
OllamaSharp
The easiest way to use Ollama in .NET
Stars: 1130
OllamaSharp is a .NET binding for the Ollama API, providing an intuitive API client to interact with Ollama. It offers support for all Ollama API endpoints, real-time streaming, progress reporting, and an API console for remote management. Users can easily set up the client, list models, pull models with progress feedback, stream completions, and build interactive chats. The project includes a demo console for exploring and managing the Ollama host.
README:


OllamaSharp provides .NET bindings for the Ollama API, simplifying interactions with Ollama both locally and remotely.
- Ease of use: Interact with Ollama in just a few lines of code.
- Reliability: Powering Microsoft Semantic Kernel, .NET Aspire and Microsoft.Extensions.AI
- API coverage: Covers every single Ollama API endpoint, including chats, embeddings, listing models, pulling and creating new models, and more.
- Real-time streaming: Stream responses directly to your application.
- Progress reporting: Real-time progress feedback on tasks like model pulling.
- Tools engine: Sophisticated tool support with source generators.
- Multi modality: Support for vision models.
- Native AOT support: Opt-in support for Native AOT for improved performance.
OllamaSharp wraps each Ollama API endpoint in awaitable methods that fully support response streaming.
The following list shows a few simple code examples.
ℹ Try our full featured demo application that's included in this repository
// set up the client
var uri = new Uri("http://localhost:11434");
var ollama = new OllamaApiClient(uri);
// select a model which should be used for further operations
ollama.SelectedModel = "llama3.1:8b";For .NET Native AOT scenarios, create a custom JsonSerializerContext with your types and pass it into the constructor.
[JsonSerializable(typeof(MyCustomType))]
public partial class MyJsonContext : JsonSerializerContext { }
// Use the static factory method for NativeAOT
var ollama = new OllamaApiClient(uri, "llama3.1:8b", MyJsonContext.Default);See the Native AOT documentation for detailed guidance.
var models = await ollama.ListLocalModelsAsync();await foreach (var status in ollama.PullModelAsync("llama3.1:405b"))
Console.WriteLine($"{status.Percent}% {status.Status}");await foreach (var stream in ollama.GenerateAsync("How are you today?"))
Console.Write(stream.Response);// messages including their roles and tool calls will automatically be tracked within the chat object
// and are accessible via the Messages property
var chat = new Chat(ollama);
while (true)
{
var message = Console.ReadLine();
await foreach (var answerToken in chat.SendAsync(message))
Console.Write(answerToken);
}Microsoft built an abstraction library to streamline the usage of different AI providers. This is a really interesting concept if you plan to build apps that might use different providers, like ChatGPT, Claude and local models with Ollama.
I encourage you to read their accouncement Introducing Microsoft.Extensions.AI Preview – Unified AI Building Blocks for .NET.
OllamaSharp is the first full implementation of their IChatClient and IEmbeddingGenerator that makes it possible to use Ollama just like every other chat provider.
To do this, simply use the OllamaApiClient as IChatClient instead of IOllamaApiClient.
// install package Microsoft.Extensions.AI.Abstractions
private static IChatClient CreateChatClient(Arguments arguments)
{
if (arguments.Provider.Equals("ollama", StringComparison.OrdinalIgnoreCase))
return new OllamaApiClient(arguments.Uri, arguments.Model);
else
return new OpenAIChatClient(new OpenAI.OpenAIClient(arguments.ApiKey), arguments.Model); // ChatGPT or compatible
}The OllamaApiClient implements both interfaces from Microsoft.Extensions.AI, you just need to cast it accordingly:
-
IChatClientfor model inference -
IEmbeddingGenerator<string, Embedding<float>>for embedding generation
I would like to thank all the contributors who take the time to improve OllamaSharp. First and foremost mili-tan, who always keeps OllamaSharp in sync with the Ollama API.
The icon and name were reused from the amazing Ollama project.
Special thanks to JetBrains for supporting this project.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for OllamaSharp
Similar Open Source Tools
OllamaSharp
OllamaSharp is a .NET binding for the Ollama API, providing an intuitive API client to interact with Ollama. It offers support for all Ollama API endpoints, real-time streaming, progress reporting, and an API console for remote management. Users can easily set up the client, list models, pull models with progress feedback, stream completions, and build interactive chats. The project includes a demo console for exploring and managing the Ollama host.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.
llama.ui
llama.ui is an open-source desktop application that provides a beautiful, user-friendly interface for interacting with large language models powered by llama.cpp. It is designed for simplicity and privacy, allowing users to chat with powerful quantized models on their local machine without the need for cloud services. The project offers multi-provider support, conversation management with indexedDB storage, rich UI components including markdown rendering and file attachments, advanced features like PWA support and customizable generation parameters, and is privacy-focused with all data stored locally in the browser.
free-chat
Free Chat is a forked project from chatgpt-demo that allows users to deploy a chat application with various features. It provides branches for different functionalities like token-based message list trimming and usage demonstration of 'promplate'. Users can control the website through environment variables, including setting OpenAI API key, temperature parameter, proxy, base URL, and more. The project welcomes contributions and acknowledges supporters. It is licensed under MIT by Muspi Merol.
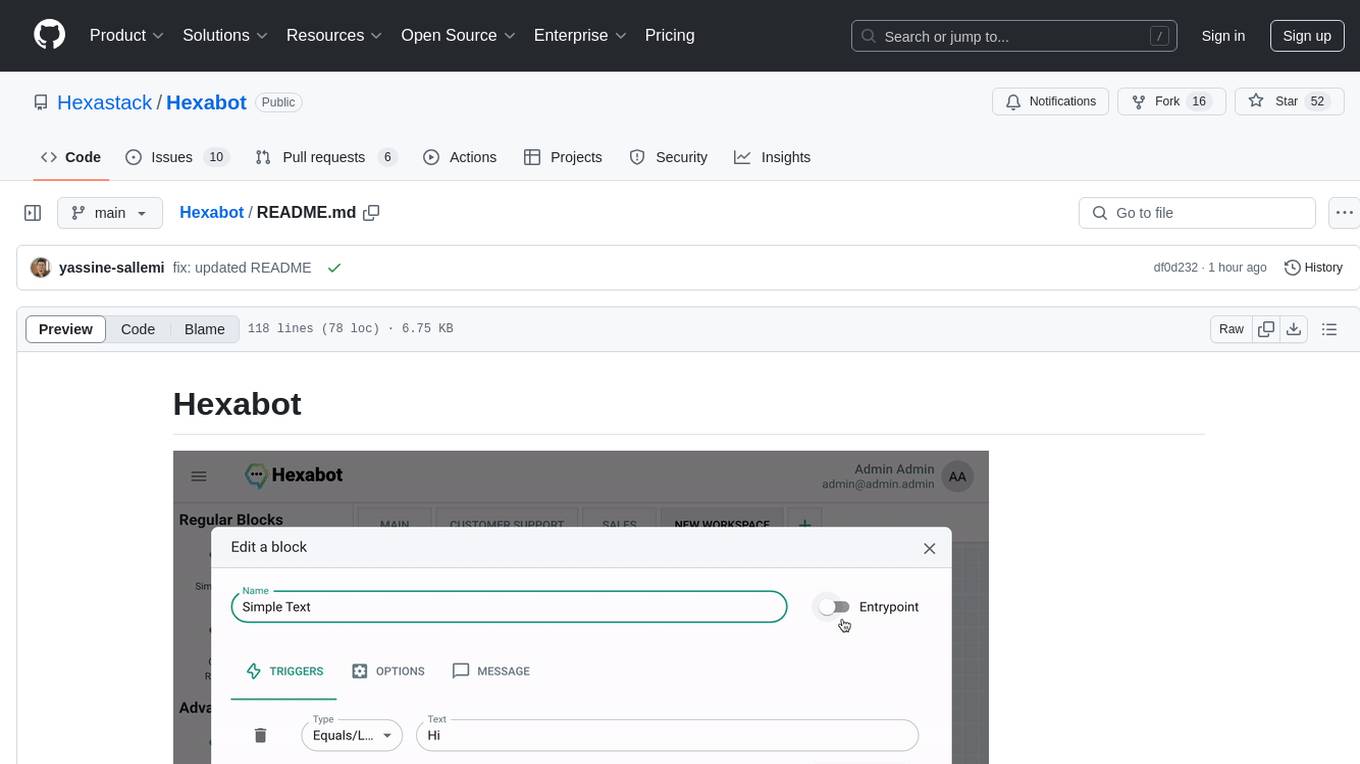
Hexabot
Hexabot Community Edition is an open-source chatbot solution designed for flexibility and customization, offering powerful text-to-action capabilities. It allows users to create and manage AI-powered, multi-channel, and multilingual chatbots with ease. The platform features an analytics dashboard, multi-channel support, visual editor, plugin system, NLP/NLU management, multi-lingual support, CMS integration, user roles & permissions, contextual data, subscribers & labels, and inbox & handover functionalities. The directory structure includes frontend, API, widget, NLU, and docker components. Prerequisites for running Hexabot include Docker and Node.js. The installation process involves cloning the repository, setting up the environment, and running the application. Users can access the UI admin panel and live chat widget for interaction. Various commands are available for managing the Docker services. Detailed documentation and contribution guidelines are provided for users interested in contributing to the project.

chatluna
Chatluna is a machine learning model plugin that provides chat services with large language models. It is highly extensible, supports multiple output formats, and offers features like custom conversation presets, rate limiting, and context awareness. Users can deploy Chatluna under Koishi without additional configuration. The plugin supports various models/platforms like OpenAI, Azure OpenAI, Google Gemini, and more. It also provides preset customization using YAML files and allows for easy forking and development within Koishi projects. However, the project lacks web UI, HTTP server, and project documentation, inviting contributions from the community.

BrowserGym
BrowserGym is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides benchmarks like MiniWoB, WebArena, VisualWebArena, WorkArena, AssistantBench, and WebLINX. Users can design new web benchmarks by inheriting the AbstractBrowserTask class. The tool allows users to install different packages for core functionalities, experiments, and specific benchmarks. It supports the development setup and offers boilerplate code for running agents on various tasks. BrowserGym is not a consumer product and should be used with caution.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.
nekro-agent
Nekro Agent is an AI chat plugin and proxy execution bot that is highly scalable, offers high freedom, and has minimal deployment requirements. It features context-aware chat for group/private chats, custom character settings, sandboxed execution environment, interactive image resource handling, customizable extension development interface, easy deployment with docker-compose, integration with Stable Diffusion for AI drawing capabilities, support for various file types interaction, hot configuration updates and command control, native multimodal understanding, visual application management control panel, CoT (Chain of Thought) support, self-triggered timers and holiday greetings, event notification understanding, and more. It allows for third-party extensions and AI-generated extensions, and includes features like automatic context trigger based on LLM, and a variety of basic commands for bot administrators.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
koog
Koog is a Kotlin-based framework for building and running AI agents entirely in idiomatic Kotlin. It allows users to create agents that interact with tools, handle complex workflows, and communicate with users. Key features include pure Kotlin implementation, MCP integration, embedding capabilities, custom tool creation, ready-to-use components, intelligent history compression, powerful streaming API, persistent agent memory, comprehensive tracing, flexible graph workflows, modular feature system, scalable architecture, and multiplatform support.

req_llm
ReqLLM is a Req-based library for LLM interactions, offering a unified interface to AI providers through a plugin-based architecture. It brings composability and middleware advantages to LLM interactions, with features like auto-synced providers/models, typed data structures, ergonomic helpers, streaming capabilities, usage & cost extraction, and a plugin-based provider system. Users can easily generate text, structured data, embeddings, and track usage costs. The tool supports various AI providers like Anthropic, OpenAI, Groq, Google, and xAI, and allows for easy addition of new providers. ReqLLM also provides API key management, detailed documentation, and a roadmap for future enhancements.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
odoo-llm
This repository provides a comprehensive framework for integrating Large Language Models (LLMs) into Odoo. It enables seamless interaction with AI providers like OpenAI, Anthropic, Ollama, and Replicate for chat completions, text embeddings, and more within the Odoo environment. The architecture includes external AI clients connecting via `llm_mcp_server` and Odoo AI Chat with built-in chat interface. The core module `llm` offers provider abstraction, model management, and security, along with tools for CRUD operations and domain-specific tool packs. Various AI providers, infrastructure components, and domain-specific tools are available for different tasks such as content generation, knowledge base management, and AI assistants creation.
arcade-ai
Arcade AI is a developer-focused tooling and API platform designed to enhance the capabilities of LLM applications and agents. It simplifies the process of connecting agentic applications with user data and services, allowing developers to concentrate on building their applications. The platform offers prebuilt toolkits for interacting with various services, supports multiple authentication providers, and provides access to different language models. Users can also create custom toolkits and evaluate their tools using Arcade AI. Contributions are welcome, and self-hosting is possible with the provided documentation.
yao
YAO is an open-source application engine written in Golang, suitable for developing business systems, website/APP API, admin panel, and self-built low-code platforms. It adopts a flow-based programming model to implement functions by writing YAO DSL or using JavaScript. Yao allows developers to create web services by processes, creating a database model, writing API services, and describing dashboard interfaces just by JSON for web & hardware, and 10x productivity. It is based on the flow-based programming idea, developed in Go language, and supports multiple ways to expand the data stream processor. Yao has a built-in data management system, making it suitable for quickly making various management backgrounds, CRM, ERP, and other internal enterprise systems. It is highly versatile, efficient, and performs better than PHP, JAVA, and other languages.
For similar tasks
OllamaSharp
OllamaSharp is a .NET binding for the Ollama API, providing an intuitive API client to interact with Ollama. It offers support for all Ollama API endpoints, real-time streaming, progress reporting, and an API console for remote management. Users can easily set up the client, list models, pull models with progress feedback, stream completions, and build interactive chats. The project includes a demo console for exploring and managing the Ollama host.

client-js
The Mistral JavaScript client is a library that allows you to interact with the Mistral AI API. With this client, you can perform various tasks such as listing models, chatting with streaming, chatting without streaming, and generating embeddings. To use the client, you can install it in your project using npm and then set up the client with your API key. Once the client is set up, you can use it to perform the desired tasks. For example, you can use the client to chat with a model by providing a list of messages. The client will then return the response from the model. You can also use the client to generate embeddings for a given input. The embeddings can then be used for various downstream tasks such as clustering or classification.
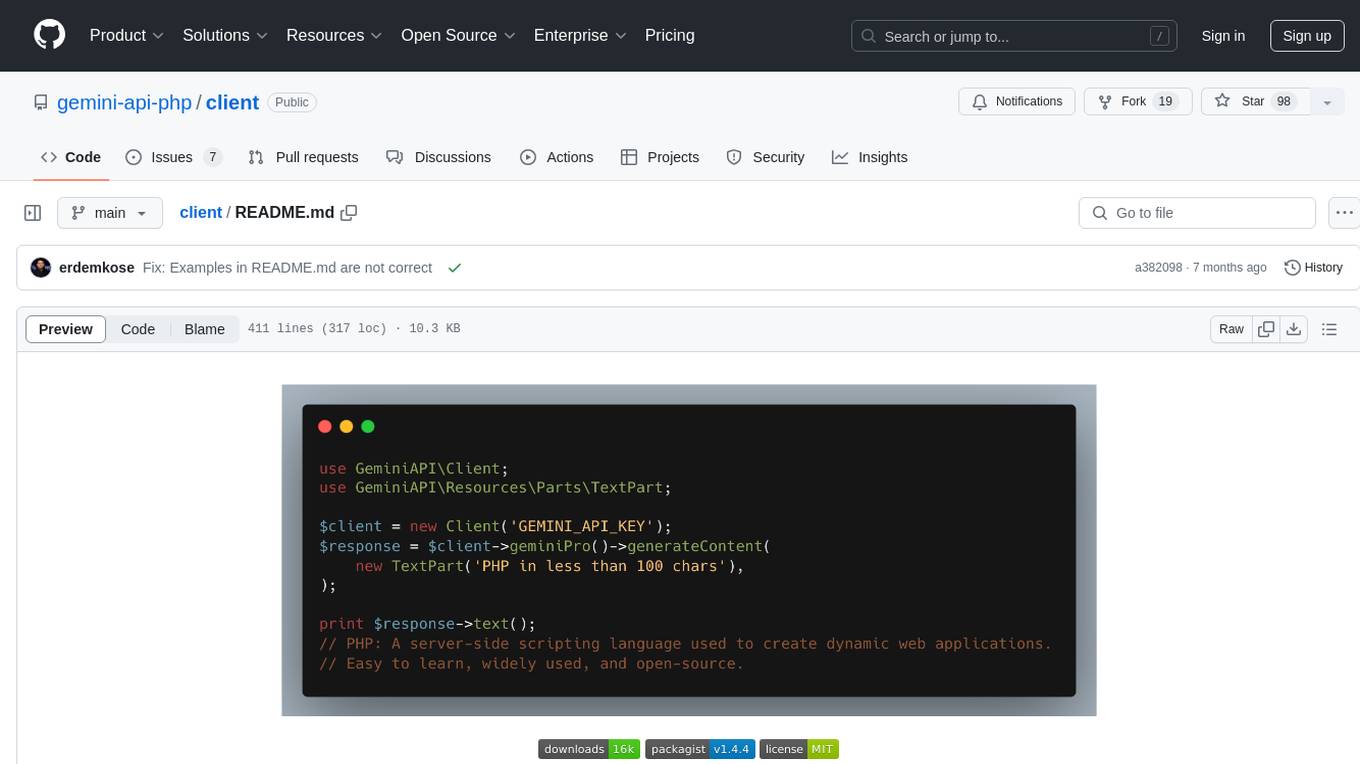
client
Gemini API PHP Client is a library that allows you to interact with Google's generative AI models, such as Gemini Pro and Gemini Pro Vision. It provides functionalities for basic text generation, multimodal input, chat sessions, streaming responses, tokens counting, listing models, and advanced usages like safety settings and custom HTTP client usage. The library requires an API key to access Google's Gemini API and can be installed using Composer. It supports various features like generating content, starting chat sessions, embedding content, counting tokens, and listing available models.
ramalama
The Ramalama project simplifies working with AI by utilizing OCI containers. It automatically detects GPU support, pulls necessary software in a container, and runs AI models. Users can list, pull, run, and serve models easily. The tool aims to support various GPUs and platforms in the future, making AI setup hassle-free.
jvm-openai
jvm-openai is a minimalistic unofficial OpenAI API client for the JVM, written in Java. It serves as a Java client for OpenAI API with a focus on simplicity and minimal dependencies. The tool provides support for various OpenAI APIs and endpoints, including Audio, Chat, Embeddings, Fine-tuning, Batch, Files, Uploads, Images, Models, Moderations, Assistants, Threads, Messages, Runs, Run Steps, Vector Stores, Vector Store Files, Vector Store File Batches, Invites, Users, Projects, Project Users, Project Service Accounts, Project API Keys, and Audit Logs. Users can easily integrate this tool into their Java projects to interact with OpenAI services efficiently.
ollama-r
The Ollama R library provides an easy way to integrate R with Ollama for running language models locally on your machine. It supports working with standard data structures for different LLMs, offers various output formats, and enables integration with other libraries/tools. The library uses the Ollama REST API and requires the Ollama app to be installed, with GPU support for accelerating LLM inference. It is inspired by Ollama Python and JavaScript libraries, making it familiar for users of those languages. The installation process involves downloading the Ollama app, installing the 'ollamar' package, and starting the local server. Example usage includes testing connection, downloading models, generating responses, and listing available models.
openai-scala-client
This is a no-nonsense async Scala client for OpenAI API supporting all the available endpoints and params including streaming, chat completion, vision, and voice routines. It provides a single service called OpenAIService that supports various calls such as Models, Completions, Chat Completions, Edits, Images, Embeddings, Batches, Audio, Files, Fine-tunes, Moderations, Assistants, Threads, Thread Messages, Runs, Run Steps, Vector Stores, Vector Store Files, and Vector Store File Batches. The library aims to be self-contained with minimal dependencies and supports API-compatible providers like Azure OpenAI, Azure AI, Anthropic, Google Vertex AI, Groq, Grok, Fireworks AI, OctoAI, TogetherAI, Cerebras, Mistral, Deepseek, Ollama, FastChat, and more.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.