
osaurus
Native, Apple Silicon–only local LLM server. Similar to Ollama, but built on Apple's MLX for maximum performance on M‑series chips. SwiftUI app + SwiftNIO server with OpenAI‑compatible endpoints.
Stars: 1293
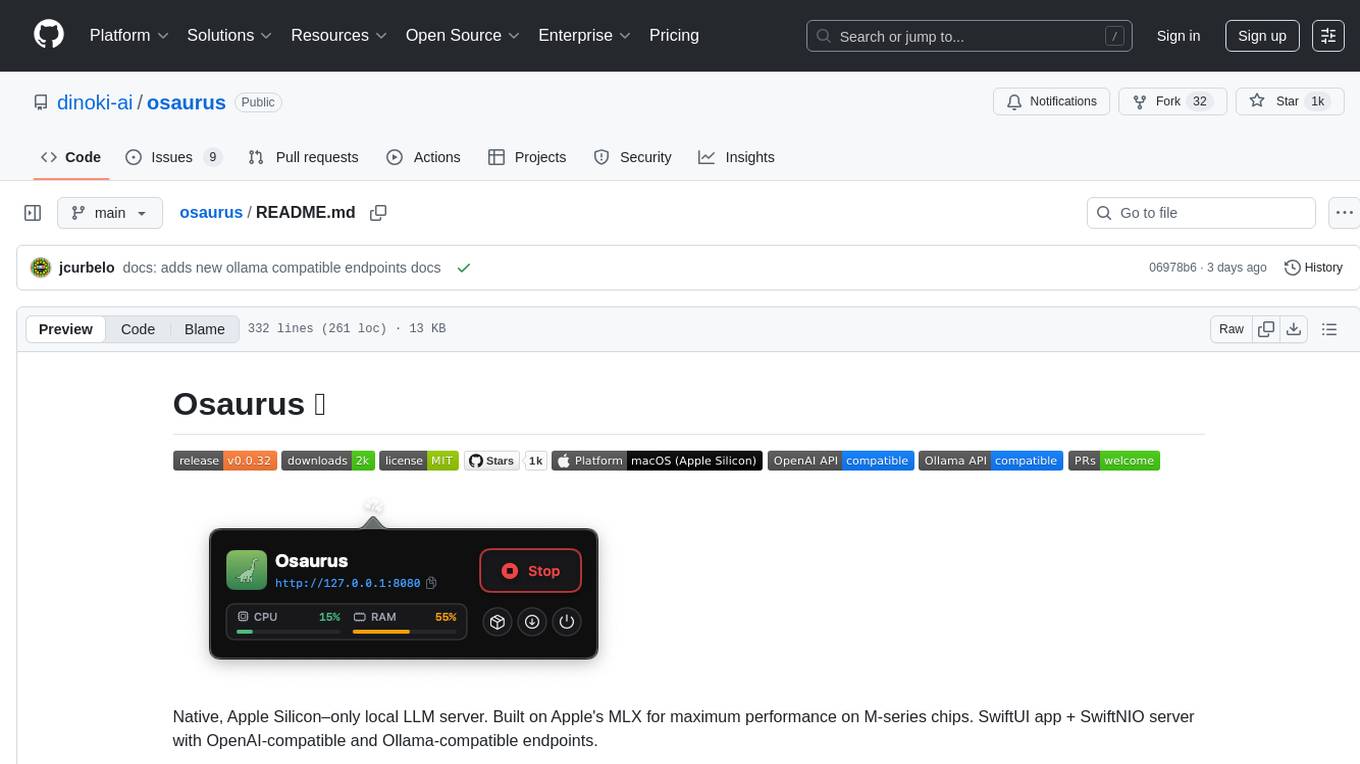
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
README:




Native, Apple Silicon–only local LLM server. Built on Apple's MLX for maximum performance on M‑series chips. SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints.
Created by Dinoki Labs (dinoki.ai), a fully native desktop AI assistant and companion.
- Native MLX runtime: Optimized for Apple Silicon using MLX/MLXLLM
- Apple Silicon only: Designed and tested for M‑series Macs
-
OpenAI API compatible:
/v1/modelsand/v1/chat/completions(stream and non‑stream) -
Ollama‑compatible:
/chatendpoint with NDJSON streaming for OllamaKit and other Ollama clients -
Function/Tool calling: OpenAI‑style
tools+tool_choice, withtool_callsparsing and streaming deltas - Fast token streaming: Server‑Sent Events for low‑latency output
-
Model manager UI: Browse, download, and manage MLX models from
mlx-community - System resource monitor: Real-time CPU and RAM usage visualization
- Self‑contained: SwiftUI app with an embedded SwiftNIO HTTP server
- macOS 15.5+
- Apple Silicon (M1 or newer)
- Xcode 16.4+ (to build from source)
osaurus/
├── Core/
│ ├── AppDelegate.swift
│ └── osaurusApp.swift
├── Controllers/
│ ├── ServerController.swift # NIO server lifecycle
│ └── ModelManager.swift # Model discovery & downloads (Hugging Face)
├── Models/
│ ├── MLXModel.swift
│ ├── OpenAIAPI.swift # OpenAI‑compatible DTOs
│ ├── ResponseWriters.swift # SSE and NDJSON response writers
│ ├── ServerConfiguration.swift
│ └── ServerHealth.swift
├── Networking/
│ ├── HTTPHandler.swift # Request parsing & routing entry
│ ├── Router.swift # Routes → handlers with path normalization
│ └── AsyncHTTPHandler.swift # Unified streaming handler
├── Services/
│ ├── MLXService.swift # MLX loading, session caching, generation
│ ├── SearchService.swift
│ └── SystemMonitorService.swift # Real-time CPU and RAM monitoring
├── Theme/
│ └── Theme.swift
├── Views/
│ ├── Components/SimpleComponents.swift
│ ├── ContentView.swift # Start/stop server, quick controls
│ └── ModelDownloadView.swift # Browse/download/manage models
└── Assets.xcassets/
- Native MLX text generation with model
- Model manager with curated suggestions (Llama, Qwen, Gemma, Mistral, etc.)
- Download sizes estimated via Hugging Face metadata
- Streaming and non‑streaming chat completions
- Multiple response formats: SSE (OpenAI‑style) and NDJSON (Ollama‑style)
- Compatible with OllamaKit and other Ollama client libraries
- OpenAI‑compatible function calling with robust parser for model outputs (handles code fences/formatting noise)
- Auto‑detects stop sequences and BOS token from tokenizer configs
- Health endpoint and simple status UI
- Real-time system resource monitoring
- Path normalization for API compatibility
The following are 20-run averages from our batch benchmark suite. See raw results for details and variance.
| Server | Model | TTFT avg (ms) | Total avg (ms) | Chars/s avg | TTFT rel | Total rel | Chars/s rel | Success |
|---|---|---|---|---|---|---|---|---|
| Osaurus | llama-3.2-3b-instruct-4bit | 86 | 1314 | 558 | 0% | 0% | 0% | 100% |
| Ollama | llama3.2 | 58 | 1655 | 434 | +32% | -26% | -22% | 100% |
| LM Studio | llama-3.2-3b-instruct | 56 | 1203 | 610 | +34% | +8% | +9% | 100% |
- Metrics: TTFT = time-to-first-token, Total = time to final token, Chars/s = streaming throughput.
- Relative % vs Osaurus baseline: TTFT/Total computed as 1 - other/osaurus; Chars/s as other/osaurus - 1. Positive = better.
- Data sources:
results/osaurus-vs-ollama-lmstudio-batch.summary.json,results/osaurus-vs-ollama-lmstudio-batch.results.csv. - How to reproduce:
scripts/run_bench.shcallsscripts/benchmark_models.pyto run prompts across servers and write results.
-
GET /→ Plain text status -
GET /health→ JSON health info -
GET /models→ OpenAI‑compatible models list -
GET /tags→ Ollama‑compatible models list -
POST /chat/completions→ OpenAI‑compatible chat completions -
POST /chat→ Ollama‑compatible chat endpoint
Path normalization: All endpoints support common API prefixes (/v1, /api, /v1/api). For example:
-
/v1/models→/models -
/api/chat/completions→/chat/completions -
/api/chat→/chat(Ollama‑style)
Download the latest signed build from the Releases page.
- Open
osaurus.xcodeprojin Xcode 16.4+ - Build and run the
osaurustarget - In the UI, configure the port via the gear icon (default
8080) and press Start - Open the model manager to download a model (e.g., "Llama 3.2 3B Instruct 4bit")
Models are stored by default at ~/MLXModels. Override with the environment variable OSU_MODELS_DIR.
Base URL: http://127.0.0.1:8080 (or your chosen port)
List models:
curl -s http://127.0.0.1:8080/v1/models | jqOllama‑compatible models list:
curl -s http://127.0.0.1:8080/v1/tags | jqNon‑streaming chat completion:
curl -s http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.2-3b-instruct-4bit",
"messages": [{"role":"user","content":"Write a haiku about dinosaurs"}],
"max_tokens": 200
}'Streaming chat completion (SSE format for /chat/completions):
curl -N http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.2-3b-instruct-4bit",
"messages": [{"role":"user","content":"Summarize Jurassic Park in one paragraph"}],
"stream": true
}'Ollama‑compatible streaming (NDJSON format for /chat):
curl -N http://127.0.0.1:8080/v1/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.2-3b-instruct-4bit",
"messages": [{"role":"user","content":"Tell me about dinosaurs"}],
"stream": true
}'This endpoint is compatible with OllamaKit and other Ollama client libraries.
Tip: Model names are lower‑cased with hyphens (derived from the friendly name), for example: Llama 3.2 3B Instruct 4bit → llama-3.2-3b-instruct-4bit.
If you're building a macOS app (Swift/Objective‑C/SwiftUI/Electron) and want to discover and connect to a running Osaurus instance, see the Shared Configuration guide: SHARED_CONFIGURATION_GUIDE.md.
Osaurus supports OpenAI‑style function calling. Send tools and optional tool_choice in your request. The model is instructed to reply with an exact JSON object containing tool_calls, and the server parses it, including common formatting like code fences.
Define tools and let the model decide (tool_choice: "auto"):
curl -s http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.2-3b-instruct-4bit",
"messages": [
{"role":"system","content":"You can call functions to answer queries succinctly."},
{"role":"user","content":"What\'s the weather in SF?"}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather by city name",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]
}
}
}
],
"tool_choice": "auto"
}'Non‑stream response will include message.tool_calls and finish_reason: "tool_calls". Streaming responses emit OpenAI‑style deltas for tool_calls (id, type, function name, and chunked arguments), finishing with finish_reason: "tool_calls" and [DONE].
After you execute a tool, continue the conversation by sending a tool role message with tool_call_id:
curl -s http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama-3.2-3b-instruct-4bit",
"messages": [
{"role":"user","content":"What\'s the weather in SF?"},
{"role":"assistant","content":"","tool_calls":[{"id":"call_1","type":"function","function":{"name":"get_weather","arguments":"{\"city\":\"SF\"}"}}]},
{"role":"tool","tool_call_id":"call_1","content":"{\"tempC\":18,\"conditions\":\"Foggy\"}"}
]
}'Notes:
- Only
type: "function"tools are supported. - Arguments must be a JSON‑escaped string in the assistant response; Osaurus also tolerates a nested
parametersobject and will normalize. - Parser accepts minor formatting noise like code fences and
assistant:prefixes.
Point your client at Osaurus and use any placeholder API key.
Python example:
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:8080/v1", api_key="osaurus")
resp = client.chat.completions.create(
model="llama-3.2-3b-instruct-4bit",
messages=[{"role": "user", "content": "Hello there!"}],
)
print(resp.choices[0].message.content)Python with tools (non‑stream):
import json
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:8080/v1", api_key="osaurus")
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather by city",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}
]
resp = client.chat.completions.create(
model="llama-3.2-3b-instruct-4bit",
messages=[{"role": "user", "content": "Weather in SF?"}],
tools=tools,
tool_choice="auto",
)
tool_calls = resp.choices[0].message.tool_calls or []
for call in tool_calls:
args = json.loads(call.function.arguments)
result = {"tempC": 18, "conditions": "Foggy"} # your tool result
followup = client.chat.completions.create(
model="llama-3.2-3b-instruct-4bit",
messages=[
{"role": "user", "content": "Weather in SF?"},
{"role": "assistant", "content": "", "tool_calls": tool_calls},
{"role": "tool", "tool_call_id": call.id, "content": json.dumps(result)},
],
)
print(followup.choices[0].message.content)Osaurus includes built‑in CORS support for browser clients.
- Disabled by default: No CORS headers are sent unless you configure allowed origins.
-
Enable via UI: gear icon → Advanced Settings → CORS Settings → Allowed Origins.
- Enter a comma‑separated list, for example:
http://localhost:3000, http://127.0.0.1:5173, https://app.example.com - Use
*to allow any origin (recommended only for local development).
- Enter a comma‑separated list, for example:
- Expose to network: If you need to access from other devices, also enable "Expose to network" in Network Settings.
Behavior when CORS is enabled:
- Requests with an allowed
OriginreceiveAccess-Control-Allow-Origin(either the specific origin or*). - Preflight
OPTIONSrequests are answered with204 No Contentand headers:-
Access-Control-Allow-Methods: echoes requested method or defaults toGET, POST, OPTIONS, HEAD -
Access-Control-Allow-Headers: echoes requested headers or defaults toContent-Type, Authorization Access-Control-Max-Age: 600
-
- Streaming endpoints also include CORS headers on their responses.
Quick examples
Configure via UI (persists to app settings). The underlying config includes:
{
"allowedOrigins": ["http://localhost:3000", "https://app.example.com"]
}Browser fetch from a web app running on http://localhost:3000:
await fetch("http://127.0.0.1:8080/v1/chat/completions", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: "llama-3.2-3b-instruct-4bit",
messages: [{ role: "user", content: "Hello!" }],
}),
});Notes
- Leave the field empty to disable CORS entirely.
-
*cannot be combined with credentials; Osaurus does not use cookies, so this is typically fine for local use.
- Curated suggestions include Llama, Qwen, Gemma, Mistral, Phi, DeepSeek, etc. (4‑bit variants for speed)
- Discovery pulls from Hugging Face
mlx-communityand computes size estimates - Required files are fetched automatically (tokenizer/config/weights)
- Change the models directory with
OSU_MODELS_DIR
- Apple Silicon only (requires MLX); Intel Macs are not supported
- Localhost only, no authentication; put behind a proxy if exposing externally
-
/transcribeendpoints are placeholders pending Whisper integration
- SwiftNIO (HTTP server)
- SwiftUI/AppKit (UI)
- MLX‑Swift, MLXLLM (runtime and generation)
- wizardeur — first PR creator
- Join us on Discord
- Read the Contributing Guide and our Code of Conduct
- See our Security Policy for reporting vulnerabilities
- Get help in Support
- Pick up a good first issue or help wanted
If you find Osaurus useful, please ⭐ the repo and share it!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for osaurus
Similar Open Source Tools
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
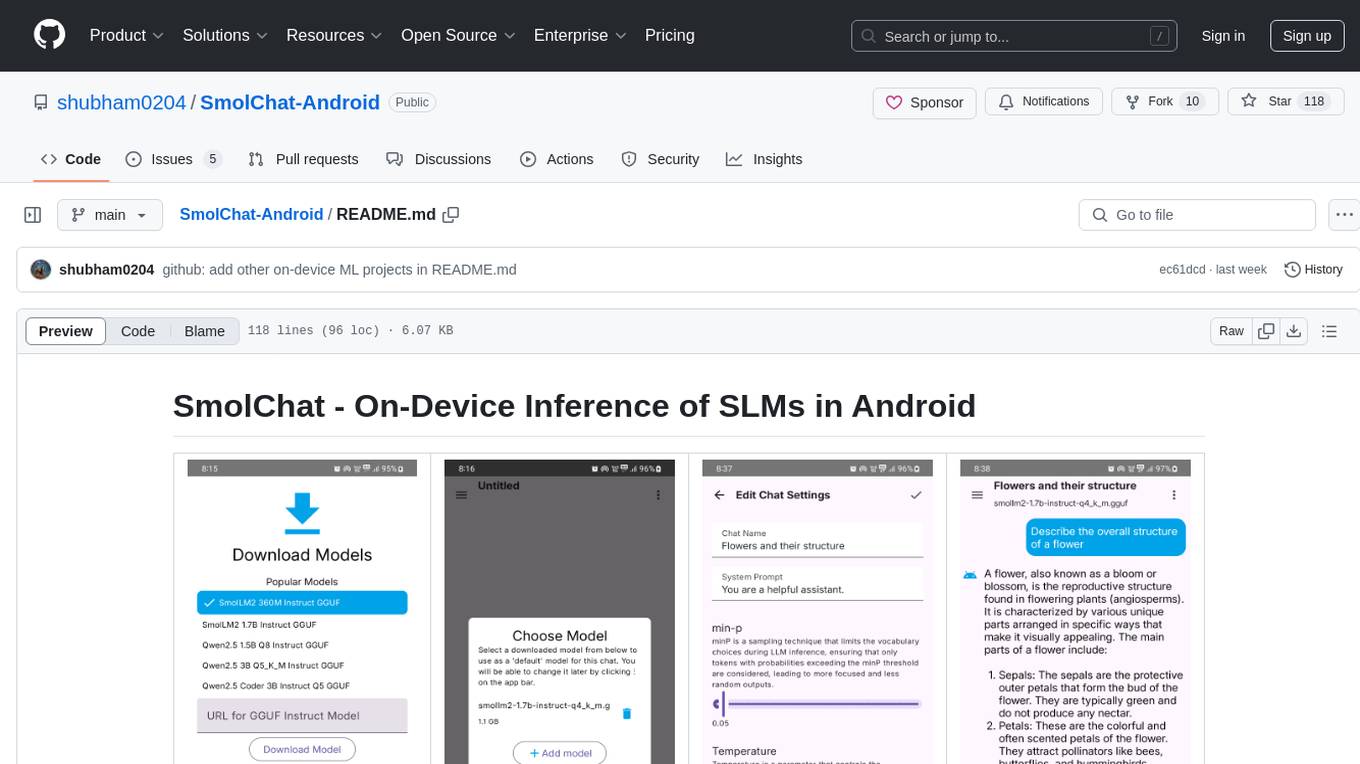
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.

chatluna
Chatluna is a machine learning model plugin that provides chat services with large language models. It is highly extensible, supports multiple output formats, and offers features like custom conversation presets, rate limiting, and context awareness. Users can deploy Chatluna under Koishi without additional configuration. The plugin supports various models/platforms like OpenAI, Azure OpenAI, Google Gemini, and more. It also provides preset customization using YAML files and allows for easy forking and development within Koishi projects. However, the project lacks web UI, HTTP server, and project documentation, inviting contributions from the community.
koog
Koog is a Kotlin-based framework for building and running AI agents entirely in idiomatic Kotlin. It allows users to create agents that interact with tools, handle complex workflows, and communicate with users. Key features include pure Kotlin implementation, MCP integration, embedding capabilities, custom tool creation, ready-to-use components, intelligent history compression, powerful streaming API, persistent agent memory, comprehensive tracing, flexible graph workflows, modular feature system, scalable architecture, and multiplatform support.

hyper-mcp
hyper-mcp is a fast and secure MCP server that enables adding AI capabilities to applications through WebAssembly plugins. It supports writing plugins in various languages, distributing them via standard OCI registries, and running them in resource-constrained environments. The tool offers sandboxing with WASM for limiting access, cross-platform compatibility, and deployment flexibility. Security features include sandboxed plugins, memory-safe execution, secure plugin distribution, and fine-grained access control. Users can configure the tool for global or project-specific use, start the server with different transport options, and utilize available plugins for tasks like time calculations, QR code generation, hash generation, IP retrieval, and webpage fetching.
llama.ui
llama.ui is an open-source desktop application that provides a beautiful, user-friendly interface for interacting with large language models powered by llama.cpp. It is designed for simplicity and privacy, allowing users to chat with powerful quantized models on their local machine without the need for cloud services. The project offers multi-provider support, conversation management with indexedDB storage, rich UI components including markdown rendering and file attachments, advanced features like PWA support and customizable generation parameters, and is privacy-focused with all data stored locally in the browser.
arcade-ai
Arcade AI is a developer-focused tooling and API platform designed to enhance the capabilities of LLM applications and agents. It simplifies the process of connecting agentic applications with user data and services, allowing developers to concentrate on building their applications. The platform offers prebuilt toolkits for interacting with various services, supports multiple authentication providers, and provides access to different language models. Users can also create custom toolkits and evaluate their tools using Arcade AI. Contributions are welcome, and self-hosting is possible with the provided documentation.
meeting-minutes
An open-source AI assistant for taking meeting notes that captures live meeting audio, transcribes it in real-time, and generates summaries while ensuring user privacy. Perfect for teams to focus on discussions while automatically capturing and organizing meeting content without external servers or complex infrastructure. Features include modern UI, real-time audio capture, speaker diarization, local processing for privacy, and more. The tool also offers a Rust-based implementation for better performance and native integration, with features like live transcription, speaker diarization, and a rich text editor for notes. Future plans include database connection for saving meeting minutes, improving summarization quality, and adding download options for meeting transcriptions and summaries. The backend supports multiple LLM providers through a unified interface, with configurations for Anthropic, Groq, and Ollama models. System architecture includes core components like audio capture service, transcription engine, LLM orchestrator, data services, and API layer. Prerequisites for setup include Node.js, Python, FFmpeg, and Rust. Development guidelines emphasize project structure, testing, documentation, type hints, and ESLint configuration. Contributions are welcome under the MIT License.
jadx-mcp-server
JADX-MCP-SERVER is a standalone Python server that interacts with JADX-AI-MCP Plugin to analyze Android APKs using LLMs like Claude. It enables live communication with decompiled Android app context, uncovering vulnerabilities, parsing manifests, and facilitating reverse engineering effortlessly. The tool combines JADX-AI-MCP and JADX MCP SERVER to provide real-time reverse engineering support with LLMs, offering features like quick analysis, vulnerability detection, AI code modification, static analysis, and reverse engineering helpers. It supports various MCP tools for fetching class information, text, methods, fields, smali code, AndroidManifest.xml content, strings.xml file, resource files, and more. Tested on Claude Desktop, it aims to support other LLMs in the future, enhancing Android reverse engineering and APK modification tools connectivity for easier reverse engineering purely from vibes.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
fastapi
智元 Fast API is a one-stop API management system that unifies various LLM APIs in terms of format, standards, and management, achieving the ultimate in functionality, performance, and user experience. It supports various models from companies like OpenAI, Azure, Baidu, Keda Xunfei, Alibaba Cloud, Zhifu AI, Google, DeepSeek, 360 Brain, and Midjourney. The project provides user and admin portals for preview, supports cluster deployment, multi-site deployment, and cross-zone deployment. It also offers Docker deployment, a public API site for registration, and screenshots of the admin and user portals. The API interface is similar to OpenAI's interface, and the project is open source with repositories for API, web, admin, and SDK on GitHub and Gitee.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.
GPTQModel
GPTQModel is an easy-to-use LLM quantization and inference toolkit based on the GPTQ algorithm. It provides support for weight-only quantization and offers features such as dynamic per layer/module flexible quantization, sharding support, and auto-heal quantization errors. The toolkit aims to ensure inference compatibility with HF Transformers, vLLM, and SGLang. It offers various model supports, faster quant inference, better quality quants, and security features like hash check of model weights. GPTQModel also focuses on faster quantization, improved quant quality as measured by PPL, and backports bug fixes from AutoGPTQ.
ai-manus
AI Manus is a general-purpose AI Agent system that supports running various tools and operations in a sandbox environment. It offers deployment with minimal dependencies, supports multiple tools like Terminal, Browser, File, Web Search, and messaging tools, allocates separate sandboxes for tasks, manages session history, supports stopping and interrupting conversations, file upload and download, and is multilingual. The system also provides user login and authentication. The project primarily relies on Docker for development and deployment, with model capability requirements and recommended Deepseek and GPT models.
For similar tasks
gorilla
Gorilla is a tool that enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, you can use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. Gorilla also releases APIBench, the largest collection of APIs, curated and easy to be trained on!

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.
awesome-llm-json
This repository is an awesome list dedicated to resources for using Large Language Models (LLMs) to generate JSON or other structured outputs. It includes terminology explanations, hosted and local models, Python libraries, blog articles, videos, Jupyter notebooks, and leaderboards related to LLMs and JSON generation. The repository covers various aspects such as function calling, JSON mode, guided generation, and tool usage with different providers and models.
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.

ragtacts
Ragtacts is a Clojure library that allows users to easily interact with Large Language Models (LLMs) such as OpenAI's GPT-4. Users can ask questions to LLMs, create question templates, call Clojure functions in natural language, and utilize vector databases for more accurate answers. Ragtacts also supports RAG (Retrieval-Augmented Generation) method for enhancing LLM output by incorporating external data. Users can use Ragtacts as a CLI tool, API server, or through a RAG Playground for interactive querying.

DelphiOpenAI
Delphi OpenAI API is an unofficial library providing Delphi implementation over OpenAI public API. It allows users to access various models, make completions, chat conversations, generate images, and call functions using OpenAI service. The library aims to facilitate tasks such as content generation, semantic search, and classification through AI models. Users can fine-tune models, work with natural language processing, and apply reinforcement learning methods for diverse applications.
token.js
Token.js is a TypeScript SDK that integrates with over 200 LLMs from 10 providers using OpenAI's format. It allows users to call LLMs, supports tools, JSON outputs, image inputs, and streaming, all running on the client side without the need for a proxy server. The tool is free and open source under the MIT license.
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.