
llm
A package abstracting llm capabilities for emacs.
Stars: 340

The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
README:
#+TITLE: llm package for emacs
- Introduction This library provides an interface for interacting with Large Language Models (LLMs). It allows elisp code to use LLMs while also giving end-users the choice to select their preferred LLM. This is particularly beneficial when working with LLMs since various high-quality models exist, some of which have paid API access, while others are locally installed and free but offer medium quality. Applications using LLMs can utilize this library to ensure compatibility regardless of whether the user has a local LLM or is paying for API access.
This library abstracts several kinds of features:
- Chat functionality: the ability to query the LLM and get a response, and continue to take turns writing to the LLM and receiving responses. The library supports both synchronous, asynchronous, and streaming responses.
- Chat with image and other kinda of media inputs are also supported, so that the user can input images and discuss them with the LLM.
- Tool use is supported, for having the LLM call elisp functions that it chooses, with arguments it provides.
- Embeddings: Send text and receive a vector that encodes the semantic meaning of the underlying text. Can be used in a search system to find similar passages.
- Prompt construction: Create a prompt to give to an LLM from one more sources of data.
Certain functionalities might not be available in some LLMs. Any such unsupported functionality will raise a 'not-implemented signal, or it may fail in some other way. Clients are recommended to check =llm-capabilities= when trying to do something beyond basic text chat.
- Packages using
llmThere a few packages using LLM (please inform us or open a PR to add anything here):
- [[https://github.com/s-kostyaev/ellama][ellama]], a package providing a host of useful ways to use LLMs to chat and transform text.
- [[https://github.com/douo/magit-gptcommit][magit-gptcommit]], a package providing autogenerated commit messages for use with [[https://magit.vc/][magit]].
- [[https://github.com/ahyatt/ekg/][ekg]], a sqlite-backed notetaking application that optionally interfaces with LLMs for note similarity and text generation in response to notes.
- Setting up providers
Users of an application that uses this package should not need to install it themselves. The llm package should be installed as a dependency when you install the package that uses it. However, you do need to require the llm module and set up the provider you will be using. Typically, applications will have a variable you can set. For example, let's say there's a package called "llm-refactoring", which has a variable
llm-refactoring-provider. You would set it up like so:
#+begin_src emacs-lisp (use-package llm-refactoring :init (require 'llm-openai) (setq llm-refactoring-provider (make-llm-openai :key my-openai-key)) #+end_src
Here my-openai-key would be a variable you set up before with your OpenAI key. Or, just substitute the key itself as a string. It's important to remember never to check your key into a public repository such as GitHub, because your key must be kept private. Anyone with your key can use the API, and you will be charged.
You can also use a function as a key, so you can store your key in a secure place and retrieve it via a function. For example, you could add a line to =~/.authinfo.gpg=:
#+begin_example machine llm.openai password #+end_example
And then set up your provider like: #+begin_src emacs-lisp (setq llm-refactoring-provider (make-llm-openai :key (plist-get (car (auth-source-search :host "llm.openai")) :secret))) #+end_src
All of the providers (except for =llm-fake=), can also take default parameters that will be used if they are not specified in the prompt. These are the same parameters as appear in the prompt, but prefixed with =default-chat-=. So, for example, if you find that you like Ollama to be less creative than the default, you can create your provider like:
#+begin_src emacs-lisp (make-llm-ollama :embedding-model "mistral:latest" :chat-model "mistral:latest" :default-chat-temperature 0.1) #+end_src
For embedding users. if you store the embeddings, you must set the embedding model. Even though there's no way for the llm package to tell whether you are storing it, if the default model changes, you may find yourself storing incompatible embeddings.
** Open AI
You can set up with make-llm-openai, with the following parameters:
-
:key, the Open AI key that you get when you sign up to use Open AI's APIs. Remember to keep this private. This is non-optional. -
:chat-model: A model name from the [[https://platform.openai.com/docs/models/gpt-4][list of Open AI's model names.]] Keep in mind some of these are not available to everyone. This is optional, and will default to a reasonable model. -
:embedding-model: A model name from [[https://platform.openai.com/docs/guides/embeddings/embedding-models][list of Open AI's embedding model names.]] This is optional, and will default to a reasonable model. ** Open AI Compatible There are many Open AI compatible APIs and proxies of Open AI. You can set up one withmake-llm-openai-compatible, with the following parameter:
-
:url, the URL of leading up to the command ("embeddings" or "chat/completions"). So, for example, "https://api.openai.com/v1/" is the URL to use Open AI (although if you wanted to do that, just usemake-llm-openaiinstead). -
:chat-model: The chat model that is supported by the provider. Some providers don't need a model to be set, but still require it in the API, so we default to "unset". -
:embedding-model: An embedding model name that is supported by the provider. This is also defaulted to "unset". ** Azure's Open AI Microsoft Azure has an Open AI integration, although it doesn't support everything Open AI does, such as tool use. You can set it up withmake-llm-azure, with the following parameter:
-
:url, the endpoint URL, such as "https://docs-test-001.openai.azure.com/". -
:key, the Azure key for Azure OpenAI service. -
:chat-model, the chat model, which must be deployed in Azure. -
embedding-model, the embedding model which must be deployed in Azure. ** GitHub Models GitHub now has its own platform for interacting with AI models. For a list of models check the [[https://github.com/marketplace/models][marketplace]]. You can set it up withmake-llm-github, with the following parameters: -
:key, a GitHub token or an Azure AI production key. -
:chat-model, the chat model, which can be any of the ones you have access for (currently o1 is restricted). -
:embedding-model, the embedding model, which can be better found [[https://github.com/marketplace?type=models&task=Embeddings][through a filter]]a. ** Gemini (not via Google Cloud) This is Google's AI model. You can get an API key via their [[https://makersuite.google.com/app/apikey][page on Google AI Studio]]. Set this up withmake-llm-gemini, with the following parameters: -
:key, the Google AI key that you get from Google AI Studio. -
:chat-model, the model name, from the [[https://ai.google.dev/models][list]] of models. This is optional and will default to the text Gemini model. -
:embedding-model: the model name, currently must be "embedding-001". This is optional and will default to "embedding-001". ** Vertex (Gemini via Google Cloud) This is mostly for those who want to use Google Cloud specifically, most users should use Gemini instead, which is easier to set up.
You can set up with make-llm-vertex, with the following parameters:
-
:project: Your project number from Google Cloud that has Vertex API enabled. -
:chat-model: A model name from the [[https://cloud.google.com/vertex-ai/docs/generative-ai/chat/chat-prompts#supported_model][list of Vertex's model names.]] This is optional, and will default to a reasonable model. -
:embedding-model: A model name from the [[https://cloud.google.com/vertex-ai/docs/generative-ai/embeddings/get-text-embeddings#supported_models][list of Vertex's embedding model names.]] This is optional, and will default to a reasonable model.
In addition to the provider, which you may want multiple of (for example, to charge against different projects), there are customizable variables:
-
llm-vertex-gcloud-binary: The binary to use for generating the API key. -
llm-vertex-gcloud-region: The gcloud region to use. It's good to set this to a region near where you are for best latency. Defaults to "us-central1".If you haven't already, you must run the following command before using this: #+begin_src sh gcloud beta services identity create --service=aiplatform.googleapis.com --project=PROJECT_ID #+end_src ** Claude [[https://docs.anthropic.com/claude/docs/intro-to-claude][Claude]] is Anthropic's large language model. It does not support embeddings. You can set it up with the following parameters:
=:key=: The API key you get from [[https://console.anthropic.com/settings/keys][Claude's settings page]]. This is required. =:chat-model=: One of the [[https://docs.anthropic.com/claude/docs/models-overview][Claude models]]. Defaults to "claude-3-opus-20240229", the most powerful model. ** Ollama [[https://ollama.ai/][Ollama]] is a way to run large language models locally. There are [[https://ollama.ai/library][many different models]] you can use with it, and some of them [[https://ollama.com/search?c=tools][support tool use]]. You set it up with the following parameters:
-
:scheme: The scheme (http/https) for the connection to ollama. This default to "http". -
:host: The host that ollama is run on. This is optional and will default to localhost. -
:port: The port that ollama is run on. This is optional and will default to the default ollama port. -
:chat-model: The model name to use for chat. This is not optional for chat use, since there is no default. -
:embedding-model: The model name to use for embeddings. Only [[https://ollama.com/search?q=&c=embedding][some models]] can be used for embeddings. This is not optional for embedding use, since there is no default. ** Ollama (authed) This is a variant of the Ollama provider, which is set up with the same parameters plus: -
:key: The authentication key of the provider.
The key is used to send a standard =Authentication= header. ** Deepseek [[https://deepseek.com][Deepseek]] is a company offers both reasoning and chat high-quality models. This provider connects to their server. It is also possible to run their model locally as a free model via Ollama. To use the service, you can set it up with the following parameters:
=:key=: The API Key you get from DeepSeek [[https://platform.deepseek.com/api_keys][API key page]]. This is required. =:chat-model=: One of the models from their [[https://api-docs.deepseek.com/quick_start/pricing][model list.]] ** GPT4All [[https://gpt4all.io/index.html][GPT4All]] is a way to run large language models locally. To use it with =llm= package, you must click "Enable API Server" in the settings. It does not offer embeddings or streaming functionality, though, so Ollama might be a better fit for users who are not already set up with local models. You can set it up with the following parameters:
-
:host: The host that GPT4All is run on. This is optional and will default to localhost. -
:port: The port that GPT4All is run on. This is optional and will default to the default ollama port. -
:chat-model: The model name to use for chat. This is not optional for chat use, since there is no default. ** llama.cpp [[https://github.com/ggerganov/llama.cpp][llama.cpp]] is a way to run large language models locally. To use it with the =llm= package, you need to start the server (with the "--embedding" flag if you plan on using embeddings). The server must be started with a model, so it is not possible to switch models until the server is restarted to use the new model. As such, model is not a parameter to the provider, since the model choice is already set once the server starts.
There is a deprecated provider, however it is no longer needed. Instead, llama cpp is Open AI compatible, so the Open AI Compatible provider should work. ** Fake This is a client that makes no call, but it just there for testing and debugging. Mostly this is of use to programmatic clients of the llm package, but end users can also use it to understand what will be sent to the LLMs. It has the following parameters:
-
:output-to-buffer: if non-nil, the buffer or buffer name to append the request sent to the LLM to. -
:chat-action-func: a function that will be called to provide a string or symbol and message cons which are used to raise an error. -
:embedding-action-func: a function that will be called to provide a vector or symbol and message cons which are used to raise an error.
- Models
When picking a chat or embedding model, anything can be used, as long as the service thinks it is valid. However, models vary on context size and capabilities. The =llm-prompt= module, and any client, can depend on the context size of the model via
llm-chat-token-limit. Similarly, some models have different capabilities, exposed inllm-capabilities. The =llm-models= module defines a list of popular models, but this isn't a comprehensive list. If you want to add a model, it is fairly easy to do, for example here is adding the Mistral model (which is already included, though):
#+begin_src emacs-lisp (require 'llm-models) (llm-models-add :name "Mistral" :symbol 'mistral :capabilities '(generation tool-use free-software) :context-length 8192 :regex "mistral")) #+end_src
The =:regex= needs to uniquely identify the model passed in from a provider's chat or embedding model.
Once this is done, the model will be recognized to have the given context length and capabilities.
- =llm= and the use of non-free LLMs
The =llm= package is part of GNU Emacs by being part of GNU ELPA. Unfortunately, the most popular LLMs in use are non-free, which is not what GNU software should be promoting by inclusion. On the other hand, by use of the =llm= package, the user can make sure that any client that codes against it will work with free models that come along. It's likely that sophisticated free LLMs will, emerge, although it's unclear right now what free software means with respect to LLMs. Because of this tradeoff, we have decided to warn the user when using non-free LLMs (which is every LLM supported right now except the fake one). You can turn this off the same way you turn off any other warning, by clicking on the left arrow next to the warning when it comes up. Alternatively, you can set
llm-warn-on-nonfreetonil. This can be set via customization as well.
To build upon the example from before: #+begin_src emacs-lisp (use-package llm-refactoring :init (require 'llm-openai) (setq llm-refactoring-provider (make-llm-openai :key my-openai-key) llm-warn-on-nonfree nil) #+end_src
- Programmatic use
Client applications should require the =llm= package, and code against it. Most functions are generic, and take a struct representing a provider as the first argument. The client code, or the user themselves can then require the specific module, such as =llm-openai=, and create a provider with a function such as
(make-llm-openai :key user-api-key). The client application will use this provider to call all the generic functions.
For all callbacks, the callback will be executed in the buffer the function was first called from. If the buffer has been killed, it will be executed in a temporary buffer instead. ** Main functions
-
llm-chat provider prompt multi-output: With user-chosenprovider, and allm-chat-promptstructure (created byllm-make-chat-prompt), send that prompt to the LLM and wait for the string output. -
llm-chat-async provider prompt response-callback error-callback multi-output: Same asllm-chat, but executes in the background. Takes aresponse-callbackwhich will be called with the text response. Theerror-callbackwill be called in case of error, with the error symbol and an error message. -
llm-chat-streaming provider prompt partial-callback response-callback error-callback multi-output: Similar tollm-chat-async, but request a streaming response. As the response is built up,partial-callbackis called with the all the text retrieved up to the current point. Finally,reponse-callbackis called with the complete text. -
llm-embedding provider string: With the user-chosenprovider, send a string and get an embedding, which is a large vector of floating point values. The embedding represents the semantic meaning of the string, and the vector can be compared against other vectors, where smaller distances between the vectors represent greater semantic similarity. -
llm-embedding-async provider string vector-callback error-callback: Same asllm-embeddingbut this is processed asynchronously.vector-callbackis called with the vector embedding, and, in case of error,error-callbackis called with the same arguments as inllm-chat-async. -
llm-batch-embedding provider strings: same asllm-embedding, but takes in a list of strings, and returns a list of vectors whose order corresponds to the ordering of the strings. -
llm-batch-embedding-async provider strings vectors-callback error-callback: same asllm-embedding-async, but takes in a list of strings, and returns a list of vectors whose order corresponds to the ordering of the strings. -
llm-count-tokens provider string: Count how many tokens are instring. This may vary byprovider, because some provideres implement an API for this, but typically is always about the same. This gives an estimate if the provider has no API support. -
llm-cancel-request requestCancels the given request, if possible. Therequestobject is the return value of async and streaming functions. -
llm-name provider. Provides a short name of the model or provider, suitable for showing to users. -
llm-models provider. Return a list of all the available model names for the provider. This could be either embedding or chat models. You can usellm-models-matchto filter on models that have a certain capability (as long as they are inllm-models). -
llm-chat-token-limit. Gets the token limit for the chat model. This isn't possible for some backends like =llama.cpp=, in which the model isn't selected or known by this library.And the following helper functions:
-
llm-make-chat-prompt text &keys context examples tools temperature max-tokens response-format reasoning non-standard-params: This is how you make prompts.textcan be a string (the user input to the llm chatbot), or a list representing a series of back-and-forth exchanges, of odd number, with the last element of the list representing the user's latest input. This supports inputting context (also commonly called a system prompt, although it isn't guaranteed to replace the actual system prompt), examples, and other important elements, all detailed in the docstring for this function.response-formatcan be'json, to force JSON output, or a JSON schema (see below) but the prompt also needs to mention and ideally go into detail about what kind of JSON response is desired. Providers with thejson-responsecapability support JSON output, and it will be ignored if unsupported.reasoningcan be'none,'light,'mediumor'maximumto control how much thinking the LLM can do (if it is a reasoning model). Thenon-standard-paramslet you specify other options that might vary per-provider, and for this, the correctness is up to the client. -
llm-chat-prompt-to-text prompt: From a prompt, return a string representation. This is not usually suitable for passing to LLMs, but for debugging purposes. -
llm-chat-streaming-to-point provider prompt buffer point finish-callback: Same basic arguments asllm-chat-streaming, but will stream topointinbuffer. -
llm-chat-prompt-append-response prompt response role: Append a new response (from the user, usually) to the prompt. Theroleis optional, and defaults to'user. *** Return and multi-output The default return value is text except for when tools are called, in which case it is a record of the return values of the tools called.
-
Models can potentially return many types of information, though, so the multi-output option was added to the llm-chat calls so that the single return value can instead be a plist that represents the various possible values. In the case of llm-chat, this plist is returned, in llm-chat-async, it is passed to the success function. In llm-chat-streaming, it is passed to the success function, and each partial update will be a plist, with no guarantee that the same keys will always be present.
The possible plist keys are:
-
:text, for the main textual output. -
:reasoning, for reasoning output, when the model separates it. -
:tool-uses, the tools that the llm identified to be called, as a list of plists, with:nameand:argsvalues. -
:tool-results, the results of calling the tools. *** JSON schema By using theresponse-formatargument tollm-make-chat-prompt, you can ask the LLM to return items according to a specified JSON schema, based on the [[https://json-schema.org][JSON Schema Spec]]. Not everything is supported, but the most commonly used parts are. To specify the JSON schema, we use a plist-based approach. JSON objects are defined with(:type object :properties (: : ... : ) :required ( ... )). Arrays are defined with(:type array :items ). Enums are defined with(:enum [ ]). You can also request integers, strings, and other types defined by the JSON Schema Spec, by just having(:type ). Typically, LLMs often require the top-level schema object to be an object, and often that all properties on the top-level object must be required.
Some examples: #+begin_src emacs-lisp (llm-chat my-provider (llm-make-chat-prompt "How many countries are there? Return the result as JSON." :response-format '(:type object :properties (:num (:type "integer")) :required ["num"]))) #+end_src
#+RESULTS: : {"num":195}
#+begin_src emacs-lisp (llm-chat my-provider (llm-make-chat-prompt "Which editor is hard to quit? Return the result as JSON." :response-format '(:type object :properties (:editor (:enum ["emacs" "vi" "vscode"]) :authors (:type "array" :items (:type "string"))) :required ["editor" "authors"]))) #+end_src
#+RESULTS: : {"editor":"vi","authors":["Bram Moolenaar","Bill Joy"]}
** Logging
Interactions with the =llm= package can be logged by setting llm-log to a non-nil value. This should be done only when developing. The log can be found in the =llm log= buffer.
** How to handle conversations
Conversations can take place by repeatedly calling llm-chat and its variants. The prompt should be constructed with llm-make-chat-prompt. For a conversation, the entire prompt must be kept as a variable, because the llm-chat-prompt-interactions slot will be getting changed by the chat functions to store the conversation. For some providers, this will store the history directly in llm-chat-prompt-interactions, but other LLMs have an opaque conversation history. For that reason, the correct way to handle a conversation is to repeatedly call llm-chat or variants with the same prompt structure, kept in a variable, and after each time, add the new user text with llm-chat-prompt-append-response. The following is an example:
#+begin_src emacs-lisp
(defvar-local llm-chat-streaming-prompt nil)
(defun start-or-continue-conversation (text)
"Called when the user has input TEXT as the next input."
(if llm-chat-streaming-prompt
(llm-chat-prompt-append-response llm-chat-streaming-prompt text)
(setq llm-chat-streaming-prompt (llm-make-chat-prompt text))
(llm-chat-streaming-to-point provider llm-chat-streaming-prompt (current-buffer) (point-max) (lambda ()))))
#+end_src
** Caution about llm-chat-prompt-interactions
The interactions in a prompt may be modified by conversation or by the conversion of the context and examples to what the LLM understands. Different providers require different things from the interactions. Some can handle system prompts, some cannot. Some require alternating user and assistant chat interactions, others can handle anything. It's important that clients keep to behaviors that work on all providers. Do not attempt to read or manipulate llm-chat-prompt-interactions after initially setting it up for the first time, because you are likely to make changes that only work for some providers. Similarly, don't directly create a prompt with make-llm-chat-prompt, because it is easy to create something that wouldn't work for all providers.
** Tool use
Note: tool use is currently beta quality. If you want to use tool use, please watch the =llm= [[https://github.com/ahyatt/llm/discussions][discussions]] for any announcements about changes.
Tool use is a way to give the LLM a list of functions it can call, and have it call the functions for you. The standard interaction has the following steps:
- The client sends the LLM a prompt with tools it can use.
- The LLM may return which tools to use, and with what arguments, or text as normal.
- If the LLM has decided to use one or more tools, those tool's functions should be called, and their results sent back to the LLM. This could be the final step depending on if any follow-on is needed.
- The LLM will return with a text response based on the initial prompt and the results of the tool use.
- The client can now can continue the conversation.
This basic structure is useful because it can guarantee a well-structured output (if the LLM does decide to use the tool). Not every LLM can handle tool use, and those that do not will ignore the tools entirely. The function =llm-capabilities= will return a list with =tool-use= in it if the LLM supports tool use. Because not all providers support tool use when streaming, =streaming-tool-use= indicates the ability to use tool uses in llm-chat-streaming. Right now only Gemini, Vertex, Claude, and Open AI support tool use. However, even for LLMs that handle tool use, there is sometimes a difference in the capabilities. Right now, it is possible to write tools that succeed in Open AI but cause errors in Gemini, because Gemini does not appear to handle tools that have types that contain other types. So client programs are advised for right now to keep function to simple types.
The way to call functions is to attach a list of functions to the =tools= slot in the prompt. This is a list of =llm-tool= structs, which is a tool that is an elisp function, with a name, a description, and a list of arguments. The docstrings give an explanation of the format. An example is:
#+begin_src emacs-lisp (llm-chat-async my-llm-provider (llm-make-chat-prompt "What is the capital of France?" :tools (list (llm-make-tool :function (lambda (callback result) ;; In this example function the assumption is that the ;; callback will be called after processing the result is ;; complete. (notify-user-of-capital result callback)) :name "capital_of_country" :description "Get the capital of a country." :args '((:name "country" :description "The country whose capital to look up." :type string)) :async t))) #'identity ;; No need to process the result in this example. (lambda (_ err) (error "Error on getting capital: %s" err))) #+end_src
Note that tools have the same arguments and structure as the tool definitions in [[https://github.com/karthink/gptel][GTPel]].
The various chat APIs will execute the functions defined in =tools= slot with the arguments supplied by the LLM. The chat functions will, Instead of returning (or passing to a callback) a string, instead a list will be returned of tool names and return values. This is not technically an alist because the same tool might be used several times, so the =car= can be equivalent.
After the tool is called, the client could use the result, but if you want to proceed with the conversation, or get a textual response that accompany the function you should just send the prompt back with no modifications. This is because the LLM gives the tool use to perform, and then expects to get back the results of that tool use. The results were already executed at the end of the call which returned the tools used, which also stores the result of that execution in the prompt. This is why it should be sent back without further modifications.
Tools will be called with vectors for array results, =nil= for false boolean results, and plists for objects.
Be aware that there is no gaurantee that the tool will be called correctly. While the LLMs mostly get this right, they are trained on Javascript functions, so imitating Javascript names is recommended. So, "write_email" is a better name for a function than "write-email".
Examples can be found in =llm-tester=. There is also a function call to generate function calls from existing elisp functions in =utilities/elisp-to-tool.el=. ** Media input Note: media input functionality is currently alpha quality. If you want to use it, please watch the =llm= [[https://github.com/ahyatt/llm/discussions][discussions]] for any announcements about changes.
Media can be used in =llm-chat= and related functions. To use media, you can use =llm-multipart= in =llm-make-chat-prompt=, and pass it an Emacs image or an =llm-media= object for other kinds of media. Besides images, some models support video and audio. Not all providers or models support these, with images being the most frequently supported media type, and video and audio more rare. ** Advanced prompt creation The =llm-prompt= module provides helper functions to create prompts that can incorporate data from your application. In particular, this should be very useful for application that need a lot of context.
A prompt defined with =llm-prompt= is a template, with placeholders that the module will fill in. Here's an example of a prompt definition, from the [[https://github.com/ahyatt/ekg][ekg]] package:
#+begin_src emacs-lisp (llm-defprompt ekg-llm-fill-prompt "The user has written a note, and would like you to append to it, to make it more useful. This is important: only output your additions, and do not repeat anything in the user's note. Write as a third party adding information to a note, so do not use the first person.
First, I'll give you information about the note, then similar other notes that user has written, in JSON. Finally, I'll give you instructions. The user's note will be your input, all the rest, including this, is just context for it. The notes given are to be used as background material, which can be referenced in your answer.
The user's note uses tags: {{tags}}. The notes with the same tags, listed here in reverse date order: {{tag-notes:10}}
These are similar notes in general, which may have duplicates from the ones above: {{similar-notes:1}}
This ends the section on useful notes as a background for the note in question.
Your instructions on what content to add to the note:
{{instructions}} ") #+end_src
When this is filled, it is done in the context of a provider, which has a known
context size (via llm-chat-token-limit). Care is taken to not overfill the
context, which is checked as it is filled via llm-count-tokens. We usually want
to not fill the whole context, but instead leave room for the chat and
subsequent terms. The variable llm-prompt-default-max-pct controls how much of
the context window we want to fill. The way we estimate the number of tokens
used is quick but inaccurate, so limiting to less than the maximum context size
is useful for guarding against a miscount leading to an error calling the LLM
due to too many tokens. If you want to have a hard limit as well that doesn't
depend on the context window size, you can use llm-prompt-default-max-tokens.
We will use the minimum of either value.
Variables are enclosed in double curly braces, like this: ={{instructions}}=. They can just be the variable, or they can also denote a number of tickets, like so: ={{tag-notes:10}}=. Tickets should be thought of like lottery tickets, where the prize is a single round of context filling for the variable. So the variable =tag-notes= gets 10 tickets for a drawing. Anything else where tickets are unspecified (unless it is just a single variable, which will be explained below) will get a number of tickets equal to the total number of specified tickets. So if you have two variables, one with 1 ticket, one with 10 tickets, one will be filled 10 times more than the other. If you have two variables, one with 1 ticket, one unspecified, the unspecified one will get 1 ticket, so each will have an even change to get filled. If no variable has tickets specified, each will get an equal chance. If you have one variable, it could have any number of tickets, but the result would be the same, since it would win every round. This algorithm is the contribution of David Petrou.
The above is true of variables that are to be filled with a sequence of possible values. A lot of LLM context filling is like this. In the above example, ={{similar-notes}}= is a retrieval based on a similarity score. It will continue to fill items from most similar to least similar, which is going to return almost everything the ekg app stores. We want to retrieve only as needed. Because of this, the =llm-prompt= module takes in /generators/ to supply each variable. However, a plain list is also acceptable, as is a single value. Any single value will not enter into the ticket system, but rather be prefilled before any tickets are used.
Values supplied in either the list or generators can be the values themselves, or conses. If a cons, the variable to fill is the =car= of the cons, and the =cdr= is the place to fill the new value, =front= or =back=. The =front= is the default: new values will be appended to the end. =back= will add new values to the start of the filled text for the variable instead.
So, to illustrate with this example, here's how the prompt will be filled:
- First, the ={{tags}}= and ={{instructions}}= will be filled first. This will happen regardless before we check the context size, so the module assumes that these will be small and not blow up the context.
- Check the context size we want to use (
llm-prompt-default-max-pctmultiplied byllm-chat-token-limit) and exit if exceeded. - Run a lottery with all tickets and choose one of the remaining variables to fill.
- If the variable won't make the text too large, fill the variable with one entry retrieved from a supplied generator, otherwise ignore. These are values are not conses, so values will be appended to the end of the generated text for each variable (so a new variable generated for tags will append after other generated tags but before the subsequent "and" in the text.
- Goto 2
The prompt can be filled two ways, one using predefined prompt template
(llm-defprompt and llm-prompt-fill), the other using a prompt template that is
passed in (llm-prompt-fill-text).
#+begin_src emacs-lisp (llm-defprompt my-prompt "My name is {{name}} and I'm here's to say {{messages}}")
(llm-prompt-fill 'my-prompt my-llm-provider :name "Pat" :messages #'my-message-retriever)
(iter-defun my-message-retriever () "Return the messages I like to say." (my-message-reset-messages) (while (my-has-next-message) (iter-yield (my-get-next-message)))) #+end_src
Alternatively, you can just fill it directly: #+begin_src emacs-lisp (llm-prompt-fill-text "Hi, I'm {{name}} and I'm here to say {{messages}}" :name "John" :messages #'my-message-retriever) #+end_src
As you can see in the examples, the variable values are passed in with matching keys.
- Contributions If you are interested in creating a provider, please send a pull request, or open a bug. This library is part of GNU ELPA, so any major provider that we include in this module needs to be written by someone with FSF papers. However, you can always write a module and put it on a different package archive, such as MELPA.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm
Similar Open Source Tools
llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.
odoo-llm
This repository provides a comprehensive framework for integrating Large Language Models (LLMs) into Odoo. It enables seamless interaction with AI providers like OpenAI, Anthropic, Ollama, and Replicate for chat completions, text embeddings, and more within the Odoo environment. The architecture includes external AI clients connecting via `llm_mcp_server` and Odoo AI Chat with built-in chat interface. The core module `llm` offers provider abstraction, model management, and security, along with tools for CRUD operations and domain-specific tool packs. Various AI providers, infrastructure components, and domain-specific tools are available for different tasks such as content generation, knowledge base management, and AI assistants creation.

BentoVLLM
BentoVLLM is an example project demonstrating how to serve and deploy open-source Large Language Models using vLLM, a high-throughput and memory-efficient inference engine. It provides a basis for advanced code customization, such as custom models, inference logic, or vLLM options. The project allows for simple LLM hosting with OpenAI compatible endpoints without the need to write any code. Users can interact with the server using Swagger UI or other methods, and the service can be deployed to BentoCloud for better management and scalability. Additionally, the repository includes integration examples for different LLM models and tools.
baibot
Baibot is a versatile chatbot framework designed to simplify the process of creating and deploying chatbots. It provides a user-friendly interface for building custom chatbots with various functionalities such as natural language processing, conversation flow management, and integration with external APIs. Baibot is highly customizable and can be easily extended to suit different use cases and industries. With Baibot, developers can quickly create intelligent chatbots that can interact with users in a seamless and engaging manner, enhancing user experience and automating customer support processes.
MaiBot
MaiBot is an intelligent QQ group chat bot based on a large language model. It is developed using the nonebot2 framework, with LLM providing conversation abilities, MongoDB for data persistence support, and NapCat as the QQ protocol endpoint support. The project is in active development stage, with features like chat functionality, emoji functionality, schedule management, memory function, knowledge base function, and relationship function planned for future updates. The project aims to create a 'life form' active in QQ group chats, focusing on companionship and creating a more human-like presence rather than a perfect assistant. The application generates content from AI models, so users are advised to discern carefully and not use it for illegal purposes.
nekro-agent
Nekro Agent is an AI chat plugin and proxy execution bot that is highly scalable, offers high freedom, and has minimal deployment requirements. It features context-aware chat for group/private chats, custom character settings, sandboxed execution environment, interactive image resource handling, customizable extension development interface, easy deployment with docker-compose, integration with Stable Diffusion for AI drawing capabilities, support for various file types interaction, hot configuration updates and command control, native multimodal understanding, visual application management control panel, CoT (Chain of Thought) support, self-triggered timers and holiday greetings, event notification understanding, and more. It allows for third-party extensions and AI-generated extensions, and includes features like automatic context trigger based on LLM, and a variety of basic commands for bot administrators.

cellm
Cellm is an Excel extension that allows users to leverage Large Language Models (LLMs) like ChatGPT within cell formulas. It enables users to extract AI responses to text ranges, making it useful for automating repetitive tasks that involve data processing and analysis. Cellm supports various models from Anthropic, Mistral, OpenAI, and Google, as well as locally hosted models via Llamafiles, Ollama, or vLLM. The tool is designed to simplify the integration of AI capabilities into Excel for tasks such as text classification, data cleaning, content summarization, entity extraction, and more.
llama.ui
llama.ui is an open-source desktop application that provides a beautiful, user-friendly interface for interacting with large language models powered by llama.cpp. It is designed for simplicity and privacy, allowing users to chat with powerful quantized models on their local machine without the need for cloud services. The project offers multi-provider support, conversation management with indexedDB storage, rich UI components including markdown rendering and file attachments, advanced features like PWA support and customizable generation parameters, and is privacy-focused with all data stored locally in the browser.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.

py-gpt
Py-GPT is a Python library that provides an easy-to-use interface for OpenAI's GPT-3 API. It allows users to interact with the powerful GPT-3 model for various natural language processing tasks. With Py-GPT, developers can quickly integrate GPT-3 capabilities into their applications, enabling them to generate text, answer questions, and more with just a few lines of code.
llms
llms.py is a lightweight CLI, API, and ChatGPT-like alternative to Open WebUI for accessing multiple LLMs. It operates entirely offline, ensuring all data is kept private in browser storage. The tool provides a convenient way to interact with various LLM models without the need for an internet connection, prioritizing user privacy and data security.
ultracontext
UltraContext is a context API for AI agents that simplifies controlling what agents see by allowing users to replace messages, compact or offload context, replay decisions, and roll back mistakes with a single API call. It provides versioned context out of the box with full history and zero complexity. The tool aims to address the issue of context rot in large language models by providing a simple API with automatic versioning, time-travel capabilities, schema-free data storage, framework-agnostic compatibility, and fast performance. UltraContext is designed to streamline the process of managing context for AI agents, enabling users to focus on solving interesting problems rather than spending time gluing context together.

llm-on-openshift
This repository provides resources, demos, and recipes for working with Large Language Models (LLMs) on OpenShift using OpenShift AI or Open Data Hub. It includes instructions for deploying inference servers for LLMs, such as vLLM, Hugging Face TGI, Caikit-TGIS-Serving, and Ollama. Additionally, it offers guidance on deploying serving runtimes, such as vLLM Serving Runtime and Hugging Face Text Generation Inference, in the Single-Model Serving stack of Open Data Hub or OpenShift AI. The repository also covers vector databases that can be used as a Vector Store for Retrieval Augmented Generation (RAG) applications, including Milvus, PostgreSQL+pgvector, and Redis. Furthermore, it provides examples of inference and application usage, such as Caikit, Langchain, Langflow, and UI examples.
For similar tasks
llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
tokencost
Tokencost is a clientside tool for calculating the USD cost of using major Large Language Model (LLMs) APIs by estimating the cost of prompts and completions. It helps track the latest price changes of major LLM providers, accurately count prompt tokens before sending OpenAI requests, and easily integrate to get the cost of a prompt or completion with a single function. Users can calculate prompt and completion costs using OpenAI requests, count tokens in prompts formatted as message lists or string prompts, and refer to a cost table with updated prices for various LLM models. The tool also supports callback handlers for LLM wrapper/framework libraries like LlamaIndex and Langchain.
gigachat
GigaChat is a Python library that allows GigaChain to interact with GigaChat, a neural network model capable of engaging in dialogue, writing code, creating texts, and images on demand. Data exchange with the service is facilitated through the GigaChat API. The library supports processing token streaming, as well as working in synchronous or asynchronous mode. It enables precise token counting in text using the GigaChat API.
client
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.
gemini-cli
gemini-cli is a versatile command-line interface for Google's Gemini LLMs, written in Go. It includes tools for chatting with models, generating/comparing embeddings, and storing data in SQLite for analysis. Users can interact with Gemini models through various subcommands like prompt, chat, counttok, embed content, embed db, and embed similar.
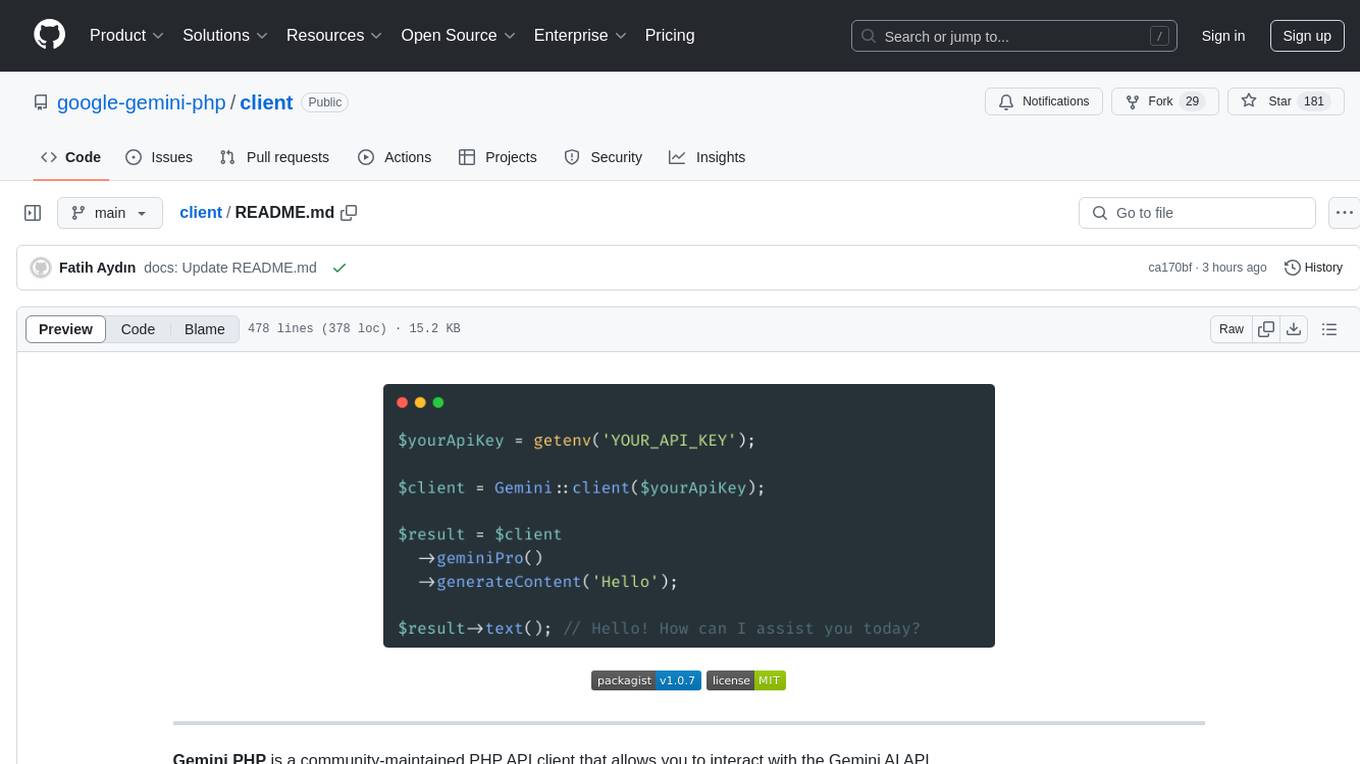
client
Gemini PHP is a PHP API client for interacting with the Gemini AI API. It allows users to generate content, chat, count tokens, configure models, embed resources, list models, get model information, troubleshoot timeouts, and test API responses. The client supports various features such as text-only input, text-and-image input, multi-turn conversations, streaming content generation, token counting, model configuration, and embedding techniques. Users can interact with Gemini's API to perform tasks related to natural language generation and text analysis.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.