
gonzo
Gonzo! The Go based TUI log analysis tool
Stars: 1643
Gonzo is a powerful, real-time log analysis terminal UI tool inspired by k9s. It allows users to analyze log streams with beautiful charts, AI-powered insights, and advanced filtering directly from the terminal. The tool provides features like live streaming log processing, OTLP support, interactive dashboard with real-time charts, advanced filtering options including regex support, and AI-powered insights such as pattern detection, anomaly analysis, and root cause suggestions. Users can also configure AI models from providers like OpenAI, LM Studio, and Ollama for intelligent log analysis. Gonzo is built with Bubble Tea, Lipgloss, Cobra, Viper, and OpenTelemetry, following a clean architecture with separate modules for TUI, log analysis, frequency tracking, OTLP handling, and AI integration.
README:

A powerful, real-time log analysis terminal UI inspired by k9s. Analyze log streams with beautiful charts, AI-powered insights, and advanced filtering - all from your terminal.




- Live streaming - Process logs as they arrive from stdin, files, or network
- OTLP native - First-class support for OpenTelemetry log format
- OTLP receiver - Built-in gRPC server to receive logs via OpenTelemetry protocol
- Format detection - Automatically detects JSON, logfmt, and plain text
- Custom formats - Define your own log formats with YAML configuration
- Severity tracking - Color-coded severity levels with distribution charts
- k9s-inspired layout - Familiar 2x2 grid interface
- Real-time charts - Word frequency, attributes, severity distribution, and time series
- Keyboard + mouse navigation - Vim-style shortcuts plus click-to-navigate and scroll wheel support
- Smart log viewer - Auto-scroll with intelligent pause/resume behavior
-
Fullscreen log viewer - Press
fto open a dedicated fullscreen modal for log browsing with all navigation features - Global pause control - Spacebar pauses entire dashboard while buffering logs
- Modal details - Deep dive into individual log entries with expandable views
- Log Counts analysis - Detailed modal with heatmap visualization, pattern analysis by severity, and service distribution
- AI analysis - Get intelligent insights about log patterns and anomalies with configurable models
- Regex support - Filter logs with regular expressions
- Attribute search - Find logs by specific attribute values
- Severity filtering - Focus on errors, warnings, or specific log levels
- Interactive selection - Click or keyboard navigate to explore logs
- Built-in skins - 11+ beautiful themes including Dracula, Nord, Monokai, GitHub Light, and more
- Light and dark modes - Themes optimized for different lighting conditions
- Custom skins - Create your own color schemes with YAML configuration
- Semantic colors - Intuitive color mapping for different UI components
- Professional themes - ControlTheory original themes included
- Pattern detection - Automatically identify recurring issues
- Anomaly analysis - Spot unusual patterns in your logs
- Root cause suggestions - Get AI-powered debugging assistance
- Configurable models - Choose from GPT-4, GPT-3.5, or any custom model
- Multiple providers - Works with OpenAI, LM Studio, Ollama, or any OpenAI-compatible API
- Local AI support - Run completely offline with local models
go install github.com/control-theory/gonzo/cmd/gonzo@latestbrew install gonzoDownload the latest release for your platform from the releases page.
nix run github:control-theory/gonzogit clone https://github.com/control-theory/gonzo.git
cd gonzo
make build# Read logs directly from files
gonzo -f application.log
# Read from multiple files
gonzo -f application.log -f error.log -f debug.log
# Use glob patterns to read multiple files
gonzo -f "/var/log/*.log"
gonzo -f "/var/log/app/*.log" -f "/var/log/nginx/*.log"
# Follow log files in real-time (like tail -f)
gonzo -f /var/log/app.log --follow
gonzo -f "/var/log/*.log" --follow
# Analyze logs from stdin (traditional way)
cat application.log | gonzo
# Stream logs from kubectl
kubectl logs -f deployment/my-app | gonzo
# Follow system logs
tail -f /var/log/syslog | gonzo
# Analyze Docker container logs
docker logs -f my-container 2>&1 | gonzo
# With AI analysis (requires API key)
export OPENAI_API_KEY=sk-your-key-here
gonzo -f application.log --ai-model="gpt-4"Gonzo supports custom log formats through YAML configuration files. This allows you to parse any structured log format without modifying the source code.
Some example custom formats are included in the repo, simply download, copy, or modify as you like! In order for the commands below to work, you must first download them and put them in the Gonzo config directory.
# Use a built-in custom format
gonzo --format=loki-stream -f loki_logs.json
# List available custom formats
ls ~/.config/gonzo/formats/
# Use your own custom format
gonzo --format=my-custom-format -f custom_logs.txtCustom formats support:
- Flexible field mapping - Map any JSON/text fields to timestamp, severity, body, and attributes
- Batch processing - Automatically expand batch formats (like Loki) into individual log entries
- Auto-mapping - Automatically extract all unmapped fields as attributes
- Nested field extraction - Extract fields from deeply nested JSON structures
- Pattern-based parsing - Use regex patterns for unstructured text logs
For detailed information on creating custom formats, see the Custom Formats Guide.
Gonzo can receive logs directly via OpenTelemetry Protocol (OTLP) over both gRPC and HTTP:
# Start Gonzo as an OTLP receiver (both gRPC on port 4317 and HTTP on port 4318)
gonzo --otlp-enabled
# Use custom ports
gonzo --otlp-enabled --otlp-grpc-port=5317 --otlp-http-port=5318
# gRPC endpoint: localhost:4317
# HTTP endpoint: http://localhost:4318/v1/logsUsing gRPC:
exporters:
otlp/gonzo_grpc:
endpoint: localhost:4317
tls:
insecure: true
service:
pipelines:
logs:
receivers: [your_receivers]
processors: [your_processors]
exporters: [otlp/gonzo_grpc]Using HTTP:
exporters:
otlphttp/gonzo_http:
endpoint: http://localhost:4318/v1/logs
service:
pipelines:
logs:
receivers: [your_receivers]
processors: [your_processors]
exporters: [otlphttp/gonzo_http]Using gRPC:
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
exporter = OTLPLogExporter(
endpoint="localhost:4317",
insecure=True
)Using HTTP:
from opentelemetry.exporter.otlp.proto.http._log_exporter import OTLPLogExporter
exporter = OTLPLogExporter(
endpoint="http://localhost:4318/v1/logs",
)See examples/send_otlp_logs.py for a complete example.
# Auto-select best available model (recommended) - file input
export OPENAI_API_KEY=sk-your-key-here
gonzo -f logs.json
# Or specify a particular model - file input
export OPENAI_API_KEY=sk-your-key-here
gonzo -f logs.json --ai-model="gpt-4"
# Follow logs with AI analysis
export OPENAI_API_KEY=sk-your-key-here
gonzo -f "/var/log/app.log" --follow --ai-model="gpt-4"
# Using local LM Studio (auto-selects first available)
export OPENAI_API_KEY="local-key"
export OPENAI_API_BASE="http://localhost:1234/v1"
gonzo -f logs.json
# Using Ollama (auto-selects best model like gpt-oss:20b)
export OPENAI_API_KEY="ollama"
export OPENAI_API_BASE="http://localhost:11434"
gonzo -f logs.json --follow
# Traditional stdin approach still works
export OPENAI_API_KEY=sk-your-key-here
cat logs.json | gonzo --ai-model="gpt-4"| Key/Mouse | Action |
|---|---|
Tab / Shift+Tab
|
Navigate between panels |
Mouse Click |
Click on any section to switch to it |
↑/↓ or k/j
|
Move selection up/down |
Mouse Wheel |
Scroll up/down to navigate selections |
←/→ or h/l
|
Horizontal navigation |
Enter |
View log details or open analysis modal (Counts section) |
ESC |
Close modal/cancel |
| Key | Action |
|---|---|
Space |
Pause/unpause entire dashboard |
/ |
Enter filter mode (regex supported) |
s |
Search and highlight text in logs |
f |
Open fullscreen log viewer modal |
c |
Toggle Host/Service columns in log view |
r |
Reset all data (manual reset) |
u / U
|
Cycle update intervals (forward/backward) |
i |
AI analysis (in detail view) |
m |
Switch AI model (shows available models) |
? / h
|
Show help |
q / Ctrl+C
|
Quit |
| Key | Action |
|---|---|
Home |
Jump to top of log buffer (stops auto-scroll) |
End |
Jump to latest logs (resumes auto-scroll) |
PgUp / PgDn
|
Navigate by pages (10 entries at a time) |
↑/↓ or k/j
|
Navigate entries with smart auto-scroll |
| Key | Action |
|---|---|
c |
Start chat with AI about current log |
Tab |
Switch between log details and chat pane |
m |
Switch AI model (works in modal too) |
Press Enter on the Counts section to open a comprehensive analysis modal featuring:
- Time-series heatmap showing severity levels vs. time (1-minute resolution)
- 60-minute rolling window with automatic scaling per severity level
- Color-coded intensity using ASCII characters (░▒▓█) with gradient effects
- Precise alignment with time headers showing minutes ago (60, 50, 40, ..., 10, 0)
- Receive time architecture - visualization based on when logs were received for reliable display
- Top 3 patterns per severity using drain3 pattern extraction algorithm
- Severity-specific tracking with dedicated drain3 instances for each level
- Real-time pattern detection as logs arrive and are processed
- Accurate pattern counts maintained separately for each severity level
- Top 3 services per severity showing which services generate each log level
- Service name extraction from common attributes (service.name, service, app, etc.)
- Real-time updates as new logs are processed and analyzed
- Fallback to host information when service names are not available
- Scrollable content using mouse wheel or arrow keys
- ESC to close and return to main dashboard
- Full-width display maximizing screen real estate for data visualization
- Real-time updates - data refreshes automatically as new logs arrive
The modal uses the same receive time architecture as the main dashboard, ensuring consistent and reliable visualization regardless of log timestamp accuracy or clock skew issues.
gonzo [flags]
gonzo [command]
Commands:
version Print version information
help Help about any command
completion Generate shell autocompletion
Flags:
-f, --file stringArray Files or file globs to read logs from (can specify multiple)
--follow Follow log files like 'tail -f' (watch for new lines in real-time)
--format string Log format to use (auto-detect if not specified). Can be: otlp, json, text, or a custom format name
-u, --update-interval duration Dashboard update interval (default: 1s)
-b, --log-buffer int Maximum log entries to keep (default: 1000)
-m, --memory-size int Maximum frequency entries (default: 10000)
--ai-model string AI model for analysis (auto-selects best available if not specified)
-s, --skin string Color scheme/skin to use (default, or name of a skin file)
--stop-words strings Additional stop words to filter out from analysis (adds to built-in list)
-t, --test-mode Run without TTY for testing
-v, --version Print version information
--config string Config file (default: $HOME/.config/gonzo/config.yml)
-h, --help Show help messageCreate ~/.config/gonzo/config.yml for persistent settings:
# File input configuration
files:
- "/var/log/app.log"
- "/var/log/error.log"
- "/var/log/*.log" # Glob patterns supported
follow: true # Enable follow mode (like tail -f)
# Update frequency for dashboard refresh
update-interval: 2s
# Buffer sizes
log-buffer: 2000
memory-size: 15000
# UI customization
skin: dracula # Choose from: default, dracula, nord, monokai, github-light, etc.
# Additional stop words to filter from analysis
stop-words:
- "log"
- "message"
- "debug"
# Development/testing
test-mode: false
# AI configuration
ai-model: "gpt-4"See examples/config.yml for a complete configuration example with detailed comments.
Gonzo supports multiple AI providers for intelligent log analysis. Configure using command line flags and environment variables. You can switch between available models at runtime using the m key.
# Set your API key
export OPENAI_API_KEY="sk-your-actual-key-here"
# Auto-select best available model (recommended)
cat logs.json | gonzo
# Or specify a particular model
cat logs.json | gonzo --ai-model="gpt-4"# 1. Start LM Studio server with a model loaded
# 2. Set environment variables (IMPORTANT: include /v1 in URL)
export OPENAI_API_KEY="local-key"
export OPENAI_API_BASE="http://localhost:1234/v1"
# Auto-select first available model (recommended)
cat logs.json | gonzo
# Or specify the exact model name from LM Studio
cat logs.json | gonzo --ai-model="openai/gpt-oss-120b"# 1. Start Ollama: ollama serve
# 2. Pull a model: ollama pull gpt-oss:20b
# 3. Set environment variables (note: no /v1 suffix needed)
export OPENAI_API_KEY="ollama"
export OPENAI_API_BASE="http://localhost:11434"
# Auto-select best model (prefers gpt-oss, llama3, mistral, etc.)
cat logs.json | gonzo
# Or specify a particular model
cat logs.json | gonzo --ai-model="gpt-oss:20b"
cat logs.json | gonzo --ai-model="llama3"# For any OpenAI-compatible API endpoint
export OPENAI_API_KEY="your-api-key"
export OPENAI_API_BASE="https://api.your-provider.com/v1"
cat logs.json | gonzo --ai-model="your-model-name"Once Gonzo is running, you can switch between available AI models without restarting:
-
Press
manywhere in the interface to open the model selection modal - Navigate with arrow keys, page up/down, or mouse wheel
- Select a model with Enter
- Cancel with Escape
The model selection modal shows:
- All available models from your configured AI provider
- Current active model (highlighted in green)
- Dynamic sizing based on terminal height
- Scroll indicators when there are many models
Note: Model switching requires the AI service to be properly configured and running. The modal will only appear if models are available from your AI provider.
When you don't specify the --ai-model flag, Gonzo automatically selects the best available model:
Selection Priority:
-
OpenAI: Prefers
gpt-4→gpt-3.5-turbo→ first available -
Ollama: Prefers
gpt-oss:20b→llama3→mistral→codellama→ first available - LM Studio: Uses first available model from the server
- Other providers: Uses first available model
Benefits:
- ✅ No need to know model names beforehand
- ✅ Works immediately with any AI provider
- ✅ Intelligent defaults for better performance
- ✅ Still allows manual model selection with
mkey
Example: Instead of gonzo --ai-model="llama3", simply run gonzo and it will auto-select llama3 if available.
LM Studio Issues:
- ✅ Ensure server is running and model is loaded
- ✅ Use full model name:
--ai-model="openai/model-name" - ✅ Include
/v1in base URL:http://localhost:1234/v1 - ✅ Check available models:
curl http://localhost:1234/v1/models
Ollama Issues:
- ✅ Start server:
ollama serve - ✅ Verify model:
ollama list - ✅ Test API:
curl http://localhost:11434/api/tags - ✅ Use correct URL:
http://localhost:11434(no/v1suffix) - ✅ Model names include tags:
gpt-oss:20b,llama3:8b
OpenAI Issues:
- ✅ Verify API key is valid and has credits
- ✅ Check model availability (gpt-4 requires API access)
| Variable | Description |
|---|---|
OPENAI_API_KEY |
API key for AI analysis (required for AI features) |
OPENAI_API_BASE |
Custom API endpoint (default: https://api.openai.com/v1) |
GONZO_FILES |
Comma-separated list of files/globs to read (equivalent to -f flags) |
GONZO_FOLLOW |
Enable follow mode (true/false) |
GONZO_UPDATE_INTERVAL |
Override update interval |
GONZO_LOG_BUFFER |
Override log buffer size |
GONZO_MEMORY_SIZE |
Override memory size |
GONZO_AI_MODEL |
Override default AI model |
GONZO_TEST_MODE |
Enable test mode |
NO_COLOR |
Disable colored output |
Enable shell completion for better CLI experience:
# Bash
source <(gonzo completion bash)
# Zsh
source <(gonzo completion zsh)
# Fish
gonzo completion fish | source
# PowerShell
gonzo completion powershell | Out-String | Invoke-ExpressionFor permanent setup, save the completion script to your shell's completion directory.
By leveraging K9s plugin system Gonzo integrates seamlessly with K9s for real-time Kubernetes log analysis.
Add this plugin to your $XDG_CONFIG_HOME/k9s/plugins.yaml file:
plugins:
gonzo:
shortCut: Ctrl-L
description: "Gonzo log analysis"
scopes:
- po
command: sh
background: false
args:
- -c
- "kubectl logs -f $NAME -n $NAMESPACE --context $CONTEXT | gonzo"
⚠️ NOTE: onmacOSalthough it is not required, definingXDG_CONFIG_HOME=~/.configis recommended in order to maintain consistency with Linux configuration practices.
- Launch k9s and navigate to pods
- Select a pod and press
ctrl-l - Gonzo opens with live log streaming and analysis
Gonzo is built with:
- Bubble Tea - Terminal UI framework
- Lipgloss - Styling and layout
- Bubbles - TUI components
- Cobra - CLI framework
- Viper - Configuration management
- OpenTelemetry - Native OTLP support
- Large amounts of ☕️
The architecture follows a clean separation:
cmd/gonzo/ # Main application entry
internal/
├── tui/ # Terminal UI implementation
├── analyzer/ # Log analysis engine
├── memory/ # Frequency tracking
├── otlplog/ # OTLP format handling
└── ai/ # AI integration
- Go 1.21 or higher
- Make (optional, for convenience)
# Quick build
make build
# Run tests
make test
# Build for all platforms
make cross-build
# Development mode (format, vet, test, build)
make dev# Run unit tests
make test
# Run with race detection
make test-race
# Integration tests
make test-integration
# Test with sample data
make demoGonzo supports beautiful, customizable color schemes to match your terminal environment and personal preferences.
Be sure you download and place in the Gonzo config directory so Gonzo can find them.
# Use a dark theme
gonzo --skin=dracula
gonzo --skin=nord
gonzo --skin=monokai
# Use a light theme
gonzo --skin=github-light
gonzo --skin=solarized-light
gonzo --skin=vs-code-light
# Use Control Theory branded themes
gonzo --skin=controltheory-light # Light theme
gonzo --skin=controltheory-dark # Dark themeDark Themes 🌙: default, controltheory-dark, dracula, gruvbox, monokai, nord, solarized-dark
Light Themes ☀️: controltheory-light, github-light, solarized-light, vs-code-light, spring
See SKINS.md for complete documentation on:
- 📖 How to create custom color schemes
- 🎯 Color reference and semantic naming
- 📦 Downloading community themes from GitHub
- 🔧 Advanced customization options
- 🎨 Design guidelines for accessibility
We love contributions! Please see CONTRIBUTING.md for details.
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
This project is licensed under the MIT License - see the LICENSE file for details.
- Inspired by k9s for the amazing TUI patterns
- Built with Charm libraries for beautiful terminal UIs
- OpenTelemetry community for the OTLP specifications
- Usage Guide - Detailed usage instructions
- AWS CloudWatch Logs Usage Guide - Usage instructions for AWS CLI log tail and live tail with Gonzo
- Stern Usage Guide - Usage and examples for using Stern with Gonzo
- Victoria Logs Integration - Using Gonzo with Victoria Logs API
- Contributing Guide - How to contribute
- Changelog - Version history
Found a bug? Please open an issue with:
- Your OS and Go version
- Steps to reproduce
- Expected vs actual behavior
- Log samples (sanitized if needed)
If you find this project useful, please consider giving it a star! It helps others discover the tool.
Made with ❤️ by ControlTheory and the Gonzo community
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gonzo
Similar Open Source Tools
gonzo
Gonzo is a powerful, real-time log analysis terminal UI tool inspired by k9s. It allows users to analyze log streams with beautiful charts, AI-powered insights, and advanced filtering directly from the terminal. The tool provides features like live streaming log processing, OTLP support, interactive dashboard with real-time charts, advanced filtering options including regex support, and AI-powered insights such as pattern detection, anomaly analysis, and root cause suggestions. Users can also configure AI models from providers like OpenAI, LM Studio, and Ollama for intelligent log analysis. Gonzo is built with Bubble Tea, Lipgloss, Cobra, Viper, and OpenTelemetry, following a clean architecture with separate modules for TUI, log analysis, frequency tracking, OTLP handling, and AI integration.

traceroot
TraceRoot is a tool that helps engineers debug production issues 10× faster using AI-powered analysis of traces, logs, and code context. It accelerates the debugging process with AI-powered insights, integrates seamlessly into the development workflow, provides real-time trace and log analysis, code context understanding, and intelligent assistance. Features include ease of use, LLM flexibility, distributed services, AI debugging interface, and integration support. Users can get started with TraceRoot Cloud for a 7-day trial or self-host the tool. SDKs are available for Python and JavaScript/TypeScript.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
context-lens
Context Lens is a local proxy tool that captures LLM API calls from coding tools to provide a breakdown of context composition, including system prompts, tool definitions, conversation history, tool results, and thinking blocks. It helps developers understand why coding sessions may be resource-intensive without requiring any code changes. The tool works with various coding tools like Claude Code, Codex, Gemini CLI, Aider, and Pi, interacting with OpenAI, Anthropic, and Google APIs. Context Lens offers a visual treemap breakdown, cost tracking, conversation threading, agent breakdown, timeline visualization, context diff analysis, findings flags, auto-detection of coding tools, LHAR export, state persistence, and streaming support, all running locally for privacy and control.
llama.ui
llama.ui is an open-source desktop application that provides a beautiful, user-friendly interface for interacting with large language models powered by llama.cpp. It is designed for simplicity and privacy, allowing users to chat with powerful quantized models on their local machine without the need for cloud services. The project offers multi-provider support, conversation management with indexedDB storage, rich UI components including markdown rendering and file attachments, advanced features like PWA support and customizable generation parameters, and is privacy-focused with all data stored locally in the browser.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.

spiceai
Spice is a portable runtime written in Rust that offers developers a unified SQL interface to materialize, accelerate, and query data from any database, data warehouse, or data lake. It connects, fuses, and delivers data to applications, machine-learning models, and AI-backends, functioning as an application-specific, tier-optimized Database CDN. Built with industry-leading technologies such as Apache DataFusion, Apache Arrow, Apache Arrow Flight, SQLite, and DuckDB. Spice makes it fast and easy to query data from one or more sources using SQL, co-locating a managed dataset with applications or machine learning models, and accelerating it with Arrow in-memory, SQLite/DuckDB, or attached PostgreSQL for fast, high-concurrency, low-latency queries.
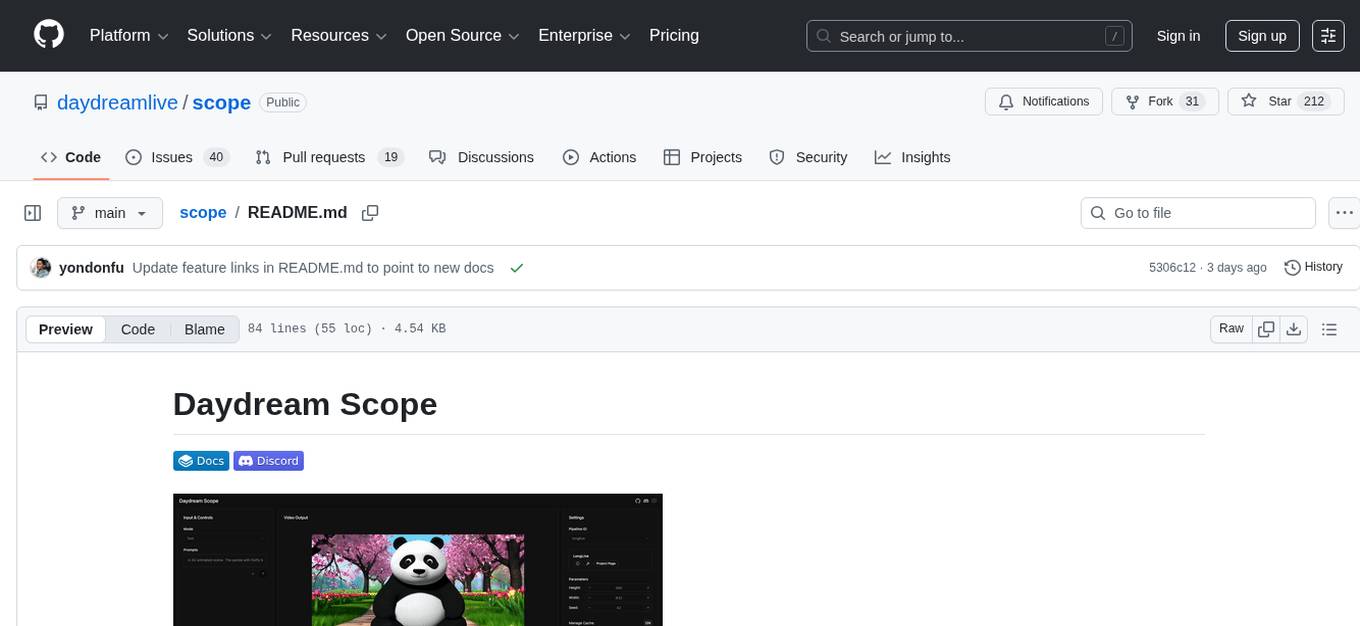
scope
Scope is a tool for running and customizing real-time, interactive generative AI pipelines and models. It offers features such as autoregressive video diffusion models, stream diffusion, real-time video processing, and an interactive UI with timeline editor. The tool supports plugins for extending capabilities, LoRAs for customizing concepts, and VACE for using reference images. Scope also provides an API with WebRTC streaming and Spout for real-time video sharing on Windows. It requires system checks and can be deployed on Runpod with specific instructions for firewall settings.
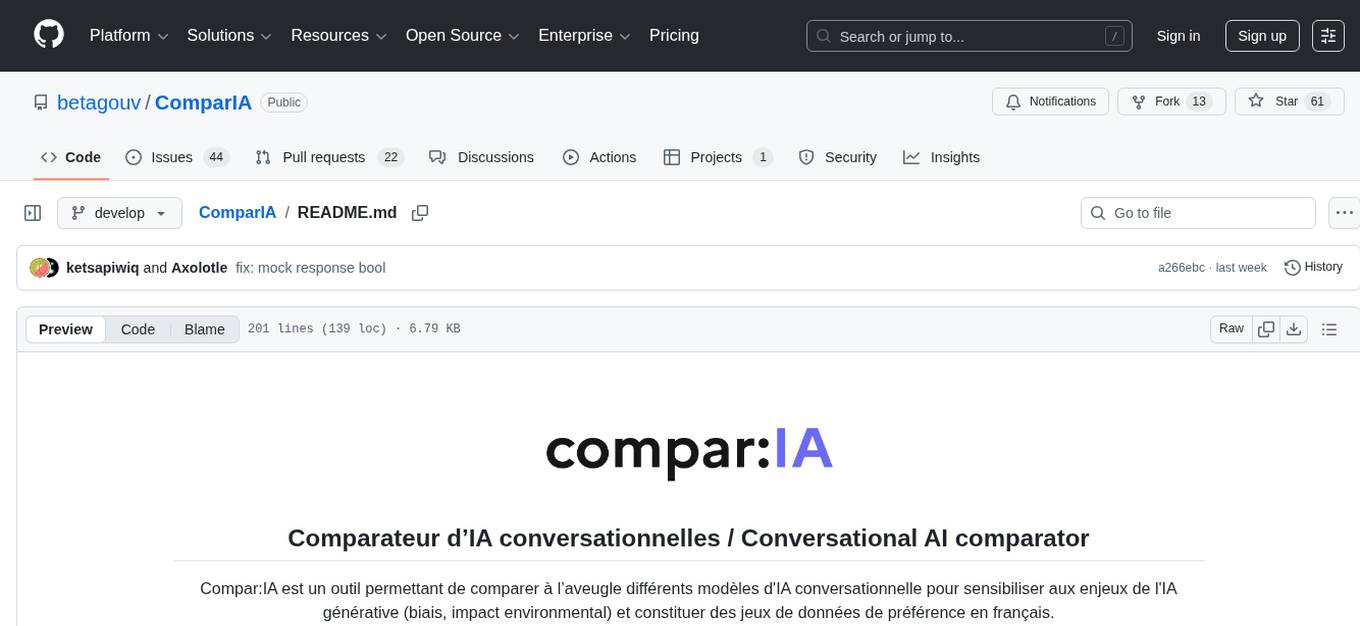
ComparIA
Compar:IA is a tool for blindly comparing different conversational AI models to raise awareness about the challenges of generative AI (bias, environmental impact) and to build up French-language preference datasets. It provides a platform for testing with real providers, enabling mock responses for testing purposes. The tool includes backend (FastAPI + Gradio) and frontend (SvelteKit) components, with Docker support for easy setup. Users can run the tool using provided Makefile commands or manually set up the backend and frontend. Additionally, the tool offers functionalities for database initialization, migrations, model generation, dataset export, and ranking methods.
odoo-llm
This repository provides a comprehensive framework for integrating Large Language Models (LLMs) into Odoo. It enables seamless interaction with AI providers like OpenAI, Anthropic, Ollama, and Replicate for chat completions, text embeddings, and more within the Odoo environment. The architecture includes external AI clients connecting via `llm_mcp_server` and Odoo AI Chat with built-in chat interface. The core module `llm` offers provider abstraction, model management, and security, along with tools for CRUD operations and domain-specific tool packs. Various AI providers, infrastructure components, and domain-specific tools are available for different tasks such as content generation, knowledge base management, and AI assistants creation.
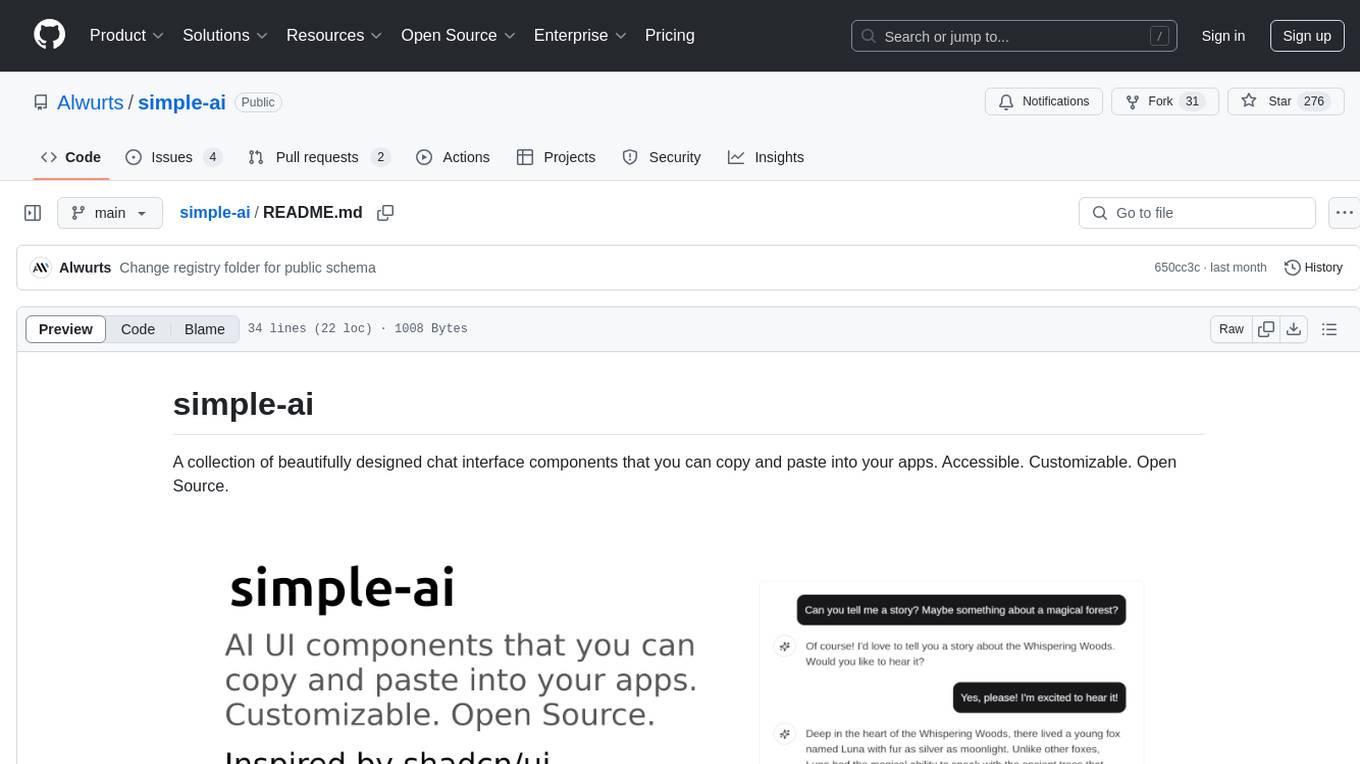
simple-ai
Simple AI is a lightweight Python library for implementing basic artificial intelligence algorithms. It provides easy-to-use functions and classes for tasks such as machine learning, natural language processing, and computer vision. With Simple AI, users can quickly prototype and deploy AI solutions without the complexity of larger frameworks.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.

llm-on-openshift
This repository provides resources, demos, and recipes for working with Large Language Models (LLMs) on OpenShift using OpenShift AI or Open Data Hub. It includes instructions for deploying inference servers for LLMs, such as vLLM, Hugging Face TGI, Caikit-TGIS-Serving, and Ollama. Additionally, it offers guidance on deploying serving runtimes, such as vLLM Serving Runtime and Hugging Face Text Generation Inference, in the Single-Model Serving stack of Open Data Hub or OpenShift AI. The repository also covers vector databases that can be used as a Vector Store for Retrieval Augmented Generation (RAG) applications, including Milvus, PostgreSQL+pgvector, and Redis. Furthermore, it provides examples of inference and application usage, such as Caikit, Langchain, Langflow, and UI examples.
osaurus
Osaurus is a versatile open-source tool designed for data scientists and machine learning engineers. It provides a wide range of functionalities for data preprocessing, feature engineering, model training, and evaluation. With Osaurus, users can easily clean and transform raw data, extract relevant features, build and tune machine learning models, and analyze model performance. The tool supports various machine learning algorithms and techniques, making it suitable for both beginners and experienced practitioners in the field. Osaurus is actively maintained and updated to incorporate the latest advancements in the machine learning domain, ensuring users have access to state-of-the-art tools and methodologies for their projects.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.
For similar tasks
Awesome-LLM4Cybersecurity
The repository 'Awesome-LLM4Cybersecurity' provides a comprehensive overview of the applications of Large Language Models (LLMs) in cybersecurity. It includes a systematic literature review covering topics such as constructing cybersecurity-oriented domain LLMs, potential applications of LLMs in cybersecurity, and research directions in the field. The repository analyzes various benchmarks, datasets, and applications of LLMs in cybersecurity tasks like threat intelligence, fuzzing, vulnerabilities detection, insecure code generation, program repair, anomaly detection, and LLM-assisted attacks.
gonzo
Gonzo is a powerful, real-time log analysis terminal UI tool inspired by k9s. It allows users to analyze log streams with beautiful charts, AI-powered insights, and advanced filtering directly from the terminal. The tool provides features like live streaming log processing, OTLP support, interactive dashboard with real-time charts, advanced filtering options including regex support, and AI-powered insights such as pattern detection, anomaly analysis, and root cause suggestions. Users can also configure AI models from providers like OpenAI, LM Studio, and Ollama for intelligent log analysis. Gonzo is built with Bubble Tea, Lipgloss, Cobra, Viper, and OpenTelemetry, following a clean architecture with separate modules for TUI, log analysis, frequency tracking, OTLP handling, and AI integration.
shell_gpt
ShellGPT is a command-line productivity tool powered by AI large language models (LLMs). This command-line tool offers streamlined generation of shell commands, code snippets, documentation, eliminating the need for external resources (like Google search). Supports Linux, macOS, Windows and compatible with all major Shells like PowerShell, CMD, Bash, Zsh, etc.
holoinsight
HoloInsight is a cloud-native observability platform that provides low-cost and high-performance monitoring services for cloud-native applications. It offers deep insights through real-time log analysis and AI integration. The platform is designed to help users gain a comprehensive understanding of their applications' performance and behavior in the cloud environment. HoloInsight is easy to deploy using Docker and Kubernetes, making it a versatile tool for monitoring and optimizing cloud-native applications. With a focus on scalability and efficiency, HoloInsight is suitable for organizations looking to enhance their observability and monitoring capabilities in the cloud.
WatchAlert
WatchAlert is a lightweight monitoring and alerting engine tailored for cloud-native environments, focusing on observability and stability themes. It provides comprehensive monitoring and alerting support, including AI-powered alert analysis for efficient troubleshooting. WatchAlert integrates with various data sources such as Prometheus, VictoriaMetrics, Loki, Elasticsearch, AliCloud SLS, Jaeger, Kubernetes, and different network protocols for monitoring and supports alert notifications via multiple channels like Feishu, DingTalk, WeChat Work, email, and custom hooks. It is optimized for cloud-native environments, easy to use, offers flexible alert rule configurations, and specializes in stability scenarios to help users quickly identify and resolve issues, providing a reliable monitoring and alerting solution to enhance operational efficiency and reduce maintenance costs.
claude-container
Claude Container is a Docker container pre-installed with Claude Code, providing an isolated environment for running Claude Code with optional API request logging in a local SQLite database. It includes three images: main container with Claude Code CLI, optional HTTP proxy for logging requests, and a web UI for visualizing and querying logs. The tool offers compatibility with different versions of Claude Code, quick start guides using a helper script or Docker Compose, authentication process, integration with existing projects, API request logging proxy setup, and data visualization with Datasette.
claude-code-engingeering
Claude Code is an advanced AI Agent framework that goes beyond a smart command-line tool. It is programmable, extensible, and composable, allowing users to teach it project specifications, split tasks into sub-agents, provide domain skills, automate responses to specific events, and integrate it into CI/CD pipelines for unmanned operation. The course aims to transform users from 'users' of Claude Code to 'masters' who can design agent 'memories', delegate tasks to sub-agents, build reusable skill packages, drive automation workflows with code, and collaborate with intelligent agents in a dance of development.
aitom
AITom is an open-source platform for AI-driven cellular electron cryo-tomography analysis. It is developed to process large amounts of Cryo-ET data, reconstruct, detect, classify, recover, and spatially model different cellular components using state-of-the-art machine learning approaches. The platform aims to automate cellular structure discovery and provide new insights into molecular biology and medical applications.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.