
client
Google Gemini API PHP Client allows you to use the Gemini AI model
Stars: 97
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.
README:



Gemini API PHP Client allows you to use the Google's generative AI models, like Gemini Pro and Gemini Pro Vision.
This library is not developed or endorsed by Google.
- Erdem Köse - github.com/erdemkose
- Installation
- How to use
You need an API key to gain access to Google's Gemini API. Visit Google AI Studio to get an API key.
First step is to install the Gemini API PHP client with Composer.
composer require gemini-api-php/clientGemini API PHP client does not come with an HTTP client.
If you are just testing or do not have an HTTP client library in your project,
you need to allow php-http/discovery composer plugin or install a PSR-18 compatible client library.
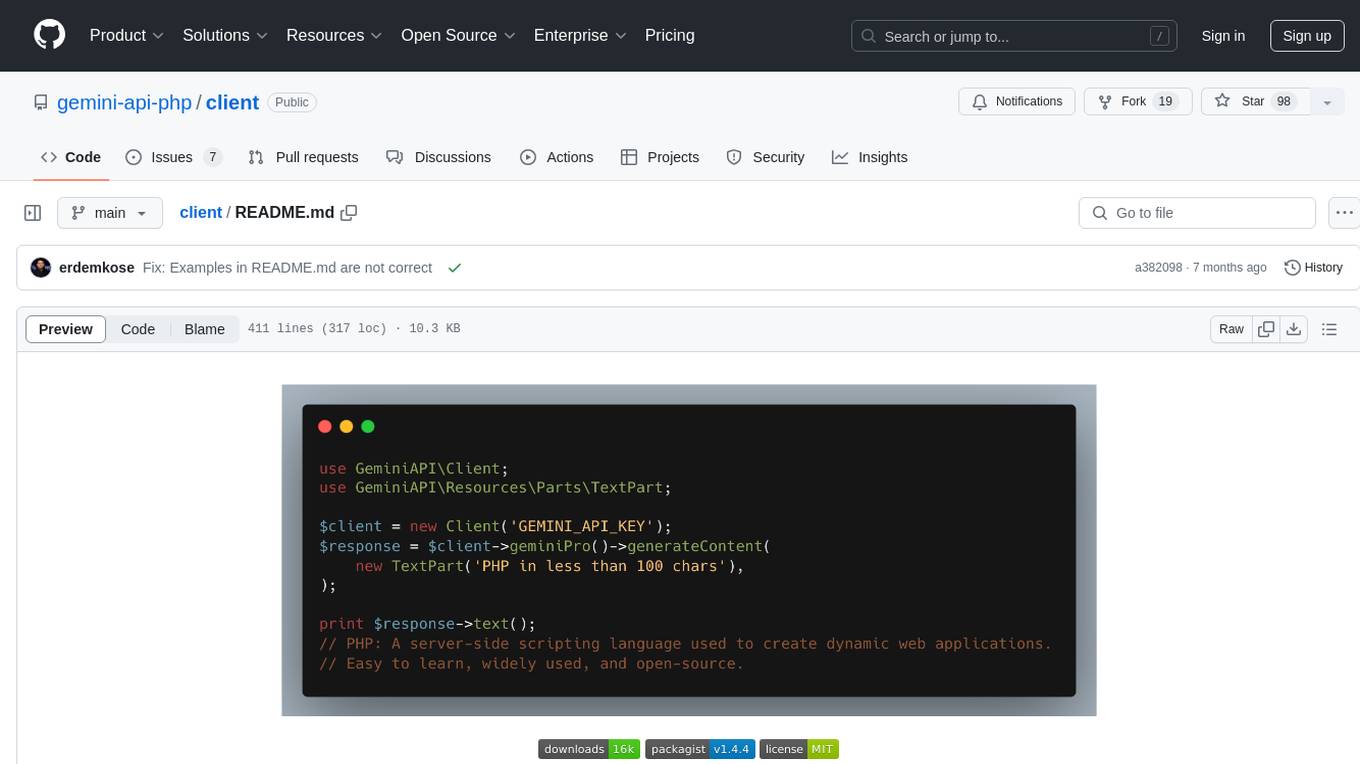
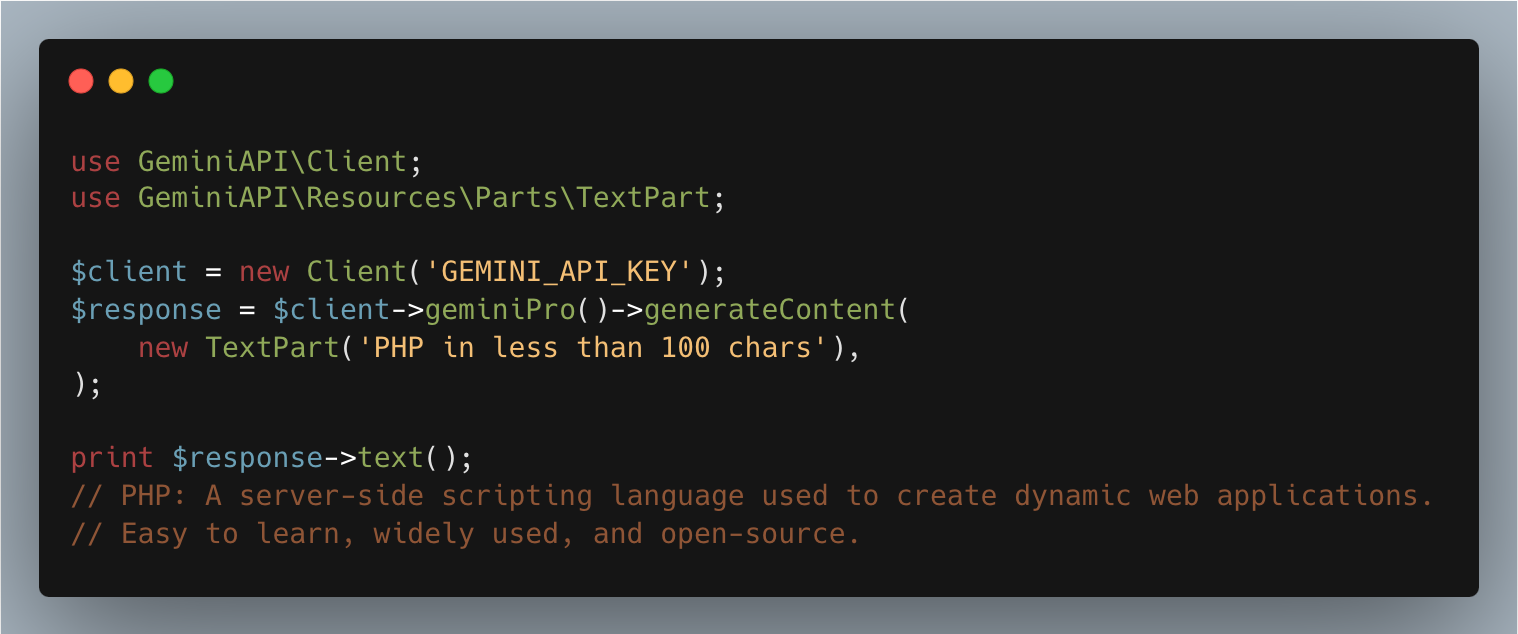
use GeminiAPI\Client;
use GeminiAPI\Resources\Parts\TextPart;
$client = new Client('GEMINI_API_KEY');
$response = $client->geminiPro()->generateContent(
new TextPart('PHP in less than 100 chars'),
);
print $response->text();
// PHP: A server-side scripting language used to create dynamic web applications.
// Easy to learn, widely used, and open-source.Image input modality is only enabled for Gemini Pro Vision model
use GeminiAPI\Client;
use GeminiAPI\Enums\MimeType;
use GeminiAPI\Resources\Parts\ImagePart;
use GeminiAPI\Resources\Parts\TextPart;
$client = new Client('GEMINI_API_KEY');
$response = $client->geminiProVision()->generateContent(
new TextPart('Explain what is in the image'),
new ImagePart(
MimeType::IMAGE_JPEG,
base64_encode(file_get_contents('elephpant.jpg')),
),
);
print $response->text();
// The image shows an elephant standing on the Earth.
// The elephant is made of metal and has a glowing symbol on its forehead.
// The Earth is surrounded by a network of glowing lines.
// The image is set against a starry background.use GeminiAPI\Client;
use GeminiAPI\Resources\Parts\TextPart;
$client = new Client('GEMINI_API_KEY');
$chat = $client->geminiPro()->startChat();
$response = $chat->sendMessage(new TextPart('Hello World in PHP'));
print $response->text();
$response = $chat->sendMessage(new TextPart('in Go'));
print $response->text();<?php
echo "Hello World!";
?>
This code will print "Hello World!" to the standard output.
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
This code will print "Hello World!" to the standard output.
use GeminiAPI\Client;
use GeminiAPI\Enums\Role;
use GeminiAPI\Resources\Content;
use GeminiAPI\Resources\Parts\TextPart;
$history = [
Content::text('Hello World in PHP', Role::User),
Content::text(
<<<TEXT
<?php
echo "Hello World!";
?>
This code will print "Hello World!" to the standard output.
TEXT,
Role::Model,
),
];
$client = new Client('GEMINI_API_KEY');
$chat = $client->geminiPro()
->startChat()
->withHistory($history);
$response = $chat->sendMessage(new TextPart('in Go'));
print $response->text();package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
This code will print "Hello World!" to the standard output.
Requires
curlextension to be enabled
In the streaming response, the callback function will be called whenever a response is returned from the server.
Long responses may be broken into separate responses, and you can start receiving responses faster using a content stream.
use GeminiAPI\Client;
use GeminiAPI\Resources\Parts\TextPart;
use GeminiAPI\Responses\GenerateContentResponse;
$callback = function (GenerateContentResponse $response): void {
static $count = 0;
print "\nResponse #{$count}\n";
print $response->text();
$count++;
};
$client = new Client('GEMINI_API_KEY');
$client->geminiPro()->generateContentStream(
$callback,
[new TextPart('PHP in less than 100 chars')],
);
// Response #0
// PHP: a versatile, general-purpose scripting language for web development, popular for
// Response #1
// its simple syntax and rich library of functions.Requires
curlextension to be enabled
use GeminiAPI\Client;
use GeminiAPI\Enums\Role;
use GeminiAPI\Resources\Content;
use GeminiAPI\Resources\Parts\TextPart;
use GeminiAPI\Responses\GenerateContentResponse;
$history = [
Content::text('Hello World in PHP', Role::User),
Content::text(
<<<TEXT
<?php
echo "Hello World!";
?>
This code will print "Hello World!" to the standard output.
TEXT,
Role::Model,
),
];
$callback = function (GenerateContentResponse $response): void {
static $count = 0;
print "\nResponse #{$count}\n";
print $response->text();
$count++;
};
$client = new Client('GEMINI_API_KEY');
$chat = $client->geminiPro()
->startChat()
->withHistory($history);
$chat->sendMessageStream($callback, new TextPart('in Go'));Response #0
package main
import "fmt"
func main() {
Response #1
fmt.Println("Hello World!")
}
This code will print "Hello World!" to the standard output.
use GeminiAPI\Client;
use GeminiAPI\Enums\ModelName;
use GeminiAPI\Resources\Parts\TextPart;
$client = new Client('GEMINI_API_KEY');
$response = $client->embeddingModel(ModelName::Embedding)
->embedContent(
new TextPart('PHP in less than 100 chars'),
);
print_r($response->embedding->values);
// [
// [0] => 0.041395925
// [1] => -0.017692696
// ...
// ]use GeminiAPI\Client;
use GeminiAPI\Resources\Parts\TextPart;
$client = new Client('GEMINI_API_KEY');
$response = $client->geminiPro()->countTokens(
new TextPart('PHP in less than 100 chars'),
);
print $response->totalTokens;
// 10use GeminiAPI\Client;
$client = new Client('GEMINI_API_KEY');
$response = $client->listModels();
print_r($response->models);
//[
// [0] => GeminiAPI\Resources\Model Object
// (
// [name] => models/gemini-pro
// [displayName] => Gemini Pro
// [description] => The best model for scaling across a wide range of tasks
// ...
// )
// [1] => GeminiAPI\Resources\Model Object
// (
// [name] => models/gemini-pro-vision
// [displayName] => Gemini Pro Vision
// [description] => The best image understanding model to handle a broad range of applications
// ...
// )
//]use GeminiAPI\Client;
use GeminiAPI\Enums\HarmCategory;
use GeminiAPI\Enums\HarmBlockThreshold;
use GeminiAPI\GenerationConfig;
use GeminiAPI\Resources\Parts\TextPart;
use GeminiAPI\SafetySetting;
$safetySetting = new SafetySetting(
HarmCategory::HARM_CATEGORY_HATE_SPEECH,
HarmBlockThreshold::BLOCK_LOW_AND_ABOVE,
);
$generationConfig = (new GenerationConfig())
->withCandidateCount(1)
->withMaxOutputTokens(40)
->withTemperature(0.5)
->withTopK(40)
->withTopP(0.6)
->withStopSequences(['STOP']);
$client = new Client('GEMINI_API_KEY');
$response = $client->geminiPro()
->withAddedSafetySetting($safetySetting)
->withGenerationConfig($generationConfig)
->generateContent(
new TextPart('PHP in less than 100 chars')
);use GeminiAPI\Client as GeminiClient;
use GeminiAPI\Resources\Parts\TextPart;
use GuzzleHttp\Client as GuzzleClient;
$guzzle = new GuzzleClient([
'proxy' => 'http://localhost:8125',
]);
$client = new GeminiClient('GEMINI_API_KEY', $guzzle);
$response = $client->geminiPro()->generateContent(
new TextPart('PHP in less than 100 chars')
);Requires
curlextension to be enabled
Since streaming responses are fetched using curl extension, they cannot use the custom HTTP client passed to the Gemini Client.
You need to pass a CurlHandler if you want to override connection options.
The following curl options will be overwritten by the Gemini Client.
CURLOPT_URLCURLOPT_POSTCURLOPT_POSTFIELDSCURLOPT_WRITEFUNCTION
You can also pass the headers you want to be used in the requests.
use GeminiAPI\Client;
use GeminiAPI\Resources\Parts\TextPart;
use GeminiAPI\Responses\GenerateContentResponse;
$callback = function (GenerateContentResponse $response): void {
print $response->text();
};
$ch = curl_init();
curl_setopt($ch, \CURLOPT_PROXY, 'http://localhost:8125');
$client = new Client('GEMINI_API_KEY');
$client->withRequestHeaders([
'User-Agent' => 'My Gemini-backed app'
])
->geminiPro()
->generateContentStream(
$callback,
[new TextPart('PHP in less than 100 chars')],
$ch,
);For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for client
Similar Open Source Tools
client
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.
client
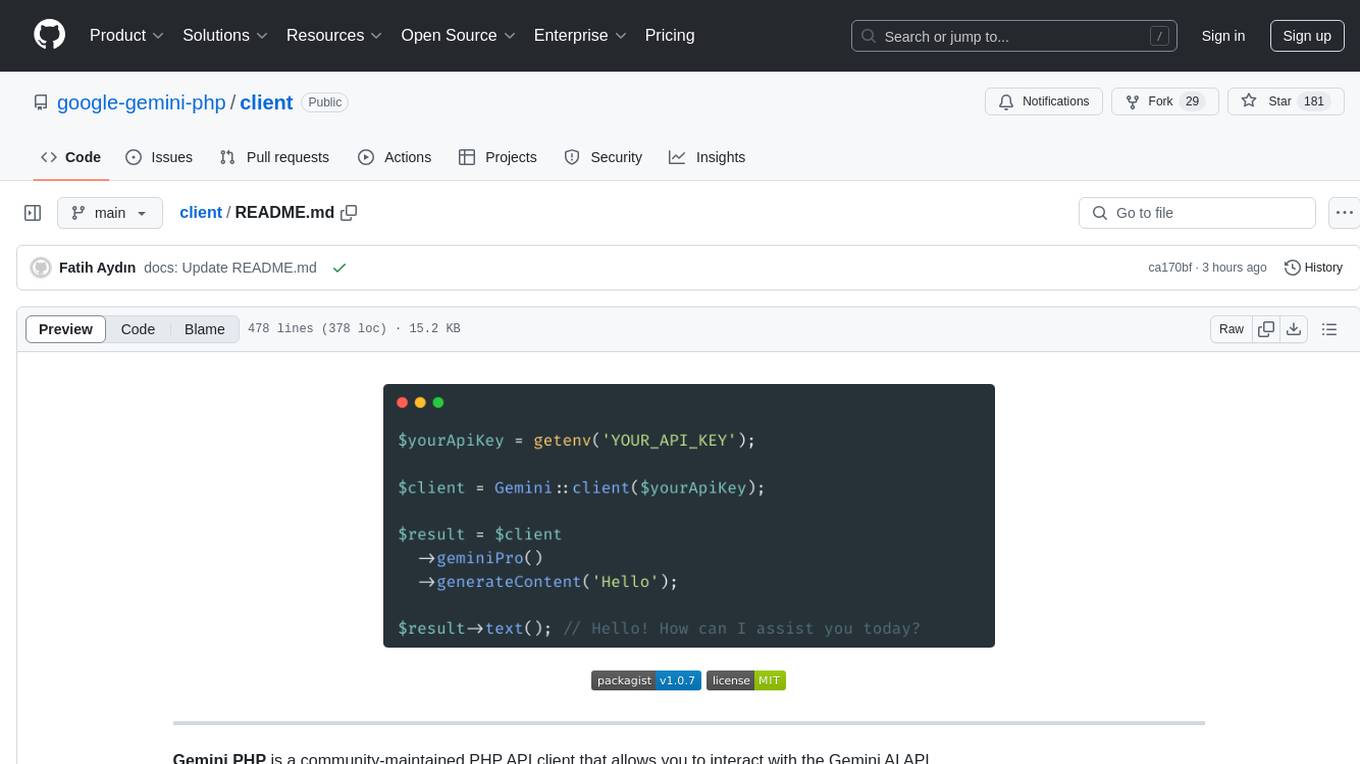
Gemini PHP is a PHP API client for interacting with the Gemini AI API. It allows users to generate content, chat, count tokens, configure models, embed resources, list models, get model information, troubleshoot timeouts, and test API responses. The client supports various features such as text-only input, text-and-image input, multi-turn conversations, streaming content generation, token counting, model configuration, and embedding techniques. Users can interact with Gemini's API to perform tasks related to natural language generation and text analysis.
java-genai
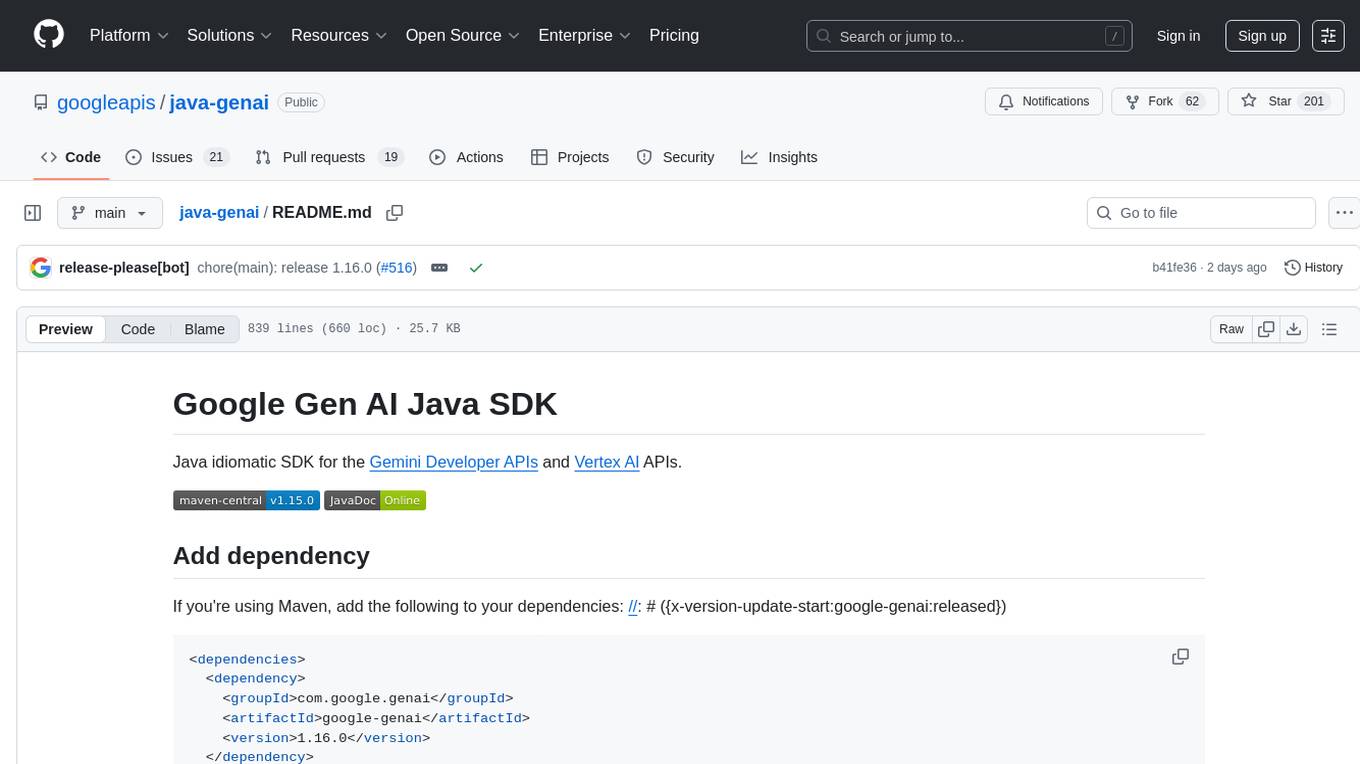
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.

js-genai
The Google Gen AI JavaScript SDK is an experimental SDK for TypeScript and JavaScript developers to build applications powered by Gemini. It supports both the Gemini Developer API and Vertex AI. The SDK is designed to work with Gemini 2.0 features. Users can access API features through the GoogleGenAI classes, which provide submodules for querying models, managing caches, creating chats, uploading files, and starting live sessions. The SDK also allows for function calling to interact with external systems. Users can find more samples in the GitHub samples directory.
OpenAI-DotNet
OpenAI-DotNet is a simple C# .NET client library for OpenAI to use through their RESTful API. It is independently developed and not an official library affiliated with OpenAI. Users need an OpenAI API account to utilize this library. The library targets .NET 6.0 and above, working across various platforms like console apps, winforms, wpf, asp.net, etc., and on Windows, Linux, and Mac. It provides functionalities for authentication, interacting with models, assistants, threads, chat, audio, images, files, fine-tuning, embeddings, and moderations.
com.openai.unity
com.openai.unity is an OpenAI package for Unity that allows users to interact with OpenAI's API through RESTful requests. It is independently developed and not an official library affiliated with OpenAI. Users can fine-tune models, create assistants, chat completions, and more. The package requires Unity 2021.3 LTS or higher and can be installed via Unity Package Manager or Git URL. Various features like authentication, Azure OpenAI integration, model management, thread creation, chat completions, audio processing, image generation, file management, fine-tuning, batch processing, embeddings, and content moderation are available.

generative-ai-python
The Google AI Python SDK is the easiest way for Python developers to build with the Gemini API. The Gemini API gives you access to Gemini models created by Google DeepMind. Gemini models are built from the ground up to be multimodal, so you can reason seamlessly across text, images, and code.
UniChat
UniChat is a pipeline tool for creating online and offline chat-bots in Unity. It leverages Unity.Sentis and text vector embedding technology to enable offline mode text content search based on vector databases. The tool includes a chain toolkit for embedding LLM and Agent in games, along with middleware components for Text to Speech, Speech to Text, and Sub-classifier functionalities. UniChat also offers a tool for invoking tools based on ReActAgent workflow, allowing users to create personalized chat scenarios and character cards. The tool provides a comprehensive solution for designing flexible conversations in games while maintaining developer's ideas.
ElevenLabs-DotNet
ElevenLabs-DotNet is a non-official Eleven Labs voice synthesis RESTful client that allows users to convert text to speech. The library targets .NET 8.0 and above, working across various platforms like console apps, winforms, wpf, and asp.net, and across Windows, Linux, and Mac. Users can authenticate using API keys directly, from a configuration file, or system environment variables. The tool provides functionalities for text to speech conversion, streaming text to speech, accessing voices, dubbing audio or video files, generating sound effects, managing history of synthesized audio clips, and accessing user information and subscription status.

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.

client-js
The Mistral JavaScript client is a library that allows you to interact with the Mistral AI API. With this client, you can perform various tasks such as listing models, chatting with streaming, chatting without streaming, and generating embeddings. To use the client, you can install it in your project using npm and then set up the client with your API key. Once the client is set up, you can use it to perform the desired tasks. For example, you can use the client to chat with a model by providing a list of messages. The client will then return the response from the model. You can also use the client to generate embeddings for a given input. The embeddings can then be used for various downstream tasks such as clustering or classification.
client-ts
Mistral Typescript Client is an SDK for Mistral AI API, providing Chat Completion and Embeddings APIs. It allows users to create chat completions, upload files, create agent completions, create embedding requests, and more. The SDK supports various JavaScript runtimes and provides detailed documentation on installation, requirements, API key setup, example usage, error handling, server selection, custom HTTP client, authentication, providers support, standalone functions, debugging, and contributions.

ai00_server
AI00 RWKV Server is an inference API server for the RWKV language model based upon the web-rwkv inference engine. It supports VULKAN parallel and concurrent batched inference and can run on all GPUs that support VULKAN. No need for Nvidia cards!!! AMD cards and even integrated graphics can be accelerated!!! No need for bulky pytorch, CUDA and other runtime environments, it's compact and ready to use out of the box! Compatible with OpenAI's ChatGPT API interface. 100% open source and commercially usable, under the MIT license. If you are looking for a fast, efficient, and easy-to-use LLM API server, then AI00 RWKV Server is your best choice. It can be used for various tasks, including chatbots, text generation, translation, and Q&A.
aiotdlib
aiotdlib is a Python asyncio Telegram client based on TDLib. It provides automatic generation of types and functions from tl schema, validation, good IDE type hinting, and high-level API methods for simpler work with tdlib. The package includes prebuilt TDLib binaries for macOS (arm64) and Debian Bullseye (amd64). Users can use their own binary by passing `library_path` argument to `Client` class constructor. Compatibility with other versions of the library is not guaranteed. The tool requires Python 3.9+ and users need to get their `api_id` and `api_hash` from Telegram docs for installation and usage.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!
model.nvim
model.nvim is a tool designed for Neovim users who want to utilize AI models for completions or chat within their text editor. It allows users to build prompts programmatically with Lua, customize prompts, experiment with multiple providers, and use both hosted and local models. The tool supports features like provider agnosticism, programmatic prompts in Lua, async and multistep prompts, streaming completions, and chat functionality in 'mchat' filetype buffer. Users can customize prompts, manage responses, and context, and utilize various providers like OpenAI ChatGPT, Google PaLM, llama.cpp, ollama, and more. The tool also supports treesitter highlights and folds for chat buffers.
For similar tasks
tokencost
Tokencost is a clientside tool for calculating the USD cost of using major Large Language Model (LLMs) APIs by estimating the cost of prompts and completions. It helps track the latest price changes of major LLM providers, accurately count prompt tokens before sending OpenAI requests, and easily integrate to get the cost of a prompt or completion with a single function. Users can calculate prompt and completion costs using OpenAI requests, count tokens in prompts formatted as message lists or string prompts, and refer to a cost table with updated prices for various LLM models. The tool also supports callback handlers for LLM wrapper/framework libraries like LlamaIndex and Langchain.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
gigachat
GigaChat is a Python library that allows GigaChain to interact with GigaChat, a neural network model capable of engaging in dialogue, writing code, creating texts, and images on demand. Data exchange with the service is facilitated through the GigaChat API. The library supports processing token streaming, as well as working in synchronous or asynchronous mode. It enables precise token counting in text using the GigaChat API.
client
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.
gemini-cli
gemini-cli is a versatile command-line interface for Google's Gemini LLMs, written in Go. It includes tools for chatting with models, generating/comparing embeddings, and storing data in SQLite for analysis. Users can interact with Gemini models through various subcommands like prompt, chat, counttok, embed content, embed db, and embed similar.
client
Gemini PHP is a PHP API client for interacting with the Gemini AI API. It allows users to generate content, chat, count tokens, configure models, embed resources, list models, get model information, troubleshoot timeouts, and test API responses. The client supports various features such as text-only input, text-and-image input, multi-turn conversations, streaming content generation, token counting, model configuration, and embedding techniques. Users can interact with Gemini's API to perform tasks related to natural language generation and text analysis.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.