
Torch-Pruning
[CVPR 2023] Towards Any Structural Pruning; LLMs / SAM / Diffusion / Transformers / YOLOv8 / CNNs
Stars: 2640
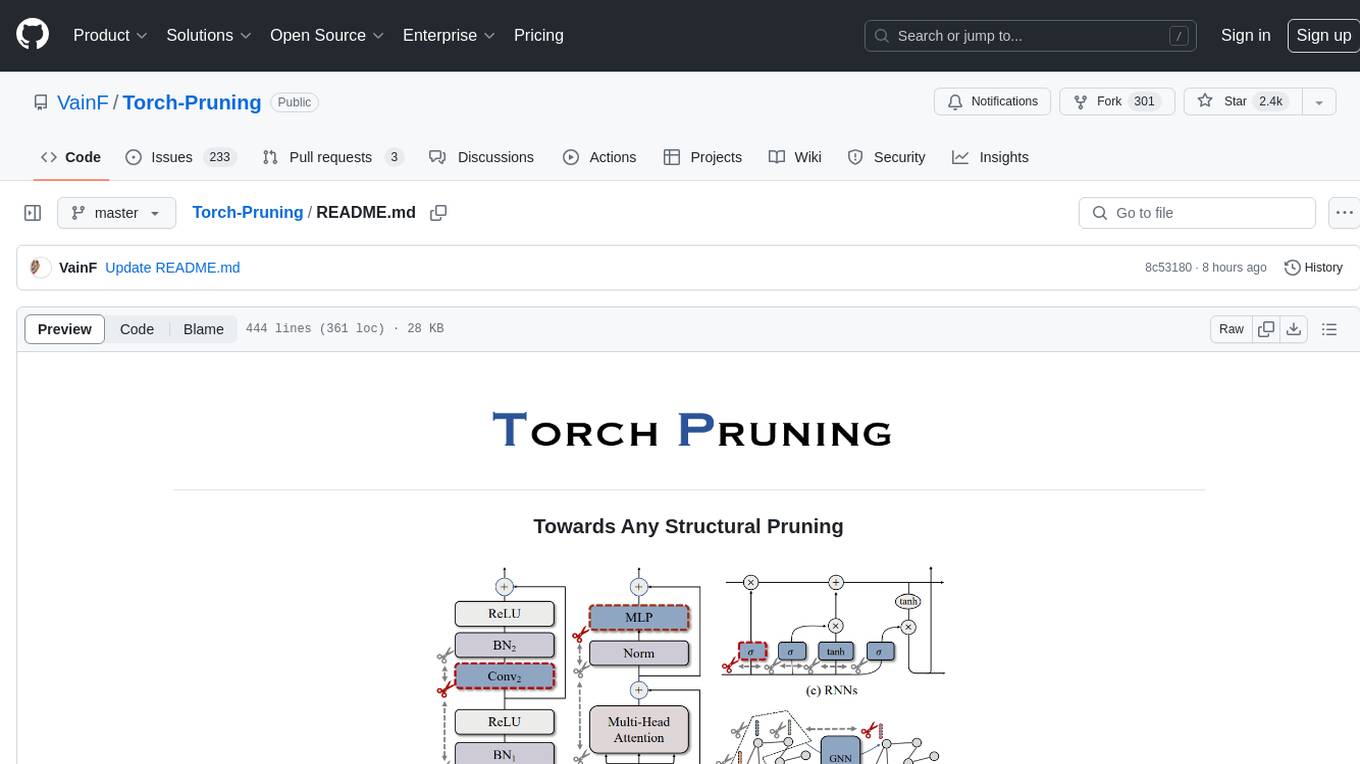
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.
README:


[Documentation & Tutorials] [FAQ]
Torch-Pruning (TP) is designed for structural pruning, facilating the following features:
- General-purpose Pruning Toolkit: TP enables structural pruning for a wide range of deep neural networks, including Large Language Models (LLMs), Segment Anything Model (SAM), Diffusion Models, Vision Transformers, ConvNext, Yolov7, yolov8, Swin Transformers, BERT, FasterRCNN, SSD, ResNe(X)t, DenseNet, RegNet, DeepLab, etc. Different from torch.nn.utils.prune that zeroizes parameters through masking, Torch-Pruning deploys an algorithm called DepGraph to remove parameters physically.
- Examples: Pruning off-the-shelf models from Timm, Huggingface Transformers, Torchvision, Yolo, etc.
- Code for reproducing paper results: Reproduce the our results in the DepGraph paper.
For more technical details, please refer to our CVPR'23 paper:
DepGraph: Towards Any Structural Pruning
Gongfan Fang, Xinyin Ma, Mingli Song, Michael Bi Mi, Xinchao Wang
Learning and Vision Lab, National University of Singapore
- 🔥 2024.09.27 Check our latest work, MaskLLM (NeurIPS 24 Spotlight), for learnable semi-structured sparsity of LLMs.
- 🚀 2024.07.20 Add Isomorphic Pruning (ECCV'24). A SOTA method for Vision Transformers and Modern CNNs.
- ⚡ High-level Pruners: MetaPruner, MagnitudePruner, BNScalePruner, GroupNormPruner, GrowingRegPruner, RandomPruner, etc. A paper list is available here.
- ⚡ Dependency Graph for automatic structural pruning
- ⚡ Low-level pruning functions
- ⚡ Importance Scores: L-p Norm, Taylor, Random, BNScaling, etc.
- ⚡ Supported modules: Linear, (Transposed) Conv, Normalization, PReLU, Embedding, MultiheadAttention, nn.Parameters, customized modules and nested/composed modules.
- ⚡ Supported operators: split, concatenation, skip connection, flatten, reshape, view, all element-wise ops, etc.
- ⚡ Examples, Tutorials and code to reproduce paper results,
Please do not hesitate to open an issue if you encounter any problems with the library or the paper.
Or Join our WeChat group for a chat:
- Installation
- Quickstart
- Citation
Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions. However, PyTorch 2.0+ is highly recommended.
pip install torch-pruning For editable installation:
git clone https://github.com/VainF/Torch-Pruning.git
cd Torch-Pruning && pip install -e .Here we provide a quick start for Torch-Pruning. More explained details can be found in Tutorals
Structural pruning removes a Group of parameters distributed across different layers. Parameters in each group will be coupled due the dependency between layers and thus must be removed simultaneously to maintain the structural integrity of the model. Torch-Pruning implements a mechanism called DependencyGraph to automatically identify dependencies and collect groups for pruning.

Tip: Please make sure that AutoGrad is enabled since TP will analyze the model structure with the Pytorch AutoGrad. This means we need to disable
torch.no_grad()or something similar when building the dependency graph.
import torch
from torchvision.models import resnet18
import torch_pruning as tp
model = resnet18(pretrained=True).eval()
# 1. Build dependency graph for a resnet18. This requires a dummy input for forwarding
DG = tp.DependencyGraph().build_dependency(model, example_inputs=torch.randn(1,3,224,224))
# 2. Get the group for pruning model.conv1 with the specified channel idxs
group = DG.get_pruning_group( model.conv1, tp.prune_conv_out_channels, idxs=[2, 6, 9] )
# 3. Do the pruning
if DG.check_pruning_group(group): # avoid over-pruning, i.e., channels=0.
group.prune()
# 4. Save & Load
model.zero_grad() # clear gradients to avoid a large file size
torch.save(model, 'model.pth') # !! no .state_dict for saving
model = torch.load('model.pth') # load the pruned modelThe above example shows the basic pruning pipeline using DepGraph. The target layer model.conv1 is coupled with multiple layers, necessitating their simultaneous removal in structural pruning. We can print the group to take a look at the internal dependencies. In the subsequent outputs, "A => B" indicates that pruning operation "A" triggers pruning operation "B." The first group[0] refers to the root of pruning. For more details about grouping, please refer to Wiki - DepGraph & Group.
print(group.details()) # or print(group)--------------------------------
Pruning Group
--------------------------------
[0] prune_out_channels on conv1 (Conv2d(3, 61, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)) => prune_out_channels on conv1 (Conv2d(3, 61, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)), idxs (3) =[2, 6, 9] (Pruning Root)
[1] prune_out_channels on conv1 (Conv2d(3, 61, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)) => prune_out_channels on bn1 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)), idxs (3) =[2, 6, 9]
[2] prune_out_channels on bn1 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)) => prune_out_channels on _ElementWiseOp_20(ReluBackward0), idxs (3) =[2, 6, 9]
[3] prune_out_channels on _ElementWiseOp_20(ReluBackward0) => prune_out_channels on _ElementWiseOp_19(MaxPool2DWithIndicesBackward0), idxs (3) =[2, 6, 9]
[4] prune_out_channels on _ElementWiseOp_19(MaxPool2DWithIndicesBackward0) => prune_out_channels on _ElementWiseOp_18(AddBackward0), idxs (3) =[2, 6, 9]
[5] prune_out_channels on _ElementWiseOp_19(MaxPool2DWithIndicesBackward0) => prune_in_channels on layer1.0.conv1 (Conv2d(61, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), idxs (3) =[2, 6, 9]
[6] prune_out_channels on _ElementWiseOp_18(AddBackward0) => prune_out_channels on layer1.0.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)), idxs (3) =[2, 6, 9]
[7] prune_out_channels on _ElementWiseOp_18(AddBackward0) => prune_out_channels on _ElementWiseOp_17(ReluBackward0), idxs (3) =[2, 6, 9]
[8] prune_out_channels on _ElementWiseOp_17(ReluBackward0) => prune_out_channels on _ElementWiseOp_16(AddBackward0), idxs (3) =[2, 6, 9]
[9] prune_out_channels on _ElementWiseOp_17(ReluBackward0) => prune_in_channels on layer1.1.conv1 (Conv2d(61, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), idxs (3) =[2, 6, 9]
[10] prune_out_channels on _ElementWiseOp_16(AddBackward0) => prune_out_channels on layer1.1.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)), idxs (3) =[2, 6, 9]
[11] prune_out_channels on _ElementWiseOp_16(AddBackward0) => prune_out_channels on _ElementWiseOp_15(ReluBackward0), idxs (3) =[2, 6, 9]
[12] prune_out_channels on _ElementWiseOp_15(ReluBackward0) => prune_in_channels on layer2.0.downsample.0 (Conv2d(61, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)), idxs (3) =[2, 6, 9]
[13] prune_out_channels on _ElementWiseOp_15(ReluBackward0) => prune_in_channels on layer2.0.conv1 (Conv2d(61, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)), idxs (3) =[2, 6, 9]
[14] prune_out_channels on layer1.1.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)) => prune_out_channels on layer1.1.conv2 (Conv2d(64, 61, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), idxs (3) =[2, 6, 9]
[15] prune_out_channels on layer1.0.bn2 (BatchNorm2d(61, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)) => prune_out_channels on layer1.0.conv2 (Conv2d(64, 61, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)), idxs (3) =[2, 6, 9]
--------------------------------
There might be many groups in a model. We can use DG.get_all_groups(ignored_layers, root_module_types) to scan all prunable groups sequentially. Each group will begin with a layer that matches nn.Module types in the root_module_types. Note that DG.get_all_groups is only for grouping and does not know which channel/dim should be pruned.
for group in DG.get_all_groups(ignored_layers=[model.conv1], root_module_types=[nn.Conv2d, nn.Linear]):
# Handle groups in sequential order
idxs = [2,4,6] # your pruning indices
group.prune(idxs=idxs)
print(group)With DepGraph, we developed several high-level pruners in this repository to facilitate effortless pruning. By specifying the desired channel pruning ratio, the pruner will scan all prunable groups, estimate weight importance, perform pruning, and fine-tune the remaining weights using your training code. For detailed information on this process, please refer to this tutorial, which shows how to implement a Network Slimming (ICCV 2017) pruner from scratch. Additionally, a more practical example is available in VainF/Isomorphic-Pruning.
import torch
from torchvision.models import resnet18
import torch_pruning as tp
model = resnet18(pretrained=True)
example_inputs = torch.randn(1, 3, 224, 224)
# 1. Importance criterion
imp = tp.importance.GroupNormImportance(p=2) # or GroupTaylorImportance(), GroupHessianImportance(), etc.
# 2. Initialize a pruner with the model and the importance criterion
ignored_layers = []
for m in model.modules():
if isinstance(m, torch.nn.Linear) and m.out_features == 1000:
ignored_layers.append(m) # DO NOT prune the final classifier!
pruner = tp.pruner.MetaPruner( # We can always choose MetaPruner if sparse training is not required.
model,
example_inputs,
importance=imp,
pruning_ratio=0.5, # remove 50% channels, ResNet18 = {64, 128, 256, 512} => ResNet18_Half = {32, 64, 128, 256}
# pruning_ratio_dict = {model.conv1: 0.2, model.layer2: 0.8}, # customized pruning ratios for layers or blocks
ignored_layers=ignored_layers,
)
# 3. Prune & finetune the model
base_macs, base_nparams = tp.utils.count_ops_and_params(model, example_inputs)
pruner.step()
macs, nparams = tp.utils.count_ops_and_params(model, example_inputs)
print(f"MACs: {base_macs/1e9} G -> {macs/1e9} G, #Params: {base_nparams/1e6} M -> {nparams/1e6} M")
# finetune the pruned model here
# finetune(model)
# ...# Note: In TP, pruning ratio means channel pruning ratio.
# Since both in & out channels will be removed by p%,
# the corresponding parameter pruning ratio will be roughly 1-(1-p%)^2.
# In this example, 3.06 ~= 11.69 * (1-0.5)^2 = 2.92
MACs: 1.822177768 G -> 0.487202536 G, #Params: 11.689512 M -> 3.05588 M
Global pruning performs importance ranking across all layers, which has the potential to find better structures. This can be easily achieved by setting global_pruning=True in the pruner. While this strategy can possibly offer performance advantages, it also carries the potential of overly pruning specific layers, resulting in a substantial decline in overall performance. We provide an alternative algorithm called Isomorphic Pruning to alleviate this issue, which can be enabled with isomorphic=True. Comprehensive examples for ViT & ConvNext pruning are available in this project.
pruner = tp.pruner.MetaPruner(
...
isomorphic=True, # enable isomorphic pruning to improve global ranking
global_pruning=True, # global pruning
)
The default pruning ratio can be set by pruning_ratio. If you want to customize the pruning ratio for some layers or blocks, you can use pruning_ratio_dict. The key of the dict can be an nn.Module or a tuple of nn.Module. In the second case, all modules in the tuple will form a scope and share the pruning ratio. Global ranking will be performed in this scope. This is also the core idea of Isomorphic Pruning.
pruner = tp.pruner.MetaPruner(
...
global_pruning=True,
pruning_ratio=0.5, # default pruning ratio
pruning_ratio_dict = {(model.layer1, model.layer2): 0.4, model.layer3: 0.2},
# Global pruning will be performed on layer1 and layer2
)Some pruners like BNScalePruner and GroupNormPruner support sparse training. This can be easily achieved by inserting pruner.update_regularizer() and pruner.regularize(model) in your standard training loops. The pruner will accumulate the regularization gradients to .grad. Sparse training is optional and may be expensive for pruning.
for epoch in range(epochs):
model.train()
pruner.update_regularizer() # <== initialize regularizer
for i, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
out = model(data)
loss = F.cross_entropy(out, target)
loss.backward() # after loss.backward()
pruner.regularize(model) # <== for sparse training
optimizer.step() # before optimizer.step()All high-level pruners offer support for interactive pruning. You can utilize the method pruner.step(interactive=True) to retrieve all the groups and interactively prune them by calling group.prune(). This feature is particularly useful if you want to control or monitor the pruning process.
for i in range(iterative_steps):
for group in pruner.step(interactive=True): # Warning: groups must be handled sequentially. Do not keep them as a list.
print(group)
# do whatever you like with the group
dep, idxs = group[0] # get the idxs
target_module = dep.target.module # get the root module
pruning_fn = dep.handler # get the pruning function
group.prune()
# group.prune(idxs=[0, 2, 6]) # It is even possible to change the pruning behaviour with the idxs parameter
macs, nparams = tp.utils.count_ops_and_params(model, example_inputs)
# finetune your model here
# finetune(model)
# ...It is easy to implement Soft Pruning leveraging interactive=True, which zeros out parameters without removing them. An example can be found in tests/test_soft_pruning.py
With DepGraph, it is easy to design some "group-level" importance scores to estimate the importance of a whole group rather than a single layer. This feature can be also used to sparsify coupled layers, making all the to-be-pruned parameters consistently sparse. In Torch-pruning, all pruners work at the group level. Check the following results to see how grouping improves the performance of pruning.

- Pruning a ResNet50 pre-trained on ImageNet-1K without fine-tuning.
- Pruning a Vision Transformer pre-trained on ImageNet-1K without fine-tuning.
In some implementations, model forwarding might rely on some static attributes. For example in convformer_s18 of timm, we have self.shape which will be changed after pruning. These attributes should be updated manually since it is impossible for TP to know the purpose of these attributes.
class Scale(nn.Module):
"""
Scale vector by element multiplications.
"""
def __init__(self, dim, init_value=1.0, trainable=True, use_nchw=True):
super().__init__()
self.shape = (dim, 1, 1) if use_nchw else (dim,) # static shape, which should be updated after pruning
self.scale = nn.Parameter(init_value * torch.ones(dim), requires_grad=trainable)
def forward(self, x):
return x * self.scale.view(self.shape) # => x * self.scale.view(-1, 1, 1), this works for pruningThe following script saves the whole model object (structure+weights) as a 'model.pth'. You can load it using the standard PyTorch API. Just remember that we save and load the whole model without .state_dict or .load_state_dict. This is because the pruned model will have a different structure after pruning from the original definition in your model.py.
model.zero_grad() # Remove gradients
torch.save(model, 'model.pth') # without .state_dict
model = torch.load('model.pth') # load the pruned modelIn Torch-Pruning, we provide a series of low-level pruning functions that only prune a single layer or module. To manually prune the model.conv1 of a ResNet-18, the pruning pipeline should look like this:
tp.prune_conv_out_channels( model.conv1, idxs=[2,6,9] )
# fix the broken dependencies manually
tp.prune_batchnorm_out_channels( model.bn1, idxs=[2,6,9] )
tp.prune_conv_in_channels( model.layer2[0].conv1, idxs=[2,6,9] )
...The following pruning functions are available:
'prune_conv_out_channels',
'prune_conv_in_channels',
'prune_depthwise_conv_out_channels',
'prune_depthwise_conv_in_channels',
'prune_batchnorm_out_channels',
'prune_batchnorm_in_channels',
'prune_linear_out_channels',
'prune_linear_in_channels',
'prune_prelu_out_channels',
'prune_prelu_in_channels',
'prune_layernorm_out_channels',
'prune_layernorm_in_channels',
'prune_embedding_out_channels',
'prune_embedding_in_channels',
'prune_parameter_out_channels',
'prune_parameter_in_channels',
'prune_multihead_attention_out_channels',
'prune_multihead_attention_in_channels',
'prune_groupnorm_out_channels',
'prune_groupnorm_in_channels',
'prune_instancenorm_out_channels',
'prune_instancenorm_in_channels',Please refer to examples/transformers/prune_hf_swin.py, which implements a new pruner for the customized module SwinPatchMerging. Another simple example is available at tests/test_customized_layer.py.
Please see reproduce.
| Method | Base (%) | Pruned (%) | $\Delta$ Acc (%) | Speed Up |
|---|---|---|---|---|
| NIPS [1] | - | - | -0.03 | 1.76x |
| Geometric [2] | 93.59 | 93.26 | -0.33 | 1.70x |
| Polar [3] | 93.80 | 93.83 | +0.03 | 1.88x |
| CP [4] | 92.80 | 91.80 | -1.00 | 2.00x |
| AMC [5] | 92.80 | 91.90 | -0.90 | 2.00x |
| HRank [6] | 93.26 | 92.17 | -0.09 | 2.00x |
| SFP [7] | 93.59 | 93.36 | +0.23 | 2.11x |
| ResRep [8] | 93.71 | 93.71 | +0.00 | 2.12x |
| Ours-L1 | 93.53 | 92.93 | -0.60 | 2.12x |
| Ours-BN | 93.53 | 93.29 | -0.24 | 2.12x |
| Ours-Group | 93.53 | 93.77 | +0.38 | 2.13x |
Latency test on ResNet-50, Batch Size=64.
[Iter 0] Pruning ratio: 0.00, MACs: 4.12 G, Params: 25.56 M, Latency: 45.22 ms +- 0.03 ms
[Iter 1] Pruning ratio: 0.05, MACs: 3.68 G, Params: 22.97 M, Latency: 46.53 ms +- 0.06 ms
[Iter 2] Pruning ratio: 0.10, MACs: 3.31 G, Params: 20.63 M, Latency: 43.85 ms +- 0.08 ms
[Iter 3] Pruning ratio: 0.15, MACs: 2.97 G, Params: 18.36 M, Latency: 41.22 ms +- 0.10 ms
[Iter 4] Pruning ratio: 0.20, MACs: 2.63 G, Params: 16.27 M, Latency: 39.28 ms +- 0.20 ms
[Iter 5] Pruning ratio: 0.25, MACs: 2.35 G, Params: 14.39 M, Latency: 34.60 ms +- 0.19 ms
[Iter 6] Pruning ratio: 0.30, MACs: 2.02 G, Params: 12.46 M, Latency: 33.38 ms +- 0.27 ms
[Iter 7] Pruning ratio: 0.35, MACs: 1.74 G, Params: 10.75 M, Latency: 31.46 ms +- 0.20 ms
[Iter 8] Pruning ratio: 0.40, MACs: 1.50 G, Params: 9.14 M, Latency: 29.04 ms +- 0.19 ms
[Iter 9] Pruning ratio: 0.45, MACs: 1.26 G, Params: 7.68 M, Latency: 27.47 ms +- 0.28 ms
[Iter 10] Pruning ratio: 0.50, MACs: 1.07 G, Params: 6.41 M, Latency: 20.68 ms +- 0.13 ms
[Iter 11] Pruning ratio: 0.55, MACs: 0.85 G, Params: 5.14 M, Latency: 20.48 ms +- 0.21 ms
[Iter 12] Pruning ratio: 0.60, MACs: 0.67 G, Params: 4.07 M, Latency: 18.12 ms +- 0.15 ms
[Iter 13] Pruning ratio: 0.65, MACs: 0.53 G, Params: 3.10 M, Latency: 15.19 ms +- 0.01 ms
[Iter 14] Pruning ratio: 0.70, MACs: 0.39 G, Params: 2.28 M, Latency: 13.47 ms +- 0.01 ms
[Iter 15] Pruning ratio: 0.75, MACs: 0.29 G, Params: 1.61 M, Latency: 10.07 ms +- 0.01 ms
[Iter 16] Pruning ratio: 0.80, MACs: 0.18 G, Params: 1.01 M, Latency: 8.96 ms +- 0.02 ms
[Iter 17] Pruning ratio: 0.85, MACs: 0.10 G, Params: 0.57 M, Latency: 7.03 ms +- 0.04 ms
[Iter 18] Pruning ratio: 0.90, MACs: 0.05 G, Params: 0.25 M, Latency: 5.81 ms +- 0.03 ms
[Iter 19] Pruning ratio: 0.95, MACs: 0.01 G, Params: 0.06 M, Latency: 5.70 ms +- 0.03 ms
[Iter 20] Pruning ratio: 1.00, MACs: 0.01 G, Params: 0.06 M, Latency: 5.71 ms +- 0.03 ms
DepGraph: Towards Any Structural Pruning [Project] [Paper]
Gongfan Fang, Xinyin Ma, Mingli Song, Michael Bi Mi, Xinchao Wang
CVPR 2023
Isomorphic Pruning for Vision Models [Project] [Arxiv]
Gongfan Fang, Xinyin Ma, Michael Bi Mi, Xinchao Wang
ECCV 2024
LLM-Pruner: On the Structural Pruning of Large Language Models [Project] [arXiv]
Xinyin Ma, Gongfan Fang, Xinchao Wang
NeurIPS 2023
Structural Pruning for Diffusion Models [Project] [arxiv]
Gongfan Fang, Xinyin Ma, Xinchao Wang
NeurIPS 2023
DeepCache: Accelerating Diffusion Models for Free [Project] [Arxiv]
Xinyin Ma, Gongfan Fang, and Xinchao Wang
CVPR 2024
SlimSAM: 0.1% Data Makes Segment Anything Slim [Project] [Arxiv]
Zigeng Chen, Gongfan Fang, Xinyin Ma, Xinchao Wang
Preprint 2023
@inproceedings{fang2023depgraph,
title={Depgraph: Towards any structural pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={16091--16101},
year={2023}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Torch-Pruning
Similar Open Source Tools
Torch-Pruning
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.
map-anything
MapAnything is an end-to-end trained transformer model for 3D reconstruction tasks, supporting over 12 different tasks including multi-image sfm, multi-view stereo, monocular metric depth estimation, and more. It provides a simple and efficient way to regress the factored metric 3D geometry of a scene from various inputs like images, calibration, poses, or depth. The tool offers flexibility in combining different geometric inputs for enhanced reconstruction results. It includes interactive demos, support for COLMAP & GSplat, data processing for training & benchmarking, and pre-trained models on Hugging Face Hub with different licensing options.
matmulfreellm
MatMul-Free LM is a language model architecture that eliminates the need for Matrix Multiplication (MatMul) operations. This repository provides an implementation of MatMul-Free LM that is compatible with the 🤗 Transformers library. It evaluates how the scaling law fits to different parameter models and compares the efficiency of the architecture in leveraging additional compute to improve performance. The repo includes pre-trained models, model implementations compatible with 🤗 Transformers library, and generation examples for text using the 🤗 text generation APIs.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.

pycm
PyCM is a Python library for multi-class confusion matrices, providing support for input data vectors and direct matrices. It is a comprehensive tool for post-classification model evaluation, offering a wide range of metrics for predictive models and accurate evaluation of various classifiers. PyCM is designed for data scientists who require diverse metrics for their models.
DeepMesh
DeepMesh is an auto-regressive artist-mesh creation tool that utilizes reinforcement learning to generate high-quality meshes conditioned on a given point cloud. It offers pretrained weights and allows users to generate obj/ply files based on specific input parameters. The tool has been tested on Ubuntu 22 with CUDA 11.8 and supports A100, A800, and A6000 GPUs. Users can clone the repository, create a conda environment, install pretrained model weights, and use command line inference to generate meshes.
dom-to-semantic-markdown
DOM to Semantic Markdown is a tool that converts HTML DOM to Semantic Markdown for use in Large Language Models (LLMs). It maximizes semantic information, token efficiency, and preserves metadata to enhance LLMs' processing capabilities. The tool captures rich web content structure, including semantic tags, image metadata, table structures, and link destinations. It offers customizable conversion options and supports both browser and Node.js environments.
netsaur
Netsaur is a powerful machine learning library for Deno, offering a lightweight and easy-to-use neural network solution. It is blazingly fast and efficient, providing a simple API for creating and training neural networks. Netsaur can run on both CPU and GPU, making it suitable for serverless environments. With Netsaur, users can quickly build and deploy machine learning models for various applications with minimal dependencies. This library is perfect for both beginners and experienced machine learning practitioners.
aiscript
AiScript is a lightweight scripting language that runs on JavaScript. It supports arrays, objects, and functions as first-class citizens, and is easy to write without the need for semicolons or commas. AiScript runs in a secure sandbox environment, preventing infinite loops from freezing the host. It also allows for easy provision of variables and functions from the host.
prajna
Prajna is an open-source programming language specifically developed for building more modular, automated, and intelligent artificial intelligence infrastructure. It aims to cater to various stages of AI research, training, and deployment by providing easy access to CPU, GPU, and various TPUs for AI computing. Prajna features just-in-time compilation, GPU/heterogeneous programming support, tensor computing, syntax improvements, and user-friendly interactions through main functions, Repl, and Jupyter, making it suitable for algorithm development and deployment in various scenarios.
ExplainableAI.jl
ExplainableAI.jl is a Julia package that implements interpretability methods for black-box classifiers, focusing on local explanations and attribution maps in input space. The package requires models to be differentiable with Zygote.jl. It is similar to Captum and Zennit for PyTorch and iNNvestigate for Keras models. Users can analyze and visualize explanations for model predictions, with support for different XAI methods and customization. The package aims to provide transparency and insights into model decision-making processes, making it a valuable tool for understanding and validating machine learning models.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.
superagentx
SuperAgentX is a lightweight open-source AI framework designed for multi-agent applications with Artificial General Intelligence (AGI) capabilities. It offers goal-oriented multi-agents with retry mechanisms, easy deployment through WebSocket, RESTful API, and IO console interfaces, streamlined architecture with no major dependencies, contextual memory using SQL + Vector databases, flexible LLM configuration supporting various Gen AI models, and extendable handlers for integration with diverse APIs and data sources. It aims to accelerate the development of AGI by providing a powerful platform for building autonomous AI agents capable of executing complex tasks with minimal human intervention.
Remote-MCP
Remote-MCP is a type-safe, bidirectional, and simple solution for remote MCP communication, enabling remote access and centralized management of model contexts. It provides a bridge for immediate remote access to a remote MCP server from a local MCP client, without waiting for future official implementations. The repository contains client and server libraries for creating and connecting to remotely accessible MCP services. The core features include basic type-safe client/server communication, MCP command/tool/prompt support, custom headers, and ongoing work on crash-safe handling and event subscription system.
For similar tasks
Torch-Pruning
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.