
edsl
Design, conduct and analyze results of AI-powered surveys and experiments. Simulate social science and market research with large numbers of AI agents and LLMs.
Stars: 279

The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.
README:
![]()
EDSL makes it easy to conduct computational social science and market research with AI. Use it to design and run surveys and experiments with many AI agents and large language models at once, or to perform complex data labeling and other research tasks. Results are formatted as specified datasets that can be replicated at no cost, and come with built-in methods for analysis, visualization and collaboration.
-
Run
pip install edslto install the package. See instructions. -
Create an account to run surveys at the Expected Parrot server and access a universal remote cache of stored responses for reproducing results.
-
Choose whether to use your own keys for language models or get an Expected Parrot key to access all available models at once. Securely manage keys, expenses and usage for your team from your account.
-
Run the starter tutorial and explore other demo notebooks for a variety of use cases.
-
Share workflows and survey results at Coop: a free platform for creating and sharing AI research.
-
Join our Discord for updates and discussions!
- Python 3.9 - 3.13
- API keys for language models. You can use your own keys or an Expected Parrot key that provides access to all available models. See instructions on managing keys and model pricing and performance information.
An integrated platform for running experiments, sharing workflows and launching hybrid human/AI surveys.
Declarative design: Specified question types ensure consistent results without requiring a JSON schema (view at Coop):
from edsl import QuestionMultipleChoice
q = QuestionMultipleChoice(
question_name = "example",
question_text = "How do you feel today?",
question_options = ["Bad", "OK", "Good"]
)
results = q.run()
results.select("example")
answer.example Good
Parameterized prompts: Easily parameterize and control prompts with "scenarios" of data automatically imported from many sources (CSV, PDF, PNG, etc.) (view at Coop):
from edsl import ScenarioList, QuestionLinearScale
q = QuestionLinearScale(
question_name = "example",
question_text = "How much do you enjoy {{ scenario.activity }}?",
question_options = [1,2,3,4,5,],
option_labels = {1:"Not at all", 5:"Very much"}
)
sl = ScenarioList.from_list("activity", ["coding", "sleeping"])
results = q.by(sl).run()
results.select("activity", "example")
scenario.activity answer.example Coding 5 Sleeping 5
Design AI agent personas to answer questions: Construct agents with relevant traits to provide diverse responses to your surveys (view at Coop)
from edsl import Agent, AgentList, QuestionList
al = AgentList(Agent(traits = {"persona":p}) for p in ["botanist", "detective"])
q = QuestionList(
question_name = "example",
question_text = "What are your favorite colors?",
max_list_items = 3
)
results = q.by(al).run()
results.select("persona", "example")
agent.persona answer.example botanist ['Green', 'Earthy Brown', 'Sunset Orange'] detective ['Gray', 'Black', 'Navy Blue']
Simplified access to LLMs: Choose whether to use your own API keys for LLMs, or access all available models with an Expected Parrot key. Run surveys with many models at once and compare responses at a convenient inferface (view at Coop)
from edsl import Model, ModelList, QuestionFreeText
ml = ModelList(Model(m) for m in ["gpt-4o", "gemini-1.5-flash"])
q = QuestionFreeText(
question_name = "example",
question_text = "What is your top tip for using LLMs to answer surveys?"
)
results = q.by(ml).run()
results.select("model", "example")
model.model answer.example gpt-4o When using large language models (LLMs) to answer surveys, my top tip is to ensure that the ... gemini-1.5-flash My top tip for using LLMs to answer surveys is to **treat the LLM as a sophisticated brainst...
Piping & skip-logic: Build rich data labeling flows with features for piping answers and adding survey logic such as skip and stop rules (view at Coop):
from edsl import QuestionMultipleChoice, QuestionFreeText, Survey
q1 = QuestionMultipleChoice(
question_name = "color",
question_text = "What is your favorite primary color?",
question_options = ["red", "yellow", "blue"]
)
q2 = QuestionFreeText(
question_name = "flower",
question_text = "Name a flower that is {{ color.answer }}."
)
survey = Survey(questions = [q1, q2])
results = survey.run()
results.select("color", "flower")
answer.color answer.flower blue A commonly known blue flower is the bluebell. Another example is the cornflower.
Caching: API calls to LLMs are cached automatically, allowing you to retrieve responses to questions that have already been run and reproduce experiments at no cost. Learn more about how the universal remote cache works.
Flexibility: Choose whether to run surveys on your own computer or at the Expected Parrot server.
Tools for collaboration: Easily share workflows and projects privately or publicly at Coop: an integrated platform for AI-based research. Your account comes with free credits for running surveys, and lets you securely share keys, track expenses and usage for your team.
Built-in tools for analyis: Analyze results as specified datasets from your account or workspace. Easily import data to use with your surveys and export results..
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for edsl
Similar Open Source Tools
edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.
superpipe
Superpipe is a lightweight framework designed for building, evaluating, and optimizing data transformation and data extraction pipelines using LLMs. It allows users to easily combine their favorite LLM libraries with Superpipe's building blocks to create pipelines tailored to their unique data and use cases. The tool facilitates rapid prototyping, evaluation, and optimization of end-to-end pipelines for tasks such as classification and evaluation of job departments based on work history. Superpipe also provides functionalities for evaluating pipeline performance, optimizing parameters for cost, accuracy, and speed, and conducting grid searches to experiment with different models and prompts.
ag2
Ag2 is a lightweight and efficient tool for generating automated reports from data sources. It simplifies the process of creating reports by allowing users to define templates and automate the data extraction and formatting. With Ag2, users can easily generate reports in various formats such as PDF, Excel, and CSV, saving time and effort in manual report generation tasks.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.
LightAgent
LightAgent is a lightweight, open-source active Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex goals, and multi-model support. It enables simpler self-learning agents, seamless integration with major chat frameworks, and quick tool generation. LightAgent also supports memory modules, tool integration, tree of thought planning, multi-agent collaboration, streaming API, agent self-learning, Langfuse log tracking, and agent assessment. It is compatible with various large models and offers features like intelligent customer service, data analysis, automated tools, and educational assistance.

LightAgent
LightAgent is a lightweight, open-source Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex task handling, and multi-model support. It also features a streaming API, tool generator, agent self-learning, adaptive tool mechanism, and more. LightAgent is designed for intelligent customer service, data analysis, automated tools, and educational assistance.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.
llmware
LLMWare is a framework for quickly developing LLM-based applications including Retrieval Augmented Generation (RAG) and Multi-Step Orchestration of Agent Workflows. This project provides a comprehensive set of tools that anyone can use - from a beginner to the most sophisticated AI developer - to rapidly build industrial-grade, knowledge-based enterprise LLM applications. Our specific focus is on making it easy to integrate open source small specialized models and connecting enterprise knowledge safely and securely.
pipelex
Pipelex is an open-source devtool designed to transform how users build repeatable AI workflows. It acts as a Docker or SQL for AI operations, allowing users to create modular 'pipes' using different LLMs for structured outputs. These pipes can be connected sequentially, in parallel, or conditionally to build complex knowledge transformations from reusable components. With Pipelex, users can share and scale proven methods instantly, saving time and effort in AI workflow development.

curator
Bespoke Curator is an open-source tool for data curation and structured data extraction. It provides a Python library for generating synthetic data at scale, with features like programmability, performance optimization, caching, and integration with HuggingFace Datasets. The tool includes a Curator Viewer for dataset visualization and offers a rich set of functionalities for creating and refining data generation strategies.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.

FlashRank
FlashRank is an ultra-lite and super-fast Python library designed to add re-ranking capabilities to existing search and retrieval pipelines. It is based on state-of-the-art Language Models (LLMs) and cross-encoders, offering support for pairwise/pointwise rerankers and listwise LLM-based rerankers. The library boasts the tiniest reranking model in the world (~4MB) and runs on CPU without the need for Torch or Transformers. FlashRank is cost-conscious, with a focus on low cost per invocation and smaller package size for efficient serverless deployments. It supports various models like ms-marco-TinyBERT, ms-marco-MiniLM, rank-T5-flan, ms-marco-MultiBERT, and more, with plans for future model additions. The tool is ideal for enhancing search precision and speed in scenarios where lightweight models with competitive performance are preferred.
call-center-ai
Call Center AI is an AI-powered call center solution leveraging Azure and OpenAI GPT. It allows for AI agent-initiated phone calls or direct calls to the bot from a configured phone number. The bot is customizable for various industries like insurance, IT support, and customer service, with features such as accessing claim information, conversation history, language change, SMS sending, and more. The project is a proof of concept showcasing the integration of Azure Communication Services, Azure Cognitive Services, and Azure OpenAI for an automated call center solution.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
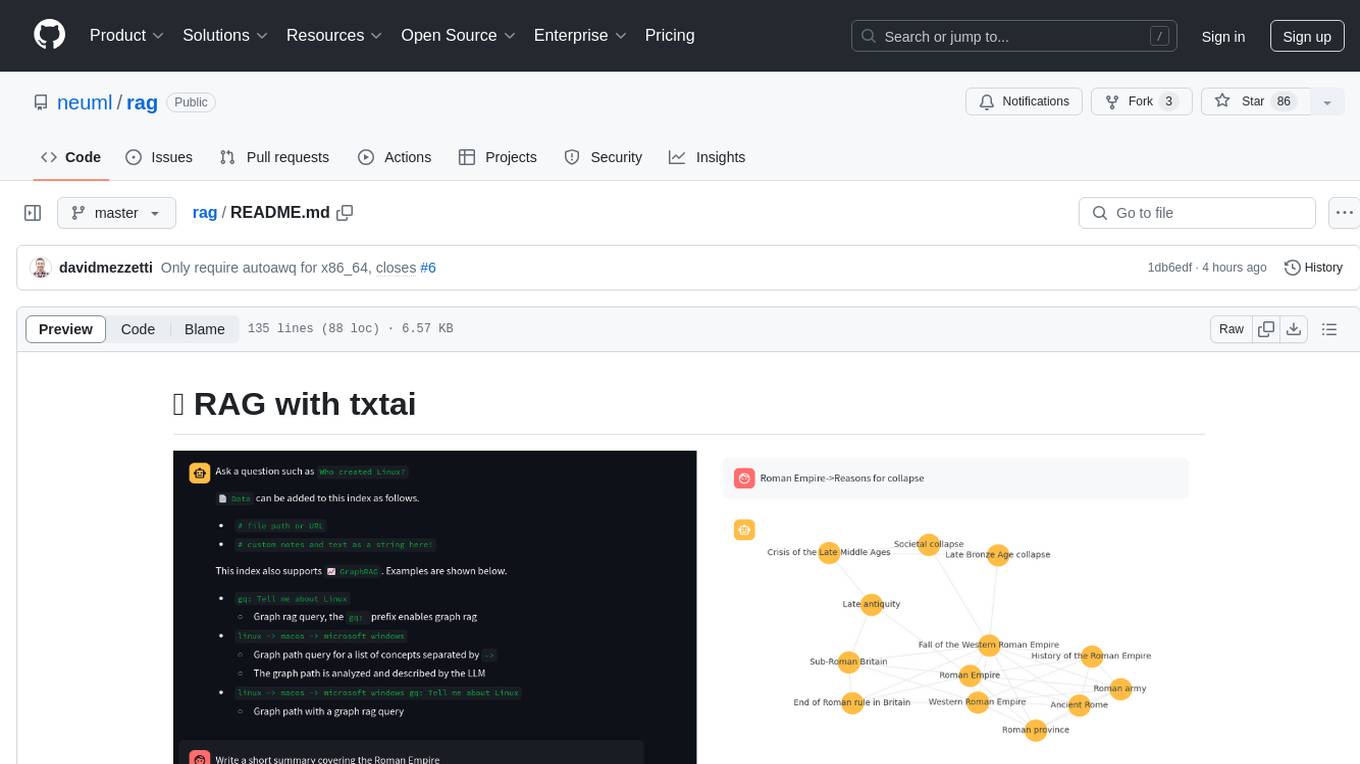
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.