
jsgrad
jsgrad is a dependency-free ML library in Typescript for model inference and training with support to WebGPU and other runtimes.
Stars: 54
jsgrad is a modern ML library for JavaScript and TypeScript that aims to provide a fast and efficient way to run and train machine learning models. It is a rewrite of tinygrad in TypeScript, offering a clean and modern API with zero dependencies. The library supports multiple runtime backends such as WebGPU, WASM, and CLANG, making it versatile for various applications in browser and server environments. With a focus on simplicity and performance, jsgrad is designed to be easy to use for both model inference and training tasks.
README:
jsgrad is a rewrite of tinygrad in TypeScript. JS ecosystem is very large, but it didn't have a good ML library for model inference and training. Since tinygrad doesn't use any external python libraries, has potential to be the fastest way to run models, is quite simple compared to others and supports many runtimes, I decided to rewrite it in TS to get the same experience in browser and in deno/node/bun.
Why you should use jsgrad?
- 0 dependencies
- will be fast (not yet)
- Multiple runtime backends (WebGPU, WASM, CLANG, + others coming soon)
- Clean, modern API inspired by tinygrad's elegant design
- Works in browser and in Deno (Node and Bun support coming soon)
See MNIST inference and training example on jsgrad.org
There are multiple ways to use jsgrad:
Hosted esm script in JS (minimal Llama HTLM example)
import { MNIST, Tensor } from 'https://esm.sh/jsr/@jsgrad/jsgrad'
const mnist = await new MNIST().load()
console.log(await mnist.call(Tensor.ones([1, 1, 28, 28])).tolist())Install package from jsr.io
# with deno
deno add jsr:@jsgrad/jsgrad
# with npm
npx jsr add @jsgrad/jsgrad
# with yarn
yarn dlx jsr add @jsgrad/jsgrad
# with pnpm
pnpm dlx jsr add @jsgrad/jsgrad
# with bun
bunx jsr add @jsgrad/jsgradand then import with
import { MNIST, Tensor } from '@jsgrad/jsgrad'
const mnist = await new MNIST().load()
console.log(await mnist.call(Tensor.ones([1, 1, 28, 28])).tolist())Soon everything should work like this in browser and server with no install step, while still being fast:
const llama = await new Llama({ model: '3.1-3B' }).load()
const res = await llama.run({ prompt: 'Hello how are you?' })const llama = await new Llama({ model: '3.1-3B', device: 'CLOUD', host: process.env.CLOUD_HOST }).load()
const res = await llama.run({ prompt: 'Hello how are you?' })const whisper = await new Whisper({ model: 'large-v2' }).load()
const listening = whisper.startListening()
// after some time
const text = await listening.stop()const tts = await new TTS()
const audio = await tts.run({ text: 'Hello how are you?' })
audio.play()class MNIST extends Model {
layers: Layer[] = [
new nn.Conv2d(1, 32, 5),
Tensor.relu,
new nn.Conv2d(32, 32, 5),
Tensor.relu,
new nn.BatchNorm(32),
Tensor.max_pool2d,
new nn.Conv2d(32, 64, 3),
Tensor.relu,
new nn.Conv2d(64, 64, 3),
Tensor.relu,
new nn.BatchNorm(64),
Tensor.max_pool2d,
(x) => x.flatten(1),
new nn.Linear(576, 10),
]
}
const [X_train, Y_train, X_test, Y_test] = await mnist()
const model = new MNIST()
const opt = Adam(get_parameters(model))
const train_step = async (): Promise<Tensor> => {
Tensor.training = true
opt.zero_grad()
const samples = Tensor.randint([BS], undefined, X_train.shape[0])
const loss = model.call(X_train.get(samples)).sparse_categorical_crossentropy(Y_train.get(samples)).backward()
await opt.step()
Tensor.training = false
return loss
}
const get_test_acc = (): Tensor => model.call(X_test).argmax(1).eq(Y_test).mean().mul(100)
let test_acc = NaN
const t = new Tqdm(range(get_number_env('STEPS', 70)))
for await (const i of t) {
const loss = await (await train_step()).item()
if (i % 10 === 9) test_acc = await get_test_acc().item()
t.set_description(`loss: ${loss.toFixed(2)}, test_accuracy: ${test_acc.toFixed(2)}`)
}
await model.save('./mnist.safetensors')For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for jsgrad
Similar Open Source Tools
jsgrad
jsgrad is a modern ML library for JavaScript and TypeScript that aims to provide a fast and efficient way to run and train machine learning models. It is a rewrite of tinygrad in TypeScript, offering a clean and modern API with zero dependencies. The library supports multiple runtime backends such as WebGPU, WASM, and CLANG, making it versatile for various applications in browser and server environments. With a focus on simplicity and performance, jsgrad is designed to be easy to use for both model inference and training tasks.

ivy
Ivy is an open-source machine learning framework that enables users to convert code between different ML frameworks and write framework-agnostic code. It allows users to transpile code from one framework to another, making it easy to use building blocks from different frameworks in a single project. Ivy also serves as a flexible framework that breaks free from framework limitations, allowing users to publish code that is interoperable with various frameworks and future frameworks. Users can define trainable modules and layers using Ivy's stateful API, making it easy to build and train models across different backends.

ivy
Ivy is an open-source machine learning framework that enables you to: * 🔄 **Convert code into any framework** : Use and build on top of any model, library, or device by converting any code from one framework to another using `ivy.transpile`. * ⚒️ **Write framework-agnostic code** : Write your code once in `ivy` and then choose the most appropriate ML framework as the backend to leverage all the benefits and tools. Join our growing community 🌍 to connect with people using Ivy. **Let's** unify.ai **together 🦾**

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.
UniChat
UniChat is a pipeline tool for creating online and offline chat-bots in Unity. It leverages Unity.Sentis and text vector embedding technology to enable offline mode text content search based on vector databases. The tool includes a chain toolkit for embedding LLM and Agent in games, along with middleware components for Text to Speech, Speech to Text, and Sub-classifier functionalities. UniChat also offers a tool for invoking tools based on ReActAgent workflow, allowing users to create personalized chat scenarios and character cards. The tool provides a comprehensive solution for designing flexible conversations in games while maintaining developer's ideas.
ai
The Vercel AI SDK is a library for building AI-powered streaming text and chat UIs. It provides React, Svelte, Vue, and Solid helpers for streaming text responses and building chat and completion UIs. The SDK also includes a React Server Components API for streaming Generative UI and first-class support for various AI providers such as OpenAI, Anthropic, Mistral, Perplexity, AWS Bedrock, Azure, Google Gemini, Hugging Face, Fireworks, Cohere, LangChain, Replicate, Ollama, and more. Additionally, it offers Node.js, Serverless, and Edge Runtime support, as well as lifecycle callbacks for saving completed streaming responses to a database in the same request.

js-genai
The Google Gen AI JavaScript SDK is an experimental SDK for TypeScript and JavaScript developers to build applications powered by Gemini. It supports both the Gemini Developer API and Vertex AI. The SDK is designed to work with Gemini 2.0 features. Users can access API features through the GoogleGenAI classes, which provide submodules for querying models, managing caches, creating chats, uploading files, and starting live sessions. The SDK also allows for function calling to interact with external systems. Users can find more samples in the GitHub samples directory.
whetstone.chatgpt
Whetstone.ChatGPT is a simple light-weight library that wraps the Open AI API with support for dependency injection. It supports features like GPT 4, GPT 3.5 Turbo, chat completions, audio transcription and translation, vision completions, files, fine tunes, images, embeddings, moderations, and response streaming. The library provides a video walkthrough of a Blazor web app built on it and includes examples such as a command line bot. It offers quickstarts for dependency injection, chat completions, completions, file handling, fine tuning, image generation, and audio transcription.
bellman
Bellman is a unified interface to interact with language and embedding models, supporting various vendors like VertexAI/Gemini, OpenAI, Anthropic, VoyageAI, and Ollama. It consists of a library for direct interaction with models and a service 'bellmand' for proxying requests with one API key. Bellman simplifies switching between models, vendors, and common tasks like chat, structured data, tools, and binary input. It addresses the lack of official SDKs for major players and differences in APIs, providing a single proxy for handling different models. The library offers clients for different vendors implementing common interfaces for generating and embedding text, enabling easy interchangeability between models.
xsai
xsAI is an extra-small AI SDK designed for Browser, Node.js, Deno, Bun, or Edge Runtime. It provides a series of utils to help users utilize OpenAI or OpenAI-compatible APIs. The SDK is lightweight and efficient, using a variety of methods to minimize its size. It is runtime-agnostic, working seamlessly across different environments without depending on Node.js Built-in Modules. Users can easily install specific utils like generateText or streamText, and leverage tools like weather to perform tasks such as getting the weather in a location.
java-genai
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.
orch
orch is a library for building language model powered applications and agents for the Rust programming language. It can be used for tasks such as text generation, streaming text generation, structured data generation, and embedding generation. The library provides functionalities for executing various language model tasks and can be integrated into different applications and contexts. It offers flexibility for developers to create language model-powered features and applications in Rust.
Ollama
Ollama SDK for .NET is a fully generated C# SDK based on OpenAPI specification using OpenApiGenerator. It supports automatic releases of new preview versions, source generator for defining tools natively through C# interfaces, and all modern .NET features. The SDK provides support for all Ollama API endpoints including chats, embeddings, listing models, pulling and creating new models, and more. It also offers tools for interacting with weather data and providing weather-related information to users.
next-token-prediction
Next-Token Prediction is a language model tool that allows users to create high-quality predictions for the next word, phrase, or pixel based on a body of text. It can be used as an alternative to well-known decoder-only models like GPT and Mistral. The tool provides options for simple usage with built-in data bootstrap or advanced customization by providing training data or creating it from .txt files. It aims to simplify methodologies, provide autocomplete, autocorrect, spell checking, search/lookup functionalities, and create pixel and audio transformers for various prediction formats.

volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.

client-js
The Mistral JavaScript client is a library that allows you to interact with the Mistral AI API. With this client, you can perform various tasks such as listing models, chatting with streaming, chatting without streaming, and generating embeddings. To use the client, you can install it in your project using npm and then set up the client with your API key. Once the client is set up, you can use it to perform the desired tasks. For example, you can use the client to chat with a model by providing a list of messages. The client will then return the response from the model. You can also use the client to generate embeddings for a given input. The embeddings can then be used for various downstream tasks such as clustering or classification.
For similar tasks
LafTools
LafTools is a privacy-first, self-hosted, fully open source toolbox designed for programmers. It offers a wide range of tools, including code generation, translation, encryption, compression, data analysis, and more. LafTools is highly integrated with a productive UI and supports full GPT-alike functionality. It is available as Docker images and portable edition, with desktop edition support planned for the future.
mlc-llm
MLC LLM is a high-performance universal deployment solution that allows native deployment of any large language models with native APIs with compiler acceleration. It supports a wide range of model architectures and variants, including Llama, GPT-NeoX, GPT-J, RWKV, MiniGPT, GPTBigCode, ChatGLM, StableLM, Mistral, and Phi. MLC LLM provides multiple sets of APIs across platforms and environments, including Python API, OpenAI-compatible Rest-API, C++ API, JavaScript API and Web LLM, Swift API for iOS App, and Java API and Android App.

crewAI
crewAI is a cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks. It provides a flexible and structured approach to AI collaboration, enabling users to define agents with specific roles, goals, and tools, and assign them tasks within a customizable process. crewAI supports integration with various LLMs, including OpenAI, and offers features such as autonomous task delegation, flexible task management, and output parsing. It is open-source and welcomes contributions, with a focus on improving the library based on usage data collected through anonymous telemetry.
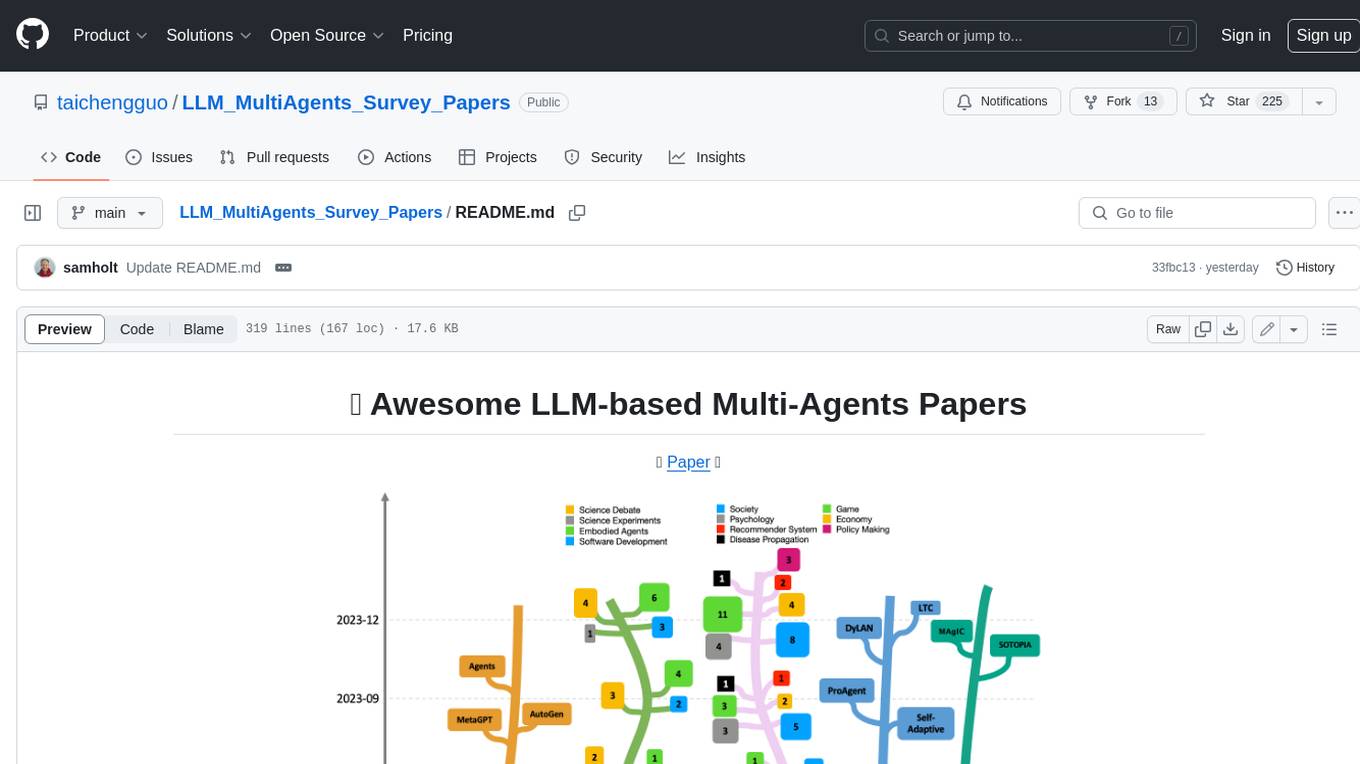
LLM_MultiAgents_Survey_Papers
This repository maintains a list of research papers on LLM-based Multi-Agents, categorized into five main streams: Multi-Agents Framework, Multi-Agents Orchestration and Efficiency, Multi-Agents for Problem Solving, Multi-Agents for World Simulation, and Multi-Agents Datasets and Benchmarks. The repository also includes a survey paper on LLM-based Multi-Agents and a table summarizing the key findings of the survey.
Awesome-LLM-Long-Context-Modeling
This repository includes papers and blogs about Efficient Transformers, Length Extrapolation, Long Term Memory, Retrieval Augmented Generation(RAG), and Evaluation for Long Context Modeling.
llm-rag-vectordb-python
This repository provides sample applications and tutorials to showcase the power of Amazon Bedrock with Python. It helps Python developers understand how to harness Amazon Bedrock in building generative AI-enabled applications. The resources also demonstrate integration with vector databases using RAG (Retrieval-augmented generation) and services like Amazon Aurora, RDS, and OpenSearch. Additionally, it explores using langchain and streamlit to create effective experimental applications.
jsgrad
jsgrad is a modern ML library for JavaScript and TypeScript that aims to provide a fast and efficient way to run and train machine learning models. It is a rewrite of tinygrad in TypeScript, offering a clean and modern API with zero dependencies. The library supports multiple runtime backends such as WebGPU, WASM, and CLANG, making it versatile for various applications in browser and server environments. With a focus on simplicity and performance, jsgrad is designed to be easy to use for both model inference and training tasks.
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.