
WatchAlert
🚀一款轻量级云原生多数据源监控告警引擎, 支持 AI 智能告警分析, 快来用它升级你们的监控系统架构吧!帮忙点个免费的Star 😊~
Stars: 566
WatchAlert is a lightweight monitoring and alerting engine tailored for cloud-native environments, focusing on observability and stability themes. It provides comprehensive monitoring and alerting support, including AI-powered alert analysis for efficient troubleshooting. WatchAlert integrates with various data sources such as Prometheus, VictoriaMetrics, Loki, Elasticsearch, AliCloud SLS, Jaeger, Kubernetes, and different network protocols for monitoring and supports alert notifications via multiple channels like Feishu, DingTalk, WeChat Work, email, and custom hooks. It is optimized for cloud-native environments, easy to use, offers flexible alert rule configurations, and specializes in stability scenarios to help users quickly identify and resolve issues, providing a reliable monitoring and alerting solution to enhance operational efficiency and reduce maintenance costs.
README:

WatchAlert 开源一站式多数据源监控告警引擎





WatchAlert 是一款为云原生环境量身打造的轻量级监控告警引擎,专注于可观测稳定性主题,提供全面的监控与告警支持。
AI + WatchAlert 实现智能化告警分析 高效处理故障告警;
架构图

能力
- AI 智能分析
- 针对
MetricsLogsTraces告警内容做内容分析,高效定位告警根因,并提供排查思路和解决方案;
- 针对
- Metrics 监控
- 集成:Prometheus、VictoriaMetrics
- Logs 监控
- 集成:Loki、ElasticSearch、阿里云日志服务 (AliCloud SLS)
- Traces 监控
- 集成:Jaeger
- Events 监控
- 集成:Kubernetes
- Network 监控
- 集成:HTTP、ICMP、TCP、SSL
- 告警通知
- 飞书、钉钉、企业微信、邮件、自定义Hook
为什么选择 WatchAlert?
- 针对云原生环境优化,轻量易用。
- 灵活的告警规则配置,支持多种数据源。
- 专注于稳定性场景,助力快速发现与解决问题。
- 提供稳定可靠的监控告警解决方案,助力用户提升运维效率,降低维护成本。
- 演示环境:http://8.147.234.89/login (admin/123)
 |
 |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
- 如果你觉得 WatchAlert 还不错,可以通过 Star 来表示你的喜欢
- 在公司或个人项目中使用 WatchAlert,并帮忙推广给伙伴使用
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for WatchAlert
Similar Open Source Tools
WatchAlert
WatchAlert is a lightweight monitoring and alerting engine tailored for cloud-native environments, focusing on observability and stability themes. It provides comprehensive monitoring and alerting support, including AI-powered alert analysis for efficient troubleshooting. WatchAlert integrates with various data sources such as Prometheus, VictoriaMetrics, Loki, Elasticsearch, AliCloud SLS, Jaeger, Kubernetes, and different network protocols for monitoring and supports alert notifications via multiple channels like Feishu, DingTalk, WeChat Work, email, and custom hooks. It is optimized for cloud-native environments, easy to use, offers flexible alert rule configurations, and specializes in stability scenarios to help users quickly identify and resolve issues, providing a reliable monitoring and alerting solution to enhance operational efficiency and reduce maintenance costs.

helicone
Helicone is an open-source observability platform designed for Language Learning Models (LLMs). It logs requests to OpenAI in a user-friendly UI, offers caching, rate limits, and retries, tracks costs and latencies, provides a playground for iterating on prompts and chat conversations, supports collaboration, and will soon have APIs for feedback and evaluation. The platform is deployed on Cloudflare and consists of services like Web (NextJs), Worker (Cloudflare Workers), Jawn (Express), Supabase, and ClickHouse. Users can interact with Helicone locally by setting up the required services and environment variables. The platform encourages contributions and provides resources for learning, documentation, and integrations.
omi
Omi is an open-source AI wearable that provides automatic, high-quality transcriptions of meetings, chats, and voice memos. It revolutionizes how conversations are captured and managed by connecting to mobile devices. The tool offers features for seamless documentation and integration with third-party services.
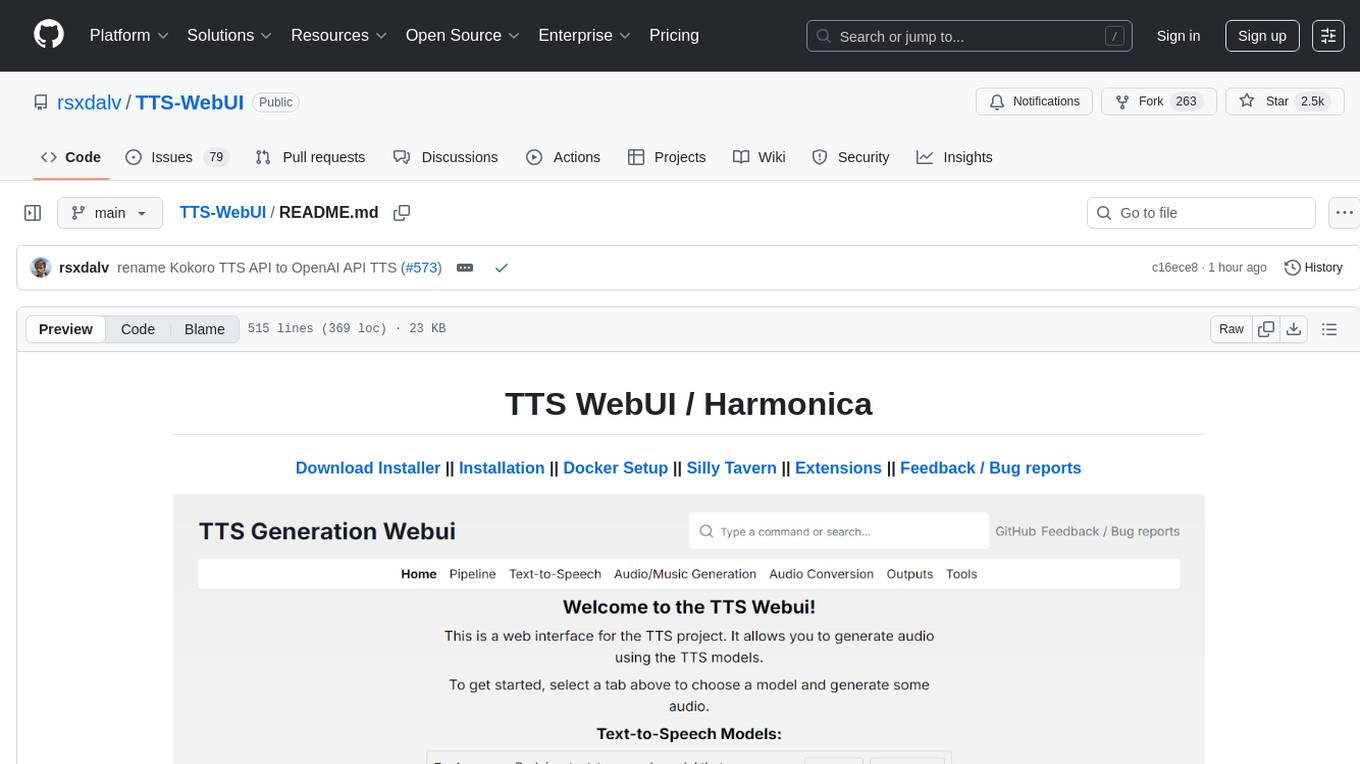
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.
retinify
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.
anx-reader
Anx Reader is a meticulously designed e-book reader tailored for book enthusiasts. It boasts powerful AI functionalities and supports various e-book formats, enhancing the reading experience. With a modern interface, the tool aims to provide a seamless and enjoyable reading journey. It offers rich format support, seamless sync across devices, smart AI assistance, personalized reading experiences, professional reading analytics, a powerful note system, practical tools, and cross-platform support. The tool is continuously evolving with features like UI adaptation for tablets, page-turning animation, TTS voice reading, reading fonts, translation, and more in the pipeline.
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.
AI-Notes
AI-Notes is a repository dedicated to practical applications of artificial intelligence and deep learning. It covers concepts such as data mining, machine learning, natural language processing, and AI. The repository contains Jupyter Notebook examples for hands-on learning and experimentation. It explores the development stages of AI, from narrow artificial intelligence to general artificial intelligence and superintelligence. The content delves into machine learning algorithms, deep learning techniques, and the impact of AI on various industries like autonomous driving and healthcare. The repository aims to provide a comprehensive understanding of AI technologies and their real-world applications.

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.
neural-compressor
Intel® Neural Compressor is an open-source Python library that supports popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search on mainstream frameworks such as TensorFlow, PyTorch, ONNX Runtime, and MXNet. It provides key features, typical examples, and open collaborations, including support for a wide range of Intel hardware, validation of popular LLMs, and collaboration with cloud marketplaces, software platforms, and open AI ecosystems.
YaneuraOu
YaneuraOu is the World's Strongest Shogi engine (AI player), winner of WCSC29 and other prestigious competitions. It is an educational and USI compliant engine that supports various features such as Ponder, MultiPV, and ultra-parallel search. The engine is known for its compatibility with different platforms like Windows, Ubuntu, macOS, and ARM. Additionally, YaneuraOu offers a standard opening book format, on-the-fly opening book support, and various maintenance commands for opening books. With a massive transposition table size of up to 33TB, YaneuraOu is a powerful and versatile tool for Shogi enthusiasts and developers.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
bytedesk
Bytedesk is an AI-powered customer service and team instant messaging tool that offers features like enterprise instant messaging, online customer service, large model AI assistant, and local area network file transfer. It supports multi-level organizational structure, role management, permission management, chat record management, seating workbench, work order system, seat management, data dashboard, manual knowledge base, skill group management, real-time monitoring, announcements, sensitive words, CRM, report function, and integrated customer service workbench services. The tool is designed for team use with easy configuration throughout the company, and it allows file transfer across platforms using WiFi/hotspots without the need for internet connection.
palico-ai
Palico AI is a tech stack designed for rapid iteration of LLM applications. It allows users to preview changes instantly, improve performance through experiments, debug issues with logs and tracing, deploy applications behind a REST API, and manage applications with a UI control panel. Users have complete flexibility in building their applications with Palico, integrating with various tools and libraries. The tool enables users to swap models, prompts, and logic easily using AppConfig. It also facilitates performance improvement through experiments and provides options for deploying applications to cloud providers or using managed hosting. Contributions to the project are welcomed, with easy ways to get involved by picking issues labeled as 'good first issue'.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
For similar tasks
WatchAlert
WatchAlert is a lightweight monitoring and alerting engine tailored for cloud-native environments, focusing on observability and stability themes. It provides comprehensive monitoring and alerting support, including AI-powered alert analysis for efficient troubleshooting. WatchAlert integrates with various data sources such as Prometheus, VictoriaMetrics, Loki, Elasticsearch, AliCloud SLS, Jaeger, Kubernetes, and different network protocols for monitoring and supports alert notifications via multiple channels like Feishu, DingTalk, WeChat Work, email, and custom hooks. It is optimized for cloud-native environments, easy to use, offers flexible alert rule configurations, and specializes in stability scenarios to help users quickly identify and resolve issues, providing a reliable monitoring and alerting solution to enhance operational efficiency and reduce maintenance costs.
shell_gpt
ShellGPT is a command-line productivity tool powered by AI large language models (LLMs). This command-line tool offers streamlined generation of shell commands, code snippets, documentation, eliminating the need for external resources (like Google search). Supports Linux, macOS, Windows and compatible with all major Shells like PowerShell, CMD, Bash, Zsh, etc.
holoinsight
HoloInsight is a cloud-native observability platform that provides low-cost and high-performance monitoring services for cloud-native applications. It offers deep insights through real-time log analysis and AI integration. The platform is designed to help users gain a comprehensive understanding of their applications' performance and behavior in the cloud environment. HoloInsight is easy to deploy using Docker and Kubernetes, making it a versatile tool for monitoring and optimizing cloud-native applications. With a focus on scalability and efficiency, HoloInsight is suitable for organizations looking to enhance their observability and monitoring capabilities in the cloud.
gonzo
Gonzo is a powerful, real-time log analysis terminal UI tool inspired by k9s. It allows users to analyze log streams with beautiful charts, AI-powered insights, and advanced filtering directly from the terminal. The tool provides features like live streaming log processing, OTLP support, interactive dashboard with real-time charts, advanced filtering options including regex support, and AI-powered insights such as pattern detection, anomaly analysis, and root cause suggestions. Users can also configure AI models from providers like OpenAI, LM Studio, and Ollama for intelligent log analysis. Gonzo is built with Bubble Tea, Lipgloss, Cobra, Viper, and OpenTelemetry, following a clean architecture with separate modules for TUI, log analysis, frequency tracking, OTLP handling, and AI integration.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.
fastapi-langgraph-agent-production-ready-template
A production-ready FastAPI template for building AI agent applications with LangGraph integration. This template provides a robust foundation for building scalable, secure, and maintainable AI agent services. It includes features like FastAPI for high-performance async API endpoints, LangGraph integration, structured logging, rate limiting, PostgreSQL for data persistence, Docker support, security measures like JWT-based authentication and input sanitization, developer-friendly features like environment-specific configuration and type hints, a model evaluation framework with automated metric-based evaluation and detailed JSON reports, and a configuration system with environment-specific settings.

deepflow
DeepFlow is an open-source project that provides deep observability for complex cloud-native and AI applications. It offers Zero Code data collection with eBPF for metrics, distributed tracing, request logs, and function profiling. DeepFlow is integrated with SmartEncoding to achieve Full Stack correlation and efficient access to all observability data. With DeepFlow, cloud-native and AI applications automatically gain deep observability, removing the burden of developers continually instrumenting code and providing monitoring and diagnostic capabilities covering everything from code to infrastructure for DevOps/SRE teams.

hub
Hub is an open-source, high-performance LLM gateway written in Rust. It serves as a smart proxy for LLM applications, centralizing control and tracing of all LLM calls and traces. Built for efficiency, it provides a single API to connect to any LLM provider. The tool is designed to be fast, efficient, and completely open-source under the Apache 2.0 license.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.