
ai-devices
AI Device Template Featuring Whisper, TTS, Groq, Llama3, OpenAI and more
Stars: 116
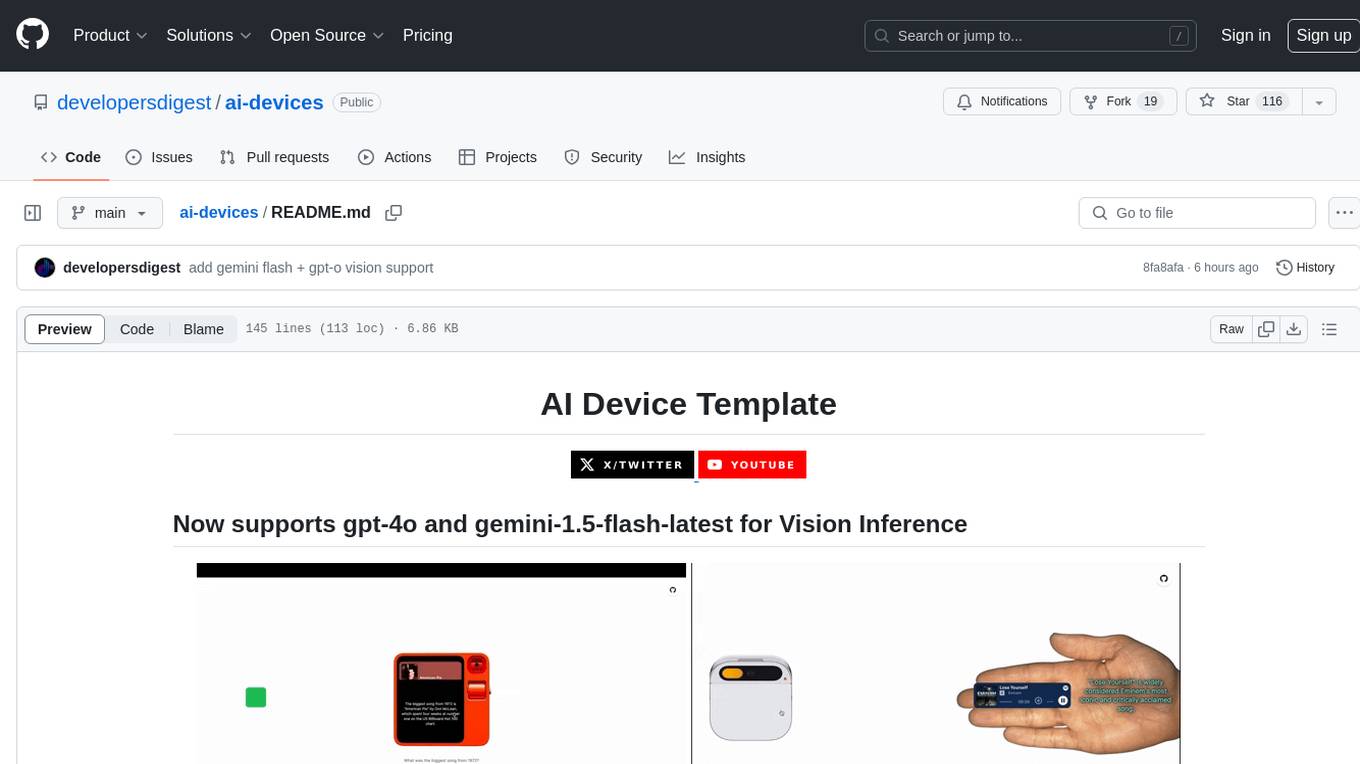
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.
README:



This project is an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. This was inspired by the recent trend of AI Devices such as the Humane AI Pin and the Rabbit R1.
- Voice input and transcription: Using Whisper models from Groq or OpenAI
- Text-to-speech output: Using OpenAI's TTS models
- Image processing: Using OpenAI's GPT-4 Vision or Fal.ai's Llava-Next models
- Function calling and conditionally rendered UI components: Using OpenAI's GPT-3.5-Turbo model
- Customizable UI settings: Includes response times, settings toggle, text-to-speech toggle, internet results toggle, and photo upload toggle
- (Optional) Rate limiting: Using Upstash
- (Optional) Tracing: With Langchain's LangSmith for function execution
git clone https://github.com/developersdigest/ai-devices.gitnpm install
# or
bun installTo use this AI-powered voice assistant, you need to provide the necessary API keys for the selected AI models and services.
- Groq API Key For Llama + Whisper
- OpenAI API Key for TTS and Vision + Whisper
- Serper API Key for Internet Results
- Langchain Tracing for function execution tracing
- Upstash Redis for IP-based rate limiting
- Spotify for Spotify API interactions
- Fal.AI (Lllava Image Model) Alternative vision model to GPT-4-Vision
Replace 'API_KEY_GOES_HERE' with your actual API keys for each service.
npm run dev
# or
bun devAccess the application at http://localhost:3000 or through the provided URL.
Modify app/config.tsx to adjust settings and configurations for the AI-powered voice assistant. Here’s an overview of the available options:
export const config = {
// Inference settings
inferenceModelProvider: 'groq', // 'groq' or 'openai'
inferenceModel: 'llama3-8b-8192', // Groq: 'llama3-70b-8192' or 'llama3-8b-8192'.. OpenAI: 'gpt-4-turbo etc
// BELOW OPTIONAL are some options for the app to use
// Whisper settings
whisperModelProvider: 'openai', // 'groq' or 'openai'
whisperModel: 'whisper-1', // Groq: 'whisper-large-v3' OpenAI: 'whisper-1'
// TTS settings
ttsModelProvider: 'openai', // only openai supported for now...
ttsModel: 'tts-1', // only openai supported for now...s
ttsvoice: 'alloy', // only openai supported for now... [alloy, echo, fable, onyx, nova, and shimmer]
// OPTIONAL:Vision settings
visionModelProvider: 'google', // 'openai' or 'fal.ai' or 'google'
visionModel: 'gemini-1.5-flash-latest', // OpenAI: 'gpt-4o' or Fal.ai: 'llava-next' or Google: 'gemini-1.5-flash-latest'
// Function calling + conditionally rendered UI
functionCallingModelProvider: 'openai', // 'openai' current only
functionCallingModel: 'gpt-3.5-turbo', // OpenAI: 'gpt-3-5-turbo'
// UI settings
enableResponseTimes: false, // Display response times for each message
enableSettingsUIToggle: true, // Display the settings UI toggle
enableTextToSpeechUIToggle: true, // Display the text to speech UI toggle
enableInternetResultsUIToggle: true, // Display the internet results UI toggle
enableUsePhotUIToggle: true, // Display the use photo UI toggle
enabledRabbitMode: true, // Enable the rabbit mode UI toggle
enabledLudicrousMode: true, // Enable the ludicrous mode UI toggle
useAttributionComponent: true, // Use the attribution component to display the attribution of the AI models/services used
// Rate limiting settings
useRateLimiting: false, // Use Upstash rate limiting to limit the number of requests per user
// Tracing with Langchain
useLangSmith: true, // Use LangSmith by Langchain to trace the execution of the functions in the config.tsx set to true to use.
};Contributions are welcome! If you find any issues or have suggestions for improvements, please open an issue or submit a pull request.
I'm the developer behind Developers Digest. If you find my work helpful or enjoy what I do, consider supporting me. Here are a few ways you can do that:
- Patreon: Support me on Patreon at patreon.com/DevelopersDigest
- Buy Me A Coffee: You can buy me a coffee at buymeacoffee.com/developersdigest
- Website: Check out my website at developersdigest.tech
- Github: Follow me on GitHub at github.com/developersdigest
- Twitter: Follow me on Twitter at twitter.com/dev__digest
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-devices
Similar Open Source Tools
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.
effective_llm_alignment
This is a super customizable, concise, user-friendly, and efficient toolkit for training and aligning LLMs. It provides support for various methods such as SFT, Distillation, DPO, ORPO, CPO, SimPO, SMPO, Non-pair Reward Modeling, Special prompts basket format, Rejection Sampling, Scoring using RM, Effective FAISS Map-Reduce Deduplication, LLM scoring using RM, NER, CLIP, Classification, and STS. The toolkit offers key libraries like PyTorch, Transformers, TRL, Accelerate, FSDP, DeepSpeed, and tools for result logging with wandb or clearml. It allows mixing datasets, generation and logging in wandb/clearml, vLLM batched generation, and aligns models using the SMPO method.
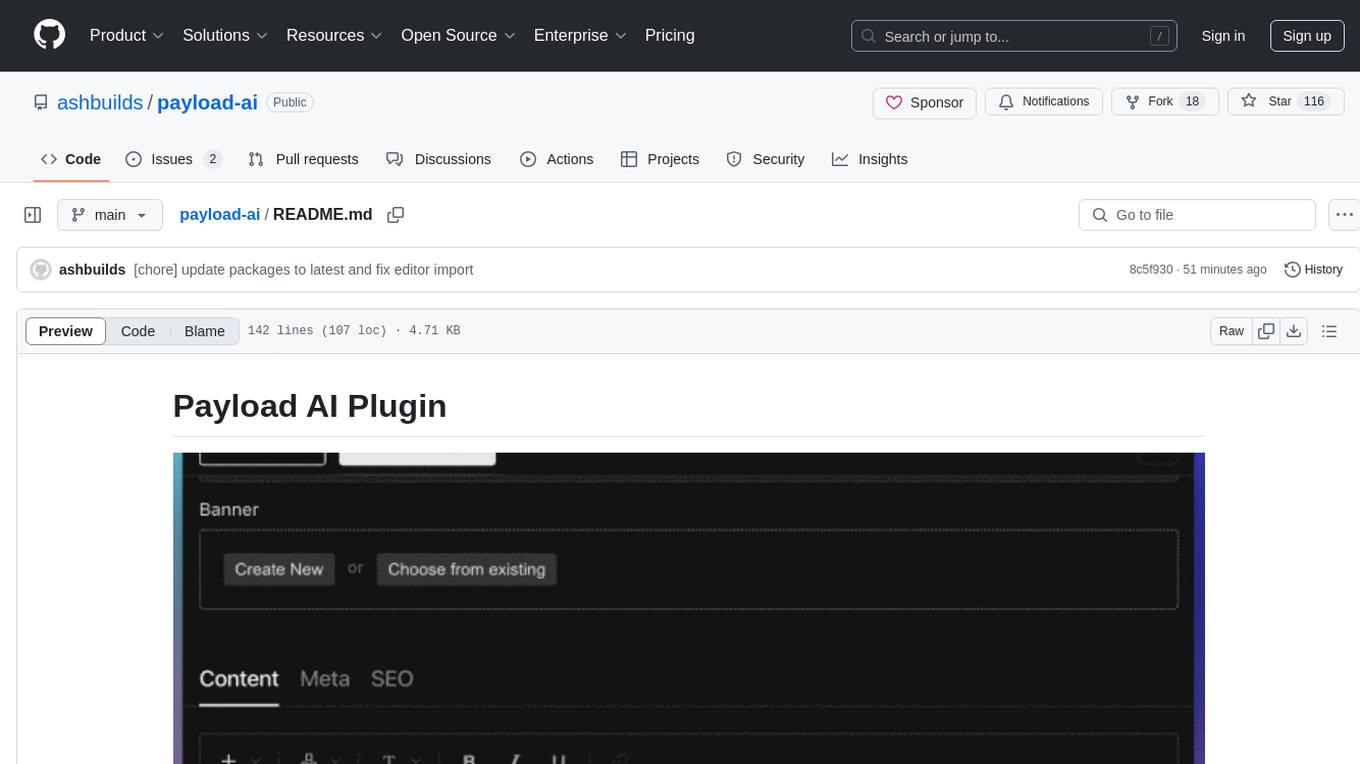
payload-ai
The Payload AI Plugin is an advanced extension that integrates modern AI capabilities into your Payload CMS, streamlining content creation and management. It offers features like text generation, voice and image generation, field-level prompt customization, prompt editor, document analyzer, fact checking, automated content workflows, internationalization support, editor AI suggestions, and AI chat support. Users can personalize and configure the plugin by setting environment variables. The plugin is actively developed and tested with Payload version v3.2.1, with regular updates expected.
sre
SmythOS is an operating system designed for building, deploying, and managing intelligent AI agents at scale. It provides a unified SDK and resource abstraction layer for various AI services, making it easy to scale and flexible. With an agent-first design, developer-friendly SDK, modular architecture, and enterprise security features, SmythOS offers a robust foundation for AI workloads. The system is built with a philosophy inspired by traditional operating system kernels, ensuring autonomy, control, and security for AI agents. SmythOS aims to make shipping production-ready AI agents accessible and open for everyone in the coming Internet of Agents era.
sd-webui-agent-scheduler
AgentScheduler is an Automatic/Vladmandic Stable Diffusion Web UI extension designed to enhance image generation workflows. It allows users to enqueue prompts, settings, and controlnets, manage queued tasks, prioritize, pause, resume, and delete tasks, view generation results, and more. The extension offers hidden features like queuing checkpoints, editing queued tasks, and custom checkpoint selection. Users can access the functionality through HTTP APIs and API callbacks. Troubleshooting steps are provided for common errors. The extension is compatible with latest versions of A1111 and Vladmandic. It is licensed under Apache License 2.0.
Cerebr
Cerebr is an intelligent AI assistant browser extension designed to enhance work efficiency and learning experience. It integrates powerful AI capabilities from various sources to provide features such as smart sidebar, multiple API support, cross-browser API configuration synchronization, comprehensive Q&A support, elegant rendering, real-time response, theme switching, and more. With a minimalist design and focus on delivering a seamless, distraction-free browsing experience, Cerebr aims to be your second brain for deep reading and understanding.
agents-starter
A starter template for building AI-powered chat agents using Cloudflare's Agent platform, powered by agents-sdk. It provides a foundation for creating interactive chat experiences with AI, complete with a modern UI and tool integration capabilities. Features include interactive chat interface with AI, built-in tool system with human-in-the-loop confirmation, advanced task scheduling, dark/light theme support, real-time streaming responses, state management, and chat history. Prerequisites include a Cloudflare account and OpenAI API key. The project structure includes components for chat UI implementation, chat agent logic, tool definitions, and helper functions. Customization guide covers adding new tools, modifying the UI, and example use cases for customer support, development assistant, data analysis assistant, personal productivity assistant, and scheduling assistant.

py-llm-core
PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.
Google_GenerativeAI
Google GenerativeAI (Gemini) is an unofficial C# .Net SDK based on REST APIs for accessing Google Gemini models. It offers a complete rewrite of the previous SDK with improved performance, flexibility, and ease of use. The SDK seamlessly integrates with LangChain.net, providing easy methods for JSON-based interactions and function calling with Google Gemini models. It includes features like enhanced JSON mode handling, function calling with code generator, multi-modal functionality, Vertex AI support, multimodal live API, image generation and captioning, retrieval-augmented generation with Vertex RAG Engine and Google AQA, easy JSON handling, Gemini tools and function calling, multimodal live API, and more.
laravel-ai-translator
Laravel AI Translator is a powerful tool designed to streamline the localization process in Laravel projects. It automates the task of translating strings across multiple languages using advanced AI models like GPT-4 and Claude. The tool supports custom language styles, preserves variables and nested structures, and ensures consistent tone and style across translations. It integrates seamlessly with Laravel projects, making internationalization easier and more efficient. Users can customize translation rules, handle large language files efficiently, and validate translations for accuracy. The tool offers contextual understanding, linguistic precision, variable handling, smart length adaptation, and tone consistency for intelligent translations.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
llmcord
llmcord is a Discord bot that transforms Discord into a collaborative LLM frontend, allowing users to interact with various LLM models. It features a reply-based chat system that enables branching conversations, supports remote and local LLM models, allows image and text file attachments, offers customizable personality settings, and provides streamed responses. The bot is fully asynchronous, efficient in managing message data, and offers hot reloading config. With just one Python file and around 200 lines of code, llmcord provides a seamless experience for engaging with LLMs on Discord.

arbigent
Arbigent (Arbiter-Agent) is an AI agent testing framework designed to make AI agent testing practical for modern applications. It addresses challenges faced by traditional UI testing frameworks and AI agents by breaking down complex tasks into smaller, dependent scenarios. The framework is customizable for various AI providers, operating systems, and form factors, empowering users with extensive customization capabilities. Arbigent offers an intuitive UI for scenario creation and a powerful code interface for seamless test execution. It supports multiple form factors, optimizes UI for AI interaction, and is cost-effective by utilizing models like GPT-4o mini. With a flexible code interface and open-source nature, Arbigent aims to revolutionize AI agent testing in modern applications.
OrChat
OrChat is a powerful CLI tool for chatting with AI models through OpenRouter. It offers features like universal model access, interactive chat with real-time streaming responses, rich markdown rendering, agentic shell access, security gating, performance analytics, command auto-completion, pricing display, auto-update system, multi-line input support, conversation management, auto-summarization, session persistence, web scraping, file and media support, smart thinking mode, conversation export, customizable themes, interactive input features, and more.
nanocoder
Nanocoder is a local-first CLI coding agent that supports multiple AI providers with tool support for file operations and command execution. It focuses on privacy and control, allowing users to code locally with AI tools. The tool is designed to bring the power of agentic coding tools to local models or controlled APIs like OpenRouter, promoting community-led development and inclusive collaboration in the AI coding space.
For similar tasks
gorilla
Gorilla is a tool that enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, you can use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. Gorilla also releases APIBench, the largest collection of APIs, curated and easy to be trained on!

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
awesome-llm-json
This repository is an awesome list dedicated to resources for using Large Language Models (LLMs) to generate JSON or other structured outputs. It includes terminology explanations, hosted and local models, Python libraries, blog articles, videos, Jupyter notebooks, and leaderboards related to LLMs and JSON generation. The repository covers various aspects such as function calling, JSON mode, guided generation, and tool usage with different providers and models.
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.

ragtacts
Ragtacts is a Clojure library that allows users to easily interact with Large Language Models (LLMs) such as OpenAI's GPT-4. Users can ask questions to LLMs, create question templates, call Clojure functions in natural language, and utilize vector databases for more accurate answers. Ragtacts also supports RAG (Retrieval-Augmented Generation) method for enhancing LLM output by incorporating external data. Users can use Ragtacts as a CLI tool, API server, or through a RAG Playground for interactive querying.

DelphiOpenAI
Delphi OpenAI API is an unofficial library providing Delphi implementation over OpenAI public API. It allows users to access various models, make completions, chat conversations, generate images, and call functions using OpenAI service. The library aims to facilitate tasks such as content generation, semantic search, and classification through AI models. Users can fine-tune models, work with natural language processing, and apply reinforcement learning methods for diverse applications.
token.js
Token.js is a TypeScript SDK that integrates with over 200 LLMs from 10 providers using OpenAI's format. It allows users to call LLMs, supports tools, JSON outputs, image inputs, and streaming, all running on the client side without the need for a proxy server. The tool is free and open source under the MIT license.
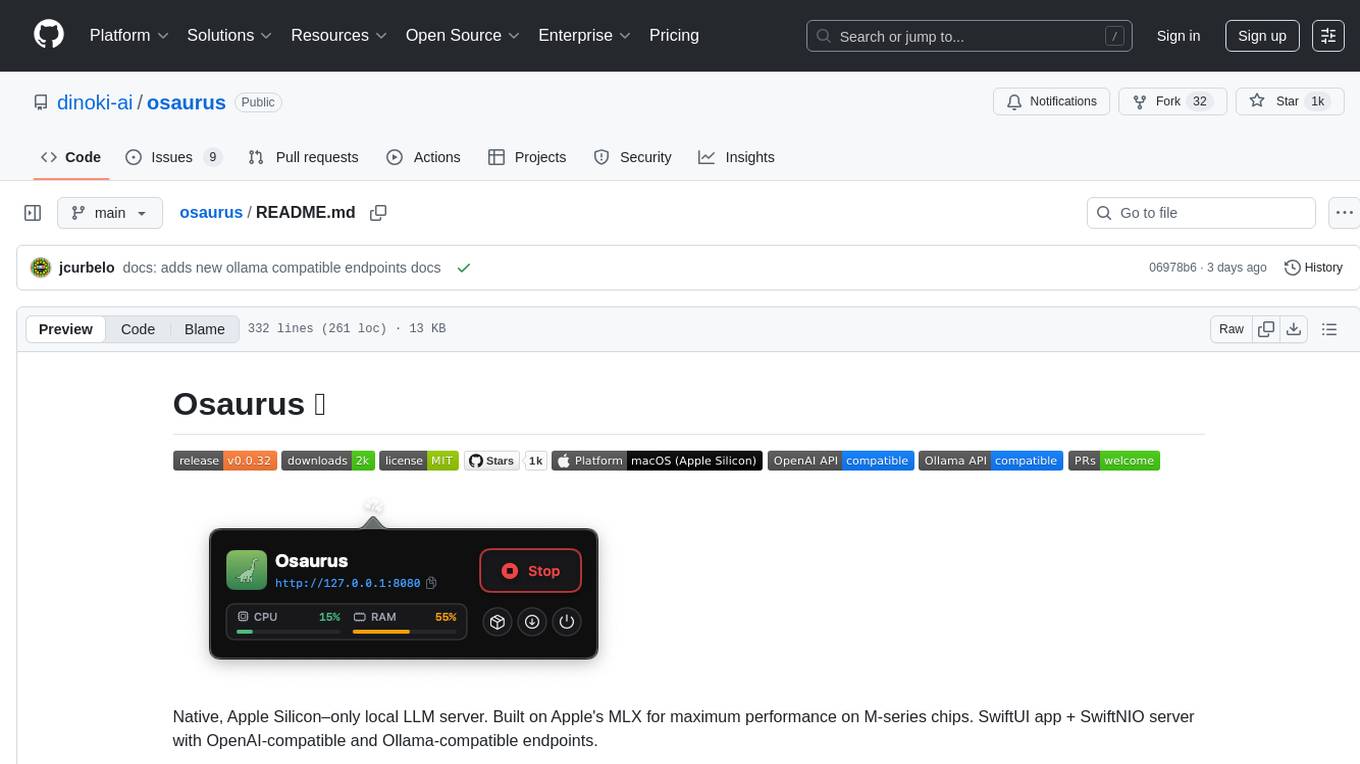
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.