
Tutel
Tutel MoE: An Optimized Mixture-of-Experts Implementation
Stars: 785
Tutel MoE is an optimized Mixture-of-Experts implementation that offers a parallel solution with 'No-penalty Parallism/Sparsity/Capacity/Switching' for modern training and inference. It supports Pytorch framework (version >= 1.10) and various GPUs including CUDA and ROCm. The tool enables Full Precision Inference of MoE-based Deepseek R1 671B on AMD MI300. Tutel provides features like all-to-all benchmarking, tensorcore option, NCCL timeout settings, Megablocks solution, and dynamic switchable configurations. Users can run Tutel in distributed mode across multiple GPUs and machines. The tool allows for custom MoE implementations and offers detailed usage examples and reference documentation.
README:
Tutel MoE: An Optimized Mixture-of-Experts Implementation, also the first parallel solution proposing "No-penalty Parallism/Sparsity/Capacity/.. Switching" for modern training and inference that have dynamic behaviors.
- Supported Framework: Pytorch (recommend: >= 1.10)
- Supported GPUs: CUDA(fp64/fp32/fp16/bfp16), ROCm(fp64/fp32/fp16)
- Supported CPU: fp64/fp32
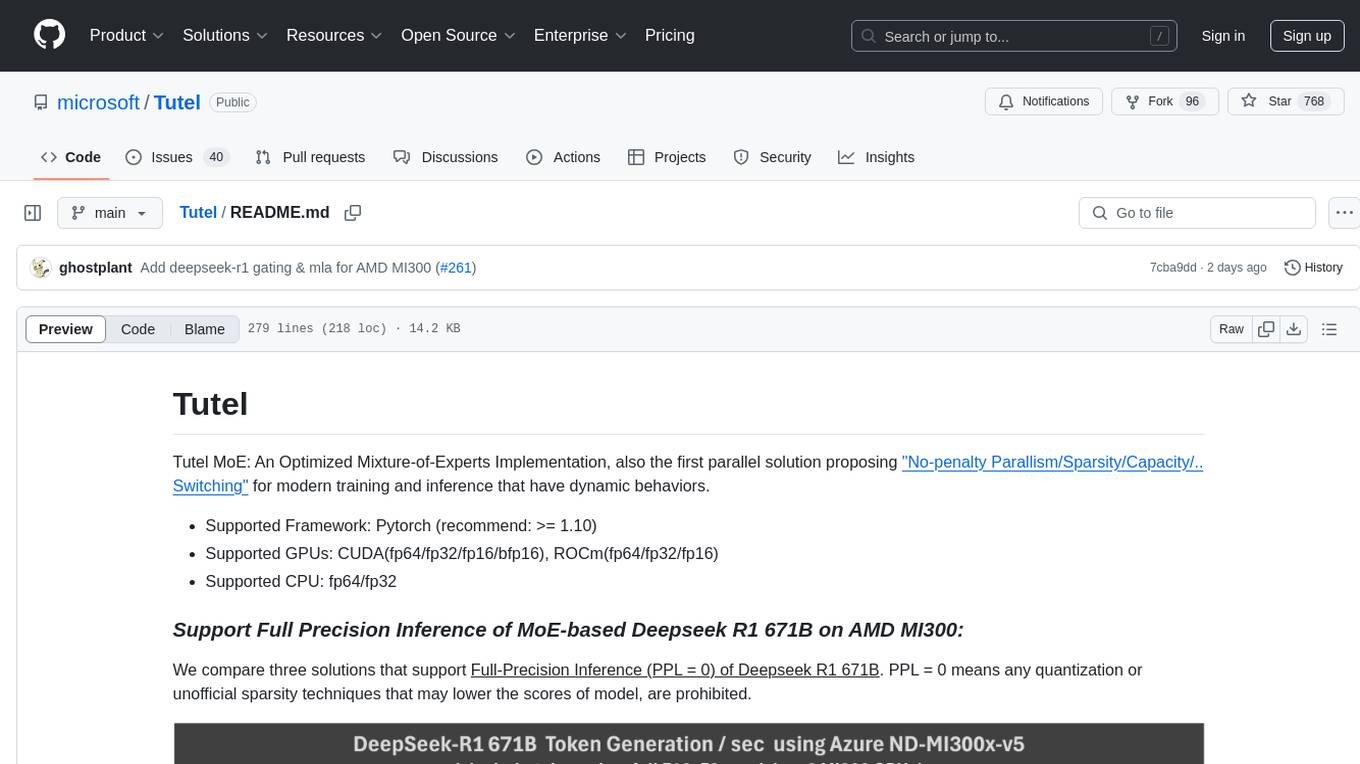
We compare three solutions that support Full-Precision Inference (PPL = 0) of Deepseek R1 671B. PPL = 0 means any quantization or unofficial sparsity techniques that may lower the scores of model, are prohibited.

- Tutel v0.4.0: Accelerating Deepseek R1 Full-precision-Chat for AMD MI300x8 (more platform support will be added in later versions):
>> Example:
# Step-1: Download Deepseek R1 671B Model
huggingface-cli download deepseek-ai/DeepSeek-R1 --local-dir ./deepseek-ai/DeepSeek-R1
# Step-2: Using 8 MI300 GPUs to Run Deepseek R1 Chat with Full Precision (PPL = 0)
docker run -it --rm --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --privileged \
-v /:/host -w /host$(pwd) tutelgroup/deepseek-671b:mi300x8-fp16xfp8 \
--model_path ./deepseek-ai/DeepSeek-R1 \
--prompt "Calculate the result of: 1 / (sqrt(5) - sqrt(3))"
# Step-3: Using 8 MI300 GPUs to Serve Deepseek R1 Chat on Local Port :8000
docker run -it --rm --ipc=host --privileged -p 8000:8000 \
-v /:/host -w /host$(pwd) tutelgroup/deepseek-671b:mi300x8-chat-20250224 \
--model_path ./deepseek-ai/DeepSeek-R1
# Step-4: Issue a Prompt Request with curl
curl -X POST http://0.0.0.0:8000/chat -d '{"text": "求1/sin(x) + x的不定积分"}'
- Tutel v0.3.3: Add all-to-all benchmark:
>> Example:
python3 -m torch.distributed.run --nproc_per_node=8 -m tutel.examples.bandwidth_test --size_mb=256- Tutel v0.3.2: Add tensorcore option for extra benchmarks / Extend the example for custom experts / Allow NCCL timeout settings:
>> Example of using tensorcore:
python3 -m tutel.examples.helloworld --dtype=float32
python3 -m tutel.examples.helloworld --dtype=float32 --use_tensorcore
python3 -m tutel.examples.helloworld --dtype=float16
python3 -m tutel.examples.helloworld --dtype=float16 --use_tensorcore
>> Example of custom gates/experts:
python3 -m tutel.examples.helloworld_custom_gate_expert --batch_size=16
>> Example of NCCL timeout settings:
TUTEL_GLOBAL_TIMEOUT_SEC=60 python3 -m torch.distributed.run --nproc_per_node=8 -m tutel.examples.helloworld --use_tensorcore
- Tutel v0.3.1: Add NCCL all_to_all_v and all_gather_v for arbitrary-length message transfers:
>> Example:
# All_to_All_v:
python3 -m torch.distributed.run --nproc_per_node=2 --master_port=7340 -m tutel.examples.nccl_all_to_all_v
# All_Gather_v:
python3 -m torch.distributed.run --nproc_per_node=2 --master_port=7340 -m tutel.examples.nccl_all_gather_v
>> How to:
net.batch_all_to_all_v([t_x_cuda, t_y_cuda, ..], common_send_counts)
net.batch_all_gather_v([t_x_cuda, t_y_cuda, ..])- Tutel v0.3: Add Megablocks solution to improve decoder inference on single-GPU with num_local_expert >= 2:
>> Example (capacity_factor=0 required by dropless-MoE):
# Using BatchMatmul:
python3 -m tutel.examples.helloworld --megablocks_size=0 --batch_size=1 --num_tokens=32 --top=1 --eval --num_local_experts=128 --capacity_factor=0
# Using Megablocks with block_size = 1:
python3 -m tutel.examples.helloworld --megablocks_size=1 --batch_size=1 --num_tokens=32 --top=1 --eval --num_local_experts=128 --capacity_factor=0
# Using Megablocks with block_size = 2:
python3 -m tutel.examples.helloworld --megablocks_size=2 --batch_size=1 --num_tokens=32 --top=1 --eval --num_local_experts=128 --capacity_factor=0
>> How to:
self._moe_layer.forward(x, .., megablocks_size=1) # Control the switch of megablocks_size (0 for disabled)- Tutel v0.2: Allow most configurations to be dynamic switchable with free cost:
>> Example:
python3 -m torch.distributed.run --nproc_per_node=8 -m tutel.examples.helloworld_switch --batch_size=16
>> How to:
self._moe_layer.forward(x, .., a2a_ffn_overlap_degree=2) # Control the switch of overlap granularity (1 for no overlapping)
self._moe_layer.forward(x, .., adaptive_r=1) # Control the switch of parallelism (0 for DP, 1 for DP + EP, W / E for MP + EP, else for DP + MP + EP)
self._moe_layer.forward(x, .., capacity_factor=1) # Control the switch of capacity_volume (positive for padding, negative for no-padding, 0 for dropless)
self._moe_layer.forward(x, .., top_k=1) # Control the switch of top_k sparsity- Tutel v0.1: Optimize the Einsum Complexity of Data Dispatch Encoding and Decoding, add 2DH option to deal with All-to-All at scale:
>> Example (suggest enabling 2DH only at scale, note that the value of --nproc_per_node MUST equal to total physical GPU counts per node, e.g. 8 for A100x8):
python3 -m torch.distributed.run --nproc_per_node=8 -m tutel.examples.helloworld --batch_size=16 --use_2dh* Prepare Recommended Pytorch >= 2.0.0:
# Windows/Linux Pytorch for NVIDIA CUDA >= 11.7:
python3 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Linux Pytorch for AMD ROCm >= 6.2.2:
python3 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.2.2
# Windows/Linux Pytorch for CPU:
python3 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
* Option-1: Install Tutel Online:
$ python3 -m pip uninstall tutel -y
$ python3 -m pip install -v -U --no-build-isolation git+https://github.com/microsoft/tutel@main
* Option-2: Build Tutel from Source:
$ git clone https://github.com/microsoft/tutel --branch main
$ python3 -m pip uninstall tutel -y
$ python3 ./tutel/setup.py install --user
* Quick Test on Single-GPU:
$ python3 -m tutel.examples.helloworld --batch_size=16 # Test Tutel-optimized MoE + manual distribution
$ python3 -m tutel.examples.helloworld_ddp --batch_size=16 # Test Tutel-optimized MoE + Pytorch DDP distribution (requires: Pytorch >= 1.8.0)
$ python3 -m tutel.examples.helloworld_ddp_tutel --batch_size=16 # Test Tutel-optimized MoE + Tutel DDP distribution (ZeRO on optimizors)
$ python3 -m tutel.examples.helloworld_amp --batch_size=16 # Test Tutel-optimized MoE with AMP data type + manual distribution
$ python3 -m tutel.examples.helloworld_custom_gate_expert --batch_size=16 # Test Tutel-optimized MoE + custom defined gate/expert layer
$ python3 -m tutel.examples.helloworld_from_scratch # Test Custom MoE implementation from scratch
$ python3 -m tutel.examples.moe_mnist # Test MoE layer in end-to-end MNIST dataset
$ python3 -m tutel.examples.moe_cifar10 # Test MoE layer in end-to-end CIFAR10 dataset
(If building from source, the following method also works:)
$ python3 ./tutel/examples/helloworld.py --batch_size=16
..
$ python3 -m torch.distributed.run --nproc_per_node=8 -m tutel.examples.helloworld --batch_size=16
* Run Tutel MoE in Distributed Mode:
(Option A - Torch launcher for `Multi-Node x Multi-GPU`:)
$ ssh <node-ip-0> python3 -m torch.distributed.run --nproc_per_node=8 --nnodes=2 --node_rank=0 --master_addr=<node-ip-0> -m tutel.examples.helloworld --batch_size=16
$ ssh <node-ip-1> python3 -m torch.distributed.run --nproc_per_node=8 --nnodes=2 --node_rank=1 --master_addr=<node-ip-0> -m tutel.examples.helloworld --batch_size=16
(Option B - Tutel launcher for `Multi-Node x Multi-GPU`, requiring package `openmpi-bin`:)
# << Single Node >>
$ mpiexec -bind-to none -host localhost -x LOCAL_SIZE=8 python3 -m tutel.launcher.run -m tutel.examples.helloworld_ddp_tutel --batch_size=16
$ mpiexec -bind-to none -host localhost -x LOCAL_SIZE=8 python3 -m tutel.launcher.run -m tutel.examples.moe_mnist
$ mpiexec -bind-to none -host localhost -x LOCAL_SIZE=8 python3 -m tutel.launcher.run -m tutel.examples.moe_cifar10
...
# << MPI-based launch for GPU backend>>
$ mpiexec -bind-to none -host <node-ip-0>,<node-ip-1>,.. -x MASTER_ADDR=<node-ip-0> -x LOCAL_SIZE=8 python3 -m tutel.launcher.run -m tutel.examples.helloworld --batch_size=16
# << MPI-based Launch for CPU backend>>
$ mpiexec -bind-to none -host localhost -x LOCAL_SIZE=1 -x OMP_NUM_THREADS=1024 python3 -m tutel.launcher.run -m tutel.examples.helloworld --batch_size=16 --device cpu
Documentation for checkpoint conversion has been moved here.
# Input Example:
import torch
x = torch.ones([6, 1024], device='cuda:0')
# Create MoE:
from tutel import moe as tutel_moe
moe_layer = tutel_moe.moe_layer(
gate_type={'type': 'top', 'k': 2},
model_dim=x.shape[-1],
experts={
'num_experts_per_device': 2,
'type': 'ffn', 'hidden_size_per_expert': 2048, 'activation_fn': lambda x: torch.nn.functional.relu(x)
},
scan_expert_func = lambda name, param: setattr(param, 'skip_allreduce', True),
)
# Cast to GPU
moe_layer = moe_layer.to('cuda:0')
# In distributed model, you need further skip doing allreduce on global parameters that have `skip_allreduce` mask,
# e.g.
# for p in moe_layer.parameters():
# if hasattr(p, 'skip_allreduce'):
# continue
# dist.all_reduce(p.grad)
# Forward MoE:
y = moe_layer(x)
print(y)
You can consult this paper below to get to know more technical details about Tutel:
@article {tutel,
author = {Changho Hwang and Wei Cui and Yifan Xiong and Ziyue Yang and Ze Liu and Han Hu and Zilong Wang and Rafael Salas and Jithin Jose and Prabhat Ram and Joe Chau and Peng Cheng and Fan Yang and Mao Yang and Yongqiang Xiong},
title = {Tutel: Adaptive Mixture-of-Experts at Scale},
year = {2022},
month = jun,
journal = {CoRR},
volume= {abs/2206.03382},
url = {https://arxiv.org/pdf/2206.03382.pdf},
}
* Usage of MOELayer Args:
gate_type : dict-type gate description, e.g. {'type': 'top', 'k': 2, 'capacity_factor': -1.5, ..},
or a list of dict-type gate descriptions, e.g. [{'type': 'top', 'k', 2}, {'type': 'top', 'k', 2}],
the value of k in top-gating can be also negative, like -2, which indicates one GPU will hold 1/(-k) parameters of an expert
capacity_factor X can be positive (factor = X), zero (factor = max(needed_volumes)) or negative (factor = min(-X, max(needed_volumes))).
model_dim : the number of channels for MOE's input tensor
experts : a dict-type config for builtin expert network
scan_expert_func : allow users to specify a lambda function to iterate each experts param, e.g. `scan_expert_func = lambda name, param: setattr(param, 'expert', True)`
result_func : allow users to specify a lambda function to format the MoE output and aux_loss, e.g. `result_func = lambda output: (output, output.l_aux)`
group : specify the explicit communication group of all_to_all
seeds : a tuple containing a tripple of int to specify manual seed of (shared params, local params, others params after MoE's)
a2a_ffn_overlap_degree : the value to control a2a overlap depth, 1 by default for no overlap, 2 for overlap a2a with half gemm, ..
parallel_type : the parallel method to compute MoE, valid types: 'auto', 'data', 'model'
pad_samples : whether do auto padding on newly-coming input data to maximum data size in history
* Usage of dict-type Experts Config:
num_experts_per_device : the number of local experts per device (by default, the value is 1 if not specified)
hidden_size_per_expert : the hidden size between two linear layers for each expert (used for type == 'ffn' only)
type : available built-in experts implementation, e.g: ffn
activation_fn : the custom-defined activation function between two linear layers (used for type == 'ffn' only)
has_fc1_bias : If set to False, the expert bias parameters `batched_fc1_bias` is disabled. Default: True
has_fc2_bias : If set to False, the expert bias parameters `batched_fc2_bias` is disabled. Default: True
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Tutel
Similar Open Source Tools
Tutel
Tutel MoE is an optimized Mixture-of-Experts implementation that offers a parallel solution with 'No-penalty Parallism/Sparsity/Capacity/Switching' for modern training and inference. It supports Pytorch framework (version >= 1.10) and various GPUs including CUDA and ROCm. The tool enables Full Precision Inference of MoE-based Deepseek R1 671B on AMD MI300. Tutel provides features like all-to-all benchmarking, tensorcore option, NCCL timeout settings, Megablocks solution, and dynamic switchable configurations. Users can run Tutel in distributed mode across multiple GPUs and machines. The tool allows for custom MoE implementations and offers detailed usage examples and reference documentation.

CodeTF
CodeTF is a Python transformer-based library for code large language models (Code LLMs) and code intelligence. It provides an interface for training and inferencing on tasks like code summarization, translation, and generation. The library offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, CodeTF enables parsing of function names, comments, and variable names. It supports fast model serving, fine-tuning of LLMs, various code intelligence tasks, preprocessed datasets, model evaluation, pretrained and fine-tuned models, and utilities to manipulate source code. CodeTF aims to facilitate the integration of state-of-the-art Code LLMs into real-world applications, ensuring a user-friendly environment for code intelligence tasks.

volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.

MHA2MLA
This repository contains the code for the paper 'Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs'. It provides tools for fine-tuning and evaluating Llama models, converting models between different frameworks, processing datasets, and performing specific model training tasks like Partial-RoPE Fine-Tuning and Multiple-Head Latent Attention Fine-Tuning. The repository also includes commands for model evaluation using Lighteval and LongBench, along with necessary environment setup instructions.
repomix
Repomix is a powerful tool that packs your entire repository into a single, AI-friendly file. It is designed to format your codebase for easy understanding by AI tools like Large Language Models (LLMs), Claude, ChatGPT, and Gemini. Repomix offers features such as AI optimization, token counting, simplicity in usage, customization options, Git awareness, and security-focused checks using Secretlint. It allows users to pack their entire repository or specific directories/files using glob patterns, and even supports processing remote Git repositories. The tool generates output in plain text, XML, or Markdown formats, with options for including/excluding files, removing comments, and performing security checks. Repomix also provides a global configuration option, custom instructions for AI context, and a security check feature to detect sensitive information in files.

react-native-fast-tflite
A high-performance TensorFlow Lite library for React Native that utilizes JSI for power, zero-copy ArrayBuffers for efficiency, and low-level C/C++ TensorFlow Lite core API for direct memory access. It supports swapping out TensorFlow Models at runtime and GPU-accelerated delegates like CoreML/Metal/OpenGL. Easy VisionCamera integration allows for seamless usage. Users can load TensorFlow Lite models, interpret input and output data, and utilize GPU Delegates for faster computation. The library is suitable for real-time object detection, image classification, and other machine learning tasks in React Native applications.

pocketgroq
PocketGroq is a tool that provides advanced functionalities for text generation, web scraping, web search, and AI response evaluation. It includes features like an Autonomous Agent for answering questions, web crawling and scraping capabilities, enhanced web search functionality, and flexible integration with Ollama server. Users can customize the agent's behavior, evaluate responses using AI, and utilize various methods for text generation, conversation management, and Chain of Thought reasoning. The tool offers comprehensive methods for different tasks, such as initializing RAG, error handling, and tool management. PocketGroq is designed to enhance development processes and enable the creation of AI-powered applications with ease.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.
mcphub.nvim
MCPHub.nvim is a powerful Neovim plugin that integrates MCP (Model Context Protocol) servers into your workflow. It offers a centralized config file for managing servers and tools, with an intuitive UI for testing resources. Ideal for LLM integration, it provides programmatic API access and interactive testing through the `:MCPHub` command.
aiohttp-debugtoolbar
aiohttp_debugtoolbar provides a debug toolbar for aiohttp web applications. It is a port of pyramid_debugtoolbar and offers basic functionality such as basic panels, intercepting redirects, pretty printing exceptions, an interactive python console, and showing source code. The library is still in early development stages and offers various debug panels for monitoring different aspects of the web application. It is a useful tool for developers working with aiohttp to debug and optimize their applications.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline

python-tgpt
Python-tgpt is a Python package that enables seamless interaction with over 45 free LLM providers without requiring an API key. It also provides image generation capabilities. The name _python-tgpt_ draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.

LLMVoX
LLMVoX is a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming Text-to-Speech (TTS) system designed to convert text outputs from Large Language Models into high-fidelity streaming speech with low latency. It achieves significantly lower Word Error Rate compared to speech-enabled LLMs while operating at comparable latency and speech quality. Key features include being lightweight & fast with only 30M parameters, LLM-agnostic for easy integration with existing models, multi-queue streaming for continuous speech generation, and multilingual support for easy adaptation to new languages.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.
For similar tasks

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.

ai-hub
AI Hub Project aims to continuously test and evaluate mainstream large language models, while accumulating and managing various effective model invocation prompts. It has integrated all mainstream large language models in China, including OpenAI GPT-4 Turbo, Baidu ERNIE-Bot-4, Tencent ChatPro, MiniMax abab5.5-chat, and more. The project plans to continuously track, integrate, and evaluate new models. Users can access the models through REST services or Java code integration. The project also provides a testing suite for translation, coding, and benchmark testing.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.

MMC
This repository, MMC, focuses on advancing multimodal chart understanding through large-scale instruction tuning. It introduces a dataset supporting various tasks and chart types, a benchmark for evaluating reasoning capabilities over charts, and an assistant achieving state-of-the-art performance on chart QA benchmarks. The repository provides data for chart-text alignment, benchmarking, and instruction tuning, along with existing datasets used in experiments. Additionally, it offers a Gradio demo for the MMCA model.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.

ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.