
ai21-python
AI21 Python SDK
Stars: 65
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.
README:
![]()
![]()


- Examples 🗂️
- AI21 Official Documentation
- Installation 💿
- Usage - Chat Completions
- Maestro
- Agents (Beta)
- Conversational RAG (Beta)
- Older Models Support Usage
- More Models
- Environment Variables
- Error Handling
- Cloud Providers ☁️
If you want to quickly get a glance how to use the AI21 Python SDK and jump straight to business, you can check out the examples. Take a look at our models and see them in action! Several examples and demonstrations have been put together to show our models' functionality and capabilities.
Feel free to dive in, experiment, and adapt these examples to suit your needs. We believe they'll help you get up and running quickly.
The full documentation for the REST API can be found on docs.ai21.com.
pip install ai21from ai21 import AI21Client
from ai21.models.chat import ChatMessage
client = AI21Client(
# defaults to os.enviorn.get('AI21_API_KEY')
api_key='my_api_key',
)
system = "You're a support engineer in a SaaS company"
messages = [
ChatMessage(content=system, role="system"),
ChatMessage(content="Hello, I need help with a signup process.", role="user"),
]
chat_completions = client.chat.completions.create(
messages=messages,
model="jamba-mini",
)You can use the AsyncAI21Client to make asynchronous requests.
There is no difference between the sync and the async client in terms of usage.
import asyncio
from ai21 import AsyncAI21Client
from ai21.models.chat import ChatMessage
system = "You're a support engineer in a SaaS company"
messages = [
ChatMessage(content=system, role="system"),
ChatMessage(content="Hello, I need help with a signup process.", role="user"),
]
client = AsyncAI21Client(
# defaults to os.enviorn.get('AI21_API_KEY')
api_key='my_api_key',
)
async def main():
response = await client.chat.completions.create(
messages=messages,
model="jamba-mini",
)
print(response)
asyncio.run(main())A more detailed example can be found here.
from ai21 import AI21Client
from ai21.models import RoleType
from ai21.models import ChatMessage
system = "You're a support engineer in a SaaS company"
messages = [
ChatMessage(text="Hello, I need help with a signup process.", role=RoleType.USER),
ChatMessage(text="Hi Alice, I can help you with that. What seems to be the problem?", role=RoleType.ASSISTANT),
ChatMessage(text="I am having trouble signing up for your product with my Google account.", role=RoleType.USER),
]
client = AI21Client()
chat_response = client.chat.create(
system=system,
messages=messages,
model="j2-ultra",
)For a more detailed example, see the chat examples.
from ai21 import AI21Client
client = AI21Client()
completion_response = client.completion.create(
prompt="This is a test prompt",
model="j2-mid",
)from ai21 import AI21Client
from ai21.models.chat import ChatMessage
system = "You're a support engineer in a SaaS company"
messages = [
ChatMessage(content=system, role="system"),
ChatMessage(content="Hello, I need help with a signup process.", role="user"),
ChatMessage(content="Hi Alice, I can help you with that. What seems to be the problem?", role="assistant"),
ChatMessage(content="I am having trouble signing up for your product with my Google account.", role="user"),
]
client = AI21Client()
response = client.chat.completions.create(
messages=messages,
model="jamba-large",
max_tokens=100,
temperature=0.7,
top_p=1.0,
stop=["\n"],
)
print(response)Note that jamba-large supports async and streaming as well.
For a more detailed example, see the completion examples.
We currently support streaming for the Chat Completions API in Jamba.
from ai21 import AI21Client
from ai21.models.chat import ChatMessage
messages = [ChatMessage(content="What is the meaning of life?", role="user")]
client = AI21Client()
response = client.chat.completions.create(
messages=messages,
model="jamba-large",
stream=True,
)
for chunk in response:
print(chunk.choices[0].delta.content, end="")import asyncio
from ai21 import AsyncAI21Client
from ai21.models.chat import ChatMessage
messages = [ChatMessage(content="What is the meaning of life?", role="user")]
client = AsyncAI21Client()
async def main():
response = await client.chat.completions.create(
messages=messages,
model="jamba-mini",
stream=True,
)
async for chunk in response:
print(chunk.choices[0].delta.content, end="")
asyncio.run(main())AI Planning & Orchestration System built for the enterprise. Read more here.
from ai21 import AI21Client
client = AI21Client()
run_result = client.beta.maestro.runs.create_and_poll(
input="Write a poem about the ocean",
requirements=[
{
"name": "length requirement",
"description": "The length of the poem should be less than 1000 characters",
},
{
"name": "rhyme requirement",
"description": "The poem should rhyme",
},
],
include=["requirements_result"]
)For a more detailed example, see maestro sync and async examples.
AI21 Agents provide a comprehensive way to create, manage, and run your Agents.
from ai21 import AI21Client
from ai21.models.agents import BudgetLevel, AgentType
client = AI21Client()
# Run the agent
run_response = client.beta.agents.runs.create_and_poll(
agent_id=agent.id,
input=[{"role": "user", "content": "What is 2+2?"}],
poll_timeout_sec=120,
)
print(f"Result: {run_response.result}")from ai21 import AI21Client
from ai21.models.agents import BudgetLevel, AgentType
client = AI21Client()
# Create
agent = client.beta.agents.create(
name="Research Assistant",
description="Specialized in research tasks",
budget=BudgetLevel.HIGH,
)
# Read
retrieved_agent = client.beta.agents.get(agent.id)
agents_list = client.beta.agents.list()
# Update
modified_agent = client.beta.agents.modify(
agent.id,
name="Enhanced Research Assistant",
description="Updated with enhanced capabilities",
)
# Delete
delete_response = client.beta.agents.delete(agent.id)For more detailed examples, see agent CRUD operations, basic runs, and async operations examples.
Like chat, but with the ability to retrieve information from your Studio library.
from ai21 import AI21Client
from ai21.models.chat import ChatMessage
messages = [
ChatMessage(content="Ask a question about your files", role="user"),
]
client = AI21Client()
client.library.files.create(
file_path="path/to/file",
path="path/to/file/in/library",
labels=["my_file_label"],
)
chat_response = client.beta.conversational_rag.create(
messages=messages,
labels=["my_file_label"],
)For a more detailed example, see the chat sync and async examples.
from ai21 import AI21Client
client = AI21Client()
file_id = client.library.files.create(
file_path="path/to/file",
path="path/to/file/in/library",
labels=["label1", "label2"],
public_url="www.example.com",
)
uploaded_file = client.library.files.get(file_id)You can set several environment variables to configure the client.
We use the standard library logging module.
To enable logging, set the AI21_LOG_LEVEL environment variable.
$ export AI21_LOG_LEVEL=debug-
AI21_API_KEY- Your API key. If not set, you must pass it to the client constructor. -
AI21_API_VERSION- The API version. Defaults tov1. -
AI21_API_HOST- The API host. Defaults tohttps://api.ai21.com/studio/v1/. -
AI21_TIMEOUT_SEC- The timeout for API requests. -
AI21_NUM_RETRIES- The maximum number of retries for API requests. Defaults to3retries. -
AI21_AWS_REGION- The AWS region to use for AWS clients. Defaults tous-east-1.
from ai21 import errors as ai21_errors
from ai21 import AI21Client, AI21APIError
from ai21.models import ChatMessage
client = AI21Client()
system = "You're a support engineer in a SaaS company"
messages = [
# Notice the given role does not exist and will be the reason for the raised error
ChatMessage(text="Hello, I need help with a signup process.", role="Non-Existent-Role"),
]
try:
chat_completion = client.chat.create(
messages=messages,
model="j2-ultra",
system=system
)
except ai21_errors.AI21ServerError as e:
print("Server error and could not be reached")
print(e.details)
except ai21_errors.TooManyRequestsError as e:
print("A 429 status code was returned. Slow down on the requests")
except AI21APIError as e:
print("A non 200 status code error. For more error types see ai21.errors")AI21 Library provides convenient ways to interact with two AWS clients for use with AWS Bedrock and AWS SageMaker.
pip install -U "ai21[AWS]"This will make sure you have the required dependencies installed, including boto3 >= 1.28.82.
from ai21 import AI21BedrockClient, BedrockModelID
from ai21.models.chat import ChatMessage
client = AI21BedrockClient(region='us-east-1') # region is optional, as you can use the env variable instead
messages = [
ChatMessage(content="You are a helpful assistant", role="system"),
ChatMessage(content="What is the meaning of life?", role="user")
]
response = client.chat.completions.create(
messages=messages,
model_id=BedrockModelID.JAMBA_1_5_LARGE,
)from ai21 import AI21BedrockClient, BedrockModelID
from ai21.models.chat import ChatMessage
system = "You're a support engineer in a SaaS company"
messages = [
ChatMessage(content=system, role="system"),
ChatMessage(content="Hello, I need help with a signup process.", role="user"),
ChatMessage(content="Hi Alice, I can help you with that. What seems to be the problem?", role="assistant"),
ChatMessage(content="I am having trouble signing up for your product with my Google account.", role="user"),
]
client = AI21BedrockClient()
response = client.chat.completions.create(
messages=messages,
model=BedrockModelID.JAMBA_1_5_LARGE,
stream=True,
)
for chunk in response:
print(chunk.choices[0].message.content, end="")import asyncio
from ai21 import AsyncAI21BedrockClient, BedrockModelID
from ai21.models.chat import ChatMessage
client = AsyncAI21BedrockClient(region='us-east-1') # region is optional, as you can use the env variable instead
messages = [
ChatMessage(content="You are a helpful assistant", role="system"),
ChatMessage(content="What is the meaning of life?", role="user")
]
async def main():
response = await client.chat.completions.create(
messages=messages,
model_id=BedrockModelID.JAMBA_1_5_LARGE,
)
asyncio.run(main())import boto3
from ai21 import AI21BedrockClient, BedrockModelID
from ai21.models.chat import ChatMessage
boto_session = boto3.Session(region_name="us-east-1")
client = AI21BedrockClient(session=boto_session)
messages = [
ChatMessage(content="You are a helpful assistant", role="system"),
ChatMessage(content="What is the meaning of life?", role="user")
]
response = client.chat.completions.create(
messages=messages,
model_id=BedrockModelID.JAMBA_1_5_LARGE,
)import boto3
import asyncio
from ai21 import AsyncAI21BedrockClient, BedrockModelID
from ai21.models.chat import ChatMessage
boto_session = boto3.Session(region_name="us-east-1")
client = AsyncAI21BedrockClient(session=boto_session)
messages = [
ChatMessage(content="You are a helpful assistant", role="system"),
ChatMessage(content="What is the meaning of life?", role="user")
]
async def main():
response = await client.chat.completions.create(
messages=messages,
model_id=BedrockModelID.JAMBA_1_5_LARGE,
)
asyncio.run(main())from ai21 import AI21SageMakerClient
client = AI21SageMakerClient(endpoint_name="j2-endpoint-name")
response = client.summarize.create(
source="Text to summarize",
source_type="TEXT",
)
print(response.summary)import asyncio
from ai21 import AsyncAI21SageMakerClient
client = AsyncAI21SageMakerClient(endpoint_name="j2-endpoint-name")
async def main():
response = await client.summarize.create(
source="Text to summarize",
source_type="TEXT",
)
print(response.summary)
asyncio.run(main())from ai21 import AI21SageMakerClient
import boto3
boto_session = boto3.Session(region_name="us-east-1")
client = AI21SageMakerClient(
session=boto_session,
endpoint_name="j2-endpoint-name",
)If you wish to interact with your Azure endpoint on Azure AI Studio, use the AI21AzureClient
and AsyncAI21AzureClient clients.
The following models are supported on Azure:
jamba-large
from ai21 import AI21AzureClient
from ai21.models.chat import ChatMessage
client = AI21AzureClient(
base_url="https://<YOUR-ENDPOINT>.inference.ai.azure.com",
api_key="<your Azure api key>",
)
messages = [
ChatMessage(content="You are a helpful assistant", role="system"),
ChatMessage(content="What is the meaning of life?", role="user")
]
response = client.chat.completions.create(
model="jamba-mini",
messages=messages,
)import asyncio
from ai21 import AsyncAI21AzureClient
from ai21.models.chat import ChatMessage
client = AsyncAI21AzureClient(
base_url="https://<YOUR-ENDPOINT>.inference.ai.azure.com/v1/chat/completions",
api_key="<your Azure api key>",
)
messages = [
ChatMessage(content="You are a helpful assistant", role="system"),
ChatMessage(content="What is the meaning of life?", role="user")
]
async def main():
response = await client.chat.completions.create(
model="jamba-large",
messages=messages,
)
asyncio.run(main())If you wish to interact with your Vertex AI endpoint on GCP, use the AI21VertexClient
and AsyncAI21VertexClient clients.
The following models are supported on Vertex:
jamba-1.5-minijamba-1.5-large
from ai21 import AI21VertexClient
from ai21.models.chat import ChatMessage
# You can also set the project_id, region, access_token and Google credentials in the constructor
client = AI21VertexClient()
messages = ChatMessage(content="What is the meaning of life?", role="user")
response = client.chat.completions.create(
model="jamba-1.5-mini",
messages=[messages],
)import asyncio
from ai21 import AsyncAI21VertexClient
from ai21.models.chat import ChatMessage
# You can also set the project_id, region, access_token and Google credentials in the constructor
client = AsyncAI21VertexClient()
async def main():
messages = ChatMessage(content="What is the meaning of life?", role="user")
response = await client.chat.completions.create(
model="jamba-1.5-mini",
messages=[messages],
)
asyncio.run(main())Happy prompting! 🚀
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai21-python
Similar Open Source Tools
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
ollama4j
Ollama4j is a Java library that serves as a wrapper or binding for the Ollama server. It allows users to communicate with the Ollama server and manage models for various deployment scenarios. The library provides APIs for interacting with Ollama, generating fake data, testing UI interactions, translating messages, and building web UIs. Users can easily integrate Ollama4j into their Java projects to leverage the functionalities offered by the Ollama server.
qwen-code
Qwen Code is an open-source AI agent optimized for Qwen3-Coder, designed to help users understand large codebases, automate tedious work, and expedite the shipping process. It offers an agentic workflow with rich built-in tools, a terminal-first approach with optional IDE integration, and supports both OpenAI-compatible API and Qwen OAuth authentication methods. Users can interact with Qwen Code in interactive mode, headless mode, IDE integration, and through a TypeScript SDK. The tool can be configured via settings.json, environment variables, and CLI flags, and offers benchmark results for performance evaluation. Qwen Code is part of an ecosystem that includes AionUi and Gemini CLI Desktop for graphical interfaces, and troubleshooting guides are available for issue resolution.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.

Acontext
Acontext is a context data platform designed for production AI agents, offering unified storage, built-in context management, and observability features. It helps agents scale from local demos to production without the need to rebuild context infrastructure. The platform provides solutions for challenges like scattered context data, long-running agents requiring context management, and tracking states from multi-modal agents. Acontext offers core features such as context storage, session management, disk storage, agent skills management, and sandbox for code execution and analysis. Users can connect to Acontext, install SDKs, initialize clients, store and retrieve messages, perform context engineering, and utilize agent storage tools. The platform also supports building agents using end-to-end scripts in Python and Typescript, with various templates available. Acontext's architecture includes client layer, backend with API and core components, infrastructure with PostgreSQL, S3, Redis, and RabbitMQ, and a web dashboard. Join the Acontext community on Discord and follow updates on GitHub.
context-lens
Context Lens is a local proxy tool that captures LLM API calls from coding tools to provide a breakdown of context composition, including system prompts, tool definitions, conversation history, tool results, and thinking blocks. It helps developers understand why coding sessions may be resource-intensive without requiring any code changes. The tool works with various coding tools like Claude Code, Codex, Gemini CLI, Aider, and Pi, interacting with OpenAI, Anthropic, and Google APIs. Context Lens offers a visual treemap breakdown, cost tracking, conversation threading, agent breakdown, timeline visualization, context diff analysis, findings flags, auto-detection of coding tools, LHAR export, state persistence, and streaming support, all running locally for privacy and control.
llms
llms.py is a lightweight CLI, API, and ChatGPT-like alternative to Open WebUI for accessing multiple LLMs. It operates entirely offline, ensuring all data is kept private in browser storage. The tool provides a convenient way to interact with various LLM models without the need for an internet connection, prioritizing user privacy and data security.

traceroot
TraceRoot is a tool that helps engineers debug production issues 10× faster using AI-powered analysis of traces, logs, and code context. It accelerates the debugging process with AI-powered insights, integrates seamlessly into the development workflow, provides real-time trace and log analysis, code context understanding, and intelligent assistance. Features include ease of use, LLM flexibility, distributed services, AI debugging interface, and integration support. Users can get started with TraceRoot Cloud for a 7-day trial or self-host the tool. SDKs are available for Python and JavaScript/TypeScript.

hyper-mcp
hyper-mcp is a fast and secure MCP server that enables adding AI capabilities to applications through WebAssembly plugins. It supports writing plugins in various languages, distributing them via standard OCI registries, and running them in resource-constrained environments. The tool offers sandboxing with WASM for limiting access, cross-platform compatibility, and deployment flexibility. Security features include sandboxed plugins, memory-safe execution, secure plugin distribution, and fine-grained access control. Users can configure the tool for global or project-specific use, start the server with different transport options, and utilize available plugins for tasks like time calculations, QR code generation, hash generation, IP retrieval, and webpage fetching.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.
jadx-mcp-server
JADX-MCP-SERVER is a standalone Python server that interacts with JADX-AI-MCP Plugin to analyze Android APKs using LLMs like Claude. It enables live communication with decompiled Android app context, uncovering vulnerabilities, parsing manifests, and facilitating reverse engineering effortlessly. The tool combines JADX-AI-MCP and JADX MCP SERVER to provide real-time reverse engineering support with LLMs, offering features like quick analysis, vulnerability detection, AI code modification, static analysis, and reverse engineering helpers. It supports various MCP tools for fetching class information, text, methods, fields, smali code, AndroidManifest.xml content, strings.xml file, resource files, and more. Tested on Claude Desktop, it aims to support other LLMs in the future, enhancing Android reverse engineering and APK modification tools connectivity for easier reverse engineering purely from vibes.
marionette_mcp
Marionette MCP is a Python library that provides a framework for building and managing complex automation tasks. It allows users to create automated workflows, interact with web applications, and perform various tasks in a structured and efficient manner. With Marionette MCP, users can easily automate repetitive tasks, streamline their workflows, and improve productivity. The library offers a wide range of features, including web scraping, form filling, data extraction, and more, making it a versatile tool for automation enthusiasts and developers alike.

python-sdk
Python SDK is a software development kit that provides tools and resources for developers to interact with Python programming language. It simplifies the process of integrating Python code into applications and services, offering a wide range of functionalities and libraries to streamline development workflows. With Python SDK, developers can easily access and manipulate data, create automation scripts, build web applications, and perform various tasks efficiently. It is designed to enhance the productivity and flexibility of Python developers by providing a comprehensive set of tools and utilities for software development.
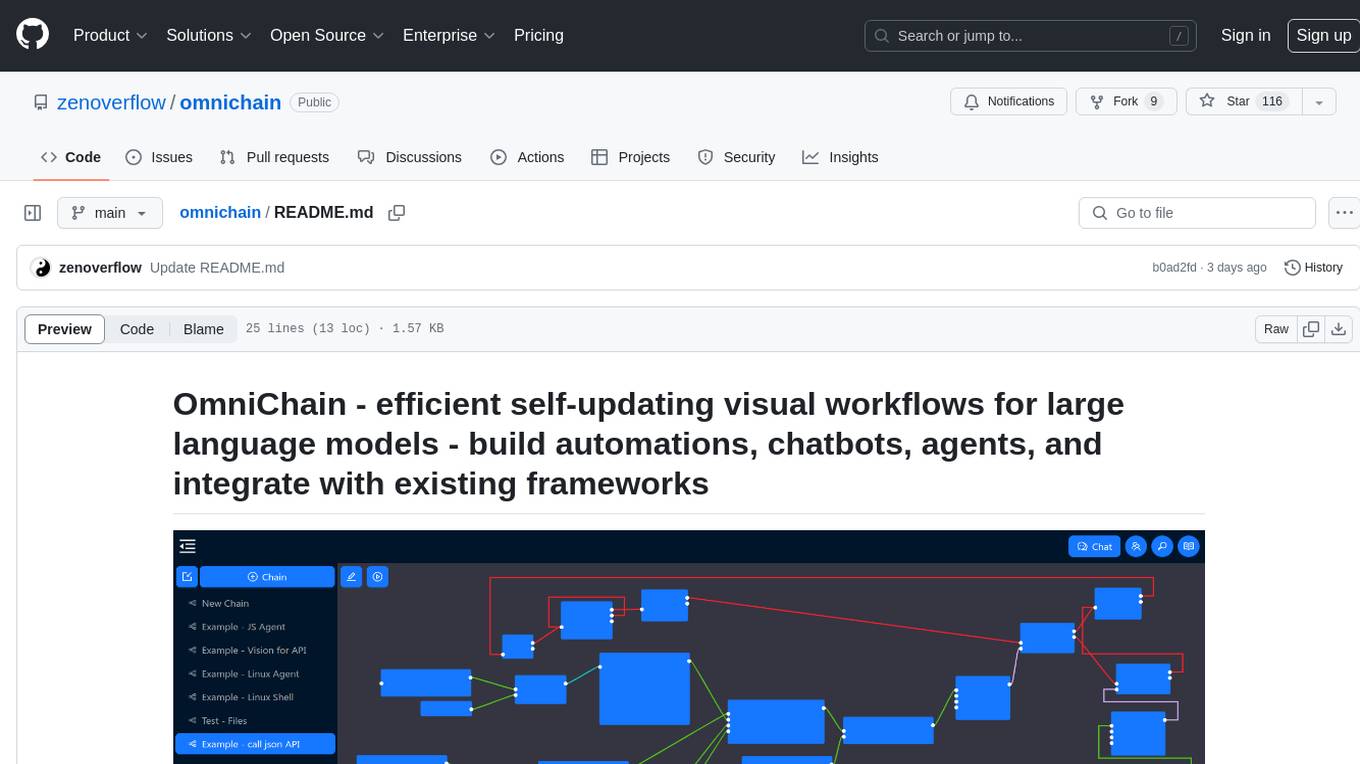
omnichain
OmniChain is a tool for building efficient self-updating visual workflows using AI language models, enabling users to automate tasks, create chatbots, agents, and integrate with existing frameworks. It allows users to create custom workflows guided by logic processes, store and recall information, and make decisions based on that information. The tool enables users to create tireless robot employees that operate 24/7, access the underlying operating system, generate and run NodeJS code snippets, and create custom agents and logic chains. OmniChain is self-hosted, open-source, and available for commercial use under the MIT license, with no coding skills required.
For similar tasks
tokencost
Tokencost is a clientside tool for calculating the USD cost of using major Large Language Model (LLMs) APIs by estimating the cost of prompts and completions. It helps track the latest price changes of major LLM providers, accurately count prompt tokens before sending OpenAI requests, and easily integrate to get the cost of a prompt or completion with a single function. Users can calculate prompt and completion costs using OpenAI requests, count tokens in prompts formatted as message lists or string prompts, and refer to a cost table with updated prices for various LLM models. The tool also supports callback handlers for LLM wrapper/framework libraries like LlamaIndex and Langchain.
llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
gigachat
GigaChat is a Python library that allows GigaChain to interact with GigaChat, a neural network model capable of engaging in dialogue, writing code, creating texts, and images on demand. Data exchange with the service is facilitated through the GigaChat API. The library supports processing token streaming, as well as working in synchronous or asynchronous mode. It enables precise token counting in text using the GigaChat API.
client
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.
gemini-cli
gemini-cli is a versatile command-line interface for Google's Gemini LLMs, written in Go. It includes tools for chatting with models, generating/comparing embeddings, and storing data in SQLite for analysis. Users can interact with Gemini models through various subcommands like prompt, chat, counttok, embed content, embed db, and embed similar.
client
Gemini PHP is a PHP API client for interacting with the Gemini AI API. It allows users to generate content, chat, count tokens, configure models, embed resources, list models, get model information, troubleshoot timeouts, and test API responses. The client supports various features such as text-only input, text-and-image input, multi-turn conversations, streaming content generation, token counting, model configuration, and embedding techniques. Users can interact with Gemini's API to perform tasks related to natural language generation and text analysis.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.