Best AI tools for< Evaluate Datasets >
20 - AI tool Sites

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Inspect
Inspect is an open-source framework for large language model evaluations created by the UK AI Safety Institute. It provides built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can explore various solvers, tools, scorers, datasets, and models to create advanced evaluations. Inspect supports extensions for new elicitation and scoring techniques through Python packages.
Athina AI
Athina AI is a platform that provides research and guides for building safe and reliable AI products. It helps thousands of AI engineers in building safer products by offering tutorials, research papers, and evaluation techniques related to large language models. The platform focuses on safety, prompt engineering, hallucinations, and evaluation of AI models.

Confident AI
Confident AI is an AI evaluation and observability platform designed to help engineers, QA teams, and product leaders build reliable AI systems. It offers best-in-class evaluation metrics powered by DeepEval, real-time production alerts, and tools for tracing and monitoring AI performance. The platform aims to streamline dataset curation, metric alignment, and LLM testing automation, ultimately saving time, reducing costs, and ensuring continuous improvement of AI models.

Machine Translation Research Hub
This website is a comprehensive resource for research in statistical and neural machine translation. It provides information, tools, and datasets related to the translation of text from one human language to another using computer algorithms trained on vast amounts of translated text.
Prolific
Prolific is a platform that allows users to quickly find research participants they can trust. It offers a diverse participant pool, including domain experts and API integration. Prolific ensures high-quality human-powered datasets in less than 2 hours, trusted by over 3000 organizations. The platform is designed for ease of use, with self-serve options and scalability. It provides rich, accurate, and comprehensive responses from engaged participants, verified through manual and algorithmic quality checks.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
AI Alliance
The AI Alliance is a community dedicated to building and advancing open-source AI agents, data, models, evaluation, safety, applications, and advocacy to ensure everyone can benefit. They focus on various areas such as skills and education, trust and safety, applications and tools, hardware enablement, foundation models, and advocacy. The organization supports global AI skill-building, education, and exploratory research, creates benchmarks and tools for safe generative AI, builds capable tools for AI model builders and developers, fosters AI hardware accelerator ecosystem, enables open foundation models and datasets, and advocates for regulatory policies for healthy AI ecosystems.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
Vocera
Vocera is an AI voice agent testing tool that allows users to test and monitor voice AI agents efficiently. It enables users to launch voice agents in minutes, ensuring a seamless conversational experience. With features like testing against AI-generated datasets, simulating scenarios, and monitoring AI performance, Vocera helps in evaluating and improving voice agent interactions. The tool provides real-time insights, detailed logs, and trend analysis for optimal performance, along with instant notifications for errors and failures. Vocera is designed to work for everyone, offering an intuitive dashboard and data-driven decision-making for continuous improvement.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.

Lisapet.AI
Lisapet.AI is an AI prompt testing suite designed for product teams to streamline the process of designing, prototyping, testing, and shipping AI features. It offers a comprehensive platform with features like best-in-class AI playground, variables for dynamic data inputs, structured outputs, side-by-side editing, function calling, image inputs, assertions & metrics, performance comparison, data sets organization, shareable reports, comments & feedback, token & cost stats, and more. The application aims to help teams save time, improve efficiency, and ensure the reliability of AI features through automated prompt testing.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
2 - Open Source AI Tools
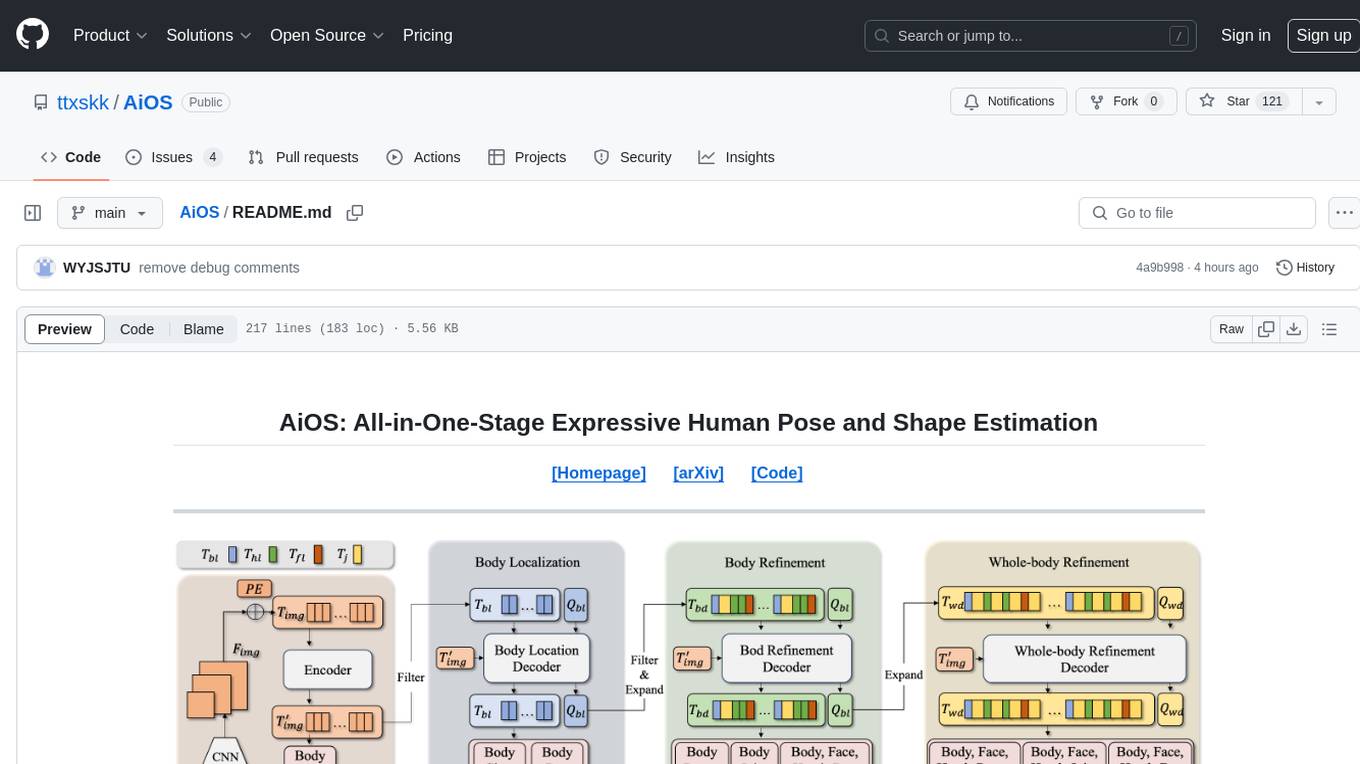
AiOS
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.
DreamLayer
DreamLayer AI is an open-source Stable Diffusion WebUI designed for AI researchers, labs, and developers. It automates prompts, seeds, and metrics for benchmarking models, datasets, and samplers, enabling reproducible evaluations across multiple seeds and configurations. The tool integrates custom metrics and evaluation pipelines, providing a streamlined workflow for AI research. With features like automated benchmarking, reproducibility, built-in metrics, multi-modal readiness, and researcher-friendly interface, DreamLayer AI aims to simplify and accelerate the model evaluation process.
20 - OpenAI Gpts


HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub
Chronic Disease Indicators Expert
This chatbot answers questions about the CDC’s Chronic Disease Indicators dataset

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.