
retinify
Real-Time AI Stereo Vision Library
Stars: 260
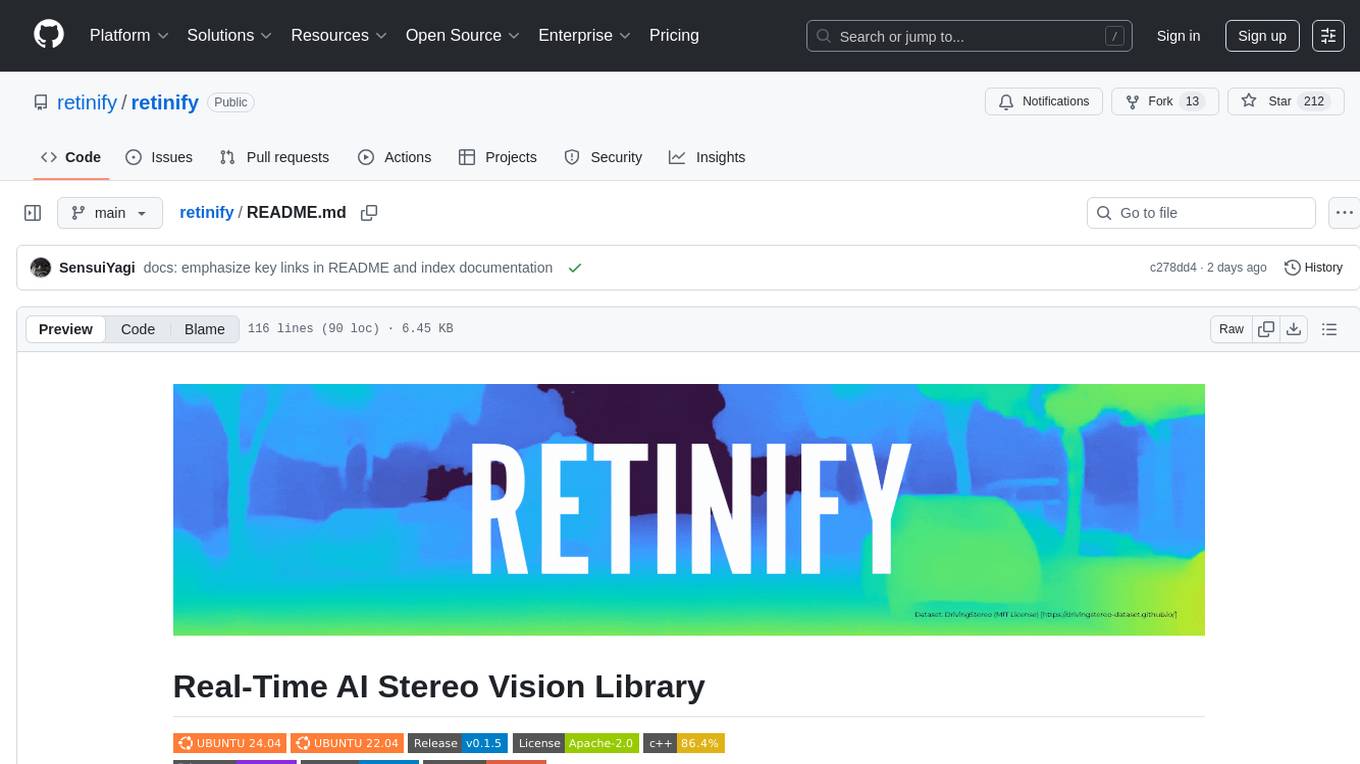
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.
README:
![]()
🚀 Real-Time AI Stereo Vision Library
Retinify is an advanced AI-powered stereo vision library designed for robotics. It enables real-time, high-precision 3D perception by leveraging GPU and NPU acceleration.
 |
 |
- 🔥 High Precision: Delivers real-time, accurate 3D mapping and object recognition from stereo image input.
- ⚡ Fast Pipeline: Distortion correction, rectification, stereo matching, and 3D reprojection are fully accelerated on the GPU, enabling real-time performance.
- 🎥 Camera-Agnostic: Accepts stereo images from any camera setup, giving you the flexibility to use your own hardware.
- 💰 Cost Efficiency: Runs using just cameras, enabling depth perception with minimal hardware cost.
- 🪶 Minimal Dependencies: The pipeline depends only on CUDA Toolkit, cuDNN, and TensorRT, providing a lean and production-grade foundation.
Rectified Stereo Images (🐍 Python)
import retinify
import numpy as np
from PIL import Image
# LOAD RECTIFIED STEREO INPUT IMAGES
left = np.asarray(Image.open("path/to/left.png").convert("RGB"))
right = np.asarray(Image.open("path/to/right.png").convert("RGB"))
# CREATE STEREO MATCHING PIPELINE
pipe = retinify.Pipeline()
# INITIALIZE THE PIPELINE
pipe.initialize(image_width=left.shape[1],
image_height=left.shape[0])
# EXECUTE STEREO MATCHING
pipe.execute(left, right)
# RETRIEVE DISPARITY
disparity = pipe.retrieve_disparity()Non-Rectified Stereo Images (🐍 Python)
Using the calibration parameters, the pipeline performs undistortion, rectification, and 3D reprojection.
import retinify
import numpy as np
from PIL import Image
# LOAD NON-RECTIFIED STEREO INPUT IMAGES
left = np.asarray(Image.open("path/to/left.png").convert("RGB"))
right = np.asarray(Image.open("path/to/right.png").convert("RGB"))
# LOAD CALIBRATION PARAMETERS
calib_params = retinify.load_calibration_parameters("path/to/calib.json")
# CREATE STEREO MATCHING PIPELINE
pipe = retinify.Pipeline()
# INITIALIZE THE PIPELINE WITH CALIBRATION PARAMETERS
pipe.initialize(image_width=left.shape[1],
image_height=left.shape[0],
pixel_format=retinify.PixelFormat.RGB8,
depth_mode=retinify.DepthMode.ACCURATE,
calibration_parameters=calib_params)
# EXECUTE STEREO MATCHING
pipe.execute(left, right)
# RETRIEVE DISPARITY
disparity = pipe.retrieve_disparity()
# RETRIEVE DEPTH
depth = pipe.retrieve_depth()
# RETRIEVE POINT CLOUD
point_cloud = pipe.retrieve_point_cloud()Rectified Stereo Images (🧬 C++)
#include <retinify/retinify.hpp>
#include <opencv2/opencv.hpp>
// LOAD RECTIFIED STEREO INPUT IMAGES
cv::Mat leftImage = cv::imread("path/to/left.png");
cv::Mat rightImage = cv::imread("path/to/right.png");
// PREPARE OUTPUT BUFFERS
cv::Mat disparity = cv::Mat::zeros(leftImage.size(), CV_32FC1);
// CREATE THE STEREO MATCHING PIPELINE
retinify::Pipeline pipeline;
// INITIALIZE THE PIPELINE
pipeline.Initialize(leftImage.cols, leftImage.rows);
// EXECUTE STEREO MATCHING
pipeline.Execute(leftImage.ptr<uint8_t>(),
leftImage.step[0],
rightImage.ptr<uint8_t>(),
rightImage.step[0]);
// RETRIEVE DISPARITY
pipeline.RetrieveDisparity(disparity.ptr<float>(), disparity.step[0]);Non-Rectified Stereo Images (🧬 C++)
Using the calibration parameters, the pipeline performs undistortion, rectification, and 3D reprojection.
#include <retinify/retinify.hpp>
#include <opencv2/opencv.hpp>
// LOAD NON-RECTIFIED STEREO INPUT IMAGES
cv::Mat leftImage = cv::imread("path/to/left.png");
cv::Mat rightImage = cv::imread("path/to/right.png");
// PREPARE OUTPUT BUFFERS
cv::Mat disparity = cv::Mat::zeros(leftImage.size(), CV_32FC1);
cv::Mat depth = cv::Mat::zeros(leftImage.size(), CV_32FC1);
cv::Mat pointCloud = cv::Mat::zeros(leftImage.size(), CV_32FC3);
// LOAD CALIBRATION PARAMETERS
retinify::CalibrationParameters calibParams;
retinify::LoadCalibrationParameters("path/to/calib.json", calibParams);
// CREATE THE STEREO MATCHING PIPELINE
retinify::Pipeline pipeline;
// INITIALIZE THE PIPELINE WITH CALIBRATION PARAMETERS
pipeline.Initialize(leftImage.cols,
leftImage.rows,
retinify::PixelFormat::RGB8,
retinify::DepthMode::ACCURATE,
calibParams);
// EXECUTE STEREO MATCHING
pipeline.Execute(leftImage.ptr<uint8_t>(),
leftImage.step[0],
rightImage.ptr<uint8_t>(),
rightImage.step[0]);
// RETRIEVE DISPARITY
pipeline.RetrieveDisparity(disparity.ptr<float>(), disparity.step[0]);
// RETRIEVE DEPTH
pipeline.RetrieveDepth(depth.ptr<float>(), depth.step[0]);
// RETRIEVE POINT CLOUD
pipeline.RetrievePointCloud(pointCloud.ptr<float>(), pointCloud.step[0]);-
📥 Installation
Step-by-step installation instructions -
🎬 Demos
Hands-on examples using OpenCV -
🔨 Tutorials
Guided explanations of retinify concepts -
🎯 Calibration
Calibration parameters specification -
🐍 Python Docs
Python API documentation -
🧬 C++ Docs
C++ API documentation -
🤖 ROS2 Docs
ROS2 integration reference
| 🎯 Target | ⚙️ Env | 📦 Status |
|---|---|---|
 |
||
 |
||
 |
Latency includes the time for image upload, inference, and disparity download, reported as the median over 10,000 iterations (measured with retinify::Pipeline).
These measurements were taken using each setting of retinify::DepthMode.
[!NOTE] Results may vary depending on the execution environment.
| DEVICE \ MODE | FAST | BALANCED | ACCURATE |
|---|---|---|---|
| NVIDIA RTX 3060 | 3.925ms / 254.8FPS | 4.691ms / 213.2FPS | 10.790ms / 92.7FPS |
| NVIDIA Jetson Orin Nano | 17.462ms / 57.3FPS | 19.751ms / 50.6FPS | 46.104ms / 21.7FPS |
For a list of third-party dependencies, please refer to NOTICE.md.
For all inquiries, including support, collaboration, please contact:
[email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for retinify
Similar Open Source Tools
retinify
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.

edge-veda
Edge-Veda is a managed on-device AI runtime for Flutter, offering text, vision, speech-to-text, text-to-speech, image generation, and RAG capabilities on real phones under real constraints. It aims to make on-device AI predictable, observable, and sustainable by providing runtime policies, structured observability, and private by default operation. The tool is designed for IoT builders, knowledge workers, and personal AI builders developing privacy-sensitive, offline-first, or long-running on-device AI applications.

pytorch-lightning
PyTorch Lightning is a framework for training and deploying AI models. It provides a high-level API that abstracts away the low-level details of PyTorch, making it easier to write and maintain complex models. Lightning also includes a number of features that make it easy to train and deploy models on multiple GPUs or TPUs, and to track and visualize training progress. PyTorch Lightning is used by a wide range of organizations, including Google, Facebook, and Microsoft. It is also used by researchers at top universities around the world. Here are some of the benefits of using PyTorch Lightning: * **Increased productivity:** Lightning's high-level API makes it easy to write and maintain complex models. This can save you time and effort, and allow you to focus on the research or business problem you're trying to solve. * **Improved performance:** Lightning's optimized training loops and data loading pipelines can help you train models faster and with better performance. * **Easier deployment:** Lightning makes it easy to deploy models to a variety of platforms, including the cloud, on-premises servers, and mobile devices. * **Better reproducibility:** Lightning's logging and visualization tools make it easy to track and reproduce training results.

GraphGen
GraphGen is a framework for synthetic data generation guided by knowledge graphs. It enhances supervised fine-tuning for large language models (LLMs) by generating synthetic data based on a fine-grained knowledge graph. The tool identifies knowledge gaps in LLMs, prioritizes generating QA pairs targeting high-value knowledge, incorporates multi-hop neighborhood sampling, and employs style-controlled generation to diversify QA data. Users can use LLaMA-Factory and xtuner for fine-tuning LLMs after data generation.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
pgmpy
pgmpy is a Python library for causal and probabilistic modeling using graphical models. It provides a uniform API for building, learning, and analyzing models, such as Bayesian Networks, Dynamic Bayesian Networks, Directed Acyclic Graphs (DAGs), and Structural Equation Models (SEMs). By integrating tools from both probabilistic inference and causal inference, pgmpy enables users to seamlessly transition between predictive and causal analyses. Key features include causal discovery/structure learning, causal validation, parameter learning, probabilistic inference, causal inference, and simulations. The library offers resources such as example notebooks, tutorial notebooks, blog posts, documentation, bug reports, and feature requests.

mindnlp
MindNLP is an open-source NLP library based on MindSpore. It provides a platform for solving natural language processing tasks, containing many common approaches in NLP. It can help researchers and developers to construct and train models more conveniently and rapidly. Key features of MindNLP include: * Comprehensive data processing: Several classical NLP datasets are packaged into a friendly module for easy use, such as Multi30k, SQuAD, CoNLL, etc. * Friendly NLP model toolset: MindNLP provides various configurable components. It is friendly to customize models using MindNLP. * Easy-to-use engine: MindNLP simplified complicated training process in MindSpore. It supports Trainer and Evaluator interfaces to train and evaluate models easily. MindNLP supports a wide range of NLP tasks, including: * Language modeling * Machine translation * Question answering * Sentiment analysis * Sequence labeling * Summarization MindNLP also supports industry-leading Large Language Models (LLMs), including Llama, GLM, RWKV, etc. For support related to large language models, including pre-training, fine-tuning, and inference demo examples, you can find them in the "llm" directory. To install MindNLP, you can either install it from Pypi, download the daily build wheel, or install it from source. The installation instructions are provided in the documentation. MindNLP is released under the Apache 2.0 license. If you find this project useful in your research, please consider citing the following paper: @misc{mindnlp2022, title={{MindNLP}: a MindSpore NLP library}, author={MindNLP Contributors}, howpublished = {\url{https://github.com/mindlab-ai/mindnlp}}, year={2022} }
Edit-Banana
Edit Banana is a universal content re-editor that allows users to transform fixed content into fully manipulatable assets. Powered by SAM 3 and multimodal large models, it enables high-fidelity reconstruction while preserving original diagram details and logical relationships. The platform offers advanced segmentation, fixed multi-round VLM scanning, high-quality OCR, user system with credits, multi-user concurrency, and a web interface. Users can upload images or PDFs to get editable DrawIO (XML) or PPTX files in seconds. The project structure includes components for segmentation, text extraction, frontend, models, and scripts, with detailed installation and setup instructions provided. The tool is open-source under the Apache License 2.0, allowing commercial use and secondary development.
intlayer
Intlayer is an open-source, flexible i18n toolkit with AI-powered translation and CMS capabilities. It is a modern i18n solution for web and mobile apps, framework-agnostic, and includes features like per-locale content files, TypeScript autocompletion, tree-shakable dictionaries, and CI/CD integration. With Intlayer, internationalization becomes faster, cleaner, and smarter, offering benefits such as cross-framework support, JavaScript-powered content management, simplified setup, enhanced routing, AI-powered translation, and more.

qianfan-starter
WenXin-Starter is a spring-boot-starter for Baidu's 'WenXin Workshop' large model, facilitating quick integration of Baidu's AI capabilities. It provides complete integration with WenXin Workshop's official API documentation, supports WenShengTu, built-in conversation memory, and supports conversation streaming. It also supports QPS control for individual models and queuing mechanism, with upcoming plugin support.
ailoy
Ailoy is a lightweight library for building AI applications such as agent systems or RAG pipelines with ease. It enables AI features effortlessly, supporting AI models locally or via cloud APIs, multi-turn conversation, system message customization, reasoning-based workflows, tool calling capabilities, and built-in vector store support. It also supports running native-equivalent functionality in web browsers using WASM. The library is in early development stages and provides examples in the `examples` directory for inspiration on building applications with Agents.
netsaur
Netsaur is a powerful machine learning library for Deno, offering a lightweight and easy-to-use neural network solution. It is blazingly fast and efficient, providing a simple API for creating and training neural networks. Netsaur can run on both CPU and GPU, making it suitable for serverless environments. With Netsaur, users can quickly build and deploy machine learning models for various applications with minimal dependencies. This library is perfect for both beginners and experienced machine learning practitioners.
sdk
The Kubeflow SDK is a set of unified Pythonic APIs that simplify running AI workloads at any scale without needing to learn Kubernetes. It offers consistent APIs across the Kubeflow ecosystem, enabling users to focus on building AI applications rather than managing complex infrastructure. The SDK provides a unified experience, simplifies AI workloads, is built for scale, allows rapid iteration, and supports local development without a Kubernetes cluster.
Liger-Kernel
Liger Kernel is a collection of Triton kernels designed for LLM training, increasing training throughput by 20% and reducing memory usage by 60%. It includes Hugging Face Compatible modules like RMSNorm, RoPE, SwiGLU, CrossEntropy, and FusedLinearCrossEntropy. The tool works with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed, aiming to enhance model efficiency and performance for researchers, ML practitioners, and curious novices.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.
rwkv-qualcomm
This repository provides support for inference RWKV models on Qualcomm HTP (Hexagon Tensor Processor) using QNN SDK. It supports RWKV v5, v6, and experimentally v7 models, inference using Qualcomm CPU, GPU, or HTP as the backend, whole-model float16 inference, activation INT16 and weights INT8 quantized inference, and activation INT16 and weights INT4/INT8 mixed quantized inference. Users can convert model weights to QNN model library files, generate HTP context cache, and run inference on Qualcomm Snapdragon SM8650 with HTP v75. The project requires QNN SDK, AIMET toolkit, and specific hardware for verification.
For similar tasks

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
react-native-vision-camera
VisionCamera is a powerful, high-performance Camera library for React Native. It features Photo and Video capture, QR/Barcode scanner, Customizable devices and multi-cameras ("fish-eye" zoom), Customizable resolutions and aspect-ratios (4k/8k images), Customizable FPS (30..240 FPS), Frame Processors (JS worklets to run facial recognition, AI object detection, realtime video chats, ...), Smooth zooming (Reanimated), Fast pause and resume, HDR & Night modes, Custom C++/GPU accelerated video pipeline (OpenGL).

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
artificial-intelligence
This repository contains a collection of AI projects implemented in Python, primarily in Jupyter notebooks. The projects cover various aspects of artificial intelligence, including machine learning, deep learning, natural language processing, computer vision, and more. Each project is designed to showcase different AI techniques and algorithms, providing a hands-on learning experience for users interested in exploring the field of artificial intelligence.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.
For similar jobs

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.