
client-ts
TS Client library for Mistral AI platform
Stars: 52
Mistral Typescript Client is an SDK for Mistral AI API, providing Chat Completion and Embeddings APIs. It allows users to create chat completions, upload files, create agent completions, create embedding requests, and more. The SDK supports various JavaScript runtimes and provides detailed documentation on installation, requirements, API key setup, example usage, error handling, server selection, custom HTTP client, authentication, providers support, standalone functions, debugging, and contributions.
README:
Mistral AI API: Our Chat Completion and Embeddings APIs specification. Create your account on La Plateforme to get access and read the docs to learn how to use it.
The SDK can be installed with either npm, pnpm, bun or yarn package managers.
npm add @mistralai/mistralaipnpm add @mistralai/mistralaibun add @mistralai/mistralaiyarn add @mistralai/mistralai zod
# Note that Yarn does not install peer dependencies automatically. You will need
# to install zod as shown above.For supported JavaScript runtimes, please consult RUNTIMES.md.
Before you begin, you will need a Mistral AI API key.
- Get your own Mistral API Key: https://docs.mistral.ai/#api-access
- Set your Mistral API Key as an environment variable. You only need to do this once.
# set Mistral API Key (using zsh for example)
$ echo 'export MISTRAL_API_KEY=[your_key_here]' >> ~/.zshenv
# reload the environment (or just quit and open a new terminal)
$ source ~/.zshenvThis example shows how to create chat completions.
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.chat.complete({
model: "mistral-small-latest",
stream: false,
messages: [
{
content:
"Who is the best French painter? Answer in one short sentence.",
role: "user",
},
],
});
// Handle the result
console.log(result);
}
run();This example shows how to upload a file.
import { Mistral } from "@mistralai/mistralai";
import { openAsBlob } from "node:fs";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.files.upload({
file: await openAsBlob("example.file"),
});
// Handle the result
console.log(result);
}
run();This example shows how to create agents completions.
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.agents.complete({
stream: false,
messages: [
{
content:
"Who is the best French painter? Answer in one short sentence.",
role: "user",
},
],
agentId: "<id>",
});
// Handle the result
console.log(result);
}
run();This example shows how to create embedding request.
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.embeddings.create({
inputs: [
"Embed this sentence.",
"As well as this one.",
],
model: "mistral-embed",
});
// Handle the result
console.log(result);
}
run();We have dedicated SDKs for the following providers:
Available methods
- moderate - Moderations
- moderateChat - Moderations Chat
- create - Embeddings
- upload - Upload File
- list - List Files
- retrieve - Retrieve File
- delete - Delete File
- download - Download File
- getSignedUrl - Get Signed Url
Server-sent events are used to stream content from certain
operations. These operations will expose the stream as an async iterable that
can be consumed using a for await...of loop. The loop will
terminate when the server no longer has any events to send and closes the
underlying connection.
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.chat.stream({
model: "mistral-small-latest",
stream: true,
messages: [
{
content:
"Who is the best French painter? Answer in one short sentence.",
role: "user",
},
],
});
for await (const event of result) {
// Handle the event
console.log(event);
}
}
run();Certain SDK methods accept files as part of a multi-part request. It is possible and typically recommended to upload files as a stream rather than reading the entire contents into memory. This avoids excessive memory consumption and potentially crashing with out-of-memory errors when working with very large files. The following example demonstrates how to attach a file stream to a request.
[!TIP]
Depending on your JavaScript runtime, there are convenient utilities that return a handle to a file without reading the entire contents into memory:
- Node.js v20+: Since v20, Node.js comes with a native
openAsBlobfunction innode:fs.- Bun: The native
Bun.filefunction produces a file handle that can be used for streaming file uploads.- Browsers: All supported browsers return an instance to a
Filewhen reading the value from an<input type="file">element.- Node.js v18: A file stream can be created using the
fileFromhelper fromfetch-blob/from.js.
import { Mistral } from "@mistralai/mistralai";
import { openAsBlob } from "node:fs";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.files.upload({
file: await openAsBlob("example.file"),
});
// Handle the result
console.log(result);
}
run();Some of the endpoints in this SDK support retries. If you use the SDK without any configuration, it will fall back to the default retry strategy provided by the API. However, the default retry strategy can be overridden on a per-operation basis, or across the entire SDK.
To change the default retry strategy for a single API call, simply provide a retryConfig object to the call:
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.models.list({
retries: {
strategy: "backoff",
backoff: {
initialInterval: 1,
maxInterval: 50,
exponent: 1.1,
maxElapsedTime: 100,
},
retryConnectionErrors: false,
},
});
// Handle the result
console.log(result);
}
run();If you'd like to override the default retry strategy for all operations that support retries, you can provide a retryConfig at SDK initialization:
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
retryConfig: {
strategy: "backoff",
backoff: {
initialInterval: 1,
maxInterval: 50,
exponent: 1.1,
maxElapsedTime: 100,
},
retryConnectionErrors: false,
},
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.models.list();
// Handle the result
console.log(result);
}
run();Some methods specify known errors which can be thrown. All the known errors are enumerated in the models/errors/errors.ts module. The known errors for a method are documented under the Errors tables in SDK docs. For example, the list method may throw the following errors:
| Error Type | Status Code | Content Type |
|---|---|---|
| errors.HTTPValidationError | 422 | application/json |
| errors.SDKError | 4XX, 5XX | */* |
If the method throws an error and it is not captured by the known errors, it will default to throwing a SDKError.
import { Mistral } from "@mistralai/mistralai";
import {
HTTPValidationError,
SDKValidationError,
} from "@mistralai/mistralai/models/errors";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
let result;
try {
result = await mistral.models.list();
// Handle the result
console.log(result);
} catch (err) {
switch (true) {
// The server response does not match the expected SDK schema
case (err instanceof SDKValidationError): {
// Pretty-print will provide a human-readable multi-line error message
console.error(err.pretty());
// Raw value may also be inspected
console.error(err.rawValue);
return;
}
case (err instanceof HTTPValidationError): {
// Handle err.data$: HTTPValidationErrorData
console.error(err);
return;
}
default: {
// Other errors such as network errors, see HTTPClientErrors for more details
throw err;
}
}
}
}
run();Validation errors can also occur when either method arguments or data returned from the server do not match the expected format. The SDKValidationError that is thrown as a result will capture the raw value that failed validation in an attribute called rawValue. Additionally, a pretty() method is available on this error that can be used to log a nicely formatted multi-line string since validation errors can list many issues and the plain error string may be difficult read when debugging.
In some rare cases, the SDK can fail to get a response from the server or even make the request due to unexpected circumstances such as network conditions. These types of errors are captured in the models/errors/httpclienterrors.ts module:
| HTTP Client Error | Description |
|---|---|
| RequestAbortedError | HTTP request was aborted by the client |
| RequestTimeoutError | HTTP request timed out due to an AbortSignal signal |
| ConnectionError | HTTP client was unable to make a request to a server |
| InvalidRequestError | Any input used to create a request is invalid |
| UnexpectedClientError | Unrecognised or unexpected error |
You can override the default server globally by passing a server name to the server: keyof typeof ServerList optional parameter when initializing the SDK client instance. The selected server will then be used as the default on the operations that use it. This table lists the names associated with the available servers:
| Name | Server |
|---|---|
eu |
https://api.mistral.ai |
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
server: "eu",
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.models.list();
// Handle the result
console.log(result);
}
run();The default server can also be overridden globally by passing a URL to the serverURL: string optional parameter when initializing the SDK client instance. For example:
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
serverURL: "https://api.mistral.ai",
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.models.list();
// Handle the result
console.log(result);
}
run();The TypeScript SDK makes API calls using an HTTPClient that wraps the native
Fetch API. This
client is a thin wrapper around fetch and provides the ability to attach hooks
around the request lifecycle that can be used to modify the request or handle
errors and response.
The HTTPClient constructor takes an optional fetcher argument that can be
used to integrate a third-party HTTP client or when writing tests to mock out
the HTTP client and feed in fixtures.
The following example shows how to use the "beforeRequest" hook to to add a
custom header and a timeout to requests and how to use the "requestError" hook
to log errors:
import { Mistral } from "@mistralai/mistralai";
import { HTTPClient } from "@mistralai/mistralai/lib/http";
const httpClient = new HTTPClient({
// fetcher takes a function that has the same signature as native `fetch`.
fetcher: (request) => {
return fetch(request);
}
});
httpClient.addHook("beforeRequest", (request) => {
const nextRequest = new Request(request, {
signal: request.signal || AbortSignal.timeout(5000)
});
nextRequest.headers.set("x-custom-header", "custom value");
return nextRequest;
});
httpClient.addHook("requestError", (error, request) => {
console.group("Request Error");
console.log("Reason:", `${error}`);
console.log("Endpoint:", `${request.method} ${request.url}`);
console.groupEnd();
});
const sdk = new Mistral({ httpClient });This SDK supports the following security scheme globally:
| Name | Type | Scheme | Environment Variable |
|---|---|---|---|
apiKey |
http | HTTP Bearer | MISTRAL_API_KEY |
To authenticate with the API the apiKey parameter must be set when initializing the SDK client instance. For example:
import { Mistral } from "@mistralai/mistralai";
const mistral = new Mistral({
apiKey: process.env["MISTRAL_API_KEY"] ?? "",
});
async function run() {
const result = await mistral.models.list();
// Handle the result
console.log(result);
}
run();We also provide provider specific SDK for:
All the methods listed above are available as standalone functions. These functions are ideal for use in applications running in the browser, serverless runtimes or other environments where application bundle size is a primary concern. When using a bundler to build your application, all unused functionality will be either excluded from the final bundle or tree-shaken away.
To read more about standalone functions, check FUNCTIONS.md.
Available standalone functions
-
agentsComplete- Agents Completion -
agentsStream- Stream Agents completion -
batchJobsCancel- Cancel Batch Job -
batchJobsCreate- Create Batch Job -
batchJobsGet- Get Batch Job -
batchJobsList- Get Batch Jobs -
chatComplete- Chat Completion -
chatStream- Stream chat completion -
classifiersModerate- Moderations -
classifiersModerateChat- Moderations Chat -
embeddingsCreate- Embeddings -
filesDelete- Delete File -
filesDownload- Download File -
filesGetSignedUrl- Get Signed Url -
filesList- List Files -
filesRetrieve- Retrieve File -
filesUpload- Upload File -
fimComplete- Fim Completion -
fimStream- Stream fim completion -
fineTuningJobsCancel- Cancel Fine Tuning Job -
fineTuningJobsCreate- Create Fine Tuning Job -
fineTuningJobsGet- Get Fine Tuning Job -
fineTuningJobsList- Get Fine Tuning Jobs -
fineTuningJobsStart- Start Fine Tuning Job -
modelsArchive- Archive Fine Tuned Model -
modelsDelete- Delete Model -
modelsList- List Models -
modelsRetrieve- Retrieve Model -
modelsUnarchive- Unarchive Fine Tuned Model -
modelsUpdate- Update Fine Tuned Model
You can setup your SDK to emit debug logs for SDK requests and responses.
You can pass a logger that matches console's interface as an SDK option.
[!WARNING] Beware that debug logging will reveal secrets, like API tokens in headers, in log messages printed to a console or files. It's recommended to use this feature only during local development and not in production.
import { Mistral } from "@mistralai/mistralai";
const sdk = new Mistral({ debugLogger: console });You can also enable a default debug logger by setting an environment variable MISTRAL_DEBUG to true.
While we value open-source contributions to this SDK, this library is generated programmatically. Any manual changes added to internal files will be overwritten on the next generation. We look forward to hearing your feedback. Feel free to open a PR or an issue with a proof of concept and we'll do our best to include it in a future release.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for client-ts
Similar Open Source Tools
client-ts
Mistral Typescript Client is an SDK for Mistral AI API, providing Chat Completion and Embeddings APIs. It allows users to create chat completions, upload files, create agent completions, create embedding requests, and more. The SDK supports various JavaScript runtimes and provides detailed documentation on installation, requirements, API key setup, example usage, error handling, server selection, custom HTTP client, authentication, providers support, standalone functions, debugging, and contributions.

LocalAGI
LocalAGI is a powerful, self-hostable AI Agent platform that allows you to design AI automations without writing code. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities. With LocalAGI, you can create customizable AI assistants, automations, chat bots, and agents that run 100% locally, without the need for cloud services or API keys. The platform offers features like no-code agents, web-based interface, advanced agent teaming, connectors for various platforms, comprehensive REST API, short & long-term memory capabilities, planning & reasoning, periodic tasks scheduling, memory management, multimodal support, extensible custom actions, fully customizable models, observability, and more.
agentops
AgentOps is a toolkit for evaluating and developing robust and reliable AI agents. It provides benchmarks, observability, and replay analytics to help developers build better agents. AgentOps is open beta and can be signed up for here. Key features of AgentOps include: - Session replays in 3 lines of code: Initialize the AgentOps client and automatically get analytics on every LLM call. - Time travel debugging: (coming soon!) - Agent Arena: (coming soon!) - Callback handlers: AgentOps works seamlessly with applications built using Langchain and LlamaIndex.
daytona
Daytona is a secure and elastic infrastructure tool designed for running AI-generated code. It offers lightning-fast infrastructure with sub-90ms sandbox creation, separated and isolated runtime for executing AI code with zero risk, massive parallelization for concurrent AI workflows, programmatic control through various APIs, unlimited sandbox persistence, and OCI/Docker compatibility. Users can create sandboxes using Python or TypeScript SDKs, run code securely inside the sandbox, and clean up the sandbox after execution. Daytona is open source under the GNU Affero General Public License and welcomes contributions from developers.

onnxruntime-server
ONNX Runtime Server is a server that provides TCP and HTTP/HTTPS REST APIs for ONNX inference. It aims to offer simple, high-performance ML inference and a good developer experience. Users can provide inference APIs for ONNX models without writing additional code by placing the models in the directory structure. Each session can choose between CPU or CUDA, analyze input/output, and provide Swagger API documentation for easy testing. Ready-to-run Docker images are available, making it convenient to deploy the server.

ai00_server
AI00 RWKV Server is an inference API server for the RWKV language model based upon the web-rwkv inference engine. It supports VULKAN parallel and concurrent batched inference and can run on all GPUs that support VULKAN. No need for Nvidia cards!!! AMD cards and even integrated graphics can be accelerated!!! No need for bulky pytorch, CUDA and other runtime environments, it's compact and ready to use out of the box! Compatible with OpenAI's ChatGPT API interface. 100% open source and commercially usable, under the MIT license. If you are looking for a fast, efficient, and easy-to-use LLM API server, then AI00 RWKV Server is your best choice. It can be used for various tasks, including chatbots, text generation, translation, and Q&A.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.

acte
Acte is a framework designed to build GUI-like tools for AI Agents. It aims to address the issues of cognitive load and freedom degrees when interacting with multiple APIs in complex scenarios. By providing a graphical user interface (GUI) for Agents, Acte helps reduce cognitive load and constraints interaction, similar to how humans interact with computers through GUIs. The tool offers APIs for starting new sessions, executing actions, and displaying screens, accessible via HTTP requests or the SessionManager class.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.
x
Ant Design X is a tool for crafting AI-driven interfaces effortlessly. It is built on the best practices of enterprise-level AI products, offering flexible and diverse atomic components for various AI dialogue scenarios. The tool provides out-of-the-box model integration with inference services compatible with OpenAI standards. It also enables efficient management of conversation data flows, supports rich template options, complete TypeScript support, and advanced theme customization. Ant Design X is designed to enhance development efficiency and deliver exceptional AI interaction experiences.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
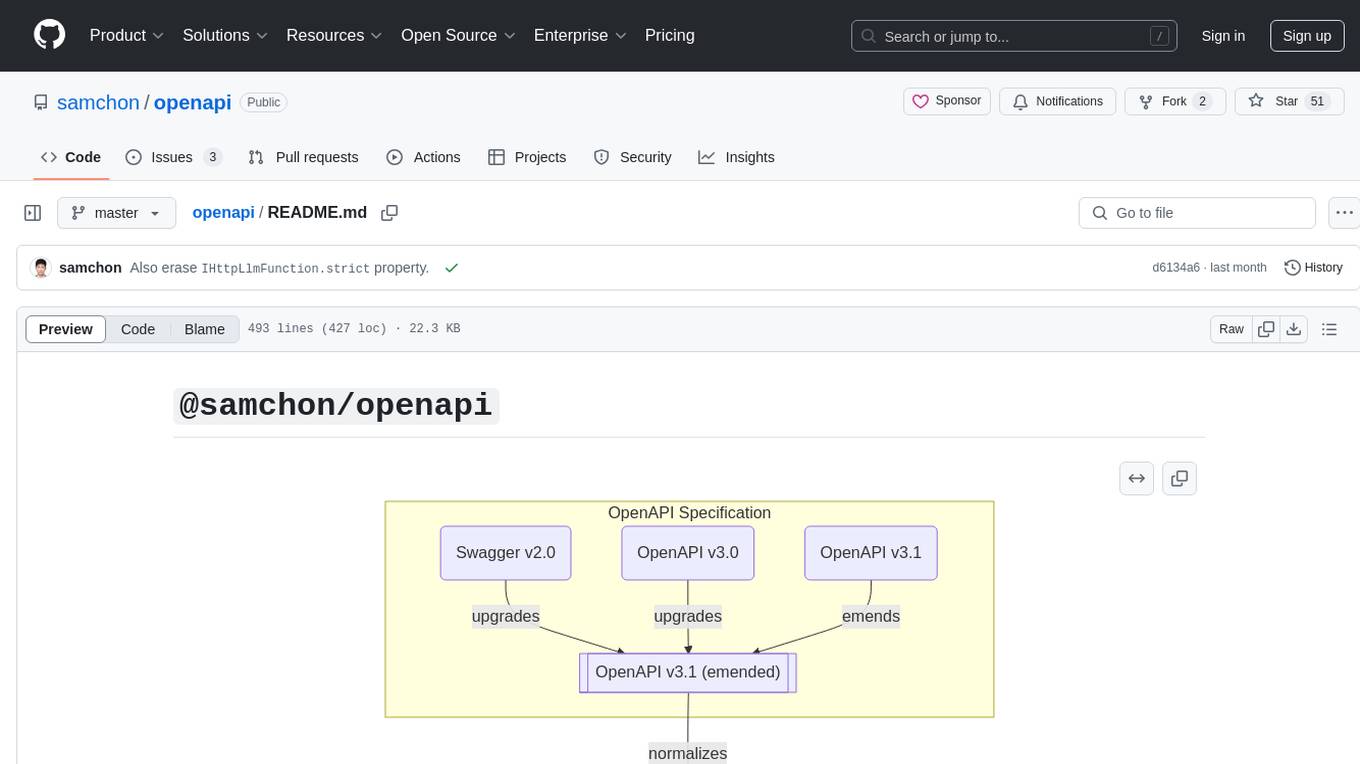
openapi
The `@samchon/openapi` repository is a collection of OpenAPI types and converters for various versions of OpenAPI specifications. It includes an 'emended' OpenAPI v3.1 specification that enhances clarity by removing ambiguous and duplicated expressions. The repository also provides an application composer for LLM (Large Language Model) function calling from OpenAPI documents, allowing users to easily perform LLM function calls based on the Swagger document. Conversions to different versions of OpenAPI documents are also supported, all based on the emended OpenAPI v3.1 specification. Users can validate their OpenAPI documents using the `typia` library with `@samchon/openapi` types, ensuring compliance with standard specifications.
node-sdk
The ChatBotKit Node SDK is a JavaScript-based platform for building conversational AI bots and agents. It offers easy setup, serverless compatibility, modern framework support, customizability, and multi-platform deployment. With capabilities like multi-modal and multi-language support, conversation management, chat history review, custom datasets, and various integrations, this SDK enables users to create advanced chatbots for websites, mobile apps, and messaging platforms.
aiotdlib
aiotdlib is a Python asyncio Telegram client based on TDLib. It provides automatic generation of types and functions from tl schema, validation, good IDE type hinting, and high-level API methods for simpler work with tdlib. The package includes prebuilt TDLib binaries for macOS (arm64) and Debian Bullseye (amd64). Users can use their own binary by passing `library_path` argument to `Client` class constructor. Compatibility with other versions of the library is not guaranteed. The tool requires Python 3.9+ and users need to get their `api_id` and `api_hash` from Telegram docs for installation and usage.
hud-python
hud-python is a Python library for creating interactive heads-up displays (HUDs) in video games. It provides a simple and flexible way to overlay information on the screen, such as player health, score, and notifications. The library is designed to be easy to use and customizable, allowing game developers to enhance the user experience by adding dynamic elements to their games. With hud-python, developers can create engaging HUDs that improve gameplay and provide important feedback to players.
For similar tasks
client-ts
Mistral Typescript Client is an SDK for Mistral AI API, providing Chat Completion and Embeddings APIs. It allows users to create chat completions, upload files, create agent completions, create embedding requests, and more. The SDK supports various JavaScript runtimes and provides detailed documentation on installation, requirements, API key setup, example usage, error handling, server selection, custom HTTP client, authentication, providers support, standalone functions, debugging, and contributions.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.