
gorilla
Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls)
Stars: 12445
Gorilla is a tool that enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, you can use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. Gorilla also releases APIBench, the largest collection of APIs, curated and easy to be trained on!
README:

📢 Check out our detailed Berkeley Function Calling Leaderboard changelog (Last updated:
) for the latest dataset / model updates to the Berkeley Function Calling Leaderboard!

-
🤖 [07/17/2025] Announcing BFCL V4 Agentic! As function-calling forms the bedrock of Agentic systems, BFCL V4 Agentic benchmark focuses on tool-calling in real-world agentic settings, featuring web search with multi-hop reasoning and error recovery, agent memory management, and format sensitivity evaluation. [Web-search Blog] [Memory Blog] [Format Sensitivity Blog] [PR] [Tweet]
-
🎯 [10/04/2024] Introducing the Agent Arena by Gorilla X LMSYS Chatbot Arena! Compare different agents in tasks like search, finance, RAG, and beyond. Explore which models and tools work best for specific tasks through our novel ranking system and community-driven prompt hub. [Blog] [Arena] [Leaderboard] [Dataset] [Tweet]
-
📣 [09/21/2024] Announcing BFCL V3 - Evaluating multi-turn and multi-step function calling capabilities! New state-based evaluation system tests models on handling complex workflows, sequential functions, and service states. [Blog] [Leaderboard] [Code] [Tweet]
-
🚀 [08/20/2024] Released BFCL V2 • Live! The Berkeley Function-Calling Leaderboard now features enterprise-contributed data and real-world scenarios. [Blog] [Live Leaderboard] [V2 Categories Leaderboard] [Tweet]
-
⚡️ [04/12/2024] Excited to release GoEx - a runtime for LLM-generated actions like code, API calls, and more. Featuring "post-facto validation" for assessing LLM actions after execution, "undo" and "damage confinement" abstractions to manage unintended actions & risks. This paves the way for fully autonomous LLM agents, enhancing interaction between apps & services with human-out-of-loop. [Blog] [Code] [Paper] [Tweet]
-
⏰ [04/01/2024] Introducing cost and latency metrics into Berkeley function calling leaderboard!
-
🚀 [03/15/2024] RAFT: Adapting Language Model to Domain Specific RAG is live! [MSFT-Meta blog] [Berkeley Blog]
-
🏆 [02/26/2024] Berkeley Function Calling Leaderboard is live!
-
🎯 [02/25/2024] OpenFunctions v2 sets new SoTA for open-source LLMs!
-
🔥 [11/16/2023] Excited to release Gorilla OpenFunctions
-
💻 [06/29/2023] Released gorilla-cli, LLMs for your CLI!
-
🟢 [06/06/2023] Released Commercially usable, Apache 2.0 licensed Gorilla models
-
🚀 [05/30/2023] Provided the CLI interface to chat with Gorilla!
-
🚀 [05/28/2023] Released Torch Hub and TensorFlow Hub Models!
-
🚀 [05/27/2023] Released the first Gorilla model!
or 🤗!
-
🔥 [05/27/2023] We released the APIZoo contribution guide for community API contributions!
-
🔥 [05/25/2023] We release the APIBench dataset and the evaluation code of Gorilla!
Gorilla enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke.
With Gorilla, we are the first to demonstrate how to use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. This repository contains inference code for running Gorilla finetuned models, evaluation code for reproducing results from our paper, and APIBench - the largest collection of APIs, curated and easy to be trained on!
Since our initial release, we've served ~500k requests and witnessed incredible adoption by developers worldwide. The project has expanded to include tools, evaluations, leaderboard, end-to-end finetuning recipes, infrastructure components, and the Gorilla API Store:
| Project | Type | Description (click to expand) |
|---|---|---|
| Gorilla Paper | 🤖 Model 📝 Fine-tuning 📚 Dataset 📊 Evaluation 🔧 Infra |
Large Language Model Connected with Massive APIs• Novel finetuning approach for API invocation• Evaluation on 1,600+ APIs (APIBench) • Retrieval-augmented training for test-time adaptation |
| Gorilla OpenFunctions-V2 | 🤖 Model | Drop-in alternative for function calling, supporting multiple complex data types and parallel execution• Multiple & parallel function execution with OpenAI-compatible endpoints• Native support for Python, Java, JavaScript, and REST APIs with expanded data types • Function relevance detection to reduce hallucinations • Enhanced RESTful API formatting capabilities • State-of-the-art performance among open-source models |
| Berkeley Function Calling Leaderboard (BFCL) | 📊 Evaluation 🏆 Leaderboard 🔧 Function Calling Infra 📚 Dataset |
Comprehensive evaluation of function-calling capabilities• V1: Expert-curated dataset for evaluating single-turn function calling• V2: Enterprise-contributed data for real-world scenarios • V3: Multi-turn & multi-step function calling evaluation • Cost and latency metrics for all models • Interactive API explorer for testing • Community-driven benchmarking platform |
| Agent Arena | 📊 Evaluation 🏆 Leaderboard |
Compare LLM agents across models, tools, and frameworks• Head-to-head agent comparisons with ELO rating system• Framework compatibility testing (LangChain, AutoGPT) • Community-driven evaluation platform • Real-world task performance metrics |
| Gorilla Execution Engine (GoEx) | 🔧 Infra | Runtime for executing LLM-generated actions with safety guarantees• Post-facto validation for verifying LLM actions after execution• Undo capabilities and damage confinement for risk mitigation • OAuth2 and API key authentication for multiple services • Support for RESTful APIs, databases, and filesystem operations • Docker-based sandboxed execution environment |
| Retrieval-Augmented Fine-tuning (RAFT) | 📝 Fine-tuning 🤖 Model |
Fine-tuning LLMs for robust domain-specific retrieval• Novel fine-tuning recipe for domain-specific RAG• Chain-of-thought answers with direct document quotes • Training with oracle and distractor documents • Improved performance on PubMed, HotpotQA, and Gorilla benchmarks • Efficient adaptation of smaller models for domain QA |
| Gorilla CLI | 🤖 Model 🔧 Local CLI Infra |
LLMs for your command-line interface• User-friendly CLI tool supporting ~1500 APIs (Kubernetes, AWS, GCP, etc.)• Natural language command generation with multi-LLM fusion • Privacy-focused with explicit execution approval • Command history and interactive selection interface |
| Gorilla API Zoo | 📚 Dataset | A community-maintained repository of up-to-date API documentation• Centralized, searchable index of APIs across domains• Structured documentation format with arguments, versioning, and examples • Community-driven updates to keep pace with API changes • Rich data source for model training and fine-tuning • Enables retrieval-augmented training and inference • Reduces hallucination through up-to-date documentation |
Try Gorilla in your browser:
- 🚀 Gorilla Colab Demo: Try the base Gorilla model
- 🌐 Gorilla Gradio Demo: Interactive web interface
- 🔥 OpenFunctions Colab Demo: Try the latest OpenFunctions model
- 🎯 OpenFunctions Website Demo: Experiment with function calling
- 📊 Berkeley Function Calling Leaderboard: Compare function calling capabilities
- Gorilla CLI - Fastest way to get started
pip install gorilla-cli
gorilla generate 100 random characters into a file called test.txtLearn more about Gorilla CLI →
- Run Gorilla Locally
git clone https://github.com/ShishirPatil/gorilla.git
cd gorilla/inferenceDetailed local setup instructions →
- Use OpenFunctions
import openai
openai.api_key = "EMPTY"
openai.api_base = "http://luigi.millennium.berkeley.edu:8000/v1"
# Define your functions
functions = [{
"name": "get_current_weather",
"description": "Get weather in a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}]
# Make API call
completion = openai.ChatCompletion.create(
model="gorilla-openfunctions-v2",
messages=[{"role": "user", "content": "What's the weather in San Francisco?"}],
functions=functions
)-
📊 Evaluation & Benchmarking
- Berkeley Function Calling Leaderboard: Compare function calling capabilities
- Agent Arena: Evaluate agent workflows
- Gorilla Paper Evaluation Scripts: Run your own evaluations
-
🛠️ Development Tools
- I would like to use Gorilla commercially. Is there going to be an Apache 2.0 licensed version?
Yes! We now have models that you can use commercially without any obligations.
- Can we use Gorilla with other tools like Langchain etc?
Absolutely! You've highlighted a great aspect of our tools. Gorilla is an end-to-end model, specifically tailored to serve correct API calls (tools) without requiring any additional coding. It's designed to work as part of a wider ecosystem and can be flexibly integrated within agentic frameworks and other tools.
Langchain, is a versatile developer tool. Its "agents" can efficiently swap in any LLM, Gorilla included, making it a highly adaptable solution for various needs.
The beauty of these tools truly shines when they collaborate, complementing each other's strengths and capabilities to create an even more powerful and comprehensive solution. This is where your contribution can make a difference. We enthusiastically welcome any inputs to further refine and enhance these tools.
Check out our blog on How to Use Gorilla: A Step-by-Step Walkthrough to see all the different ways you can integrate Gorilla in your projects.
In the immediate future, we plan to release the following:
- [ ] Multimodal function-calling leaderboard
- [ ] Agentic function-calling leaderboard
- [ ] New batch of user contributed live function calling evals.
- [ ] BFCL metrics to evaluate contamination
- [ ] Openfunctions-v3 model to support more languages and multi-turn capability
- [x] Agent Arena to compare LLM agents across models, tools, and frameworks [10/04/2024]
- [x] Multi-turn and multi-step function calling evaluation [09/21/2024]
- [x] User contributed Live Function Calling Leaderboard [08/20/2024]
- [x] BFCL systems metrics including cost and latency [04/01/2024]
- [x] Gorilla Execution Engine (GoEx) - Runtime for executing LLM-generated actions with safety guarantees [04/12/2024]
- [x] Berkeley Function Calling leaderboard (BFCL) for evaluating tool-calling/function-calling models [02/26/2024]
- [x] Openfunctions-v2 with more languages (Java, JS, Python), relevance detection [02/26/2024]
- [x] API Zoo Index for easy access to all APIs [02/16/2024]
- [x] Openfunctions-v1, Apache 2.0, with parallel and multiple function calling [11/16/2023]
- [x] Openfunctions-v0, Apache 2.0 function calling model [11/16/2023]
- [X] Release a commercially usable, Apache 2.0 licensed Gorilla model [06/05/2023]
- [X] Release weights for all APIs from APIBench [05/28/2023]
- [X] Run Gorilla LLM locally [05/28/2023]
- [X] Release weights for HF model APIs [05/27/2023]
- [X] Hosted Gorilla LLM chat for HF model APIs [05/27/2023]
- [X] Opening up the APIZoo for contributions from community
- [X] Dataset and Eval Code
Gorilla is Apache 2.0 licensed, making it suitable for both academic and commercial use.
- 💬 Join our Discord Community
- 🐦 Follow us on X
@article{patil2023gorilla,
title={Gorilla: Large Language Model Connected with Massive APIs},
author={Shishir G. Patil and Tianjun Zhang and Xin Wang and Joseph E. Gonzalez},
year={2023},
journal={arXiv preprint arXiv:2305.15334},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for gorilla
Similar Open Source Tools
gorilla
Gorilla is a tool that enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, you can use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. Gorilla also releases APIBench, the largest collection of APIs, curated and easy to be trained on!

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
fastapi_mcp
FastAPI-MCP is a zero-configuration tool that automatically exposes FastAPI endpoints as Model Context Protocol (MCP) tools. It allows for direct integration with FastAPI apps, automatic discovery and conversion of endpoints to MCP tools, preservation of request and response schemas, documentation preservation similar to Swagger, and the ability to extend with custom MCP tools. Users can easily add an MCP server to their FastAPI application and customize the server creation and configuration. The tool supports connecting to the MCP server using SSE or mcp-proxy stdio for different MCP clients. FastAPI-MCP is developed and maintained by Tadata Inc.
mcp-context-forge
MCP Context Forge is a powerful tool for generating context-aware data for machine learning models. It provides functionalities to create diverse datasets with contextual information, enhancing the performance of AI algorithms. The tool supports various data formats and allows users to customize the context generation process easily. With MCP Context Forge, users can efficiently prepare training data for tasks requiring contextual understanding, such as sentiment analysis, recommendation systems, and natural language processing.
hujiang_dictionary
Hujiang Dictionary is a tool that provides translation services between Japanese, Chinese, and English. It supports various translation modes such as Japanese to Chinese, Chinese to Japanese, English to Japanese, and more. The tool utilizes cloud services like Telegram, Lambda, and Cloudflare Workers for different deployment options. Users can interact with the tool via a command-line interface (CLI) to perform translations and access online resources like weblio and Google Translate. Additionally, the tool offers a Telegram bot for users to access translation services conveniently. The tool also supports setting up and managing databases for storing translation data.

SpecForge
SpecForge is a powerful tool for generating API specifications from code. It helps developers to easily create and maintain accurate API documentation by extracting information directly from the codebase. With SpecForge, users can streamline the process of documenting APIs, ensuring consistency and reducing manual effort. The tool supports various programming languages and frameworks, making it versatile and adaptable to different development environments. By automating the generation of API specifications, SpecForge enhances collaboration between developers and stakeholders, improving overall project efficiency and quality.

cellm
Cellm is an Excel extension that allows users to leverage Large Language Models (LLMs) like ChatGPT within cell formulas. It enables users to extract AI responses to text ranges, making it useful for automating repetitive tasks that involve data processing and analysis. Cellm supports various models from Anthropic, Mistral, OpenAI, and Google, as well as locally hosted models via Llamafiles, Ollama, or vLLM. The tool is designed to simplify the integration of AI capabilities into Excel for tasks such as text classification, data cleaning, content summarization, entity extraction, and more.
baibot
Baibot is a versatile chatbot framework designed to simplify the process of creating and deploying chatbots. It provides a user-friendly interface for building custom chatbots with various functionalities such as natural language processing, conversation flow management, and integration with external APIs. Baibot is highly customizable and can be easily extended to suit different use cases and industries. With Baibot, developers can quickly create intelligent chatbots that can interact with users in a seamless and engaging manner, enhancing user experience and automating customer support processes.
arcade-ai
Arcade AI is a developer-focused tooling and API platform designed to enhance the capabilities of LLM applications and agents. It simplifies the process of connecting agentic applications with user data and services, allowing developers to concentrate on building their applications. The platform offers prebuilt toolkits for interacting with various services, supports multiple authentication providers, and provides access to different language models. Users can also create custom toolkits and evaluate their tools using Arcade AI. Contributions are welcome, and self-hosting is possible with the provided documentation.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
aiounifi
Aiounifi is a Python library that provides a simple interface for interacting with the Unifi Controller API. It allows users to easily manage their Unifi network devices, such as access points, switches, and gateways, through automated scripts or applications. With Aiounifi, users can retrieve device information, perform configuration changes, monitor network performance, and more, all through a convenient and efficient API wrapper. This library simplifies the process of integrating Unifi network management into custom solutions, making it ideal for network administrators, developers, and enthusiasts looking to automate and streamline their network operations.
atomic-agents
The Atomic Agents framework is a modular and extensible tool designed for creating powerful applications. It leverages Pydantic for data validation and serialization. The framework follows the principles of Atomic Design, providing small and single-purpose components that can be combined. It integrates with Instructor for AI agent architecture and supports various APIs like Cohere, Anthropic, and Gemini. The tool includes documentation, examples, and testing features to ensure smooth development and usage.
hayhooks
Hayhooks is a tool that simplifies the deployment and serving of Haystack pipelines as REST APIs. It allows users to wrap their pipelines with custom logic and expose them via HTTP endpoints, including OpenAI-compatible chat completion endpoints. With Hayhooks, users can easily convert their Haystack pipelines into API services with minimal boilerplate code.

chatluna
Chatluna is a machine learning model plugin that provides chat services with large language models. It is highly extensible, supports multiple output formats, and offers features like custom conversation presets, rate limiting, and context awareness. Users can deploy Chatluna under Koishi without additional configuration. The plugin supports various models/platforms like OpenAI, Azure OpenAI, Google Gemini, and more. It also provides preset customization using YAML files and allows for easy forking and development within Koishi projects. However, the project lacks web UI, HTTP server, and project documentation, inviting contributions from the community.
For similar tasks
gorilla
Gorilla is a tool that enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, you can use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. Gorilla also releases APIBench, the largest collection of APIs, curated and easy to be trained on!

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
awesome-llm-json
This repository is an awesome list dedicated to resources for using Large Language Models (LLMs) to generate JSON or other structured outputs. It includes terminology explanations, hosted and local models, Python libraries, blog articles, videos, Jupyter notebooks, and leaderboards related to LLMs and JSON generation. The repository covers various aspects such as function calling, JSON mode, guided generation, and tool usage with different providers and models.
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.

ragtacts
Ragtacts is a Clojure library that allows users to easily interact with Large Language Models (LLMs) such as OpenAI's GPT-4. Users can ask questions to LLMs, create question templates, call Clojure functions in natural language, and utilize vector databases for more accurate answers. Ragtacts also supports RAG (Retrieval-Augmented Generation) method for enhancing LLM output by incorporating external data. Users can use Ragtacts as a CLI tool, API server, or through a RAG Playground for interactive querying.

DelphiOpenAI
Delphi OpenAI API is an unofficial library providing Delphi implementation over OpenAI public API. It allows users to access various models, make completions, chat conversations, generate images, and call functions using OpenAI service. The library aims to facilitate tasks such as content generation, semantic search, and classification through AI models. Users can fine-tune models, work with natural language processing, and apply reinforcement learning methods for diverse applications.
token.js
Token.js is a TypeScript SDK that integrates with over 200 LLMs from 10 providers using OpenAI's format. It allows users to call LLMs, supports tools, JSON outputs, image inputs, and streaming, all running on the client side without the need for a proxy server. The tool is free and open source under the MIT license.
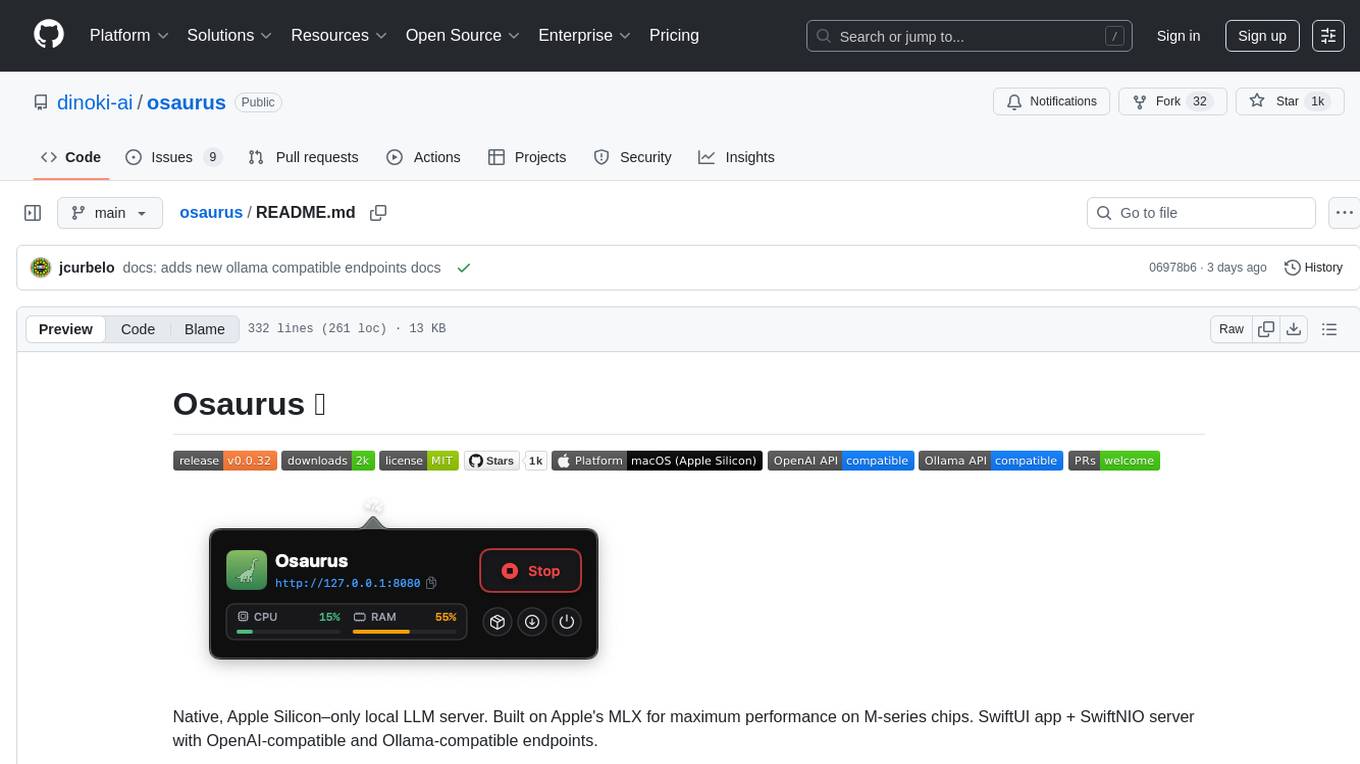
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.