
client
⚡️ Gemini PHP is a community-maintained PHP API client that allows you to interact with the Gemini AI API.
Stars: 198
Gemini PHP is a PHP API client for interacting with the Gemini AI API. It allows users to generate content, chat, count tokens, configure models, embed resources, list models, get model information, troubleshoot timeouts, and test API responses. The client supports various features such as text-only input, text-and-image input, multi-turn conversations, streaming content generation, token counting, model configuration, and embedding techniques. Users can interact with Gemini's API to perform tasks related to natural language generation and text analysis.
README:



Gemini PHP is a community-maintained PHP API client that allows you to interact with the Gemini AI API.
- Fatih AYDIN github.com/aydinfatih
To complete this quickstart, make sure that your development environment meets the following requirements:
- Requires PHP 8.1+
First, install Gemini via the Composer package manager:
composer require google-gemini-php/clientIf you want to use beta features you should install beta branch:
composer require google-gemini-php/client:1.0.4-betaFor beta documentation: https://github.com/google-gemini-php/client/tree/beta
Ensure that the php-http/discovery composer plugin is allowed to run or install a client manually if your project does not already have a PSR-18 client integrated.
composer require guzzlehttp/guzzleTo use the Gemini API, you'll need an API key. If you don't already have one, create a key in Google AI Studio.
Interact with Gemini's API:
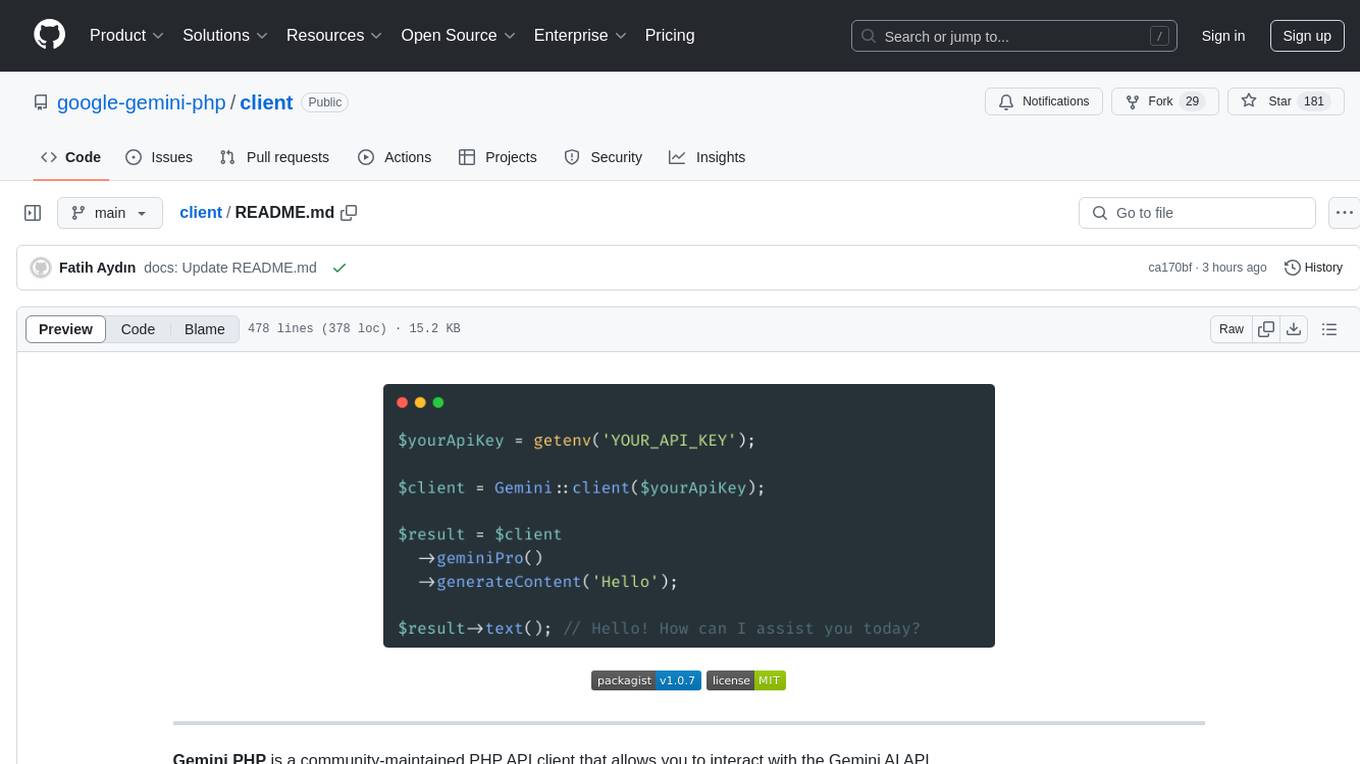
$yourApiKey = getenv('YOUR_API_KEY');
$client = Gemini::client($yourApiKey);
$result = $client->geminiPro()->generateContent('Hello');
$result->text(); // Hello! How can I assist you today?
// Custom Model
$result = $client->generativeModel(model: 'models/gemini-1.5-flash-001')->generateContent('Hello');
$result->text(); // Hello! How can I assist you today?
// Enum usage
$result = $client->geminiPro()->generativeModel(model: ModelType::GEMINI_FLASH);
$result->text(); // Hello! How can I assist you today?
// Enum method usage
$result = $client->geminiPro()->generativeModel(
model: ModelType::generateGeminiModel(
variation: ModelVariation::FLASH,
generation: 1.5,
version: "002"
), // models/gemini-1.5-flash-002
);
$result->text(); // Hello! How can I assist you today?
If necessary, it is possible to configure and create a separate client.
$yourApiKey = getenv('YOUR_API_KEY');
$client = Gemini::factory()
->withApiKey($yourApiKey)
->withBaseUrl('https://generativelanguage.example.com/v1') // default: https://generativelanguage.googleapis.com/v1/
->withHttpHeader('X-My-Header', 'foo')
->withQueryParam('my-param', 'bar')
->withHttpClient(new \GuzzleHttp\Client([])) // default: HTTP client found using PSR-18 HTTP Client Discovery
->withStreamHandler(fn(RequestInterface $request): ResponseInterface => $client->send($request, [
'stream' => true // Allows to provide a custom stream handler for the http client.
]))
->make();Generate a response from the model given an input message. If the input contains only text, use the gemini-pro model.
$yourApiKey = getenv('YOUR_API_KEY');
$client = Gemini::client($yourApiKey);
$result = $client->geminiPro()->generateContent('Hello');
$result->text(); // Hello! How can I assist you today?
If the input contains both text and image, use the gemini-pro-vision model.
$result = $client
->geminiFlash()
->generateContent([
'What is this picture?',
new Blob(
mimeType: MimeType::IMAGE_JPEG,
data: base64_encode(
file_get_contents('https://storage.googleapis.com/generativeai-downloads/images/scones.jpg')
)
)
]);
$result->text(); // The picture shows a table with a white tablecloth. On the table are two cups of coffee, a bowl of blueberries, a silver spoon, and some flowers. There are also some blueberry scones on the table.Using Gemini, you can build freeform conversations across multiple turns.
$chat = $client
->geminiPro()
->startChat(history: [
Content::parse(part: 'The stories you write about what I have to say should be one line. Is that clear?'),
Content::parse(part: 'Yes, I understand. The stories I write about your input should be one line long.', role: Role::MODEL)
]);
$response = $chat->sendMessage('Create a story set in a quiet village in 1600s France');
echo $response->text(); // Amidst rolling hills and winding cobblestone streets, the tranquil village of Beausoleil whispered tales of love, intrigue, and the magic of everyday life in 17th century France.
$response = $chat->sendMessage('Rewrite the same story in 1600s England');
echo $response->text(); // In the heart of England's lush countryside, amidst emerald fields and thatched-roof cottages, the village of Willowbrook unfolded a tapestry of love, mystery, and the enchantment of ordinary days in the 17th century.The
gemini-pro-visionmodel (for text-and-image input) is not yet optimized for multi-turn conversations. Make sure to use gemini-pro and text-only input for chat use cases.
By default, the model returns a response after completing the entire generation process. You can achieve faster interactions by not waiting for the entire result, and instead use streaming to handle partial results.
$stream = $client
->geminiPro()
->streamGenerateContent('Write long a story about a magic backpack.');
foreach ($stream as $response) {
echo $response->text();
}When using long prompts, it might be useful to count tokens before sending any content to the model.
$response = $client
->geminiPro()
->countTokens('Write a story about a magic backpack.');
echo $response->totalTokens; // 9Every prompt you send to the model includes parameter values that control how the model generates a response. The model can generate different results for different parameter values. Learn more about model parameters.
Also, you can use safety settings to adjust the likelihood of getting responses that may be considered harmful. By default, safety settings block content with medium and/or high probability of being unsafe content across all dimensions. Learn more about safety settings.
use Gemini\Data\GenerationConfig;
use Gemini\Enums\HarmBlockThreshold;
use Gemini\Data\SafetySetting;
use Gemini\Enums\HarmCategory;
$safetySettingDangerousContent = new SafetySetting(
category: HarmCategory::HARM_CATEGORY_DANGEROUS_CONTENT,
threshold: HarmBlockThreshold::BLOCK_ONLY_HIGH
);
$safetySettingHateSpeech = new SafetySetting(
category: HarmCategory::HARM_CATEGORY_HATE_SPEECH,
threshold: HarmBlockThreshold::BLOCK_ONLY_HIGH
);
$generationConfig = new GenerationConfig(
stopSequences: [
'Title',
],
maxOutputTokens: 800,
temperature: 1,
topP: 0.8,
topK: 10
);
$generativeModel = $client
->geminiPro()
->withSafetySetting($safetySettingDangerousContent)
->withSafetySetting($safetySettingHateSpeech)
->withGenerationConfig($generationConfig)
->generateContent("Write a story about a magic backpack.");Embedding is a technique used to represent information as a list of floating point numbers in an array. With Gemini, you can represent text (words, sentences, and blocks of text) in a vectorized form, making it easier to compare and contrast embeddings. For example, two texts that share a similar subject matter or sentiment should have similar embeddings, which can be identified through mathematical comparison techniques such as cosine similarity.
Use the embedding-001 model with either embedContents or batchEmbedContents:
$response = $client
->embeddingModel()
->embedContent("Write a story about a magic backpack.");
print_r($response->embedding->values);
//[
// [0] => 0.008624583
// [1] => -0.030451821
// [2] => -0.042496547
// [3] => -0.029230341
// [4] => 0.05486475
// [5] => 0.006694871
// [6] => 0.004025645
// [7] => -0.007294857
// [8] => 0.0057651913
// ...
//]$response = $client
->embeddingModel()
->batchEmbedContents("Bu bir testtir", "Deneme123");
print_r($response->embeddings);
// [
// [0] => Gemini\Data\ContentEmbedding Object
// (
// [values] => Array
// (
// [0] => 0.035855837
// [1] => -0.049537655
// [2] => -0.06834927
// [3] => -0.010445258
// [4] => 0.044641383
// [5] => 0.031156342
// [6] => -0.007810312
// [7] => -0.0106866965
// ...
// ),
// ),
// [1] => Gemini\Data\ContentEmbedding Object
// (
// [values] => Array
// (
// [0] => 0.035855837
// [1] => -0.049537655
// [2] => -0.06834927
// [3] => -0.010445258
// [4] => 0.044641383
// [5] => 0.031156342
// [6] => -0.007810312
// [7] => -0.0106866965
// ...
// ),
// ),
// ]Use list models to see the available Gemini models:
-
pageSize (optional): The maximum number of Models to return (per page).
If unspecified, 50 models will be returned per page. This method returns at most 1000 models per page, even if you pass a larger pageSize. -
nextPageToken (optional): A page token, received from a previous models.list call.
Provide the pageToken returned by one request as an argument to the next request to retrieve the next page. When paginating, all other parameters provided to models.list must match the call that provided the page token.
$response = $client->models()->list(pageSize: 3, nextPageToken: 'ChFtb2RlbHMvZ2VtaW5pLXBybw==');
$response->models;
//[
// [0] => Gemini\Data\Model Object
// (
// [name] => models/gemini-pro
// [version] => 001
// [displayName] => Gemini Pro
// [description] => The best model for scaling across a wide range of tasks
// ...
// )
// [1] => Gemini\Data\Model Object
// (
// [name] => models/gemini-pro-vision
// [version] => 001
// [displayName] => Gemini Pro Vision
// [description] => The best image understanding model to handle a broad range of applications
// ...
// )
// [2] => Gemini\Data\Model Object
// (
// [name] => models/embedding-001
// [version] => 001
// [displayName] => Embedding 001
// [description] => Obtain a distributed representation of a text.
// ...
// )
//]$response->nextPageToken // Chltb2RlbHMvZ2VtaW5pLTEuMC1wcm8tMDAxGet information about a model, such as version, display name, input token limit, etc.
$response = $client->models()->retrieve(ModelType::GEMINI_PRO);
$response->model;
//Gemini\Data\Model Object
//(
// [name] => models/gemini-pro
// [version] => 001
// [displayName] => Gemini Pro
// [description] => The best model for scaling across a wide range of tasks
// ...
//)You may run into a timeout when sending requests to the API. The default timeout depends on the HTTP client used.
You can increase the timeout by configuring the HTTP client and passing in to the factory.
This example illustrates how to increase the timeout using Guzzle.
Gemini::factory()
->withApiKey($apiKey)
->withHttpClient(new \GuzzleHttp\Client(['timeout' => $timeout]))
->make();The package provides a fake implementation of the Gemini\Client class that allows you to fake the API responses.
To test your code ensure you swap the Gemini\Client class with the Gemini\Testing\ClientFake class in your test case.
The fake responses are returned in the order they are provided while creating the fake client.
All responses are having a fake() method that allows you to easily create a response object by only providing the parameters relevant for your test case.
use Gemini\Testing\ClientFake;
use Gemini\Responses\GenerativeModel\GenerateContentResponse;
$client = new ClientFake([
GenerateContentResponse::fake([
'candidates' => [
[
'content' => [
'parts' => [
[
'text' => 'success',
],
],
],
],
],
]),
]);
$result = $fake->geminiPro()->generateContent('test');
expect($result->text())->toBe('success');In case of a streamed response you can optionally provide a resource holding the fake response data.
use Gemini\Testing\ClientFake;
use Gemini\Responses\GenerativeModel\GenerateContentResponse;
$client = new ClientFake([
GenerateContentResponse::fakeStream(),
]);
$result = $client->geminiPro()->streamGenerateContent('Hello');
expect($response->getIterator()->current())
->text()->toBe('In the bustling city of Aethelwood, where the cobblestone streets whispered');After the requests have been sent there are various methods to ensure that the expected requests were sent:
// assert list models request was sent
$fake->models()->assertSent(callback: function ($method) {
return $method === 'list';
});
// or
$fake->assertSent(resource: Models::class, callback: function ($method) {
return $method === 'list';
});
$fake->geminiPro()->assertSent(function (string $method, array $parameters) {
return $method === 'generateContent' &&
$parameters[0] === 'Hello';
});
// or
$fake->assertSent(resource: GenerativeModel::class, model: ModelType::GEMINI_PRO, callback: function (string $method, array $parameters) {
return $method === 'generateContent' &&
$parameters[0] === 'Hello';
});
// assert 2 generative model requests were sent
$client->assertSent(resource: GenerativeModel::class, model: ModelType::GEMINI_PRO, callback: 2);
// or
$client->geminiPro()->assertSent(2);
// assert no generative model requests were sent
$client->assertNotSent(resource: GenerativeModel::class, model: ModelType::GEMINI_PRO);
// or
$client->geminiPro()->assertNotSent();
// assert no requests were sent
$client->assertNothingSent();To write tests expecting the API request to fail you can provide a Throwable object as the response.
$client = new ClientFake([
new ErrorException([
'message' => 'The model `gemini-basic` does not exist',
'status' => 'INVALID_ARGUMENT',
'code' => 400,
]),
]);
// the `ErrorException` will be thrown
$client->geminiPro()->generateContent('test');For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for client
Similar Open Source Tools
client
Gemini PHP is a PHP API client for interacting with the Gemini AI API. It allows users to generate content, chat, count tokens, configure models, embed resources, list models, get model information, troubleshoot timeouts, and test API responses. The client supports various features such as text-only input, text-and-image input, multi-turn conversations, streaming content generation, token counting, model configuration, and embedding techniques. Users can interact with Gemini's API to perform tasks related to natural language generation and text analysis.
client
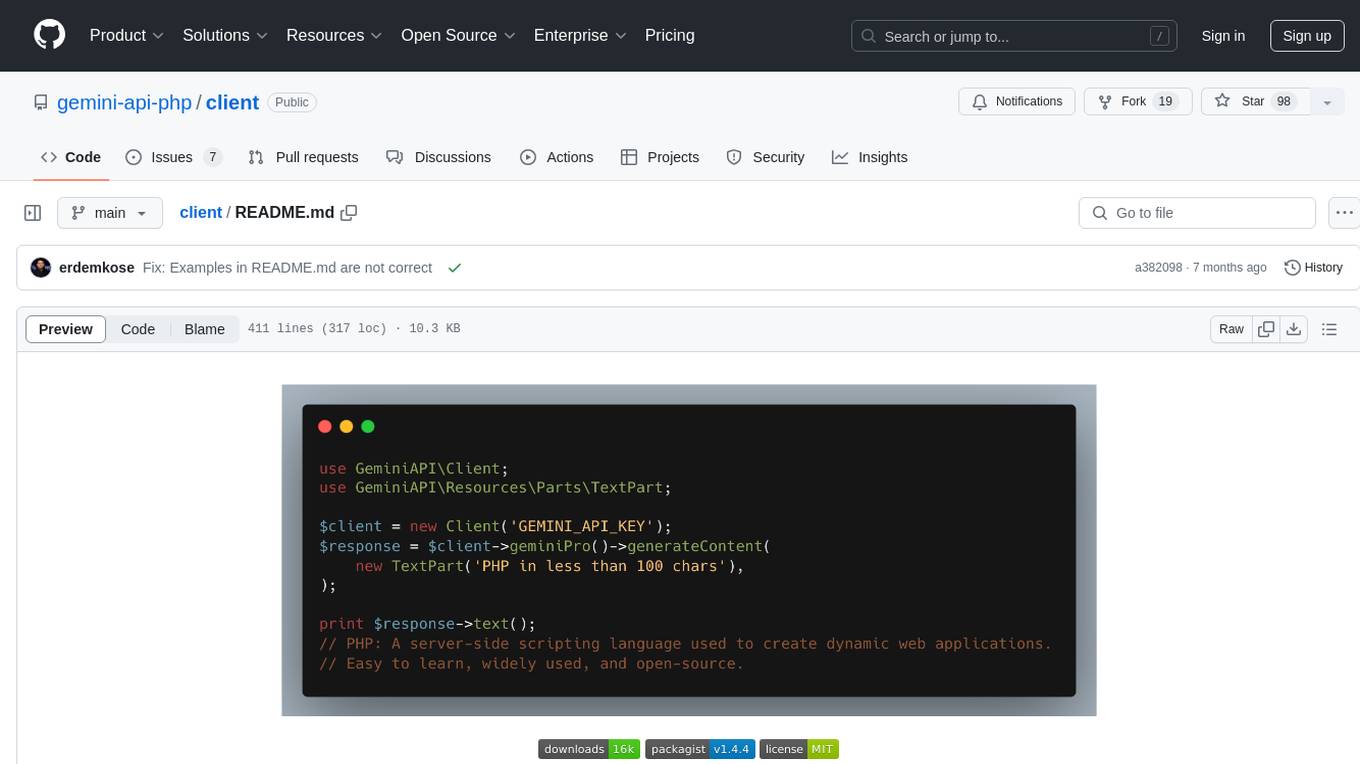
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.
llm-chain
LLM Chain is a PHP library for building LLM-based features and applications. It provides abstractions for Language Models and Embeddings Models from platforms like OpenAI, Azure, Google, Replicate, and others. The core feature is to interact with language models via messages, supporting different message types and content. LLM Chain also supports tool calling, document embedding, vector stores, similarity search, structured output, response streaming, image processing, audio processing, embeddings, parallel platform calls, and input/output processing. Contributions are welcome, and the repository contains fixture licenses for testing multi-modal features.

LarAgent
LarAgent is a framework designed to simplify the creation and management of AI agents within Laravel projects. It offers an Eloquent-like syntax for creating and managing AI agents, Laravel-style artisan commands, flexible agent configuration, structured output handling, image input support, and extensibility. LarAgent supports multiple chat history storage options, custom tool creation, event system for agent interactions, multiple provider support, and can be used both in Laravel and standalone environments. The framework is constantly evolving to enhance developer experience, improve AI capabilities, enhance security and storage features, and enable advanced integrations like provider fallback system, Laravel Actions integration, and voice chat support.
lmstudio.js
lmstudio.js is a pre-release alpha client SDK for LM Studio, allowing users to use local LLMs in JS/TS/Node. It is currently undergoing rapid development with breaking changes expected. Users can follow LM Studio's announcements on Twitter and Discord. The SDK provides API usage for loading models, predicting text, setting up the local LLM server, and more. It supports features like custom loading progress tracking, model unloading, structured output prediction, and cancellation of predictions. Users can interact with LM Studio through the CLI tool 'lms' and perform tasks like text completion, conversation, and getting prediction statistics.
java-genai
Java idiomatic SDK for the Gemini Developer APIs and Vertex AI APIs. The SDK provides a Client class for interacting with both APIs, allowing seamless switching between the 2 backends without code rewriting. It supports features like generating content, embedding content, generating images, upscaling images, editing images, and generating videos. The SDK also includes options for setting API versions, HTTP request parameters, client behavior, and response schemas.
venom
Venom is a high-performance system developed with JavaScript to create a bot for WhatsApp, support for creating any interaction, such as customer service, media sending, sentence recognition based on artificial intelligence and all types of design architecture for WhatsApp.
UniChat
UniChat is a pipeline tool for creating online and offline chat-bots in Unity. It leverages Unity.Sentis and text vector embedding technology to enable offline mode text content search based on vector databases. The tool includes a chain toolkit for embedding LLM and Agent in games, along with middleware components for Text to Speech, Speech to Text, and Sub-classifier functionalities. UniChat also offers a tool for invoking tools based on ReActAgent workflow, allowing users to create personalized chat scenarios and character cards. The tool provides a comprehensive solution for designing flexible conversations in games while maintaining developer's ideas.
x
Ant Design X is a tool for crafting AI-driven interfaces effortlessly. It is built on the best practices of enterprise-level AI products, offering flexible and diverse atomic components for various AI dialogue scenarios. The tool provides out-of-the-box model integration with inference services compatible with OpenAI standards. It also enables efficient management of conversation data flows, supports rich template options, complete TypeScript support, and advanced theme customization. Ant Design X is designed to enhance development efficiency and deliver exceptional AI interaction experiences.
OpenAI-DotNet
OpenAI-DotNet is a simple C# .NET client library for OpenAI to use through their RESTful API. It is independently developed and not an official library affiliated with OpenAI. Users need an OpenAI API account to utilize this library. The library targets .NET 6.0 and above, working across various platforms like console apps, winforms, wpf, asp.net, etc., and on Windows, Linux, and Mac. It provides functionalities for authentication, interacting with models, assistants, threads, chat, audio, images, files, fine-tuning, embeddings, and moderations.

CodeTF
CodeTF is a Python transformer-based library for code large language models (Code LLMs) and code intelligence. It provides an interface for training and inferencing on tasks like code summarization, translation, and generation. The library offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, CodeTF enables parsing of function names, comments, and variable names. It supports fast model serving, fine-tuning of LLMs, various code intelligence tasks, preprocessed datasets, model evaluation, pretrained and fine-tuned models, and utilities to manipulate source code. CodeTF aims to facilitate the integration of state-of-the-art Code LLMs into real-world applications, ensuring a user-friendly environment for code intelligence tasks.
ax
Ax is a Typescript library that allows users to build intelligent agents inspired by agentic workflows and the Stanford DSP paper. It seamlessly integrates with multiple Large Language Models (LLMs) and VectorDBs to create RAG pipelines or collaborative agents capable of solving complex problems. The library offers advanced features such as streaming validation, multi-modal DSP, and automatic prompt tuning using optimizers. Users can easily convert documents of any format to text, perform smart chunking, embedding, and querying, and ensure output validation while streaming. Ax is production-ready, written in Typescript, and has zero dependencies.
bellman
Bellman is a unified interface to interact with language and embedding models, supporting various vendors like VertexAI/Gemini, OpenAI, Anthropic, VoyageAI, and Ollama. It consists of a library for direct interaction with models and a service 'bellmand' for proxying requests with one API key. Bellman simplifies switching between models, vendors, and common tasks like chat, structured data, tools, and binary input. It addresses the lack of official SDKs for major players and differences in APIs, providing a single proxy for handling different models. The library offers clients for different vendors implementing common interfaces for generating and embedding text, enabling easy interchangeability between models.
com.openai.unity
com.openai.unity is an OpenAI package for Unity that allows users to interact with OpenAI's API through RESTful requests. It is independently developed and not an official library affiliated with OpenAI. Users can fine-tune models, create assistants, chat completions, and more. The package requires Unity 2021.3 LTS or higher and can be installed via Unity Package Manager or Git URL. Various features like authentication, Azure OpenAI integration, model management, thread creation, chat completions, audio processing, image generation, file management, fine-tuning, batch processing, embeddings, and content moderation are available.

js-genai
The Google Gen AI JavaScript SDK is an experimental SDK for TypeScript and JavaScript developers to build applications powered by Gemini. It supports both the Gemini Developer API and Vertex AI. The SDK is designed to work with Gemini 2.0 features. Users can access API features through the GoogleGenAI classes, which provide submodules for querying models, managing caches, creating chats, uploading files, and starting live sessions. The SDK also allows for function calling to interact with external systems. Users can find more samples in the GitHub samples directory.
DeRTa
DeRTa (Refuse Whenever You Feel Unsafe) is a tool designed to improve safety in Large Language Models (LLMs) by training them to refuse compliance at any response juncture. The tool incorporates methods such as MLE with Harmful Response Prefix and Reinforced Transition Optimization (RTO) to address refusal positional bias and strengthen the model's capability to transition from potential harm to safety refusal. DeRTa provides training data, model weights, and evaluation scripts for LLMs, enabling users to enhance safety in language generation tasks.
For similar tasks

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.