第6章:进行文本分类的微调 | - ch06.ipynb - gpt_class_finetune.py - exercise-solutions.ipynb |
ch06 | |
|
| 第7章:进行遵循指令的微调 | - ch07.ipynb - gpt_instruction_finetuning.py(总结) - ollama_evaluate.py(总结) - exercise-solutions.ipynb |
ch07 | |
|
| 附录 A:PyTorch 简介 | - code-part1.ipynb - code-part2.ipynb - DDP-script.py - exercise-solutions.ipynb |
appendix-A | |
 |
| 附录 B:参考文献与进一步阅读 | 无代码 | - | ||
| 附录 C:习题解答 | 无代码 | - | ||
| 附录 D:在训练循环中加入附加功能 | - appendix-D.ipynb | appendix-D | |
|
| 附录 E:使用 LoRA 进行参数高效微调 | - appendix-E.ipynb | appendix-E | |
|
下图是本书内容的总结性思维导图。
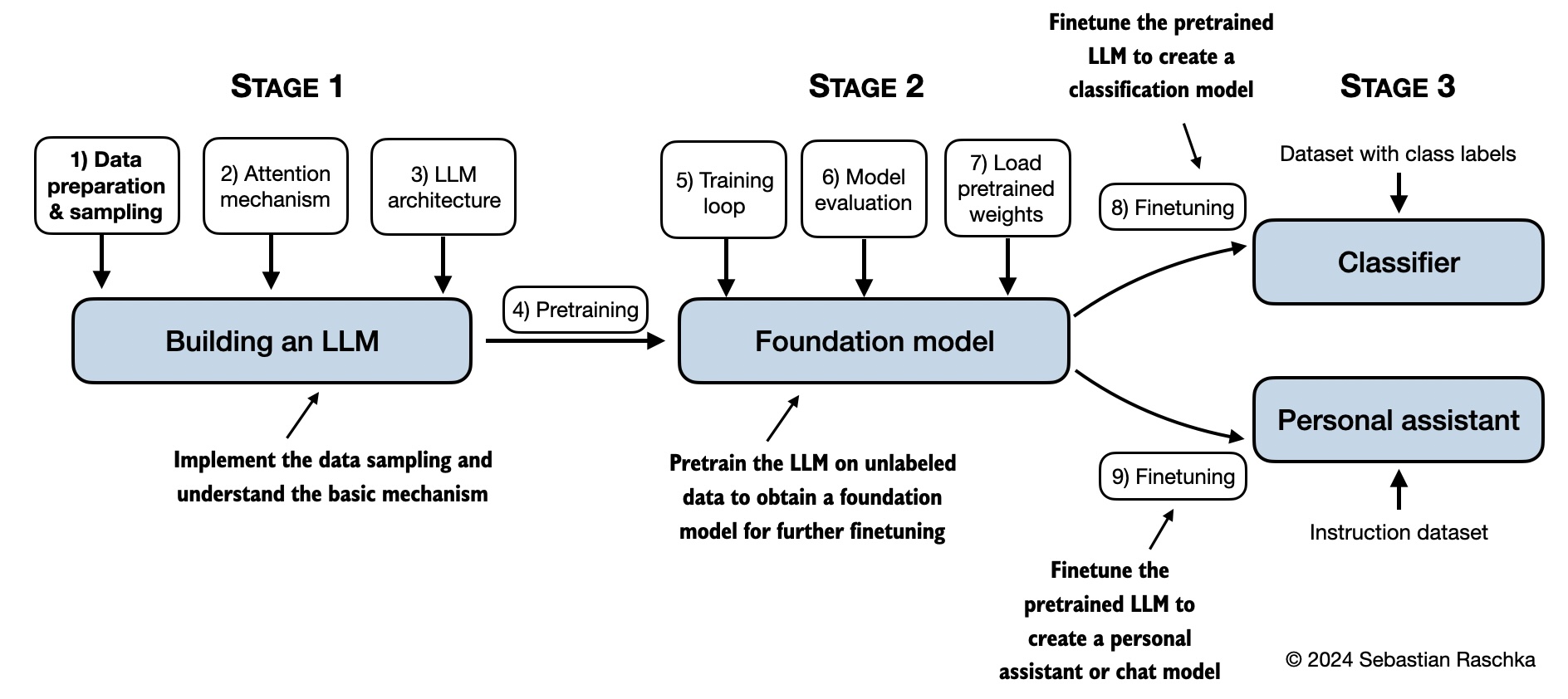
本书主要章节中的代码设计为能够在常规笔记本电脑上运行,并且不会占用过长时间,因此不需要专门的硬件。这种方式确保了广泛的读者群体能够参与其中。此外,如果有可用的 GPU,代码会自动使用它们。(更多建议请参考 setup 文档。)
欢迎各种形式的反馈,最好通过 Manning 论坛 或 GitHub 讨论区 分享。如果你有任何问题或只是想与他人讨论想法,也请随时在论坛中发布。
请注意,由于本存储库包含与印刷书籍相对应的代码,因此目前无法接受扩展主要章节代码内容的贡献,因为这可能会导致与实体书籍的内容不一致。保持一致性有助于确保每个人的顺畅体验。
如果你发现本书或代码对你的研究有帮助,请考虑引用它。
引用:
Raschka, Sebastian. Build A Large Language Model (From Scratch). Manning, 2024. ISBN: 978-1633437166.
BibTeX 条目:
@book{build-llms-from-scratch-book,
author = {Sebastian Raschka},
title = {Build A Large Language Model (From Scratch)},
publisher = {Manning},
year = {2024},
isbn = {978-1633437166},
url = {https://www.manning.com/books/build-a-large-language-model-from-scratch},
github = {https://github.com/rasbt/LLMs-from-scratch}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLMs-from-scratch-CN
Similar Open Source Tools
LLMs-from-scratch-CN
This repository is a Chinese translation of the GitHub project 'LLMs-from-scratch', including detailed markdown notes and related Jupyter code. The translation process aims to maintain the accuracy of the original content while optimizing the language and expression to better suit Chinese learners' reading habits. The repository features detailed Chinese annotations for all Jupyter code, aiding users in practical implementation. It also provides various supplementary materials to expand knowledge. The project focuses on building Large Language Models (LLMs) from scratch, covering fundamental constructions like Transformer architecture, sequence modeling, and delving into deep learning models such as GPT and BERT. Each part of the project includes detailed code implementations and learning resources to help users construct LLMs from scratch and master their core technologies.
generative-ai-use-cases-jp
Generative AI (生成 AI) brings revolutionary potential to transform businesses. This repository demonstrates business use cases leveraging Generative AI.

MEGREZ
MEGREZ is a modern and elegant open-source high-performance computing platform that efficiently manages GPU resources. It allows for easy container instance creation, supports multiple nodes/multiple GPUs, modern UI environment isolation, customizable performance configurations, and user data isolation. The platform also comes with pre-installed deep learning environments, supports multiple users, features a VSCode web version, resource performance monitoring dashboard, and Jupyter Notebook support.
Qbot
Qbot is an AI-oriented automated quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It provides a full closed-loop process from data acquisition, strategy development, backtesting, simulation trading to live trading. The platform emphasizes AI strategies such as machine learning, reinforcement learning, and deep learning, combined with multi-factor models to enhance returns. Users with some Python knowledge and trading experience can easily utilize the platform to address trading pain points and gaps in the market.

EmoLLM
EmoLLM is a series of large-scale psychological health counseling models that can support **understanding-supporting-helping users** in the psychological health counseling chain, which is fine-tuned from `LLM` instructions. Welcome everyone to star~⭐⭐. The currently open source `LLM` fine-tuning configurations are as follows:

Awesome-LLM-RAG-Application
Awesome-LLM-RAG-Application is a repository that provides resources and information about applications based on Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) pattern. It includes a survey paper, GitHub repo, and guides on advanced RAG techniques. The repository covers various aspects of RAG, including academic papers, evaluation benchmarks, downstream tasks, tools, and technologies. It also explores different frameworks, preprocessing tools, routing mechanisms, evaluation frameworks, embeddings, security guardrails, prompting tools, SQL enhancements, LLM deployment, observability tools, and more. The repository aims to offer comprehensive knowledge on RAG for readers interested in exploring and implementing LLM-based systems and products.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.
Awesome-Chinese-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, ,'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in less than 3 words,Verb + noun form,in daily spoken language,in lowercase letters).Answer in english languagesname:Awesome-Chinese-LLM readme:# Awesome Chinese LLM   An Awesome Collection for LLM in Chinese 收集和梳理中文LLM相关    自ChatGPT为代表的大语言模型(Large Language Model, LLM)出现以后,由于其惊人的类通用人工智能(AGI)的能力,掀起了新一轮自然语言处理领域的研究和应用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例。本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个! 如果本项目能给您带来一点点帮助,麻烦点个⭐️吧~ 同时也欢迎大家贡献本项目未收录的开源模型、应用、数据集等。提供新的仓库信息请发起PR,并按照本项目的格式提供仓库链接、star数,简介等相关信息,感谢~
cia
CIA is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for processing large datasets and generating insightful reports. With CIA, users can easily explore data, perform statistical analysis, and create interactive visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, CIA offers a comprehensive set of features to streamline your data analysis workflow and uncover valuable insights.
PocketFlow
Pocket Flow is a 100-line minimalist LLM framework designed for (Multi-)Agents, Workflow, RAG, etc. It provides a core abstraction for LLM projects by focusing on computation and communication through a graph structure and shared store. The framework aims to support the development of LLM Agents, such as Cursor AI, by offering a minimal and low-level approach that is well-suited for understanding and usage. Users can install Pocket Flow via pip or by copying the source code, and detailed documentation is available on the project website.
99AI
99AI is a commercializable AI web application based on NineAI 2.4.2 (no authorization, no backdoors, no piracy, integrated front-end and back-end integration packages, supports Docker rapid deployment). The uncompiled source code is temporarily closed. Compared with the stable version, the development version is faster.
LLMOne
LLMOne is an open-source, lightweight enterprise-level platform for deploying and serving large language models. It aims to address pain points in traditional large model private deployment such as long cycles, complex configurations, performance challenges, and high operational costs. LLMOne simplifies the deployment process with highly automated workflows and optimized runtime environments, ensuring enterprise-level performance and stability. It caters to developers, manufacturers, and users of large language models, providing features like rapid deployment, professional inference performance, broad compatibility with AI hardware, flexible model and application management, visual operational monitoring, and an open application ecosystem.

agentica
Agentica is a human-centric framework for building large language model agents. It provides functionalities for planning, memory management, tool usage, and supports features like reflection, planning and execution, RAG, multi-agent, multi-role, and workflow. The tool allows users to quickly code and orchestrate agents, customize prompts, and make API calls to various services. It supports API calls to OpenAI, Azure, Deepseek, Moonshot, Claude, Ollama, and Together. Agentica aims to simplify the process of building AI agents by providing a user-friendly interface and a range of functionalities for agent development.
For similar tasks
LLMs-from-scratch-CN
This repository is a Chinese translation of the GitHub project 'LLMs-from-scratch', including detailed markdown notes and related Jupyter code. The translation process aims to maintain the accuracy of the original content while optimizing the language and expression to better suit Chinese learners' reading habits. The repository features detailed Chinese annotations for all Jupyter code, aiding users in practical implementation. It also provides various supplementary materials to expand knowledge. The project focuses on building Large Language Models (LLMs) from scratch, covering fundamental constructions like Transformer architecture, sequence modeling, and delving into deep learning models such as GPT and BERT. Each part of the project includes detailed code implementations and learning resources to help users construct LLMs from scratch and master their core technologies.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.