
SmolChat-Android
Running any GGUF SLMs/LLMs locally, on-device in Android
Stars: 507
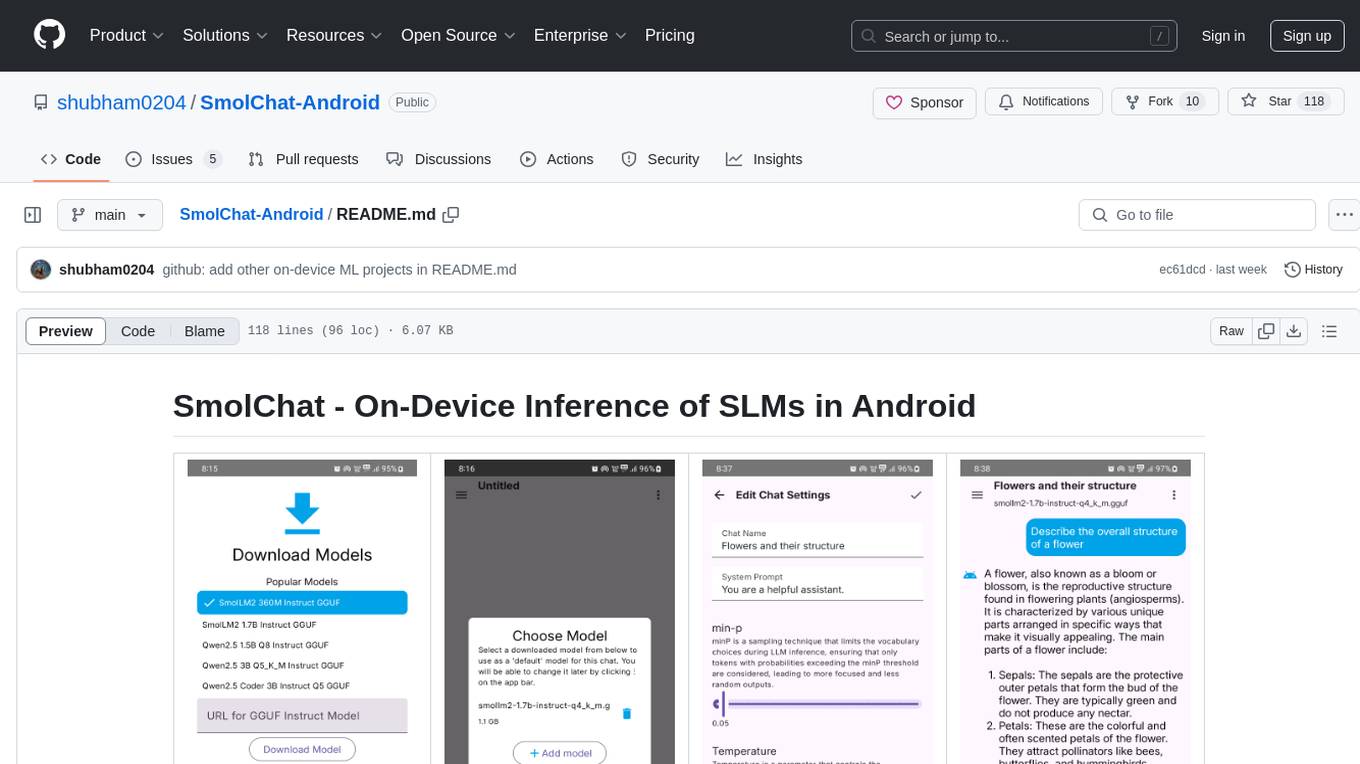
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.
README:
![]()

|

|

|

|

|

|

- Download the latest APK from GitHub Releases and transfer it to your Android device.
- If your device does not downloading APKs from untrusted sources, search for how to allow downloading APKs from unknown sources for your device.
Obtainium allows users to update/download apps directly from their sources, like GitHub or FDroid.
- Download the Obtainium app by choosing your device architecture or 'Download Universal APK'.
- From the bottom menu, select '➕Add App'
- In the text field labelled 'App source URL *', enter the following URL and click 'Add' besides the text field:
https://github.com/shubham0204/SmolChat-Android - SmolChat should now be visible in the 'Apps' screen. You can get notifications about newer releases and download them directly without going to the GitHub repo.
- Provide a usable user interface to interact with local SLMs (small language models) locally, on-device
- Allow users to add/remove SLMs (GGUF models) and modify their system prompts or inference parameters (temperature, min-p)
- Allow users to create specific-downstream tasks quickly and use SLMs to generate responses
- Simple, easy to understand, extensible codebase
- Clone the repository with its submodule originating from llama.cpp,
git clone --depth=1 https://github.com/shubham0204/SmolChat-Android
cd SmolChat-Android
git submodule update --init --recursive
-
Android Studio starts building the project automatically. If not, select Build > Rebuild Project to start a project build.
-
After a successful project build, connect an Android device to your system. Once connected, the name of the device must be visible in top menu-bar in Android Studio.
-
The application uses llama.cpp to load and execute GGUF models. As llama.cpp is written in pure C/C++, it is easy to compile on Android-based targets using the NDK.
-
The
smollmmodule uses allm_inference.cppclass which interacts with llama.cpp's C-style API to execute the GGUF model and a JNI bindingsmollm.cpp. Check the C++ source files here. On the Kotlin side, theSmolLMclass provides the required methods to interact with the JNI (C++ side) bindings. -
The
appmodule contains the application logic and UI code. Whenever a new chat is opened, the app instantiates theSmolLMclass and provides it the model file-path which is stored by theLLMModelentity. Next, the app adds messages with roleuserandsystemto the chat by retrieving them from the database and usingLLMInference::addChatMessage. -
For tasks, the messages are not persisted, and we inform to
LLMInferenceby passing_storeChats=falsetoLLMInference::loadModel.
-
ggerganov/llama.cpp is a pure C/C++ framework to execute machine learning models on multiple execution backends. It provides a primitive C-style API to interact with LLMs converted to the GGUF format native to ggml/llama.cpp. The app uses JNI bindings to interact with a small class
smollm. cppwhich uses llama.cpp to load and execute GGUF models. -
noties/Markwon is a markdown rendering library for Android. The app uses Markwon and Prism4j (for code syntax highlighting) to render Markdown responses from the SLMs.
- shubham0204/Android-Doc-QA: On-device RAG-based question answering from documents
- shubham0204/OnDevice-Face-Recognition-Android: Realtime face recognition with FaceNet, Mediapipe and ObjectBox's vector database
- shubham0204/FaceRecognition_With_FaceNet_Android: Realtime face recognition with FaceNet, MLKit
- shubham0204/CLIP-Android: On-device CLIP inference in Android (search images with textual queries)
- shubham0204/Segment-Anything-Android: Execute Meta's SAM model in Android with onnxruntime
- shubham0204/Depth-Anything-Android: Execute the Depth-Anything model in Android with onnxruntime for monocular depth estimation
-
shubham0204/Sentence-Embeddings-Android: Generate
sentence-embeddings (from models like
all-MiniLM-L6-V2) in Android
The following features/tasks are planned for the future releases of the app:
- Assign names to chats automatically (just like ChatGPT and Claude)
- Add a search bar to the navigation drawer to search for messages within chats
- Add a background service which uses BlueTooth/HTTP/WiFi to communicate with a desktop application to send queries from the desktop to the mobile device for inference
- Enable auto-scroll when generating partial response in
ChatActivity - Measure RAM consumption
- Integrate Android-Doc-QA for on-device RAG-based question answering from documents
- Check if llama.cpp can be compiled to use Vulkan for inference on Android devices (and use the mobile GPU)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SmolChat-Android
Similar Open Source Tools
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
omnichain
OmniChain is a tool for building efficient self-updating visual workflows using AI language models, enabling users to automate tasks, create chatbots, agents, and integrate with existing frameworks. It allows users to create custom workflows guided by logic processes, store and recall information, and make decisions based on that information. The tool enables users to create tireless robot employees that operate 24/7, access the underlying operating system, generate and run NodeJS code snippets, and create custom agents and logic chains. OmniChain is self-hosted, open-source, and available for commercial use under the MIT license, with no coding skills required.

BentoVLLM
BentoVLLM is an example project demonstrating how to serve and deploy open-source Large Language Models using vLLM, a high-throughput and memory-efficient inference engine. It provides a basis for advanced code customization, such as custom models, inference logic, or vLLM options. The project allows for simple LLM hosting with OpenAI compatible endpoints without the need to write any code. Users can interact with the server using Swagger UI or other methods, and the service can be deployed to BentoCloud for better management and scalability. Additionally, the repository includes integration examples for different LLM models and tools.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.

DB-GPT
DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents. It aims to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
qwen-code
Qwen Code is an open-source AI agent optimized for Qwen3-Coder, designed to help users understand large codebases, automate tedious work, and expedite the shipping process. It offers an agentic workflow with rich built-in tools, a terminal-first approach with optional IDE integration, and supports both OpenAI-compatible API and Qwen OAuth authentication methods. Users can interact with Qwen Code in interactive mode, headless mode, IDE integration, and through a TypeScript SDK. The tool can be configured via settings.json, environment variables, and CLI flags, and offers benchmark results for performance evaluation. Qwen Code is part of an ecosystem that includes AionUi and Gemini CLI Desktop for graphical interfaces, and troubleshooting guides are available for issue resolution.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
llama.ui
llama.ui is an open-source desktop application that provides a beautiful, user-friendly interface for interacting with large language models powered by llama.cpp. It is designed for simplicity and privacy, allowing users to chat with powerful quantized models on their local machine without the need for cloud services. The project offers multi-provider support, conversation management with indexedDB storage, rich UI components including markdown rendering and file attachments, advanced features like PWA support and customizable generation parameters, and is privacy-focused with all data stored locally in the browser.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
baibot
Baibot is a versatile chatbot framework designed to simplify the process of creating and deploying chatbots. It provides a user-friendly interface for building custom chatbots with various functionalities such as natural language processing, conversation flow management, and integration with external APIs. Baibot is highly customizable and can be easily extended to suit different use cases and industries. With Baibot, developers can quickly create intelligent chatbots that can interact with users in a seamless and engaging manner, enhancing user experience and automating customer support processes.
ai-inference
AI Inference is a Python library that provides tools for deploying and running machine learning models in production environments. It simplifies the process of integrating AI models into applications by offering a high-level API for inference tasks. With AI Inference, developers can easily load pre-trained models, perform inference on new data, and deploy models as RESTful APIs. The library supports various deep learning frameworks such as TensorFlow and PyTorch, making it versatile for a wide range of AI applications.
llms
llms.py is a lightweight CLI, API, and ChatGPT-like alternative to Open WebUI for accessing multiple LLMs. It operates entirely offline, ensuring all data is kept private in browser storage. The tool provides a convenient way to interact with various LLM models without the need for an internet connection, prioritizing user privacy and data security.
For similar tasks
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.

wllama
Wllama is a WebAssembly binding for llama.cpp, a high-performance and lightweight language model library. It enables you to run inference directly on the browser without the need for a backend or GPU. Wllama provides both high-level and low-level APIs, allowing you to perform various tasks such as completions, embeddings, tokenization, and more. It also supports model splitting, enabling you to load large models in parallel for faster download. With its Typescript support and pre-built npm package, Wllama is easy to integrate into your React Typescript projects.
lmstudio.js
lmstudio.js is a pre-release alpha client SDK for LM Studio, allowing users to use local LLMs in JS/TS/Node. It is currently undergoing rapid development with breaking changes expected. Users can follow LM Studio's announcements on Twitter and Discord. The SDK provides API usage for loading models, predicting text, setting up the local LLM server, and more. It supports features like custom loading progress tracking, model unloading, structured output prediction, and cancellation of predictions. Users can interact with LM Studio through the CLI tool 'lms' and perform tasks like text completion, conversation, and getting prediction statistics.
Oxide-Lab
Oxide Lab is a private AI chat desktop application with local LLM support, allowing users to run large language models locally without internet connectivity or external API services. Built with Rust and Tauri v2, it offers a fast and secure chat interface where all inference happens on the user's machine, ensuring data privacy and security. The application supports multiple architectures, model formats, and hardware accelerations, along with streaming text generation and a modern UI built with Svelte and Tailwind CSS.
ai-optimizer
The Oracle AI Optimizer and Toolkit provides a streamlined environment for developers and data scientists to explore Generative Artificial Intelligence (GenAI) and Retrieval-Augmented Generation (RAG) capabilities. It integrates Oracle Database 23ai AI VectorSearch and SelectAI to enhance Large Language Models (LLMs) through RAG.
For similar jobs
react-native-vision-camera
VisionCamera is a powerful, high-performance Camera library for React Native. It features Photo and Video capture, QR/Barcode scanner, Customizable devices and multi-cameras ("fish-eye" zoom), Customizable resolutions and aspect-ratios (4k/8k images), Customizable FPS (30..240 FPS), Frame Processors (JS worklets to run facial recognition, AI object detection, realtime video chats, ...), Smooth zooming (Reanimated), Fast pause and resume, HDR & Night modes, Custom C++/GPU accelerated video pipeline (OpenGL).
iris_android
This repository contains an offline Android chat application based on llama.cpp example. Users can install, download models, and run the app completely offline and privately. To use the app, users need to go to the releases page, download and install the app. Building the app requires downloading Android Studio, cloning the repository, and importing it into Android Studio. The app can be run offline by following specific steps such as enabling developer options, wireless debugging, and downloading the stable LM model. The project is maintained by Nerve Sparks and contributions are welcome through creating feature branches and pull requests.
aiolauncher_scripts
AIO Launcher Scripts is a collection of Lua scripts that can be used with AIO Launcher to enhance its functionality. These scripts can be used to create widget scripts, search scripts, and side menu scripts. They provide various functions such as displaying text, buttons, progress bars, charts, and interacting with app widgets. The scripts can be used to customize the appearance and behavior of the launcher, add new features, and interact with external services.
gemini-android
Gemini Android is a repository showcasing Google's Generative AI on Android using Stream Chat SDK for Compose. It demonstrates the Gemini API for Android, implements UI elements with Jetpack Compose, utilizes Android architecture components like Hilt and AppStartup, performs background tasks with Kotlin Coroutines, and integrates chat systems with Stream Chat Compose SDK for real-time event handling. The project also provides technical content, instructions on building the project, tech stack details, architecture overview, modularization strategies, and a contribution guideline. It follows Google's official architecture guidance and offers a real-world example of app architecture implementation.

blinkid-android
The BlinkID Android SDK is a comprehensive solution for implementing secure document scanning and extraction. It offers powerful capabilities for extracting data from a wide range of identification documents. The SDK provides features for integrating document scanning into Android apps, including camera requirements, SDK resource pre-bundling, customizing the UX, changing default strings and localization, troubleshooting integration difficulties, and using the SDK through various methods. It also offers options for completely custom UX with low-level API integration. The SDK size is optimized for different processor architectures, and API documentation is available for reference. For any questions or support, users can contact the Microblink team at help.microblink.com.
react-native-airship
React Native Airship is a module designed to integrate Airship's iOS and Android SDKs into React Native applications. It provides developers with the necessary tools to incorporate Airship's push notification services seamlessly. The module offers a simple and efficient way to leverage Airship's features within React Native projects, enhancing user engagement and retention through targeted notifications.
gpt_mobile
GPT Mobile is a chat assistant for Android that allows users to chat with multiple models at once. It supports various platforms such as OpenAI GPT, Anthropic Claude, and Google Gemini. Users can customize temperature, top p (Nucleus sampling), and system prompt. The app features local chat history, Material You style UI, dark mode support, and per app language setting for Android 13+. It is built using 100% Kotlin, Jetpack Compose, and follows a modern app architecture for Android developers.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.