
ppl.llm.serving
None
Stars: 126

ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
README:
ppl.llm.serving is a part of PPL.LLM system.

We recommend users who are new to this project to read the Overview of system.
ppl.llm.serving is a serving based on ppl.nn for various Large Language Models(LLMs). This repository contains a server based on gRPC and inference support for LLaMA.
- Linux running on x86_64 or arm64 CPUs
- GCC >= 9.4.0
- CMake >= 3.18
- Git >= 2.7.0
- CUDA Toolkit >= 11.4. 11.6 recommended. (for CUDA)
- Rust & cargo >= 1.8.0. (for Huggingface Tokenizer)
Here is a brief tutorial, refer to LLaMA Guide for more details.
-
Installing Prerequisites(on Debian or Ubuntu for example)
apt-get install build-essential cmake git
-
Cloning Source Code
git clone https://github.com/openppl-public/ppl.llm.serving.git
-
Building from Source
./build.sh -DPPLNN_USE_LLM_CUDA=ON -DPPLNN_CUDA_ENABLE_NCCL=ON -DPPLNN_ENABLE_CUDA_JIT=OFF -DPPLNN_CUDA_ARCHITECTURES="'80;86;87'" -DPPLCOMMON_CUDA_ARCHITECTURES="'80;86;87'" -DPPL_LLM_ENABLE_GRPC_SERVING=ON
NCCL is required if multiple GPU devices are used.
We support Sync Decode feature (mainly for offline_inference), which means model forward and decode in the same thread. To enable this feature, compile with marco
-DPPL_LLM_SERVING_SYNC_DECODE=ON. -
Exporting Models
Refer to ppl.pmx for details.
-
Running Server
./ppl_llm_server \ --model-dir /data/model \ --model-param-path /data/model/params.json \ --tokenizer-path /data/tokenizer.model \ --tensor-parallel-size 1 \ --top-p 0.0 \ --top-k 1 \ --max-tokens-scale 0.94 \ --max-input-tokens-per-request 4096 \ --max-output-tokens-per-request 4096 \ --max-total-tokens-per-request 8192 \ --max-running-batch 1024 \ --max-tokens-per-step 8192 \ --host 127.0.0.1 \ --port 23333You are expected to give the correct values before running the server.
-
model-dir: path of models exported by ppl.pmx. -
model-param-path: params of models.$model_dir/params.json. -
tokenizer-path: tokenizer files forsentencepiece.
-
-
Running client: send request through gRPC to query the model
./ppl-build/client_sample 127.0.0.1:23333
See tools/client_sample.cc for more details.
-
Benchmarking
./ppl-build/client_qps_measure --target=127.0.0.1:23333 --tokenizer=/path/to/tokenizer/path --dataset=tools/samples_1024.json --request_rate=inf
See tools/client_qps_measure.cc for more details.
--request_rateis the number of request per second, and valueinfmeans send all client request with no interval. -
Running inference offline:
./offline_inference \ --model-dir /data/model \ --model-param-path /data/model/params.json \ --tokenizer-path /data/tokenizer.model \ --tensor-parallel-size 1 \ --top-p 0.0 \ --top-k 1 \ --max-tokens-scale 0.94 \ --max-input-tokens-per-request 4096 \ --max-output-tokens-per-request 4096 \ --max-total-tokens-per-request 8192 \ --max-running-batch 1024 \ --max-tokens-per-step 8192 \ --host 127.0.0.1 \ --port 23333See tools/offline_inference.cc for more details.
This project is distributed under the Apache License, Version 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ppl.llm.serving
Similar Open Source Tools
ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.
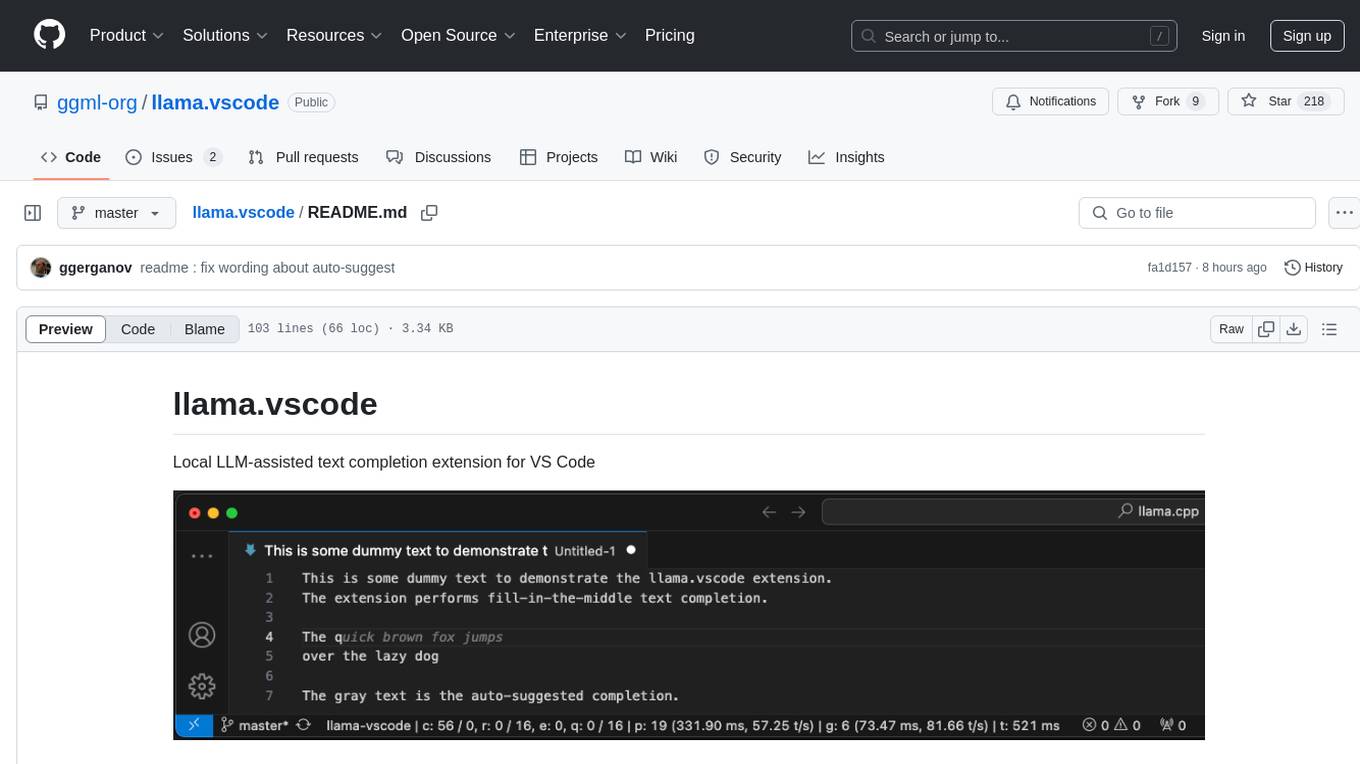
llama.vscode
llama.vscode is a local LLM-assisted text completion extension for Visual Studio Code. It provides auto-suggestions on input, allows accepting suggestions with shortcuts, and offers various features to enhance text completion. The extension is designed to be lightweight and efficient, enabling high-quality completions even on low-end hardware. Users can configure the scope of context around the cursor and control text generation time. It supports very large contexts and displays performance statistics for better user experience.
zml
ZML is a high-performance AI inference stack built for production, using Zig language, MLIR, and Bazel. It allows users to create exciting AI projects, run pre-packaged models like MNIST, TinyLlama, OpenLLama, and Meta Llama, and compile models for accelerator runtimes. Users can also run tests, explore examples, and contribute to the project. ZML is licensed under the Apache 2.0 license.
DALM
The DALM (Domain Adapted Language Modeling) toolkit is designed to unify general LLMs with vector stores to ground AI systems in efficient, factual domains. It provides developers with tools to build on top of Arcee's open source Domain Pretrained LLMs, enabling organizations to deeply tailor AI according to their unique intellectual property and worldview. The toolkit contains code for fine-tuning a fully differential Retrieval Augmented Generation (RAG-end2end) architecture, incorporating in-batch negative concept alongside RAG's marginalization for efficiency. It includes training scripts for both retriever and generator models, evaluation scripts, data processing codes, and synthetic data generation code.
aiohttp-client-cache
aiohttp-client-cache is an asynchronous persistent cache for aiohttp client requests, based on requests-cache. It is easy to use, customizable, and persistent, with several storage backends available, including SQLite, DynamoDB, MongoDB, DragonflyDB, and Redis.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.
obs-localvocal
LocalVocal is a Speech AI assistant OBS Plugin that enables users to transcribe speech into text and translate it into any language locally on their machine. The plugin runs OpenAI's Whisper for real-time speech processing and prediction. It supports features like transcribing audio in real-time, displaying captions on screen, sending captions to files, syncing captions with recordings, and translating captions to major languages. Users can bring their own Whisper model, filter or replace captions, and experience partial transcriptions for streaming. The plugin is privacy-focused, requiring no GPU, cloud costs, network, or downtime.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
habitat-sim
Habitat-Sim is a high-performance physics-enabled 3D simulator with support for 3D scans of indoor/outdoor spaces, CAD models of spaces and piecewise-rigid objects, configurable sensors, robots described via URDF, and rigid-body mechanics. It prioritizes simulation speed over the breadth of simulation capabilities, achieving several thousand frames per second (FPS) running single-threaded and over 10,000 FPS multi-process on a single GPU when rendering a scene from the Matterport3D dataset. Habitat-Sim simulates a Fetch robot interacting in ReplicaCAD scenes at over 8,000 steps per second (SPS), where each ‘step’ involves rendering 1 RGBD observation (128×128 pixels) and rigid-body dynamics for 1/30sec.
ai-containers
This repository contains Dockerfiles, scripts, yaml files, Helm charts, etc. used to scale out AI containers with versions of TensorFlow and PyTorch optimized for Intel platforms. Scaling is done with python, Docker, kubernetes, kubeflow, cnvrg.io, Helm, and other container orchestration frameworks for use in the cloud and on-premise.
ModelGenerator
AIDO.ModelGenerator is a software stack designed for developing AI-driven Digital Organisms. It enables researchers to adapt pretrained models and generate finetuned models for various tasks. The framework supports rapid prototyping with experiments like applying pre-trained models to new data, developing finetuning tasks, benchmarking models, and testing new architectures. Built on PyTorch, HuggingFace, and Lightning, it facilitates seamless integration with these ecosystems. The tool caters to cross-disciplinary teams in ML & Bio, offering installation, usage, tutorials, and API reference in its documentation.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.
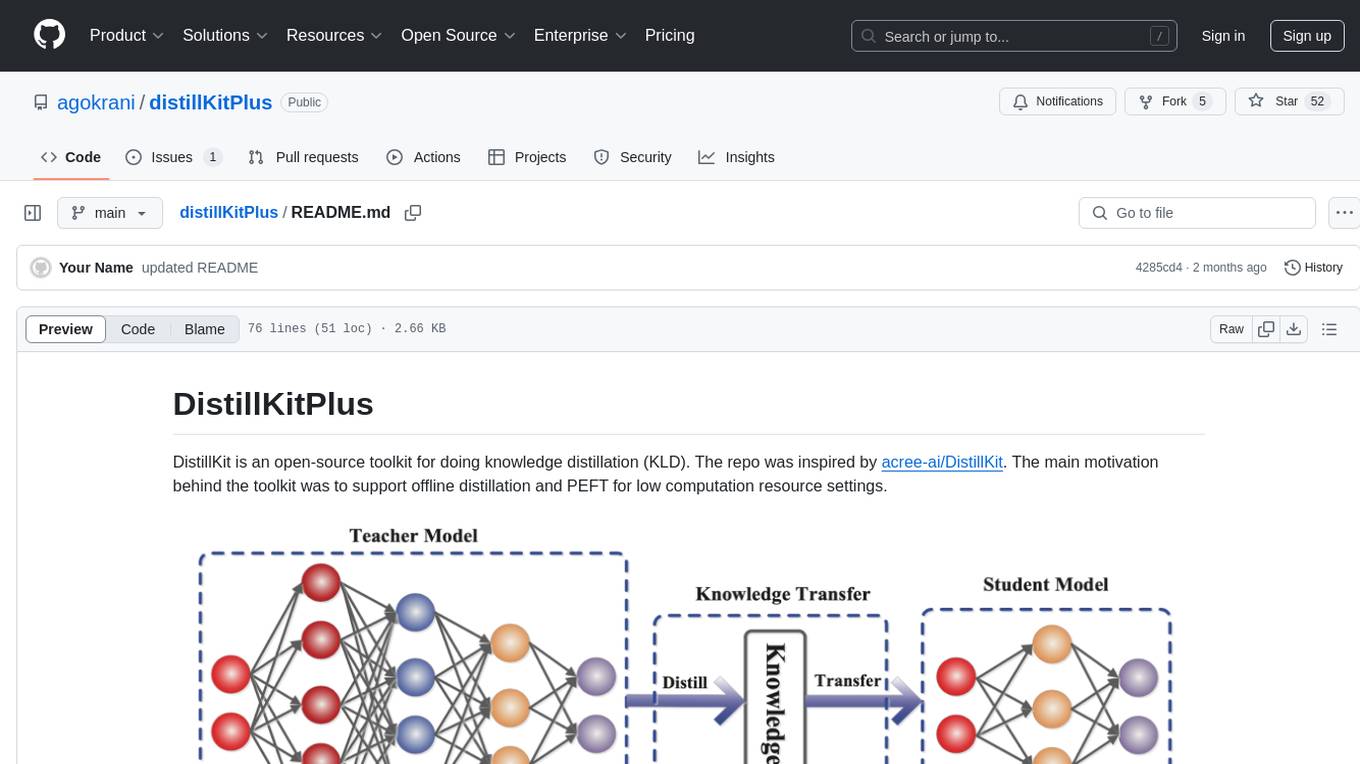
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.
stable-diffusion-discord-bot
A discord bot built to interface with the InvokeAI fork of stable-diffusion. It is a work in progress for a major rewrite of the arty project, compatible with `invokeai 5.1.1`. The bot supports various functionalities like building node graphs from job requests, refreshing renders using png metadata, removing backgrounds, job progress tracking, and LLM integration. Users can install custom invokeai nodes for advanced functionality and launch the bot natively or with docker. Patches and pull requests are welcomed.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.
For similar tasks

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.

ai-hub
AI Hub Project aims to continuously test and evaluate mainstream large language models, while accumulating and managing various effective model invocation prompts. It has integrated all mainstream large language models in China, including OpenAI GPT-4 Turbo, Baidu ERNIE-Bot-4, Tencent ChatPro, MiniMax abab5.5-chat, and more. The project plans to continuously track, integrate, and evaluate new models. Users can access the models through REST services or Java code integration. The project also provides a testing suite for translation, coding, and benchmark testing.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.

MMC
This repository, MMC, focuses on advancing multimodal chart understanding through large-scale instruction tuning. It introduces a dataset supporting various tasks and chart types, a benchmark for evaluating reasoning capabilities over charts, and an assistant achieving state-of-the-art performance on chart QA benchmarks. The repository provides data for chart-text alignment, benchmarking, and instruction tuning, along with existing datasets used in experiments. Additionally, it offers a Gradio demo for the MMCA model.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.