
EasyAIVtuber
Simply animate your 2D waifu.
Stars: 51
EasyAIVtuber is a tool designed to animate 2D waifus by providing features like automatic idle actions, speaking animations, head nodding, singing animations, and sleeping mode. It also offers API endpoints and a web UI for interaction. The tool requires dependencies like torch and pre-trained models for optimal performance. Users can easily test the tool using OBS and UnityCapture, with options to customize character input, output size, simplification level, webcam output, model selection, port configuration, sleep interval, and movement extension. The tool also provides an API using Flask for actions like speaking based on audio, rhythmic movements, singing based on music and voice, stopping current actions, and changing images.
README:
驱动你的纸片人老婆。 Simply animate your 2D waifu.

Fork自 yuyuyzl/EasyVtuber。由于是AI Vtuber,因此删减了原项目的面捕功能。
本项目配合stable diffusion等文生图模型为最佳食用方式。喜欢请点个星星哦~
视频教程:制作中...0.0
- 空闲自动做动作(眨眼、东张西望)
- 说话动作(自动对口型)
- 摇子(自动随节奏点头)
- 唱歌动作(自动对口型,跟随节奏摇摆)
- 睡大觉(使用
--sleep参数控制入睡间隔) - API调用接口
- webui方式调用
创建并激活虚拟环境
conda create -n eaiv python=3.10
conda activate eaiv
安装torch(最好是30系显卡及以上)
# CUDA 11.8
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
然后在项目目录下执行以下命令
pip install -r requirements.txt
原模型文件地址:https://www.dropbox.com/s/y7b8jl4n2euv8xe/talking-head-anime-3-models.zip?dl=0
下载后解压到data/models文件夹中,与placeholder.txt同级
如果不想下载所有权重(四个版本),也可以在huggingface上下载:https://huggingface.co/ksuriuri/talking-head-anime-3-models
正确的目录层级为
+ models
- separable_float
- separable_half
- standard_float
- standard_half
- placeholder.txt
可在网上自行搜索教程安装
注:如果电脑上安装过VTube Studio,也许OBS的视频采集设备的设备中就会有 VTubeStudioCam(没做过实验不太确定)。 若有此设备,便无需执行下面步骤安装UnityCapture,直接使用 VTubeStudioCam 即可
为了能够在OBS上看到纸片老婆并且使用透明背景,需要安装UnityCapture
参考 https://github.com/schellingb/UnityCapture#installation
只需要正常走完Install.bat,在OBS的视频采集设备中便能看到对应的设备(Unity Video Capture)。
在OBS添加完视频采集设备以后,右键视频采集设备-设置-取消激活-分辨率类型选自定义-分辨率512x512(与--output_size参数一致)-视频格式选ARGB-激活
- 打开OBS,添加视频采集设备并按要求(安装UnityCapture)进行配置
- 将
main.bat中第一行的虚拟环境的路径修改为你自己的虚拟环境路径 - 运行
main.bat,等待初始化完毕,如配置无误,这时OBS中便能够看到人物在动 - 二选一
- 简单测试:运行
test.py - 运行webui:将
webui.bat中第一行的虚拟环境的路径修改为你自己的虚拟环境路径,然后运行webui.bat
- 简单测试:运行
具体使用可参考 API Details
| 参数名 | 类型 | 说明 |
|---|---|---|
| --character | str |
data/images目录下的输入图像文件名,不需要带扩展名 |
| --output_size | str | 格式为512x512,必须是4的倍数。增大它并不会让图像更清晰,但配合extend_movement会增大可动范围 |
| --simplify | int | 可用值为1 2 3 4,值越大CPU运算量越小,但动作精度越低 |
| --output_webcam | str | 可用值为unitycapture,选择对应的输出种类,不传不输出到摄像头 |
| --model | str | 可用值为standard_float standard_half separable_float separable_half,显存占用不同,选择合适的即可 |
| --port | int | 本地API的端口号,默认为7888,若7888被占用则需要更改 |
| --sleep | int | 入睡间隔,默认为20,空闲状态下20秒后会睡大觉,设置为-1即可不进入睡觉状态 |
| --extend_movement | float | 暂时没有用)根据头部位置,对模型输出图像进一步进行移动和旋转使得上半身可动 传入的数值表示移动倍率(建议值为1) |
API使用Flask来开发,默认运行在 http://127.0.0.1:7888 (默认端口为7888),可在main.bat的--port中修改端口号。
使用post请求 http://127.0.0.1:7888/alive ,并传入参数即可做出对应动作,具体示例可参考test.py。
REQUEST
{
"type": "speak",
"speech_path": "your speech path"
}在"speech_path"中填写你的语音音频路径,支持wav, mp3, flac等格式(pygame支持的格式)
RESPONSE
{
"status": "success"
}REQUEST
{
"type": "rhythm",
"music_path": "your music path",
"beat": 2
}在"music_path"中填写你的音频路径,支持wav, mp3, flac等格式(pygame支持的格式)。
"beat"(可选):取值为 1 2 4,控制节拍,默认为2
RESPONSE
{
"status": "success"
}REQUEST
{
"type": "sing",
"music_path": "your music path",
"voice_path": "your voice path",
"mouth_offset": 0.0,
"beat": 2
}口型驱动的原理是根据音量大小来控制嘴巴的大小,因此需要事先将人声提取出来以更精准地控制口型。
假设你有一首歌,路径为path/music.wav,利用UVR5等工具分离出人声音频path/voice.wav,然后将path/music.wav填入"music_path",
将path/voice.wav填入"voice_path",支持wav, mp3, flac等格式(pygame支持的格式)。
"mouth_offset"(可选):取值区间为 [0, 1],默认为0,如果角色唱歌时的嘴张的不够大,可以试试将这个值设大
"beat"(可选):取值为1 2 4,默认为2,控制节拍
RESPONSE
{
"status": "success"
}REQUEST
{
"type": "stop"
}RESPONSE
{
"status": "success"
}REQUEST
{
"type": "change_img",
"img": "your image path"
}在"img"中填写图片路径,图片大小最好是512x512,png格式
RESPONSE
{
"status": "success"
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for EasyAIVtuber
Similar Open Source Tools
EasyAIVtuber
EasyAIVtuber is a tool designed to animate 2D waifus by providing features like automatic idle actions, speaking animations, head nodding, singing animations, and sleeping mode. It also offers API endpoints and a web UI for interaction. The tool requires dependencies like torch and pre-trained models for optimal performance. Users can easily test the tool using OBS and UnityCapture, with options to customize character input, output size, simplification level, webcam output, model selection, port configuration, sleep interval, and movement extension. The tool also provides an API using Flask for actions like speaking based on audio, rhythmic movements, singing based on music and voice, stopping current actions, and changing images.

step-free-api
The StepChat Free service provides high-speed streaming output, multi-turn dialogue support, online search support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. Additionally, it provides seven other free APIs for various services. The repository includes a disclaimer about using reverse APIs and encourages users to avoid commercial use to prevent service pressure on the official platform. It offers online testing links, showcases different demos, and provides deployment guides for Docker, Docker-compose, Render, Vercel, and native deployments. The repository also includes information on using multiple accounts, optimizing Nginx reverse proxy, and checking the liveliness of refresh tokens.

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation
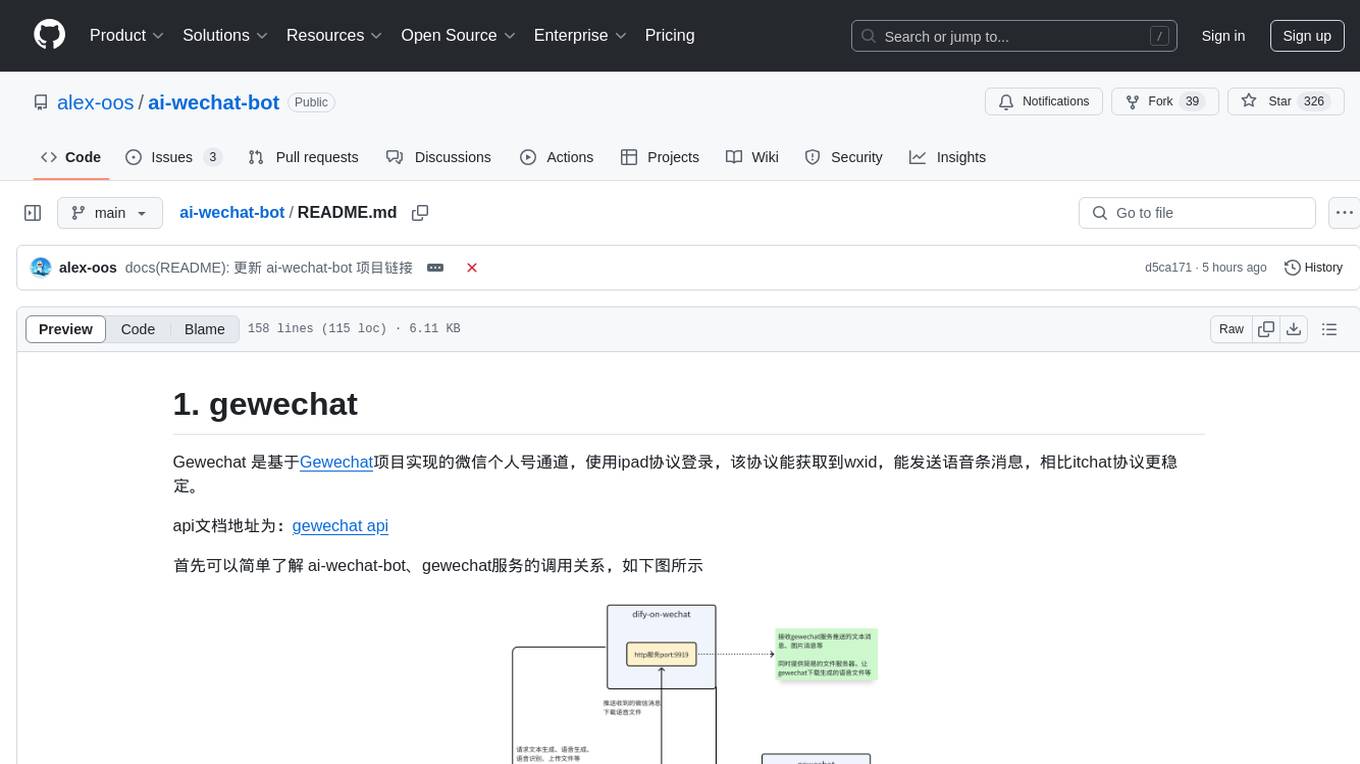
ai-wechat-bot
Gewechat is a project based on the Gewechat project to implement a personal WeChat channel, using the iPad protocol for login. It can obtain wxid and send voice messages, which is more stable than the itchat protocol. The project provides documentation for the API. Users can deploy the Gewechat service and use the ai-wechat-bot project to interface with it. Configuration parameters for Gewechat and ai-wechat-bot need to be set in the config.json file. Gewechat supports sending voice messages, with limitations on the duration of received voice messages. The project has restrictions such as requiring the server to be in the same province as the device logging into WeChat, limited file download support, and support only for text and image messages.
Groq2API
Groq2API is a REST API wrapper around the Groq2 model, a large language model trained by Google. The API allows you to send text prompts to the model and receive generated text responses. The API is easy to use and can be integrated into a variety of applications.
emohaa-free-api
Emohaa AI Free API is a free API that allows you to access the Emohaa AI chatbot. Emohaa AI is a powerful chatbot that can understand and respond to a wide range of natural language queries. It can be used for a variety of purposes, such as customer service, information retrieval, and language translation. The Emohaa AI Free API is easy to use and can be integrated into any application. It is a great way to add AI capabilities to your projects without having to build your own chatbot from scratch.

spark-free-api
Spark AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, AI drawing support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository includes multiple free-api projects for various AI services. Users can access the API for tasks such as chat completions, AI drawing, document interpretation, image analysis, and ssoSessionId live checking. The project also provides guidelines for deployment using Docker, Docker-compose, Render, Vercel, and native deployment methods. It recommends using custom clients for faster and simpler access to the free-api series projects.

Chat-Style-Bot
Chat-Style-Bot is an intelligent chatbot designed to mimic the chatting style of a specified individual. By analyzing and learning from WeChat chat records, Chat-Style-Bot can imitate your unique chatting style and become your personal chat assistant. Whether it's communicating with friends or handling daily conversations, Chat-Style-Bot can provide a natural, personalized interactive experience.
HiveChat
HiveChat is an AI chat application designed for small and medium teams. It supports various models such as DeepSeek, Open AI, Claude, and Gemini. The tool allows easy configuration by one administrator for the entire team to use different AI models. It supports features like email or Feishu login, LaTeX and Markdown rendering, DeepSeek mind map display, image understanding, AI agents, cloud data storage, and integration with multiple large model service providers. Users can engage in conversations by logging in, while administrators can configure AI service providers, manage users, and control account registration. The technology stack includes Next.js, Tailwindcss, Auth.js, PostgreSQL, Drizzle ORM, and Ant Design.
newapi-ai-check-in
The newapi.ai-check-in repository is designed for automatically signing in with multiple accounts on public welfare websites. It supports various features such as single/multiple account automatic check-ins, multiple robot notifications, Linux.do and GitHub login authentication, and Cloudflare bypass. Users can fork the repository, set up GitHub environment secrets, configure multiple account formats, enable GitHub Actions, and test the check-in process manually. The script runs every 8 hours and users can trigger manual check-ins at any time. Notifications can be enabled through email, DingTalk, Feishu, WeChat Work, PushPlus, ServerChan, and Telegram bots. To prevent automatic disabling of Actions due to inactivity, users can set up a trigger PAT in the GitHub settings. The repository also provides troubleshooting tips for failed check-ins and instructions for setting up a local development environment.
qwen-free-api
Qwen AI Free service supports high-speed streaming output, multi-turn dialogue, watermark-free AI drawing, long document interpretation, image parsing, zero-configuration deployment, multi-token support, automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository provides various free APIs for different AI services. Users can access the service through different deployment methods like Docker, Docker-compose, Render, Vercel, and native deployment. It offers interfaces for chat completions, AI drawing, document interpretation, image parsing, and token checking. Users need to provide 'login_tongyi_ticket' for authorization. The project emphasizes research, learning, and personal use only, discouraging commercial use to avoid service pressure on the official platform.
superagent
Superagent is an open-source AI assistant framework and API that allows developers to add powerful AI assistants to their applications. These assistants use large language models (LLMs), retrieval augmented generation (RAG), and generative AI to help users with a variety of tasks, including question answering, chatbot development, content generation, data aggregation, and workflow automation. Superagent is backed by Y Combinator and is part of YC W24.

Bindu
Bindu is an operating layer for AI agents that provides identity, communication, and payment capabilities. It delivers a production-ready service with a convenient API to connect, authenticate, and orchestrate agents across distributed systems using open protocols: A2A, AP2, and X402. Built with a distributed architecture, Bindu makes it fast to develop and easy to integrate with any AI framework. Transform any agent framework into a fully interoperable service for communication, collaboration, and commerce in the Internet of Agents.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.
glm-free-api
GLM AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, intelligent agent dialogue support, AI drawing support, online search support, long document interpretation support, image parsing support. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository also includes six other free APIs for various services like Moonshot AI, StepChat, Qwen, Metaso, Spark, and Emohaa. The tool supports tasks such as chat completions, AI drawing, document interpretation, image parsing, and refresh token survival check.
For similar tasks
EasyAIVtuber
EasyAIVtuber is a tool designed to animate 2D waifus by providing features like automatic idle actions, speaking animations, head nodding, singing animations, and sleeping mode. It also offers API endpoints and a web UI for interaction. The tool requires dependencies like torch and pre-trained models for optimal performance. Users can easily test the tool using OBS and UnityCapture, with options to customize character input, output size, simplification level, webcam output, model selection, port configuration, sleep interval, and movement extension. The tool also provides an API using Flask for actions like speaking based on audio, rhythmic movements, singing based on music and voice, stopping current actions, and changing images.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.