
LocalLLMClient
Swift local LLM client for iOS, macOS, Linux
Stars: 82

LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
README:
![]()


A Swift package to interact with local Large Language Models (LLMs) on Apple platforms.
Demo / Multimodal
| MobileVLM-3B (llama.cpp) | Qwen2.5 VL 3B (MLX) |
|---|---|
iPhone 16 Pro
[!IMPORTANT] This project is still experimental. The API is subject to change.
[!TIP] To run larger models more reliably, consider adding
com.apple.developer.kernel.increased-memory-limitentitlement to your app.
- Support for GGUF / MLX models / FoundationModels framework
- Support for iOS, macOS and Linux
- Streaming API
- Multimodal (experimental)
- Tool calling (experimental)
Add the following dependency to your Package.swift file:
dependencies: [
.package(url: "https://github.com/tattn/LocalLLMClient.git", branch: "main")
]The API documentation is available here.
import LocalLLMClient
import LocalLLMClientLlama
let session = LLMSession(model: .llama(
id: "lmstudio-community/gemma-3-4B-it-qat-GGUF",
model: "gemma-3-4B-it-QAT-Q4_0.gguf"
))
print(try await session.respond(to: "Tell me a joke."))
for try await text in session.streamResponse(to: "Write a story about cats.") {
print(text, terminator: "")
}Using llama.cpp
import LocalLLMClient
import LocalLLMClientLlama
// Create a model
let model = LLMSession.DownloadModel.llama(
id: "lmstudio-community/gemma-3-4B-it-qat-GGUF",
model: "gemma-3-4B-it-QAT-Q4_0.gguf",
parameter: .init(
temperature: 0.7, // Randomness (0.0〜1.0)
topK: 40, // Top-K sampling
topP: 0.9, // Top-P (nucleus) sampling
options: .init(responseFormat: .json) // Response format
)
)
// You can track download progress
try await model.downloadModel { progress in
print("Download progress: \(progress)")
}
// Create a session with the downloaded model
let session = LLMSession(model: model)
// Generate a response with a specific prompt
let response = try await session.respond(to: """
Create the beginning of a synopsis for an epic story with a cat as the main character.
Format it in JSON, as shown below.
{
"title": "<title>",
"content": "<content>",
}
""")
print(response)
// You can also add system messages before asking questions
session.messages = [.system("You are a helpful assistant.")]Using Apple MLX
import LocalLLMClient
import LocalLLMClientMLX
// Create a model
let model = LLMSession.DownloadModel.mlx(
id: "mlx-community/Qwen3-1.7B-4bit",
parameter: .init(
temperature: 0.7, // Randomness (0.0 to 1.0)
topP: 0.9 // Top-P (nucleus) sampling
)
)
// You can track download progress
try await model.downloadModel { progress in
print("Download progress: \(progress)")
}
// Create a session with the downloaded model
let session = LLMSession(model: model)
// Generate text with system and user messages
session.messages = [.system("You are a helpful assistant.")]
let response = try await session.respond(to: "Tell me a story about a cat.")
print(response)Using Apple FoundationModels
import LocalLLMClient
import LocalLLMClientFoundationModels
// Available on iOS 26.0+ / macOS 26.0+ and requires Apple Intelligence
let session = LLMSession(model: .foundationModels(
// Use system's default model
model: .default,
// Configure generation options
parameter: .init(
temperature: 0.7,
)
))
// Generate a response with a specific prompt
let response = try await session.respond(to: "Tell me a short story about a clever fox.")
print(response)LocalLLMClient supports tool calling for integrations with external systems.
[!IMPORTANT] Tool calling is only available with models that support this feature. Each backend has different model compatibility.
Make sure your chosen model explicitly supports tool calling before using this feature.
Using tool calling
import LocalLLMClient
import LocalLLMClientLlama
@Tool("get_weather")
struct GetWeatherTool {
let description = "Get the current weather in a given location"
@ToolArguments
struct Arguments {
@ToolArgument("The city and state, e.g. San Francisco, CA")
var location: String
@ToolArgument("Temperature unit")
var unit: Unit?
@ToolArgumentEnum
enum Unit: String {
case celsius
case fahrenheit
}
}
func call(arguments: Arguments) async throws -> ToolOutput {
// In a real implementation, this would call a weather API
let temp = arguments.unit == .celsius ? "22°C" : "72°F"
return ToolOutput([
"location": arguments.location,
"temperature": temp,
"condition": "sunny"
])
}
}
// Create the tool
let weatherTool = GetWeatherTool()
// Create a session with a model that supports tool calling and register tools
let session = LLMSession(
model: .llama(
id: "Qwen/Qwen2.5-1.5B-Instruct-GGUF",
model: "qwen2.5-1.5b-instruct-q4_k_m.gguf"
),
tools: [weatherTool]
)
// Ask a question that requires tool use
let response = try await session.respond(to: "What's the weather like in Tokyo?")
print(response)
// The model will automatically call the weather tool and include the result in its responseLocalLLMClient also supports multimodal models for processing images.
Using with llama.cpp
import LocalLLMClient
import LocalLLMClientLlama
// Create a session with a multimodal model
let session = LLMSession(model: .llama(
id: "ggml-org/gemma-3-4b-it-GGUF",
model: "gemma-3-4b-it-Q8_0.gguf",
mmproj: "mmproj-model-f16.gguf"
))
// Ask a question about an image
let response = try await session.respond(
to: "What's in this image?",
attachments: [.image(.init(resource: .yourImage))]
)
print(response)
// You can also stream the response
for try await text in session.streamResponse(
to: "Describe this image in detail",
attachments: [.image(.init(resource: .yourImage))]
) {
print(text, terminator: "")
}Using with Apple MLX
import LocalLLMClient
import LocalLLMClientMLX
// Create a session with a multimodal model
let session = LLMSession(model: .mlx(
id: "mlx-community/Qwen2.5-VL-3B-Instruct-abliterated-4bit"
))
// Ask a question about an image
let response = try await session.respond(
to: "What's in this image?",
attachments: [.image(.init(resource: .yourImage))]
)
print(response)For more advanced control over model loading and inference, you can use the LocalLLMClient APIs directly.
Using with llama.cpp
import LocalLLMClient
import LocalLLMClientLlama
import LocalLLMClientUtility
// Download model from Hugging Face (Gemma 3)
let ggufName = "gemma-3-4B-it-QAT-Q4_0.gguf"
let downloader = FileDownloader(source: .huggingFace(
id: "lmstudio-community/gemma-3-4B-it-qat-GGUF",
globs: [ggufName]
))
try await downloader.download { print("Progress: \($0)") }
// Initialize a client with the downloaded model
let modelURL = downloader.destination.appending(component: ggufName)
let client = try await LocalLLMClient.llama(url: modelURL, parameter: .init(
context: 4096, // Context size
temperature: 0.7, // Randomness (0.0〜1.0)
topK: 40, // Top-K sampling
topP: 0.9, // Top-P (nucleus) sampling
options: .init(responseFormat: .json) // Response format
))
let prompt = """
Create the beginning of a synopsis for an epic story with a cat as the main character.
Format it in JSON, as shown below.
{
"title": "<title>",
"content": "<content>",
}
"""
// Generate text
let input = LLMInput.chat([
.system("You are a helpful assistant."),
.user(prompt)
])
for try await text in try await client.textStream(from: input) {
print(text, terminator: "")
}Using with Apple MLX
import LocalLLMClient
import LocalLLMClientMLX
import LocalLLMClientUtility
// Download model from Hugging Face
let downloader = FileDownloader(
source: .huggingFace(id: "mlx-community/Qwen3-1.7B-4bit", globs: .mlx)
)
try await downloader.download { print("Progress: \($0)") }
// Initialize a client with the downloaded model
let client = try await LocalLLMClient.mlx(url: downloader.destination, parameter: .init(
temperature: 0.7, // Randomness (0.0 to 1.0)
topP: 0.9 // Top-P (nucleus) sampling
))
// Generate text
let input = LLMInput.chat([
.system("You are a helpful assistant."),
.user("Tell me a story about a cat.")
])
for try await text in try await client.textStream(from: input) {
print(text, terminator: "")
}Using with Apple FoundationModels
import LocalLLMClient
import LocalLLMClientFoundationModels
// Available on iOS 26.0+ / macOS 26.0+ and requires Apple Intelligence
let client = try await LocalLLMClient.foundationModels(
// Use system's default model
model: .default,
// Configure generation options
parameter: .init(
temperature: 0.7,
)
)
// Generate text
let input = LLMInput.chat([
.system("You are a helpful assistant."),
.user("Tell me a short story about a clever fox.")
])
for try await text in try await client.textStream(from: input) {
print(text, terminator: "")
}Advanced Multimodal with llama.cpp
import LocalLLMClient
import LocalLLMClientLlama
import LocalLLMClientUtility
// Download model from Hugging Face (Gemma 3)
let model = "gemma-3-4b-it-Q8_0.gguf"
let mmproj = "mmproj-model-f16.gguf"
let downloader = FileDownloader(
source: .huggingFace(id: "ggml-org/gemma-3-4b-it-GGUF", globs: [model, mmproj]),
)
try await downloader.download { print("Download: \($0)") }
// Initialize a client with the downloaded model
let client = try await LocalLLMClient.llama(
url: downloader.destination.appending(component: model),
mmprojURL: downloader.destination.appending(component: mmproj)
)
let input = LLMInput.chat([
.user("What's in this image?", attachments: [.image(.init(resource: .yourImage))]),
])
// Generate text without streaming
print(try await client.generateText(from: input))Advanced Multimodal with Apple MLX
import LocalLLMClient
import LocalLLMClientMLX
import LocalLLMClientUtility
// Download model from Hugging Face (Qwen2.5 VL)
let downloader = FileDownloader(source: .huggingFace(
id: "mlx-community/Qwen2.5-VL-3B-Instruct-abliterated-4bit",
globs: .mlx
))
try await downloader.download { print("Progress: \($0)") }
let client = try await LocalLLMClient.mlx(url: downloader.destination)
let input = LLMInput.chat([
.user("What's in this image?", attachments: [.image(.init(resource: .yourImage))]),
])
// Generate text without streaming
print(try await client.generateText(from: input))You can use LocalLLMClient directly from the terminal using the command line tool:
# Run using llama.cpp
swift run LocalLLMCLI --model /path/to/your/model.gguf "Your prompt here"
# Run using MLX
./scripts/run_mlx.sh --model https://huggingface.co/mlx-community/Qwen3-1.7B-4bit "Your prompt here"- LLaMA 3
- Gemma 3 / 2
- Qwen 3 / 2
- Phi 4
Models compatible with llama.cpp backend
Models compatible with MLX backend
If you have a model that works, please open an issue or PR to add it to the list.
- iOS 16.0+ / macOS 14.0+
- Xcode 16.0+
This package uses llama.cpp, Apple's MLX and Foundation Models framework for model inference.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LocalLLMClient
Similar Open Source Tools
LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.
koog
Koog is a Kotlin-based framework for building and running AI agents entirely in idiomatic Kotlin. It allows users to create agents that interact with tools, handle complex workflows, and communicate with users. Key features include pure Kotlin implementation, MCP integration, embedding capabilities, custom tool creation, ready-to-use components, intelligent history compression, powerful streaming API, persistent agent memory, comprehensive tracing, flexible graph workflows, modular feature system, scalable architecture, and multiplatform support.
llama.ui
llama.ui is an open-source desktop application that provides a beautiful, user-friendly interface for interacting with large language models powered by llama.cpp. It is designed for simplicity and privacy, allowing users to chat with powerful quantized models on their local machine without the need for cloud services. The project offers multi-provider support, conversation management with indexedDB storage, rich UI components including markdown rendering and file attachments, advanced features like PWA support and customizable generation parameters, and is privacy-focused with all data stored locally in the browser.
ai-inference
AI Inference is a Python library that provides tools for deploying and running machine learning models in production environments. It simplifies the process of integrating AI models into applications by offering a high-level API for inference tasks. With AI Inference, developers can easily load pre-trained models, perform inference on new data, and deploy models as RESTful APIs. The library supports various deep learning frameworks such as TensorFlow and PyTorch, making it versatile for a wide range of AI applications.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
arcade-ai
Arcade AI is a developer-focused tooling and API platform designed to enhance the capabilities of LLM applications and agents. It simplifies the process of connecting agentic applications with user data and services, allowing developers to concentrate on building their applications. The platform offers prebuilt toolkits for interacting with various services, supports multiple authentication providers, and provides access to different language models. Users can also create custom toolkits and evaluate their tools using Arcade AI. Contributions are welcome, and self-hosting is possible with the provided documentation.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.

DB-GPT
DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents. It aims to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.

bisheng
Bisheng is a leading open-source **large model application development platform** that empowers and accelerates the development and deployment of large model applications, helping users enter the next generation of application development with the best possible experience.
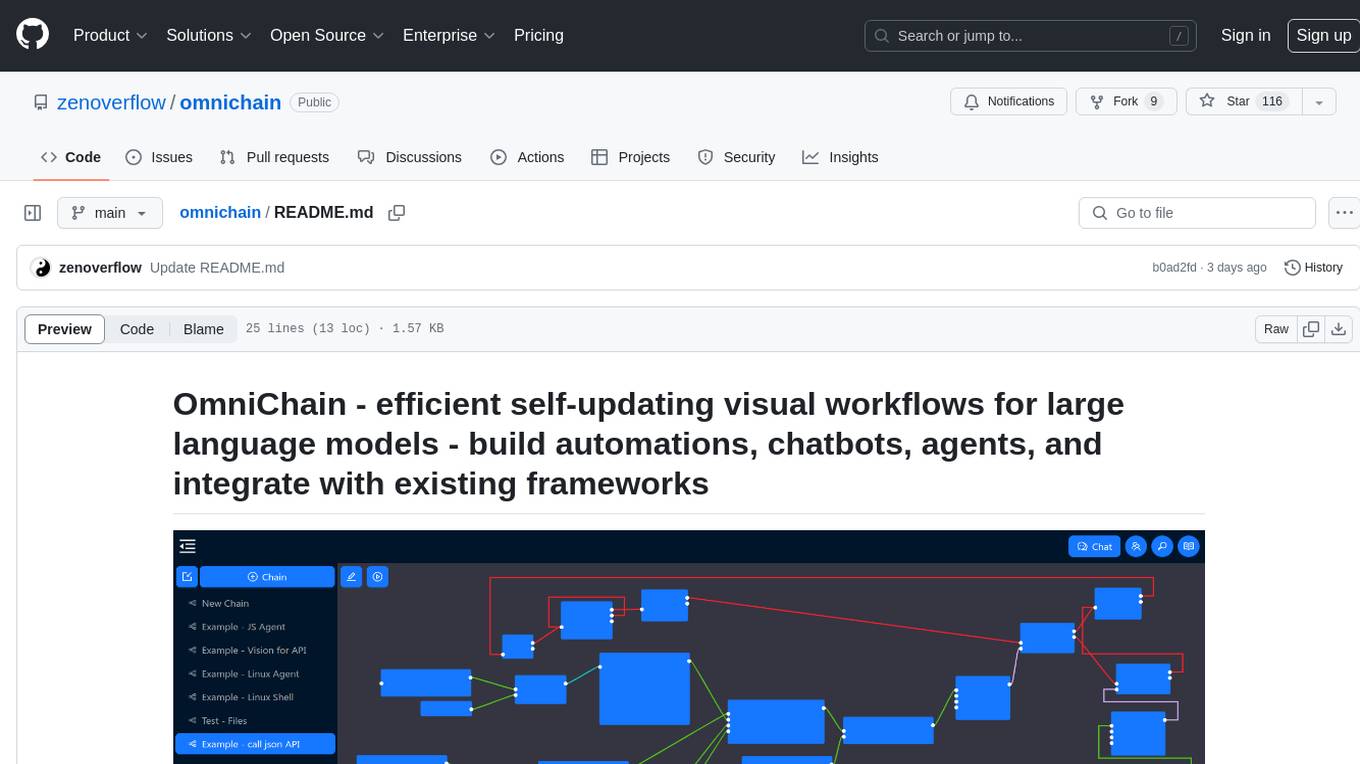
omnichain
OmniChain is a tool for building efficient self-updating visual workflows using AI language models, enabling users to automate tasks, create chatbots, agents, and integrate with existing frameworks. It allows users to create custom workflows guided by logic processes, store and recall information, and make decisions based on that information. The tool enables users to create tireless robot employees that operate 24/7, access the underlying operating system, generate and run NodeJS code snippets, and create custom agents and logic chains. OmniChain is self-hosted, open-source, and available for commercial use under the MIT license, with no coding skills required.
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
For similar tasks

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
tool-ahead-of-time
Tool-Ahead-of-Time (TAoT) is a Python package that enables tool calling for any model available through Langchain's ChatOpenAI library, even before official support is provided. It reformats model output into a JSON parser for tool calling. The package supports OpenAI and non-OpenAI models, following LangChain's syntax for tool calling. Users can start using the tool without waiting for official support, providing a more robust solution for tool calling.
mcphub.nvim
MCPHub.nvim is a powerful Neovim plugin that integrates MCP (Model Context Protocol) servers into your workflow. It offers a centralized config file for managing servers and tools, with an intuitive UI for testing resources. Ideal for LLM integration, it provides programmatic API access and interactive testing through the `:MCPHub` command.
go-utcp
The Universal Tool Calling Protocol (UTCP) is a modern, flexible, and scalable standard for defining and interacting with tools across various communication protocols. It emphasizes scalability, interoperability, and ease of use. It provides built-in transports for HTTP, CLI, Server-Sent Events, streaming HTTP, GraphQL, MCP, and UDP. Users can use the library to construct a client and call tools using the available transports. The library also includes utilities for variable substitution, in-memory repository for storing providers and tools, and OpenAPI conversion to UTCP manuals.
utcp-specification
The Universal Tool Calling Protocol (UTCP) Specification repository contains the official documentation for a modern and scalable standard that enables AI systems and clients to discover and interact with tools across different communication protocols. It defines tool discovery mechanisms, call formats, provider configuration, authentication methods, and response handling.
ailoy
Ailoy is a lightweight library for building AI applications such as agent systems or RAG pipelines with ease. It enables AI features effortlessly, supporting AI models locally or via cloud APIs, multi-turn conversation, system message customization, reasoning-based workflows, tool calling capabilities, and built-in vector store support. It also supports running native-equivalent functionality in web browsers using WASM. The library is in early development stages and provides examples in the `examples` directory for inspiration on building applications with Agents.
LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
ai-sdk-cpp
The AI SDK CPP is a modern C++ toolkit that provides a unified, easy-to-use API for building AI-powered applications with popular model providers like OpenAI and Anthropic. It bridges the gap for C++ developers by offering a clean, expressive codebase with minimal dependencies. The toolkit supports text generation, streaming content, multi-turn conversations, error handling, tool calling, async tool execution, and configurable retries. Future updates will include additional providers, text embeddings, and image generation models. The project also includes a patched version of nlohmann/json for improved thread safety and consistent behavior in multi-threaded environments.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.