Best AI tools for< Image Understanding >
20 - AI tool Sites
Image Describer
Image Describer is an AI-powered image description generator that allows users to upload an image, select a use case, add additional information, and receive a detailed description of the image's content. It can summarize the content of the picture, describe physical objects, emotions, and atmosphere within the picture. The tool also offers Text-To-Speech ability to assist visually impaired individuals in understanding image content.
Picture To Summary AI
Picture To Summary AI is an online tool that leverages cutting-edge AI technology to provide summaries from images or pictures. Users can upload images and receive concise and accurate summaries generated by AI, extract text from images, generate captions for social media posts, and customize prompts to tailor descriptions. The tool aims to simplify communication and understanding of image content through AI-driven analysis.
Picture To Summary AI
Picture To Summary AI is a powerful online tool that leverages cutting-edge AI technology to analyze images and generate insightful summaries or descriptions. Users can upload images and receive concise and accurate summaries, extract text from images, generate captions for social media posts, and customize prompts to tailor the output. The application aims to simplify communication and understanding by providing quick and efficient image analysis solutions.
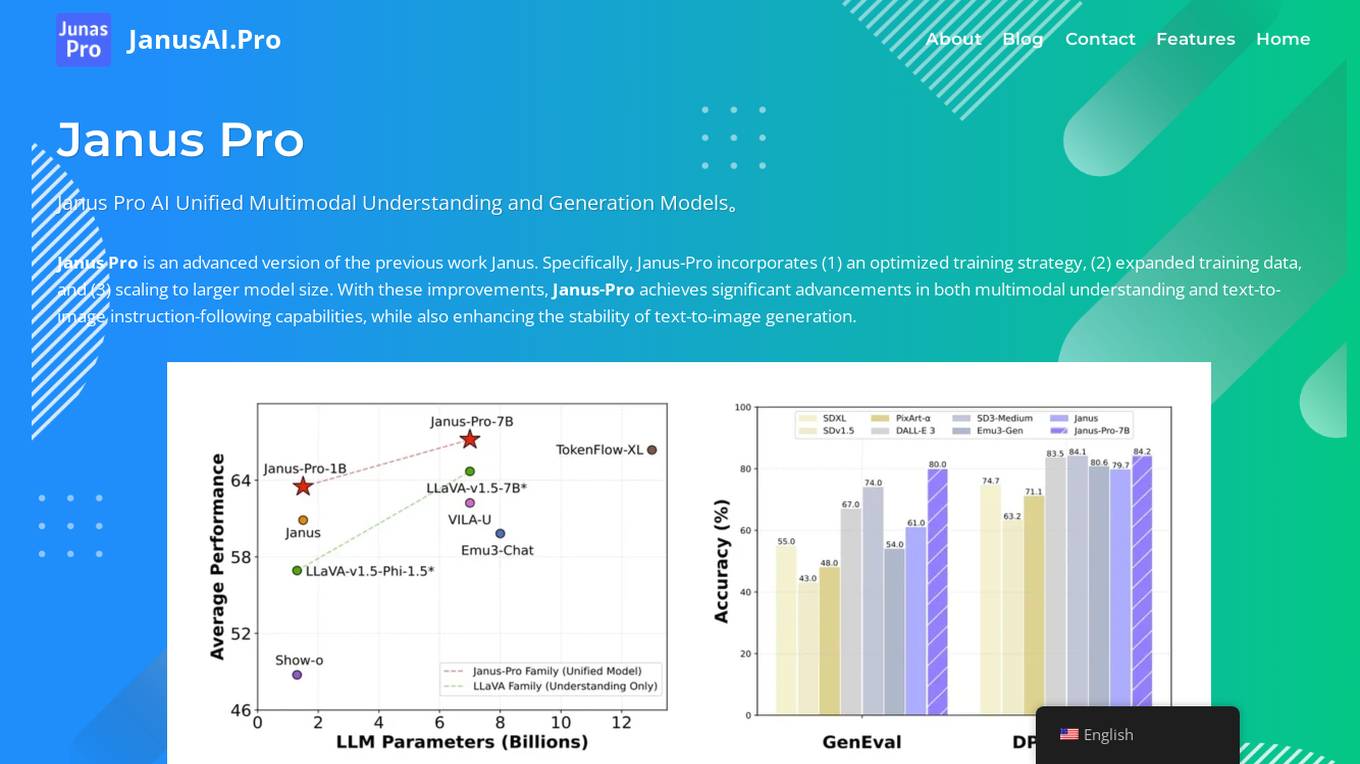
Janus Pro AI
Janus Pro AI is an advanced unified multimodal AI model that combines image understanding and generation capabilities. It incorporates optimized training strategies, expanded training data, and larger model scaling to achieve significant advancements in both multimodal understanding and text-to-image generation tasks. Janus Pro features a decoupled visual encoding system, outperforming leading models like DALL-E 3 and Stable Diffusion in benchmark tests. It offers open-source compatibility, vision processing specifications, cost-effective scalability, and an optimized training framework.
Describe.pictures
Describe.pictures is an AI tool designed to generate detailed descriptions of images. By utilizing advanced AI models, users can quickly obtain complete descriptions of various images. The tool allows users to select an image and input the desired way of describing it, such as providing detailed or brief descriptions. The generated descriptions are detailed and vivid, capturing the essence and details of the image. With a focus on enhancing user experience and providing accurate image descriptions, Describe.pictures is a valuable tool for various applications.

Molmo AI
Molmo AI is a powerful, open-source multimodal AI model revolutionizing visual understanding. It helps developers easily build tools that can understand images and interact with the world in useful ways. Molmo AI offers exceptional image understanding, efficient data usage, open and accessible features, on-device compatibility, and a new era in multimodal AI development. It closes the gap between open and closed AI models, empowers the AI community with open access, and efficiently utilizes data for superior performance.
AITag.Photo
AITag.Photo is an AI tool that helps users quickly generate tags, descriptions, and other keywords for their photos. It uses advanced image understanding technology to accurately generate content descriptions for each photo, making it easy to organize and manage photos efficiently. Users can create stories based on images, featuring dialogues or monologues of characters. AITag.Photo simplifies the process of describing photos, saving users time and effort in photo management.

CVF Open Access
The Computer Vision Foundation (CVF) is a non-profit organization dedicated to advancing the field of computer vision. CVF organizes several conferences and workshops each year, including the International Conference on Computer Vision (ICCV), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Winter Conference on Applications of Computer Vision (WACV). CVF also publishes the International Journal of Computer Vision (IJCV) and the Computer Vision and Image Understanding (CVIU) journal. The CVF Open Access website provides access to the full text of all CVF-sponsored conference papers. These papers are available for free download in PDF format. The CVF Open Access website also includes links to the arXiv versions of the papers, where available.

YesChat
YesChat is an AI-driven platform that provides access to a vast array of AI technologies for various needs, including ChatGPT, GPT-4V for text generation and image understanding, Dalle3 for image creation, and Claude for document analysis. With YesChat, users can chat with their files, browse the internet, chat with images, generate images, and access nearly 200,000 GPT models for a wide variety of applications in work, study, and everyday life. YesChat offers 20 free GPT-4V uses per day, and users can subscribe for additional benefits and extended access.
Monkt
Monkt is a powerful document processing platform that transforms various document formats into AI-ready Markdown or structured JSON. It offers features like instant conversion of PDF, Word, PowerPoint, Excel, CSV, web pages, and raw HTML into clean markdown format optimized for AI/LLM systems. Monkt enables users to create intelligent applications, custom AI chatbots, knowledge bases, and training datasets. It supports batch processing, image understanding, LLM optimization, and API integration for seamless document processing. The platform is designed to handle document transformation at scale, with support for multiple file formats and custom JSON schemas.
Nano Banana AI Image Creator & Editor
Nano Banana AI Image Creator & Editor is an advanced AI platform that allows users to create and edit images instantly with simple prompts. It leverages cutting-edge Nano Banana AI technology to effortlessly craft exceptional artwork, illustrations, and visual content. The platform offers a streamlined journey from creative idea to stunning visual content, providing features like character consistency, multi-image context understanding, and instant generation. Users can enhance their creations with powerful editing tools and export high-resolution images for various platforms. Nano Banana AI revolutionizes visual content creation with unmatched precision, consistency, and ease-of-use.
Janus Pro AI
Janus Pro AI is a cutting-edge multimodal image generation and understanding platform that empowers users to create high-quality images for various projects. It offers powerful features such as multiple art styles, smart editing, lightning-fast image generation, high resolution output, commercial rights, and 24/7 generation service. The platform is built on DeepSeek's advanced architecture, providing users with a seamless experience in generating images in different styles and settings.
NSFW AI Images Generator
The NSFW AI Images Generator is an AI tool that specializes in crafting dream female portraits and generating NSFW AI chat conversations. It offers users the ability to create ideal beauty images and interact with an AI girlfriend for companionship. The tool aims to provide users with a unique and personalized experience through AI-generated content.
Nana Banana AI Image Editor
Nana Banana is a revolutionary AI image editor powered by Google Nano Banana Official API. It offers advanced natural language understanding, exceptional character consistency, and one-shot editing perfection. Users can create stunning images by leveraging cutting-edge technology to transform text prompts into visual reality with precision.
Grok AI Image Generator | Grok 2.0
Grok AI Image Generator | Grok 2.0 is an AI image generator that leverages the power of AI to create stunning and diverse images. It is an open-source large language model AI developed by Elon Musk, offering enhanced language understanding, code capabilities, and drawing features. Users can generate high-quality, photorealistic images with minimal content restrictions, powered by the FLUX.1 model for advanced capabilities.
Image Narrate
This free AI image description generator tool allows users to upload an image and receive a detailed description of its contents. The tool utilizes advanced AI algorithms to analyze the image's elements, including color, shape, and texture, to generate a comprehensive description that captures the hidden meanings and emotions conveyed by the image. The tool is particularly useful for artists, designers, and anyone interested in gaining a deeper understanding of their own creations or exploring the hidden narratives within images.
Nano Banana
Nano Banana is a free online AI image editor that allows users to create and edit images quickly and efficiently using powerful AI technology. With features like portrait enhancement, style transfer, background editing, object modification, color grading, image restoration, and more, Nano Banana offers a wide range of tools for image manipulation. Users can generate consistent images, try on clothes virtually, create anime avatars, edit sketches, remove backgrounds, swap faces, make memes and stickers, and much more. The application is powered by Google's latest AI technology, providing fast processing and high-quality results for various image editing tasks.
Flux Image AI Generator
Flux Image AI Generator is an online tool that utilizes advanced AI technology to transform text prompts into high-quality images in seconds. It offers a range of models catering to different needs, from commercial projects to non-commercial experimentation. With features like image-to-image generation and advanced language understanding, Flux Image AI Generator provides users with unprecedented creative control and speed in generating visuals.
VirtualFantasy.ai
VirtualFantasy.ai is an AI-powered virtual companion platform that utilizes advanced artificial intelligence algorithms to provide users with personalized assistance and companionship. The platform offers a wide range of features such as virtual conversations, emotional support, task reminders, entertainment recommendations, and personalized insights. VirtualFantasy.ai aims to enhance users' daily lives by offering a virtual companion that can engage in meaningful interactions and provide support whenever needed.

MiniGPT-4
MiniGPT-4 is a powerful AI tool that combines a vision encoder with a large language model (LLM) to enhance vision-language understanding. It can generate detailed image descriptions, create websites from handwritten drafts, write stories and poems inspired by images, provide solutions to problems shown in images, and teach users how to cook based on food photos. MiniGPT-4 is highly computationally efficient and easy to use, making it a valuable tool for a wide range of applications.
1 - Open Source AI Tools
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
20 - OpenAI Gpts
Image Descriptor for Image Generation
Upload image, then Expert image describer providing detailed and specific descriptions of images.
Making my ideal type
I guide in visualizing your ideal type and provide preference insights. 나의 이상형 이미지로 만들기
Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!

Image Generation with Selfcritique & Improvement
More accurate and easier image generation with self critique & improvement! Try it now
Easy Image Maker
Question-and-answer style image design agent, solving the problem of not knowing how to describe design parameters to GPT.
The Ultimate Image Generator
Highly optimized prompts and top secret refinements to create the perfect image every time...
Reliable Image Generator with LGTM Overlay
Efficiently generates images and overlays 'LGTM'
Image Scout
A comprehensive guide for finding themed public domain images with a vast resource list.
Consistent Image Generator
Geneate an image ➡ Request modifications. This GPT supports generating consistent and continuous images with Dalle. It also offers the ability to restore or integrate photos you upload. ✔️Where to use: Wordpress Blog Post, Youtube thumbnail, AI profile, facebook, X, threads feed, Instagram reels
Image Translator(→日本語)
画像中の文章を日本語に翻訳します。(使い方:画像をアップロードするだけ。プロンプトの文章は不要です。) 2023/12/29 より自然な日本語になるように修正