
litdata
Transform datasets at scale. Optimize datasets for fast AI model training.
Stars: 432

LitData is a tool designed for blazingly fast, distributed streaming of training data from any cloud storage. It allows users to transform and optimize data in cloud storage environments efficiently and intuitively, supporting various data types like images, text, video, audio, geo-spatial, and multimodal data. LitData integrates smoothly with frameworks such as LitGPT and PyTorch, enabling seamless streaming of data to multiple machines. Key features include multi-GPU/multi-node support, easy data mixing, pause & resume functionality, support for profiling, memory footprint reduction, cache size configuration, and on-prem optimizations. The tool also provides benchmarks for measuring streaming speed and conversion efficiency, along with runnable templates for different data types. LitData enables infinite cloud data processing by utilizing the Lightning.ai platform to scale data processing with optimized machines.
README:
Transform datasets at scale.
Optimize data for fast AI model training.
Transform Optimize ✅ Parallelize data processing ✅ Stream large cloud datasets ✅ Create vector embeddings ✅ Accelerate training by 20x ✅ Run distributed inference ✅ Pause and resume data streaming ✅ Scrape websites at scale ✅ Use remote data without local loading




Lightning AI • Quick start • Optimize data • Transform data • Features • Benchmarks • Templates • Community
LitData scales data processing tasks (data scraping, image resizing, distributed inference, embedding creation) on local or cloud machines. It also enables optimizing datasets to accelerate AI model training and work with large remote datasets without local loading.
First, install LitData:
pip install litdataChoose your workflow:
🚀 Speed up model training
🚀 Transform datasets
Advanced install
Install all the extras
pip install 'litdata[extras]'
Accelerate model training (20x faster) by optimizing datasets for streaming directly from cloud storage. Work with remote data without local downloads with features like loading data subsets, accessing individual samples, and resumable streaming.
Step 1: Optimize the data This step will format the dataset for fast loading. The data will be written in a chunked binary format.
import numpy as np
from PIL import Image
import litdata as ld
def random_images(index):
fake_images = Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8))
fake_labels = np.random.randint(10)
# You can use any key:value pairs. Note that their types must not change between samples, and Python lists must
# always contain the same number of elements with the same types.
data = {"index": index, "image": fake_images, "class": fake_labels}
return data
if __name__ == "__main__":
# The optimize function writes data in an optimized format.
ld.optimize(
fn=random_images, # the function applied to each input
inputs=list(range(1000)), # the inputs to the function (here it's a list of numbers)
output_dir="fast_data", # optimized data is stored here
num_workers=4, # The number of workers on the same machine
chunk_bytes="64MB" # size of each chunk
)Step 2: Put the data on the cloud
Upload the data to a Lightning Studio (backed by S3) or your own S3 bucket:
aws s3 cp --recursive fast_data s3://my-bucket/fast_dataStep 3: Stream the data during training
Load the data by replacing the PyTorch DataSet and DataLoader with the StreamingDataset and StreamingDataloader
import litdata as ld
train_dataset = ld.StreamingDataset('s3://my-bucket/fast_data', shuffle=True, drop_last=True)
train_dataloader = ld.StreamingDataLoader(train_dataset)
for sample in train_dataloader:
img, cls = sample['image'], sample['class']Key benefits:
✅ Accelerate training: Optimized datasets load 20x faster.
✅ Stream cloud datasets: Work with cloud data without downloading it.
✅ Pytorch-first: Works with PyTorch libraries like PyTorch Lightning, Lightning Fabric, Hugging Face.
✅ Easy collaboration: Share and access datasets in the cloud, streamlining team projects.
✅ Scale across GPUs: Streamed data automatically scales to all GPUs.
✅ Flexible storage: Use S3, GCS, Azure, or your own cloud account for data storage.
✅ Compression: Reduce your data footprint by using advanced compression algorithms.
✅ Run local or cloud: Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ Enterprise security: Self host or process data on your cloud account with Lightning Studios.
Accelerate data processing tasks (data scraping, image resizing, embedding creation, distributed inference) by parallelizing (map) the work across many machines at once.
Here's an example that resizes and crops a large image dataset:
from PIL import Image
import litdata as ld
# use a local or S3 folder
input_dir = "my_large_images" # or "s3://my-bucket/my_large_images"
output_dir = "my_resized_images" # or "s3://my-bucket/my_resized_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# resize the input image
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
ld.map(
fn=resize_image,
inputs=inputs,
output_dir="output_dir",
)Key benefits:
✅ Parallelize processing: Reduce processing time by transforming data across multiple machines simultaneously.
✅ Scale to large data: Increase the size of datasets you can efficiently handle.
✅ Flexible usecases: Resize images, create embeddings, scrape the internet, etc...
✅ Run local or cloud: Run on your own machines or auto-scale to 1000s of cloud GPUs with Lightning Studios.
✅ Enterprise security: Self host or process data on your cloud account with Lightning Studios.
✅ Stream large cloud datasets
Use data stored on the cloud without needing to download it all to your computer, saving time and space.
Imagine you're working on a project with a huge amount of data stored online. Instead of waiting hours to download it all, you can start working with the data almost immediately by streaming it.
Once you've optimized the dataset with LitData, stream it as follows:
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset('s3://my-bucket/my-data', shuffle=True)
dataloader = StreamingDataLoader(dataset, batch_size=64)
for batch in dataloader:
process(batch) # Replace with your data processing logicAdditionally, you can inject client connection settings for S3 or GCP when initializing your dataset. This is useful for specifying custom endpoints and credentials per dataset.
from litdata import StreamingDataset
# boto3 compatible storage options for a custom S3-compatible endpoint
storage_options = {
"endpoint_url": "your_endpoint_url",
"aws_access_key_id": "your_access_key_id",
"aws_secret_access_key": "your_secret_access_key",
}
dataset = StreamingDataset('s3://my-bucket/my-data', storage_options=storage_options)
# s5cmd compatible storage options for a custom S3-compatible endpoint
# Note: If s5cmd is installed, it will be used by default for S3 operations. If you prefer not to use s5cmd, you can disable it by setting the environment variable: `DISABLE_S5CMD=1`
storage_options = {
"AWS_ACCESS_KEY_ID": "your_access_key_id",
"AWS_SECRET_ACCESS_KEY": "your_secret_access_key",
"S3_ENDPOINT_URL": "your_endpoint_url", # Required only for custom endpoints
}
dataset = StreamingDataset('s3://my-bucket/my-data', storage_options=storage_options)Alternative: Using s5cmd for S3 Operations
Also, you can specify a custom cache directory when initializing your dataset. This is useful when you want to store the cache in a specific location.
from litdata import StreamingDataset
# Initialize the StreamingDataset with the custom cache directory
dataset = StreamingDataset('s3://my-bucket/my-data', cache_dir="/path/to/cache")✅ Stream Hugging Face 🤗 datasets
To use your favorite Hugging Face dataset with LitData, simply pass its URL to StreamingDataset.
How to get HF dataset URI?
https://github.com/user-attachments/assets/3ba9e2ef-bf6b-41fc-a578-e4b4113a0e72
Prerequisites:
Install the required dependencies to stream Hugging Face datasets:
pip install "litdata[extra]" huggingface_hub
# Optional: To speed up downloads on high-bandwidth networks
pip install hf_tansfer
export HF_HUB_ENABLE_HF_TRANSFER=1Stream Hugging Face dataset:
import litdata as ld
# Define the Hugging Face dataset URI
hf_dataset_uri = "hf://datasets/leonardPKU/clevr_cogen_a_train/data"
# Create a streaming dataset
dataset = ld.StreamingDataset(hf_dataset_uri)
# Print the first sample
print("Sample", dataset[0])
# Stream the dataset using StreamingDataLoader
dataloader = ld.StreamingDataLoader(dataset, batch_size=4)
for sample in dataloader:
pass You don’t need to worry about indexing the dataset or any other setup. LitData will handle all the necessary steps automatically and cache the index.json file, so you won't have to index it again.
This ensures that the next time you stream the dataset, the indexing step is skipped..
If the Hugging Face dataset hasn't been indexed yet, you can index it first using the index_hf_dataset method, and then stream it using the code above.
import litdata as ld
hf_dataset_uri = "hf://datasets/leonardPKU/clevr_cogen_a_train/data"
ld.index_hf_dataset(hf_dataset_uri)-
Indexing the Hugging Face dataset ahead of time will make streaming abit faster, as it avoids the need for real-time indexing during streaming.
-
To use
HF gated dataset, ensure theHF_TOKENenvironment variable is set.
Note: For HuggingFace datasets, indexing & streaming is supported only for datasets in Parquet format.
For full control over the cache path(where index.json file will be stored) and other configurations, follow these steps:
- Index the Hugging Face dataset first:
import litdata as ld
hf_dataset_uri = "hf://datasets/open-thoughts/OpenThoughts-114k/data"
ld.index_parquet_dataset(hf_dataset_uri, "hf-index-dir")- To stream HF datasets now, pass the
HF dataset URI, the path where theindex.jsonfile is stored, andParquetLoaderas theitem_loaderto theStreamingDataset:
import litdata as ld
from litdata.streaming.item_loader import ParquetLoader
hf_dataset_uri = "hf://datasets/open-thoughts/OpenThoughts-114k/data"
dataset = ld.StreamingDataset(hf_dataset_uri, item_loader=ParquetLoader(), index_path="hf-index-dir")
for batch in ld.StreamingDataLoader(dataset, batch_size=4):
pass
Below is the benchmark for the Imagenet dataset (155 GB), demonstrating that optimizing the dataset using LitData is faster and results in smaller output size compared to raw Parquet files.
| Operation | Size (GB) | Time (seconds) | Throughput (images/sec) |
|---|---|---|---|
| LitData Optimize Dataset | 45 | 283.17 | 4000-4700 |
| Parquet Optimize Dataset | 51 | 465.96 | 3600-3900 |
| Index Parquet Dataset (overhead) | N/A | 6 | N/A |
✅ Streams on multi-GPU, multi-node
Data optimized and loaded with Lightning automatically streams efficiently in distributed training across GPUs or multi-node.
The StreamingDataset and StreamingDataLoader automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks (PyTorch Lightning, Lightning Fabric, or PyTorch) to do distributed training.
Here you can see an illustration showing how the Streaming Dataset works with multi node / multi gpu under the hood.
from litdata import StreamingDataset, StreamingDataLoader
# For the training dataset, don't forget to enable shuffle and drop_last !!!
train_dataset = StreamingDataset('s3://my-bucket/my-train-data', shuffle=True, drop_last=True)
train_dataloader = StreamingDataLoader(train_dataset, batch_size=64)
for batch in train_dataloader:
process(batch) # Replace with your data processing logic
val_dataset = StreamingDataset('s3://my-bucket/my-val-data', shuffle=False, drop_last=False)
val_dataloader = StreamingDataLoader(val_dataset, batch_size=64)
for batch in val_dataloader:
process(batch) # Replace with your data processing logic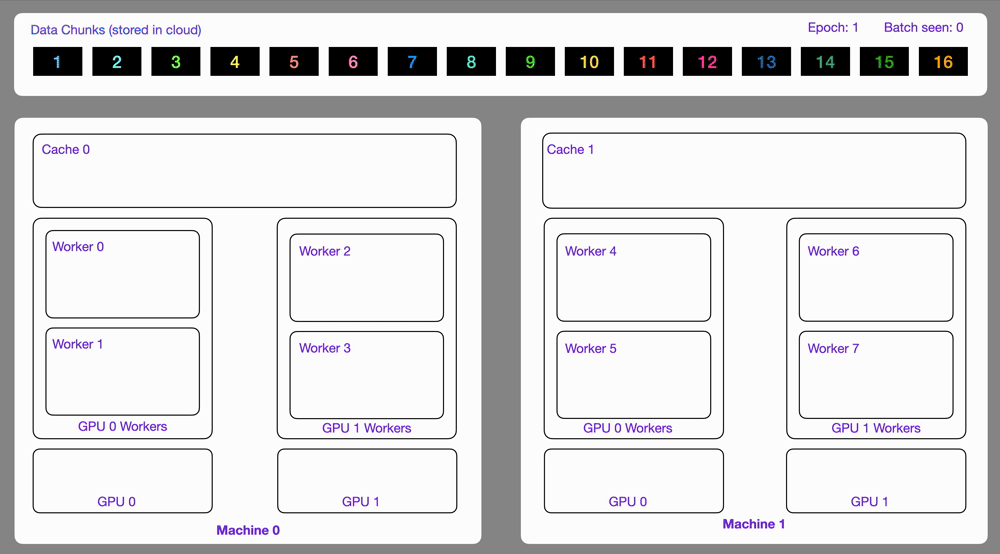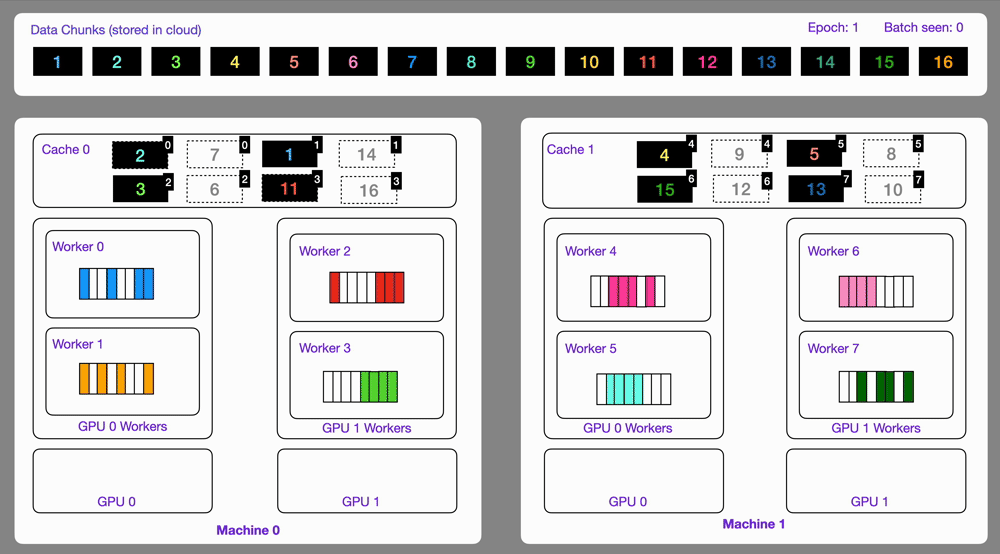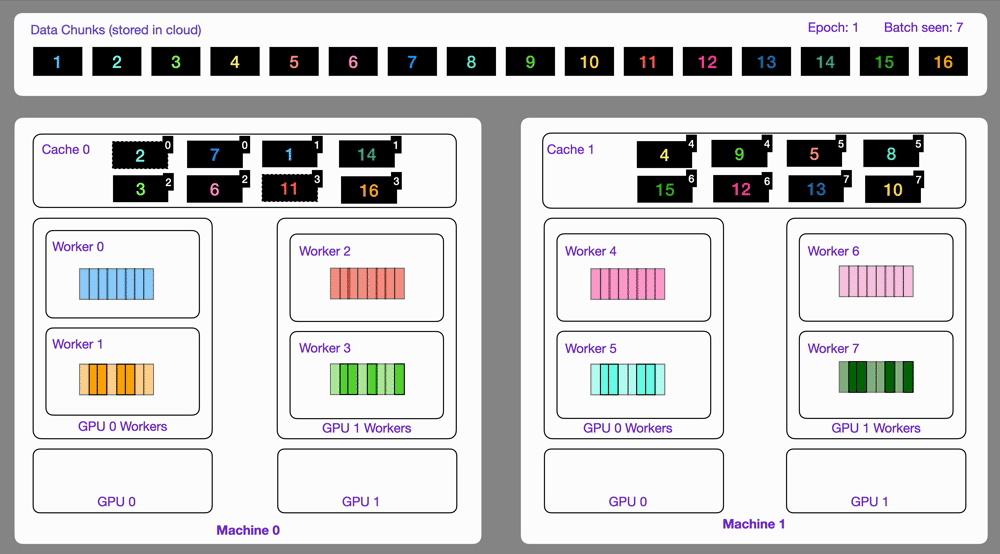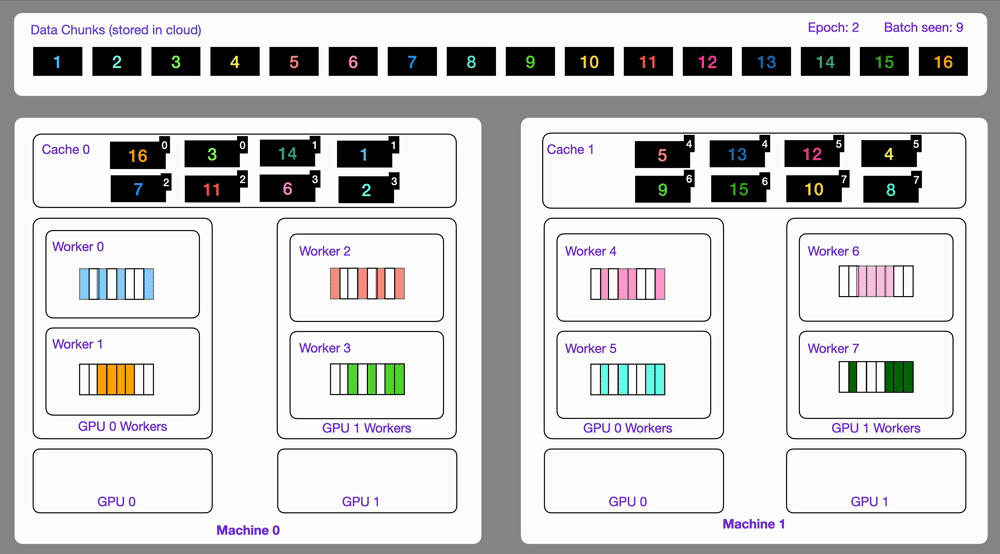
✅ Stream from multiple cloud providers
The StreamingDataset provides support for reading optimized datasets from common cloud storage providers like AWS S3, Google Cloud Storage (GCS), and Azure Blob Storage. Below are examples of how to use StreamingDataset with each cloud provider.
import os
import litdata as ld
# Read data from AWS S3 using s5cmd
# Note: If s5cmd is installed, it will be used by default for S3 operations. If you prefer not to use s5cmd, you can disable it by setting the environment variable: `DISABLE_S5CMD=1`
aws_storage_options={
"AWS_ACCESS_KEY_ID": os.environ['AWS_ACCESS_KEY_ID'],
"AWS_SECRET_ACCESS_KEY": os.environ['AWS_SECRET_ACCESS_KEY'],
"S3_ENDPOINT_URL": os.environ['AWS_ENDPOINT_URL'], # Required only for custom endpoints
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
# Read Data from AWS S3 with Unsigned Request using s5cmd
aws_storage_options={
"AWS_NO_SIGN_REQUEST": "Yes" # Required for unsigned requests
"S3_ENDPOINT_URL": os.environ['AWS_ENDPOINT_URL'], # Required only for custom endpoints
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
# Read data from AWS S3 using boto3
os.environ["DISABLE_S5CMD"] = "1"
aws_storage_options={
"aws_access_key_id": os.environ['AWS_ACCESS_KEY_ID'],
"aws_secret_access_key": os.environ['AWS_SECRET_ACCESS_KEY'],
}
dataset = ld.StreamingDataset("s3://my-bucket/my-data", storage_options=aws_storage_options)
# Read data from GCS
gcp_storage_options={
"project": os.environ['PROJECT_ID'],
}
dataset = ld.StreamingDataset("gs://my-bucket/my-data", storage_options=gcp_storage_options)
# Read data from Azure
azure_storage_options={
"account_url": f"https://{os.environ['AZURE_ACCOUNT_NAME']}.blob.core.windows.net",
"credential": os.environ['AZURE_ACCOUNT_ACCESS_KEY']
}
dataset = ld.StreamingDataset("azure://my-bucket/my-data", storage_options=azure_storage_options)✅ Pause, resume data streaming
Stream data during long training, if interrupted, pick up right where you left off without any issues.
LitData provides a stateful Streaming DataLoader e.g. you can pause and resume your training whenever you want.
Info: The Streaming DataLoader was used by Lit-GPT to pretrain LLMs. Restarting from an older checkpoint was critical to get to pretrain the full model due to several failures (network, CUDA Errors, etc..).
import os
import torch
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset("s3://my-bucket/my-data", shuffle=True)
dataloader = StreamingDataLoader(dataset, num_workers=os.cpu_count(), batch_size=64)
# Restore the dataLoader state if it exists
if os.path.isfile("dataloader_state.pt"):
state_dict = torch.load("dataloader_state.pt")
dataloader.load_state_dict(state_dict)
# Iterate over the data
for batch_idx, batch in enumerate(dataloader):
# Store the state every 1000 batches
if batch_idx % 1000 == 0:
torch.save(dataloader.state_dict(), "dataloader_state.pt")✅ LLM Pre-training
LitData is highly optimized for LLM pre-training. First, we need to tokenize the entire dataset and then we can consume it.
import json
from pathlib import Path
import zstandard as zstd
from litdata import optimize, TokensLoader
from tokenizer import Tokenizer
from functools import partial
# 1. Define a function to convert the text within the jsonl files into tokens
def tokenize_fn(filepath, tokenizer=None):
with zstd.open(open(filepath, "rb"), "rt", encoding="utf-8") as f:
for row in f:
text = json.loads(row)["text"]
if json.loads(row)["meta"]["redpajama_set_name"] == "RedPajamaGithub":
continue # exclude the GitHub data since it overlaps with starcoder
text_ids = tokenizer.encode(text, bos=False, eos=True)
yield text_ids
if __name__ == "__main__":
# 2. Generate the inputs (we are going to optimize all the compressed json files from SlimPajama dataset )
input_dir = "./slimpajama-raw"
inputs = [str(file) for file in Path(f"{input_dir}/SlimPajama-627B/train").rglob("*.zst")]
# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections"
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: You can use HF tokenizer or any others
inputs=inputs,
output_dir="./slimpajama-optimized",
chunk_size=(2049 * 8012),
# This is important to inform LitData that we are encoding contiguous 1D array (tokens).
# LitData skips storing metadata for each sample e.g all the tokens are concatenated to form one large tensor.
item_loader=TokensLoader(),
)import os
from litdata import StreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
# Increase by one because we need the next word as well
dataset = StreamingDataset(
input_dir=f"./slimpajama-optimized/train",
item_loader=TokensLoader(block_size=2048 + 1),
shuffle=True,
drop_last=True,
)
train_dataloader = StreamingDataLoader(dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the SlimPajama dataset
for batch in tqdm(train_dataloader):
pass✅ Filter illegal data
Sometimes, you have bad data that you don't want to include in the optimized dataset. With LitData, yield only the good data sample to include.
from litdata import optimize, StreamingDataset
def should_keep(index) -> bool:
# Replace with your own logic
return index % 2 == 0
def fn(data):
if should_keep(data):
yield data
if __name__ == "__main__":
optimize(
fn=fn,
inputs=list(range(1000)),
output_dir="only_even_index_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_even_index_optimized")
data = list(dataset)
print(data)
# [0, 2, 4, 6, 8, 10, ..., 992, 994, 996, 998]You can even use try/expect.
from litdata import optimize, StreamingDataset
def fn(data):
try:
yield 1 / data
except:
pass
if __name__ == "__main__":
optimize(
fn=fn,
inputs=[0, 0, 0, 1, 2, 4, 0],
output_dir="only_defined_ratio_optimized",
chunk_bytes="64MB",
num_workers=1
)
dataset = StreamingDataset("only_defined_ratio_optimized")
data = list(dataset)
# The 0 are filtered out as they raise a division by zero
print(data)
# [1.0, 0.5, 0.25] ✅ Combine datasets
Mix and match different sets of data to experiment and create better models.
Combine datasets with CombinedStreamingDataset. As an example, this mixture of Slimpajama & StarCoder was used in the TinyLLAMA project to pretrain a 1.1B Llama model on 3 trillion tokens.
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
import os
train_datasets = [
StreamingDataset(
input_dir="s3://tinyllama-template/slimpajama/train/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
StreamingDataset(
input_dir="s3://tinyllama-template/starcoder/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
]
# Mix SlimPajama data and Starcoder data with these proportions:
weights = (0.693584, 0.306416)
combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights, iterate_over_all=False)
train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the combined datasets
for batch in tqdm(train_dataloader):
pass✅ Merge datasets
Merge multiple optimized datasets into one.
import numpy as np
from PIL import Image
from litdata import StreamingDataset, merge_datasets, optimize
def random_images(index):
return {
"index": index,
"image": Image.fromarray(np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8)),
"class": np.random.randint(10),
}
if __name__ == "__main__":
out_dirs = ["fast_data_1", "fast_data_2", "fast_data_3", "fast_data_4"] # or ["s3://my-bucket/fast_data_1", etc.]"
for out_dir in out_dirs:
optimize(fn=random_images, inputs=list(range(250)), output_dir=out_dir, num_workers=4, chunk_bytes="64MB")
merged_out_dir = "merged_fast_data" # or "s3://my-bucket/merged_fast_data"
merge_datasets(input_dirs=out_dirs, output_dir=merged_out_dir)
dataset = StreamingDataset(merged_out_dir)
print(len(dataset))
# out: 1000✅ Split datasets for train, val, test
Split a dataset into train, val, test splits with train_test_split.
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data") # data are stored in the cloud
print(len(dataset)) # display the length of your data
# out: 100,000
train_dataset, val_dataset, test_dataset = train_test_split(dataset, splits=[0.3, 0.2, 0.5])
print(train_dataset)
# out: 30,000
print(val_dataset)
# out: 20,000
print(test_dataset)
# out: 50,000✅ Load a subset of the remote dataset
Work on a smaller, manageable portion of your data to save time and resources.
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=0.01) # data are stored in the cloud
print(len(dataset)) # display the length of your data
# out: 1000✅ Upsample from your source datasets
Use to control the size of one iteration of a StreamingDataset using repeats. Contains floor(N) possibly shuffled copies of the source data, then a subsampling of the remainder.
from litdata import StreamingDataset
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=2.5, shuffle=True)
print(len(dataset)) # display the length of your data
# out: 250000✅ Easily modify optimized cloud datasets
Add new data to an existing dataset or start fresh if needed, providing flexibility in data management.
LitData optimized datasets are assumed to be immutable. However, you can make the decision to modify them by changing the mode to either append or overwrite.
from litdata import optimize, StreamingDataset
def compress(index):
return index, index**2
if __name__ == "__main__":
# Add some data
optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
)
# Later on, you add more data
optimize(
fn=compress,
inputs=list(range(100, 200)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
mode="append",
)
ds = StreamingDataset("./my_optimized_dataset")
assert len(ds) == 200
assert ds[:] == [(i, i**2) for i in range(200)]The overwrite mode will delete the existing data and start from fresh.
✅ Stream parquet datasets
Stream Parquet datasets directly with LitData—no need to convert them into LitData’s optimized binary format! If your dataset is already in Parquet format, you can efficiently index and stream it using StreamingDataset and StreamingDataLoader.
Assumption:
Your dataset directory contains one or more Parquet files.
Prerequisites:
Install the required dependencies to stream Parquet datasets from cloud storage like Amazon S3 or Google Cloud Storage:
# For Amazon S3
pip install "litdata[extra]" s3fs
# For Google Cloud Storage
pip install "litdata[extra]" gcsfsIndex Your Dataset:
Index your Parquet dataset to create an index file that LitData can use to stream the dataset.
import litdata as ld
# Point to your data stored in the cloud
pq_dataset_uri = "s3://my-bucket/my-parquet-data" # or "gs://my-bucket/my-parquet-data"
ld.index_parquet_dataset(pq_dataset_uri)Stream the Dataset
Use StreamingDataset with ParquetLoader to load and stream the dataset efficiently:
import litdata as ld
from litdata.streaming.item_loader import ParquetLoader
# Specify your dataset location in the cloud
pq_dataset_uri = "s3://my-bucket/my-parquet-data" # or "gs://my-bucket/my-parquet-data"
# Set up the streaming dataset
dataset = ld.StreamingDataset(pq_dataset_uri, item_loader=ParquetLoader())
# print the first sample
print("Sample", dataset[0])
# Stream the dataset using StreamingDataLoader
dataloader = ld.StreamingDataLoader(dataset, batch_size=4)
for sample in dataloader:
pass✅ Use compression
Reduce your data footprint by using advanced compression algorithms.
import litdata as ld
def compress(index):
return index, index**2
if __name__ == "__main__":
# Add some data
ld.optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
num_workers=1,
compression="zstd"
)Using zstd, you can achieve high compression ratio like 4.34x for this simple example.
| Without | With |
|---|---|
| 2.8kb | 646b |
✅ Access samples without full data download
Look at specific parts of a large dataset without downloading the whole thing or loading it on a local machine.
from litdata import StreamingDataset
dataset = StreamingDataset("s3://my-bucket/my-data") # data are stored in the cloud
print(len(dataset)) # display the length of your data
print(dataset[42]) # show the 42th element of the dataset✅ Use any data transforms
Customize how your data is processed to better fit your needs.
Subclass the StreamingDataset and override its __getitem__ method to add any extra data transformations.
from litdata import StreamingDataset, StreamingDataLoader
import torchvision.transforms.v2.functional as F
class ImagenetStreamingDataset(StreamingDataset):
def __getitem__(self, index):
image = super().__getitem__(index)
return F.resize(image, (224, 224))
dataset = ImagenetStreamingDataset(...)
dataloader = StreamingDataLoader(dataset, batch_size=4)
for batch in dataloader:
print(batch.shape)
# Out: (4, 3, 224, 224)✅ Profile data loading speed
Measure and optimize how fast your data is being loaded, improving efficiency.
The StreamingDataLoader supports profiling of your data loading process. Simply use the profile_batches argument to specify the number of batches you want to profile:
from litdata import StreamingDataset, StreamingDataLoader
StreamingDataLoader(..., profile_batches=5)This generates a Chrome trace called result.json. Then, visualize this trace by opening Chrome browser at the chrome://tracing URL and load the trace inside.
✅ Reduce memory use for large files
Handle large data files efficiently without using too much of your computer's memory.
When processing large files like compressed parquet files, use the Python yield keyword to process and store one item at the time, reducing the memory footprint of the entire program.
from pathlib import Path
import pyarrow.parquet as pq
from litdata import optimize
from tokenizer import Tokenizer
from functools import partial
# 1. Define a function to convert the text within the parquet files into tokens
def tokenize_fn(filepath, tokenizer=None):
parquet_file = pq.ParquetFile(filepath)
# Process per batch to reduce RAM usage
for batch in parquet_file.iter_batches(batch_size=8192, columns=["content"]):
for text in batch.to_pandas()["content"]:
yield tokenizer.encode(text, bos=False, eos=True)
# 2. Generate the inputs
input_dir = "/teamspace/s3_connections/tinyllama-template"
inputs = [str(file) for file in Path(f"{input_dir}/starcoderdata").rglob("*.parquet")]
# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections"
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: Use HF tokenizer or any others
inputs=inputs,
output_dir="/teamspace/datasets/starcoderdata",
chunk_size=(2049 * 8012), # Number of tokens to store by chunks. This is roughly 64MB of tokens per chunk.
)✅ Limit local cache space
Limit the amount of disk space used by temporary files, preventing storage issues.
Adapt the local caching limit of the StreamingDataset. This is useful to make sure the downloaded data chunks are deleted when used and the disk usage stays low.
from litdata import StreamingDataset
dataset = StreamingDataset(..., max_cache_size="10GB")✅ Change cache directory path
Specify the directory where cached files should be stored, ensuring efficient data retrieval and management. This is particularly useful for organizing your data storage and improving access times.
from litdata import StreamingDataset
from litdata.streaming.cache import Dir
cache_dir = "/path/to/your/cache"
data_dir = "s3://my-bucket/my_optimized_dataset"
dataset = StreamingDataset(input_dir=Dir(path=cache_dir, url=data_dir))✅ Optimize loading on networked drives
Optimize data handling for computers on a local network to improve performance for on-site setups.
On-prem compute nodes can mount and use a network drive. A network drive is a shared storage device on a local area network. In order to reduce their network overload, the StreamingDataset supports caching the data chunks.
from litdata import StreamingDataset
dataset = StreamingDataset(input_dir="local:/data/shared-drive/some-data")✅ Optimize dataset in distributed environment
Lightning can distribute large workloads across hundreds of machines in parallel. This can reduce the time to complete a data processing task from weeks to minutes by scaling to enough machines.
To apply the optimize operator across multiple machines, simply provide the num_nodes and machine arguments to it as follows:
import os
from litdata import optimize, Machine
def compress(index):
return (index, index ** 2)
optimize(
fn=compress,
inputs=list(range(100)),
num_workers=2,
output_dir="my_output",
chunk_bytes="64MB",
num_nodes=2,
machine=Machine.DATA_PREP, # You can select between dozens of optimized machines
)If the output_dir is a local path, the optimized dataset will be present in: /teamspace/jobs/{job_name}/nodes-0/my_output. Otherwise, it will be stored in the specified output_dir.
Read the optimized dataset:
from litdata import StreamingDataset
output_dir = "/teamspace/jobs/litdata-optimize-2024-07-08/nodes.0/my_output"
dataset = StreamingDataset(output_dir)
print(dataset[:])✅ Encrypt, decrypt data at chunk/sample level
Secure data by applying encryption to individual samples or chunks, ensuring sensitive information is protected during storage.
This example shows how to use the FernetEncryption class for sample-level encryption with a data optimization function.
from litdata import optimize
from litdata.utilities.encryption import FernetEncryption
import numpy as np
from PIL import Image
# Initialize FernetEncryption with a password for sample-level encryption
fernet = FernetEncryption(password="your_secure_password", level="sample")
data_dir = "s3://my-bucket/optimized_data"
def random_image(index):
"""Generate a random image for demonstration purposes."""
fake_img = Image.fromarray(np.random.randint(0, 255, (32, 32, 3), dtype=np.uint8))
return {"image": fake_img, "class": index}
# Optimize data while applying encryption
optimize(
fn=random_image,
inputs=list(range(5)), # Example inputs: [0, 1, 2, 3, 4]
num_workers=1,
output_dir=data_dir,
chunk_bytes="64MB",
encryption=fernet,
)
# Save the encryption key to a file for later use
fernet.save("fernet.pem")Load the encrypted data using the StreamingDataset class as follows:
from litdata import StreamingDataset
from litdata.utilities.encryption import FernetEncryption
# Load the encryption key
fernet = FernetEncryption(password="your_secure_password", level="sample")
fernet.load("fernet.pem")
# Create a streaming dataset for reading the encrypted samples
ds = StreamingDataset(input_dir=data_dir, encryption=fernet)Implement your own encryption method: Subclass the Encryption class and define the necessary methods:
from litdata.utilities.encryption import Encryption
class CustomEncryption(Encryption):
def encrypt(self, data):
# Implement your custom encryption logic here
return data
def decrypt(self, data):
# Implement your custom decryption logic here
return dataThis allows the data to remain secure while maintaining flexibility in the encryption method.
✅ Parallelize data transformations (map)
Apply the same change to different parts of the dataset at once to save time and effort.
The map operator can be used to apply a function over a list of inputs.
Here is an example where the map operator is used to apply a resize_image function over a folder of large images.
from litdata import map
from PIL import Image
# Note: Inputs could also refer to files on s3 directly.
input_dir = "my_large_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# The resize image takes one of the input (image_path) and the output directory.
# Files written to output_dir are persisted.
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
map(
fn=resize_image,
inputs=inputs,
output_dir="s3://my-bucket/my_resized_images",
)
In this section we show benchmarks for speed to optimize a dataset and the resulting streaming speed (Reproduce the benchmark).
Data optimized and streamed with LitData achieves a 20x speed up over non optimized data and 2x speed up over other streaming solutions.
Speed to stream Imagenet 1.2M from AWS S3:
| Framework | Images / sec 1st Epoch (float32) | Images / sec 2nd Epoch (float32) | Images / sec 1st Epoch (torch16) | Images / sec 2nd Epoch (torch16) |
|---|---|---|---|---|
| LitData | 5839 | 6692 | 6282 | 7221 |
| Web Dataset | 3134 | 3924 | 3343 | 4424 |
| Mosaic ML | 2898 | 5099 | 2809 | 5158 |
Benchmark details
-
Imagenet-1.2M dataset contains
1,281,167 images. - To align with other benchmarks, we measured the streaming speed (
images per second) loaded from AWS S3 for several frameworks.
LitData optimizes the Imagenet dataset for fast training 3-5x faster than other frameworks:
Time to optimize 1.2 million ImageNet images (Faster is better):
| Framework | Train Conversion Time | Val Conversion Time | Dataset Size | # Files |
|---|---|---|---|---|
| LitData | 10:05 min | 00:30 min | 143.1 GB | 2.339 |
| Web Dataset | 32:36 min | 01:22 min | 147.8 GB | 1.144 |
| Mosaic ML | 49:49 min | 01:04 min | 143.1 GB | 2.298 |
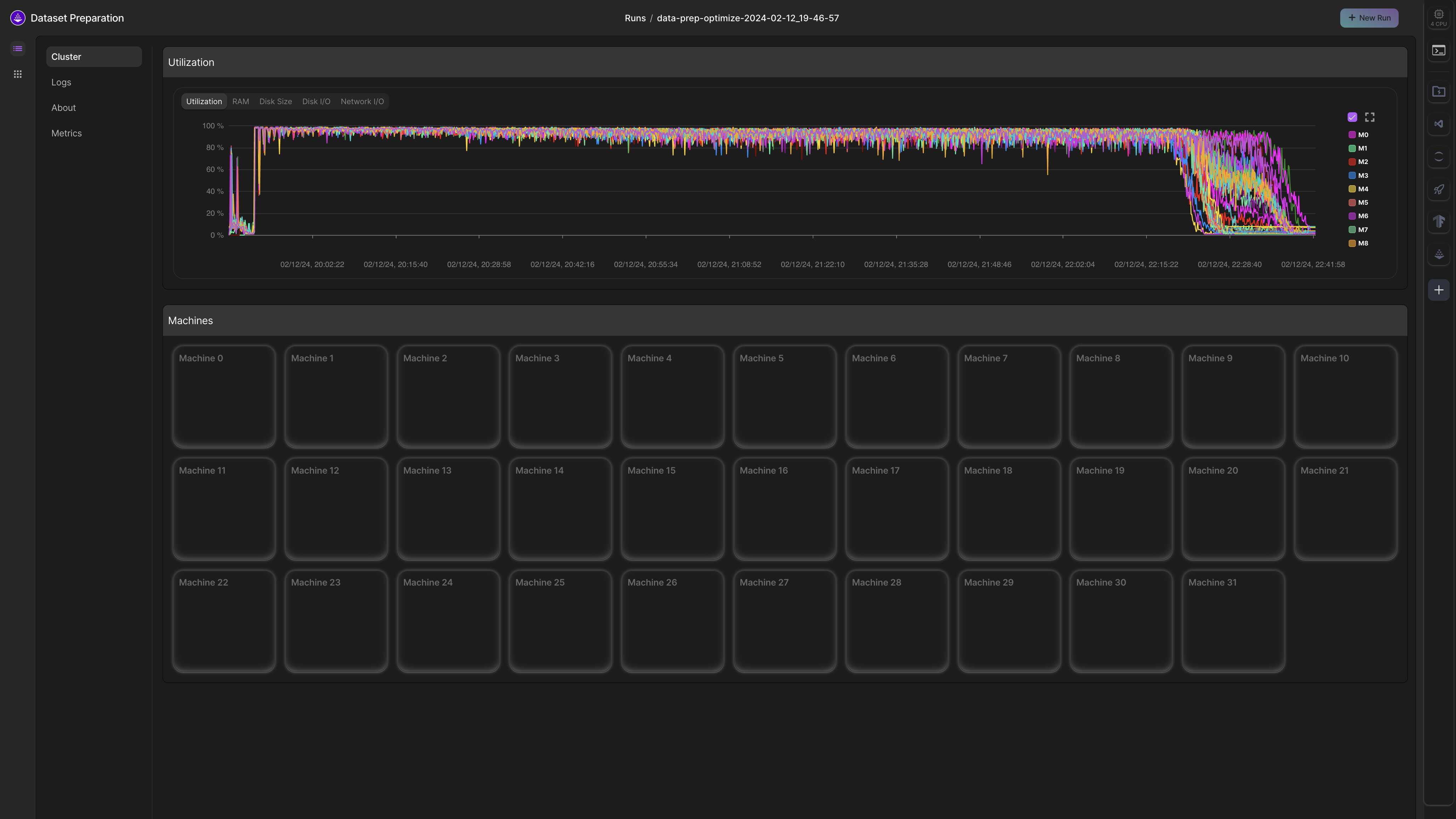
Transformations with LitData are linearly parallelizable across machines.
For example, let's say that it takes 56 hours to embed a dataset on a single A10G machine. With LitData, this can be speed up by adding more machines in parallel
| Number of machines | Hours |
|---|---|
| 1 | 56 |
| 2 | 28 |
| 4 | 14 |
| ... | ... |
| 64 | 0.875 |
To scale the number of machines, run the processing script on Lightning Studios:
from litdata import map, Machine
map(
...
num_nodes=32,
machine=Machine.DATA_PREP, # Select between dozens of optimized machines
)To scale the number of machines for data optimization, use Lightning Studios:
from litdata import optimize, Machine
optimize(
...
num_nodes=32,
machine=Machine.DATA_PREP, # Select between dozens of optimized machines
)
Example: Process the LAION 400 million image dataset in 2 hours on 32 machines, each with 32 CPUs.
Below are templates for real-world applications of LitData at scale.
| Studio | Data type | Time (minutes) | Machines | Dataset |
|---|---|---|---|---|
| Download LAION-400MILLION dataset | Image & Text | 120 | 32 | LAION-400M |
| Tokenize 2M Swedish Wikipedia Articles | Text | 7 | 4 | Swedish Wikipedia |
| Embed English Wikipedia under 5 dollars | Text | 15 | 3 | English Wikipedia |
| Studio | Data type | Time (minutes) | Machines | Dataset |
|---|---|---|---|---|
| Benchmark cloud data-loading libraries | Image & Label | 10 | 1 | Imagenet 1M |
| Optimize GeoSpatial data for model training | Image & Mask | 120 | 32 | Chesapeake Roads Spatial Context |
| Optimize TinyLlama 1T dataset for training | Text | 240 | 32 | SlimPajama & StarCoder |
| Optimize parquet files for model training | Parquet Files | 12 | 16 | Randomly Generated data |
LitData is a community project accepting contributions - Let's make the world's most advanced AI data processing framework.
💬 Get help on Discord
📋 License: Apache 2.0
- Thomas Chaton (tchaton)
- Luca Antiga (lantiga)
- Justus Schock (justusschock)
- Bhimraj Yadav (bhimrazy)
- Deependu (deependujha)
- Jirka Borda (Borda)
- Adrian Wälchli (awaelchli)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for litdata
Similar Open Source Tools
litdata
LitData is a tool designed for blazingly fast, distributed streaming of training data from any cloud storage. It allows users to transform and optimize data in cloud storage environments efficiently and intuitively, supporting various data types like images, text, video, audio, geo-spatial, and multimodal data. LitData integrates smoothly with frameworks such as LitGPT and PyTorch, enabling seamless streaming of data to multiple machines. Key features include multi-GPU/multi-node support, easy data mixing, pause & resume functionality, support for profiling, memory footprint reduction, cache size configuration, and on-prem optimizations. The tool also provides benchmarks for measuring streaming speed and conversion efficiency, along with runnable templates for different data types. LitData enables infinite cloud data processing by utilizing the Lightning.ai platform to scale data processing with optimized machines.
litserve
LitServe is a high-throughput serving engine for deploying AI models at scale. It generates an API endpoint for a model, handles batching, streaming, autoscaling across CPU/GPUs, and more. Built for enterprise scale, it supports every framework like PyTorch, JAX, Tensorflow, and more. LitServe is designed to let users focus on model performance, not the serving boilerplate. It is like PyTorch Lightning for model serving but with broader framework support and scalability.

volga
Volga is a general purpose real-time data processing engine in Python for modern AI/ML systems. It aims to be a Python-native alternative to Flink/Spark Streaming with extended functionality for real-time AI/ML workloads. It provides a hybrid push+pull architecture, Entity API for defining data entities and feature pipelines, DataStream API for general data processing, and customizable data connectors. Volga can run on a laptop or a distributed cluster, making it suitable for building custom real-time AI/ML feature platforms or general data pipelines without relying on third-party platforms.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.
ShannonBase
ShannonBase is a HTAP database provided by Shannon Data AI, designed for big data and AI. It extends MySQL with native embedding support, machine learning capabilities, a JavaScript engine, and a columnar storage engine. ShannonBase supports multimodal data types and natively integrates LightGBM for training and prediction. It leverages embedding algorithms and vector data type for ML/RAG tasks, providing Zero Data Movement, Native Performance Optimization, and Seamless SQL Integration. The tool includes a lightweight JavaScript engine for writing stored procedures in SQL or JavaScript.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.

LightRAG
LightRAG is a repository hosting the code for LightRAG, a system that supports seamless integration of custom knowledge graphs, Oracle Database 23ai, Neo4J for storage, and multiple file types. It includes features like entity deletion, batch insert, incremental insert, and graph visualization. LightRAG provides an API server implementation for RESTful API access to RAG operations, allowing users to interact with it through HTTP requests. The repository also includes evaluation scripts, code for reproducing results, and a comprehensive code structure.
aicsimageio
AICSImageIO is a Python tool for Image Reading, Metadata Conversion, and Image Writing for Microscopy Images. It supports various file formats like OME-TIFF, TIFF, ND2, DV, CZI, LIF, PNG, GIF, and Bio-Formats. Users can read and write metadata and imaging data, work with different file systems like local paths, HTTP URLs, s3fs, and gcsfs. The tool provides functionalities for full image reading, delayed image reading, mosaic image reading, metadata reading, xarray coordinate plane attachment, cloud IO support, and saving to OME-TIFF. It also offers benchmarking and developer resources.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.

react-native-fast-tflite
A high-performance TensorFlow Lite library for React Native that utilizes JSI for power, zero-copy ArrayBuffers for efficiency, and low-level C/C++ TensorFlow Lite core API for direct memory access. It supports swapping out TensorFlow Models at runtime and GPU-accelerated delegates like CoreML/Metal/OpenGL. Easy VisionCamera integration allows for seamless usage. Users can load TensorFlow Lite models, interpret input and output data, and utilize GPU Delegates for faster computation. The library is suitable for real-time object detection, image classification, and other machine learning tasks in React Native applications.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output based on a Context-Free Grammar (CFG). It supports various programming languages like Python, Go, SQL, Math, JSON, and more. Users can define custom grammars using EBNF syntax. SynCode offers fast generation, seamless integration with HuggingFace Language Models, and the ability to sample with different decoding strategies.

req_llm
ReqLLM is a Req-based library for LLM interactions, offering a unified interface to AI providers through a plugin-based architecture. It brings composability and middleware advantages to LLM interactions, with features like auto-synced providers/models, typed data structures, ergonomic helpers, streaming capabilities, usage & cost extraction, and a plugin-based provider system. Users can easily generate text, structured data, embeddings, and track usage costs. The tool supports various AI providers like Anthropic, OpenAI, Groq, Google, and xAI, and allows for easy addition of new providers. ReqLLM also provides API key management, detailed documentation, and a roadmap for future enhancements.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.
ragoon
RAGoon is a high-level library designed for batched embeddings generation, fast web-based RAG (Retrieval-Augmented Generation) processing, and quantized indexes processing. It provides NLP utilities for multi-model embedding production, high-dimensional vector visualization, and enhancing language model performance through search-based querying, web scraping, and data augmentation techniques.
For similar tasks
litdata
LitData is a tool designed for blazingly fast, distributed streaming of training data from any cloud storage. It allows users to transform and optimize data in cloud storage environments efficiently and intuitively, supporting various data types like images, text, video, audio, geo-spatial, and multimodal data. LitData integrates smoothly with frameworks such as LitGPT and PyTorch, enabling seamless streaming of data to multiple machines. Key features include multi-GPU/multi-node support, easy data mixing, pause & resume functionality, support for profiling, memory footprint reduction, cache size configuration, and on-prem optimizations. The tool also provides benchmarks for measuring streaming speed and conversion efficiency, along with runnable templates for different data types. LitData enables infinite cloud data processing by utilizing the Lightning.ai platform to scale data processing with optimized machines.
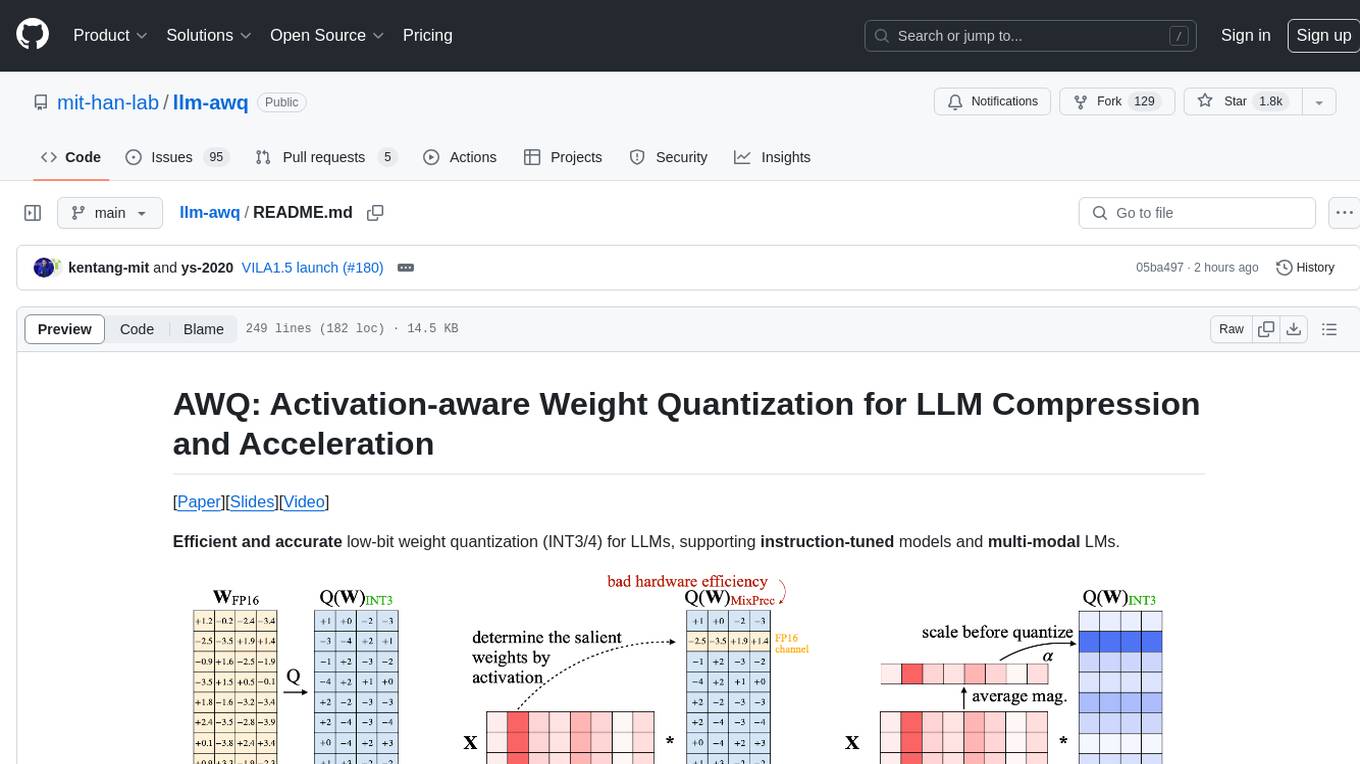
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
Liger-Kernel
Liger Kernel is a collection of Triton kernels designed for LLM training, increasing training throughput by 20% and reducing memory usage by 60%. It includes Hugging Face Compatible modules like RMSNorm, RoPE, SwiGLU, CrossEntropy, and FusedLinearCrossEntropy. The tool works with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed, aiming to enhance model efficiency and performance for researchers, ML practitioners, and curious novices.
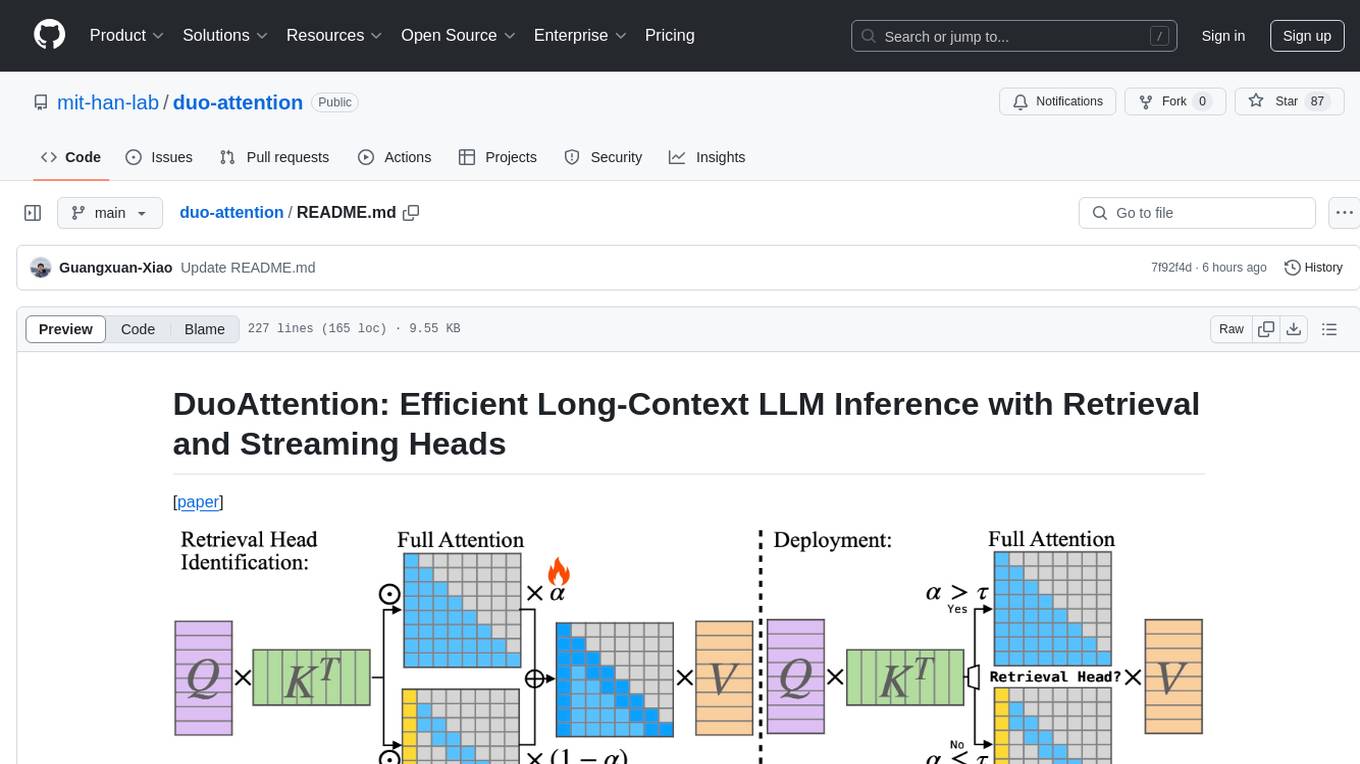
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.

instructor-js
Instructor is a Typescript library for structured extraction in Typescript, powered by llms, designed for simplicity, transparency, and control. It stands out for its simplicity, transparency, and user-centric design. Whether you're a seasoned developer or just starting out, you'll find Instructor's approach intuitive and steerable.

lanarky
Lanarky is a Python web framework designed for building microservices using Large Language Models (LLMs). It is LLM-first, fast, modern, supports streaming over HTTP and WebSockets, and is open-source. The framework provides an abstraction layer for developers to easily create LLM microservices. Lanarky guarantees zero vendor lock-in and is free to use. It is built on top of FastAPI and offers features familiar to FastAPI users. The project is now in maintenance mode, with no active development planned, but community contributions are encouraged.
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.