
spandrel
Spandrel gives your project support for various PyTorch architectures meant for AI Super-Resolution, restoration, and inpainting. Based on the model support implemented in chaiNNer.
Stars: 183
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.
README:



![]()


Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.
After seeing many projects extract out chaiNNer's model support into their own projects, I decided to create this PyPi package for the architecture support and model loading functionality. I'm also hoping that by having a central package anyone can use, the community will be encouraged to help add support for more models.
This package does not yet have easy inference code, but porting that code is planned as well.
Spandrel is available through pip:
pip install spandrelWhile Spandrel supports different kinds of models, this is how you would run a super resolution model (e.g. ESRGAN, SwinIR, HAT, etc.):
from spandrel import ImageModelDescriptor, ModelLoader
import torch
# load a model from disk
model = ModelLoader().load_from_file(r"path/to/model.pth")
# make sure it's an image to image model
assert isinstance(model, ImageModelDescriptor)
# send it to the GPU and put it in inference mode
model.cuda().eval()
# use the model
def process(image: torch.Tensor) -> torch.Tensor:
with torch.no_grad():
return model(image)Note that model is a ModelDescriptor object, which is a wrapper around the actual PyTorch model. This wrapper provides a unified interface for running models, and also contains metadata about the model. See ImageModelDescriptor for more details about the metadata contained and how to call the model.
NOTE:
ImageModelDescriptorwill NOT convert an image to a tensor for you. It is purely making the forward passes of these models more convenient to use, since the actual forward passes are not always as simple as image in/image out.
If you are working on a non-commercial open-source project or a private project, you should use spandrel and spandrel_extra_arches to get everything spandrel has to offer. The spandrel package only contains architectures with permissive and public domain licenses (MIT, Apache 2.0, public domain), so it is fit for every use case. Architectures with restrictive licenses (e.g. non-commercial) are implemented in the spandrel_extra_arches package.
import spandrel
import spandrel_extra_arches
# add extra architectures before `ModelLoader` is used
spandrel_extra_arches.install()
# load a model from disk
model = spandrel.ModelLoader().load_from_file(r"path/to/model.pth")
... # use modelSpandrel mainly supports loading .pth files for all supported architectures. This is what you will typically find from official repos and community trained models. However, Spandrel also supports loading TorchScript traced models (.pt), certain types of .ckpt files, and .safetensors files for any supported architecture saved in one of these formats.
NOTE: By its very nature, Spandrel will never be able to support every model architecture. The goal is just to support as many as is realistically possible.
Spandrel currently supports a limited amount of network architectures. If the architecture you need is not supported, feel free to request it or try adding it.
-
ESRGAN (RRDBNet)
- This includes regular ESRGAN, ESRGAN+, "new-arch ESRGAN" (RealSR, BSRGAN), and Real-ESRGAN
- Models: Community ESRGAN | ESRGAN+ | BSRGAN | RealSR | Real-ESRGAN
- Real-ESRGAN Compact (SRVGGNet) | Models
- Swift-SRGAN | Models
- SwinIR | Models
- Swin2SR | Models
- HAT | Models
- Omni-SR | Models
- SRFormer (+) | Models
- DAT | Models
- FeMaSR (+) | Models
- GRL | Models
- DITN | Models
- MM-RealSR | Models
- SPAN | Models
- Real-CUGAN | Models, Pro Models
- CRAFT | Models
- SAFMN | Models, JPEG model
- RGT | RGT Models, RGT-S Models
- DCTLSA | Models
- ATD | Models
- AdaCode | Models
- DRCT
- PLKSR and RealPLKSR | Models
- SeemoRe | Models
- MoSR | Models
- MoESR | Models
- RCAN | Models
- GFPGAN | 1.2, 1.3, 1.4
- RestoreFormer | Model
- CodeFormer (+) | Model
- SCUNet | GAN Model | PSNR Model
- Uformer | Denoise SIDD Model | Deblur GoPro Model
- KBNet | Models
- NAFNet | Models
- Restormer (+) | Models
- FFTformer | Models
- M3SNet (+) | Models
- MPRNet (+) | Deblurring, Deraining, Denoising
- MIRNet2 (+) | Models (SR not supported)
- DnCNN, FDnCNN | Models
- DRUNet | Models
- IPT | Models
(All architectures marked with a + are only part of spandrel_extra_arches.)
Use .safetensors files for guaranteed security.
As you may know, loading .pth files poses a security risk due to python's pickle module being inherently unsafe and vulnerable to arbitrary code execution (ACE). To mitigate this, Spandrel only allows deserializing certain types of data. This helps to improve security, but it still doesn't fully solve the issue of ACE.
Here are some cool projects that use Spandrel:
This repo is bounded by the MIT license. However, the code of implemented architectures (everything inside an __arch/ directory) is bound by their original respective licenses (which are included in their respective __arch/ directories).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for spandrel
Similar Open Source Tools
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.
lm.rs
lm.rs is a tool that allows users to run inference on Language Models locally on the CPU using Rust. It supports LLama3.2 1B and 3B models, with a WebUI also available. The tool provides benchmarks and download links for models and tokenizers, with recommendations for quantization options. Users can convert models from Google/Meta on huggingface using provided scripts. The tool can be compiled with cargo and run with various arguments for model weights, tokenizer, temperature, and more. Additionally, a backend for the WebUI can be compiled and run to connect via the web interface.
model2vec
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance. It outperforms other static embedding models like GLoVe and BPEmb, is lightweight with only `numpy` as a major dependency, offers fast inference, dataset-free distillation, and is integrated into Sentence Transformers, txtai, and Chonkie. Model2Vec creates powerful models by passing a vocabulary through a sentence transformer model, reducing dimensionality using PCA, and weighting embeddings using zipf weighting. Users can distill their own models or use pre-trained models from the HuggingFace hub. Evaluation can be done using the provided evaluation package. Model2Vec is licensed under MIT.

PowerInfer
PowerInfer is a high-speed Large Language Model (LLM) inference engine designed for local deployment on consumer-grade hardware, leveraging activation locality to optimize efficiency. It features a locality-centric design, hybrid CPU/GPU utilization, easy integration with popular ReLU-sparse models, and support for various platforms. PowerInfer achieves high speed with lower resource demands and is flexible for easy deployment and compatibility with existing models like Falcon-40B, Llama2 family, ProSparse Llama2 family, and Bamboo-7B.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord
thinc
Thinc is a lightweight deep learning library that offers an elegant, type-checked, functional-programming API for composing models, with support for layers defined in other frameworks such as PyTorch, TensorFlow and MXNet. You can use Thinc as an interface layer, a standalone toolkit or a flexible way to develop new models.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
For similar tasks
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.

wllama
Wllama is a WebAssembly binding for llama.cpp, a high-performance and lightweight language model library. It enables you to run inference directly on the browser without the need for a backend or GPU. Wllama provides both high-level and low-level APIs, allowing you to perform various tasks such as completions, embeddings, tokenization, and more. It also supports model splitting, enabling you to load large models in parallel for faster download. With its Typescript support and pre-built npm package, Wllama is easy to integrate into your React Typescript projects.
lmstudio.js
lmstudio.js is a pre-release alpha client SDK for LM Studio, allowing users to use local LLMs in JS/TS/Node. It is currently undergoing rapid development with breaking changes expected. Users can follow LM Studio's announcements on Twitter and Discord. The SDK provides API usage for loading models, predicting text, setting up the local LLM server, and more. It supports features like custom loading progress tracking, model unloading, structured output prediction, and cancellation of predictions. Users can interact with LM Studio through the CLI tool 'lms' and perform tasks like text completion, conversation, and getting prediction statistics.
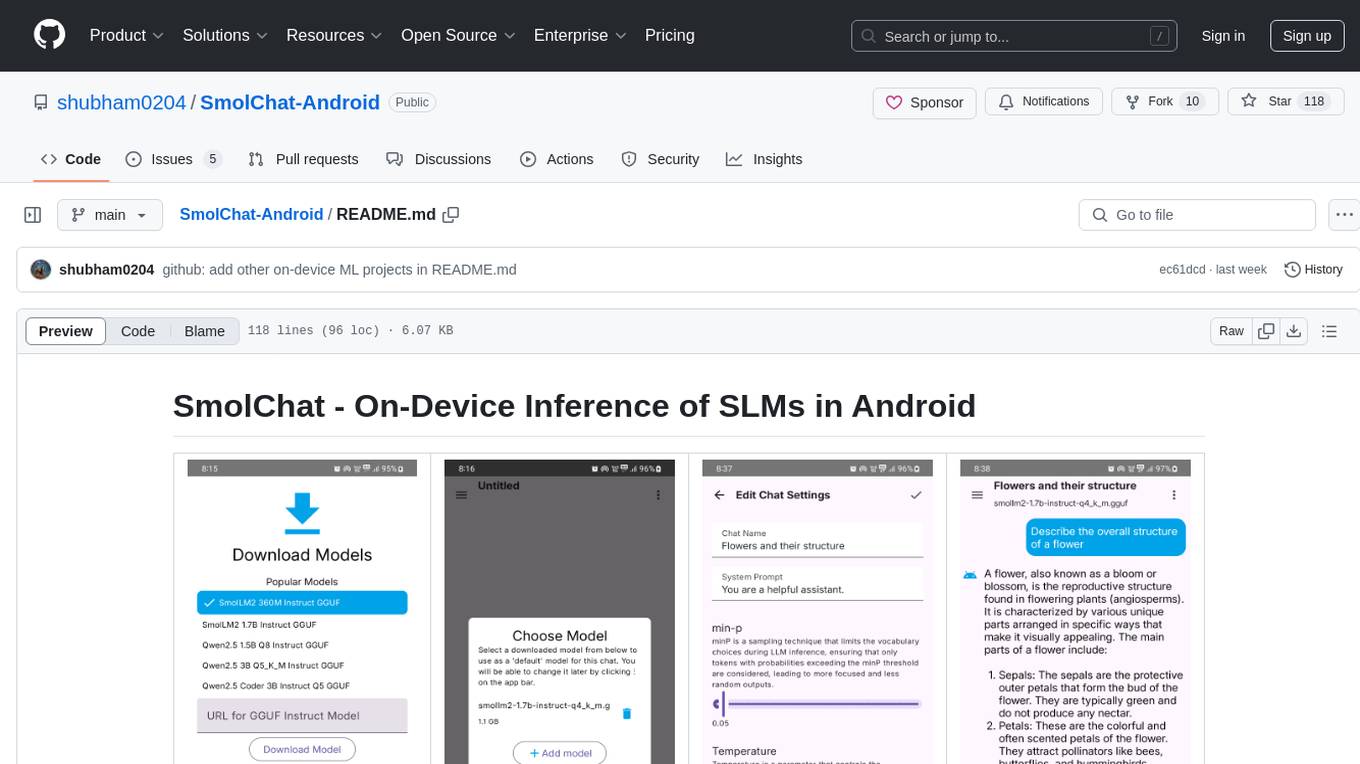
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.
Oxide-Lab
Oxide Lab is a private AI chat desktop application with local LLM support, allowing users to run large language models locally without internet connectivity or external API services. Built with Rust and Tauri v2, it offers a fast and secure chat interface where all inference happens on the user's machine, ensuring data privacy and security. The application supports multiple architectures, model formats, and hardware accelerations, along with streaming text generation and a modern UI built with Svelte and Tailwind CSS.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.
For similar jobs
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.
manga-image-translator
Translate texts in manga/images. Some manga/images will never be translated, therefore this project is born. * Image/Manga Translator * Samples * Online Demo * Disclaimer * Installation * Pip/venv * Poetry * Additional instructions for **Windows** * Docker * Hosting the web server * Using as CLI * Setting Translation Secrets * Using with Nvidia GPU * Building locally * Usage * Batch mode (default) * Demo mode * Web Mode * Api Mode * Related Projects * Docs * Recommended Modules * Tips to improve translation quality * Options * Language Code Reference * Translators Reference * GPT Config Reference * Using Gimp for rendering * Api Documentation * Synchronous mode * Asynchronous mode * Manual translation * Next steps * Support Us * Thanks To All Our Contributors :
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.