
nestia
NestJS Helper + AI Chatbot Development
Stars: 2069
Nestia is a set of helper libraries for NestJS, providing super-fast/easy decorators, advanced WebSocket routes, Swagger generator, SDK library generator for clients, mockup simulator for client applications, automatic E2E test functions generator, test program utilizing e2e test functions, benchmark program using e2e test functions, super A.I. chatbot by Swagger document, Swagger-UI with online TypeScript editor, and a CLI tool. It enhances performance significantly and offers a collection of typed fetch functions with DTO structures like tRPC, along with a mockup simulator that is fully automated.
README:


![]()
Nestia is a set of helper libraries for NestJS, supporting below features:
-
@nestia/core:- Super-fast/easy decorators
- Advanced WebSocket routes
-
@nestia/sdk:- Swagger generator, more evolved than ever
- SDK library generator for clients
- Mockup Simulator for client applications
- Automatic E2E test functions generator
-
@nestia/e2e: Test program utilizing e2e test functions -
@nestia/benchmark: Benchmark program using e2e test functions -
@nestia/editor: Swagger-UI with Online TypeScript Editor -
@agentica: Agentic AI library specialized in LLM function calling -
@autobe: Vibe coding agent generating NestJS application -
nestia: Just CLI (command line interface) tool
[!NOTE]
- Only one line required, with pure TypeScript type
- Enhance performance 30x up
- Runtime validator is 20,000x faster than
class-validator- JSON serialization is 200x faster than
class-transformer- Software Development Kit
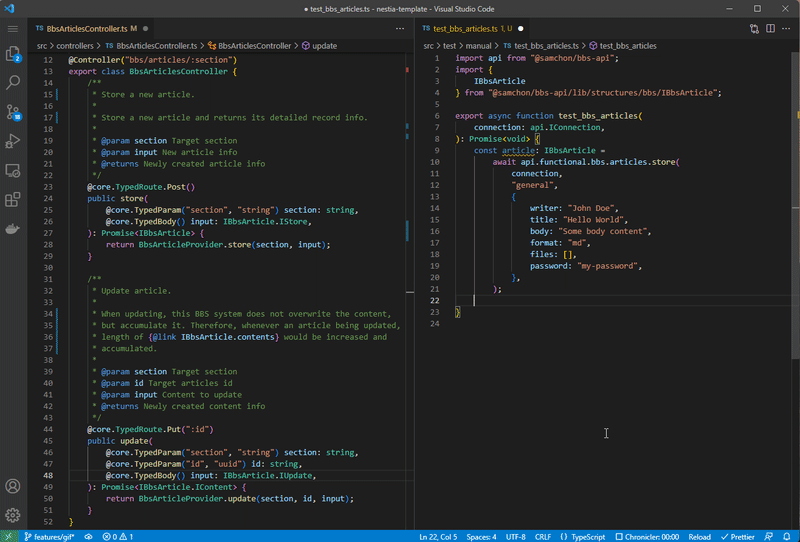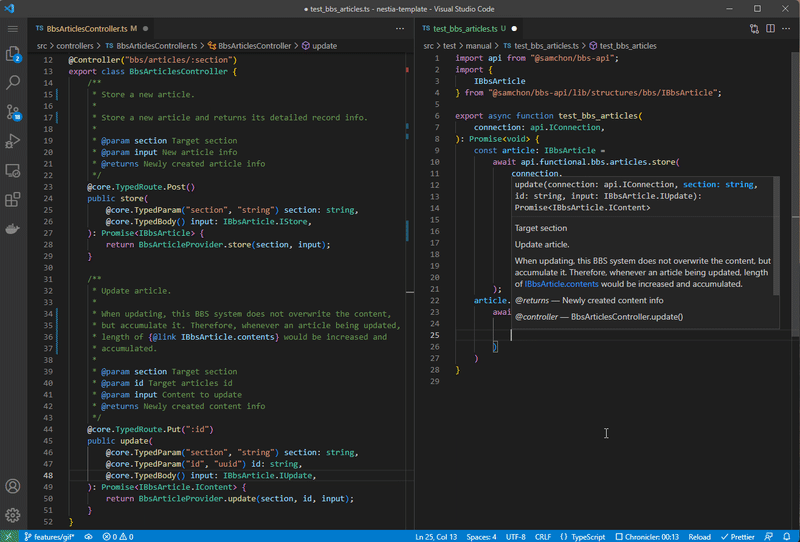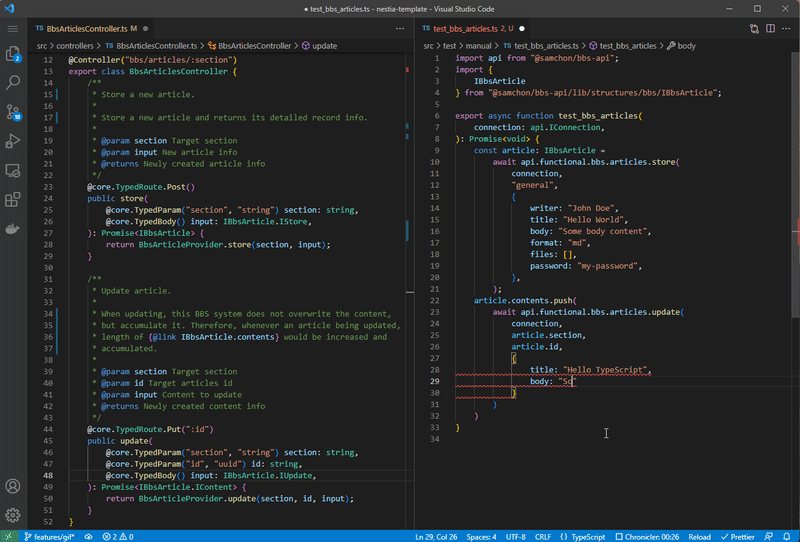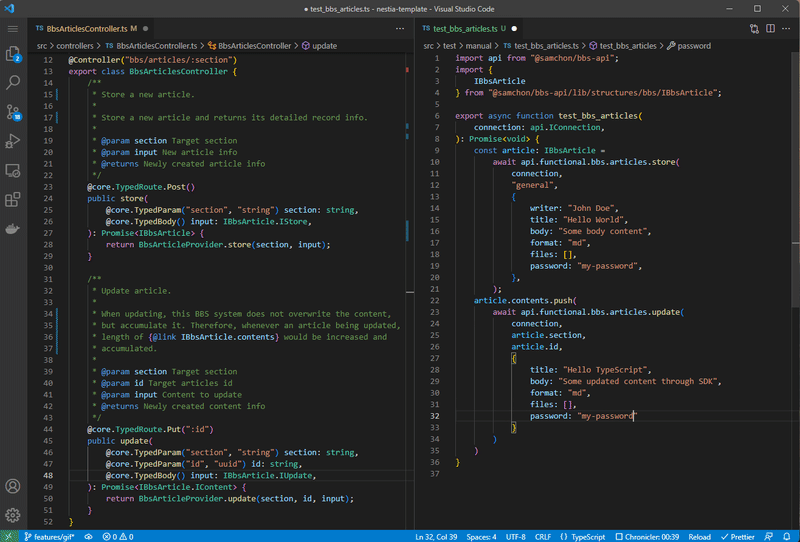
Left is NestJS server code, and right is client (frontend) code utilizing SDK
Thanks for your support.
Your donation would encourage nestia development.

Check out the document in the website:
- Core Library
- Software Development Kit
- Swagger Document
- E2E Testing
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for nestia
Similar Open Source Tools
nestia
Nestia is a set of helper libraries for NestJS, providing super-fast/easy decorators, advanced WebSocket routes, Swagger generator, SDK library generator for clients, mockup simulator for client applications, automatic E2E test functions generator, test program utilizing e2e test functions, benchmark program using e2e test functions, super A.I. chatbot by Swagger document, Swagger-UI with online TypeScript editor, and a CLI tool. It enhances performance significantly and offers a collection of typed fetch functions with DTO structures like tRPC, along with a mockup simulator that is fully automated.

chatluna
Chatluna is a machine learning model plugin that provides chat services with large language models. It is highly extensible, supports multiple output formats, and offers features like custom conversation presets, rate limiting, and context awareness. Users can deploy Chatluna under Koishi without additional configuration. The plugin supports various models/platforms like OpenAI, Azure OpenAI, Google Gemini, and more. It also provides preset customization using YAML files and allows for easy forking and development within Koishi projects. However, the project lacks web UI, HTTP server, and project documentation, inviting contributions from the community.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.
tools
Strands Agents Tools is a community-driven project that provides a powerful set of tools for your agents to use. It bridges the gap between large language models and practical applications by offering ready-to-use tools for file operations, system execution, API interactions, mathematical operations, and more. The tools cover a wide range of functionalities including file operations, shell integration, memory storage, web infrastructure, HTTP client, Slack client, Python execution, mathematical tools, AWS integration, image and video processing, audio output, environment management, task scheduling, advanced reasoning, swarm intelligence, dynamic MCP client, parallel tool execution, browser automation, diagram creation, RSS feed management, and computer automation.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.
ktransformers
KTransformers is a flexible Python-centric framework designed to enhance the user's experience with advanced kernel optimizations and placement/parallelism strategies for Transformers. It provides a Transformers-compatible interface, RESTful APIs compliant with OpenAI and Ollama, and a simplified ChatGPT-like web UI. The framework aims to serve as a platform for experimenting with innovative LLM inference optimizations, focusing on local deployments constrained by limited resources and supporting heterogeneous computing opportunities like GPU/CPU offloading of quantized models.
ai-manus
AI Manus is a general-purpose AI Agent system that supports running various tools and operations in a sandbox environment. It offers deployment with minimal dependencies, supports multiple tools like Terminal, Browser, File, Web Search, and messaging tools, allocates separate sandboxes for tasks, manages session history, supports stopping and interrupting conversations, file upload and download, and is multilingual. The system also provides user login and authentication. The project primarily relies on Docker for development and deployment, with model capability requirements and recommended Deepseek and GPT models.
koog
Koog is a Kotlin-based framework for building and running AI agents entirely in idiomatic Kotlin. It allows users to create agents that interact with tools, handle complex workflows, and communicate with users. Key features include pure Kotlin implementation, MCP integration, embedding capabilities, custom tool creation, ready-to-use components, intelligent history compression, powerful streaming API, persistent agent memory, comprehensive tracing, flexible graph workflows, modular feature system, scalable architecture, and multiplatform support.
crystal
Crystal is an Electron desktop application that allows users to run, inspect, and test multiple Claude Code instances simultaneously using git worktrees. It provides features such as parallel sessions, git worktree isolation, session persistence, git integration, change tracking, notifications, and the ability to run scripts. Crystal simplifies the workflow by creating isolated sessions, iterating with Claude Code, reviewing diff changes, and squashing commits for a clean history. It is a tool designed for collaborative AI notebook editing and testing.
rig
Rig is a Rust library designed for building scalable, modular, and user-friendly applications powered by large language models (LLMs). It provides full support for LLM completion and embedding workflows, offers simple yet powerful abstractions for LLM providers like OpenAI and Cohere, as well as vector stores such as MongoDB and in-memory storage. With Rig, users can easily integrate LLMs into their applications with minimal boilerplate code.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.
nekro-agent
Nekro Agent is an AI chat plugin and proxy execution bot that is highly scalable, offers high freedom, and has minimal deployment requirements. It features context-aware chat for group/private chats, custom character settings, sandboxed execution environment, interactive image resource handling, customizable extension development interface, easy deployment with docker-compose, integration with Stable Diffusion for AI drawing capabilities, support for various file types interaction, hot configuration updates and command control, native multimodal understanding, visual application management control panel, CoT (Chain of Thought) support, self-triggered timers and holiday greetings, event notification understanding, and more. It allows for third-party extensions and AI-generated extensions, and includes features like automatic context trigger based on LLM, and a variety of basic commands for bot administrators.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.

blurr
Panda is a proactive, on-device AI agent for Android that autonomously understands natural language commands and operates your phone's UI to achieve them. It acts as a personal operator, handling complex, multi-step tasks across different applications. With intelligent UI automation, high-quality voice, and personalized local memory, Panda simplifies interactions with technology. Built on Kotlin, Panda's architecture includes Eyes & Hands for physical device connection, The Brain for reasoning, and The Agent for execution. The project is a proof-of-concept aiming to become an indispensable assistant.
jadx-mcp-server
JADX-MCP-SERVER is a standalone Python server that interacts with JADX-AI-MCP Plugin to analyze Android APKs using LLMs like Claude. It enables live communication with decompiled Android app context, uncovering vulnerabilities, parsing manifests, and facilitating reverse engineering effortlessly. The tool combines JADX-AI-MCP and JADX MCP SERVER to provide real-time reverse engineering support with LLMs, offering features like quick analysis, vulnerability detection, AI code modification, static analysis, and reverse engineering helpers. It supports various MCP tools for fetching class information, text, methods, fields, smali code, AndroidManifest.xml content, strings.xml file, resource files, and more. Tested on Claude Desktop, it aims to support other LLMs in the future, enhancing Android reverse engineering and APK modification tools connectivity for easier reverse engineering purely from vibes.
jadx-ai-mcp
JADX-AI-MCP is a plugin for the JADX decompiler that integrates with Model Context Protocol (MCP) to provide live reverse engineering support with LLMs like Claude. It allows for quick analysis, vulnerability detection, and AI code modification, all in real time. The tool combines JADX-AI-MCP and JADX MCP SERVER to analyze Android APKs effortlessly. It offers various prompts for code understanding, vulnerability detection, reverse engineering helpers, static analysis, AI code modification, and documentation. The tool is part of the Zin MCP Suite and aims to connect all android reverse engineering and APK modification tools with a single MCP server for easy reverse engineering of APK files.
For similar tasks

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.

ai-hub
AI Hub Project aims to continuously test and evaluate mainstream large language models, while accumulating and managing various effective model invocation prompts. It has integrated all mainstream large language models in China, including OpenAI GPT-4 Turbo, Baidu ERNIE-Bot-4, Tencent ChatPro, MiniMax abab5.5-chat, and more. The project plans to continuously track, integrate, and evaluate new models. Users can access the models through REST services or Java code integration. The project also provides a testing suite for translation, coding, and benchmark testing.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.

MMC
This repository, MMC, focuses on advancing multimodal chart understanding through large-scale instruction tuning. It introduces a dataset supporting various tasks and chart types, a benchmark for evaluating reasoning capabilities over charts, and an assistant achieving state-of-the-art performance on chart QA benchmarks. The repository provides data for chart-text alignment, benchmarking, and instruction tuning, along with existing datasets used in experiments. Additionally, it offers a Gradio demo for the MMCA model.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.

ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
For similar jobs
google.aip.dev
API Improvement Proposals (AIPs) are design documents that provide high-level, concise documentation for API development at Google. The goal of AIPs is to serve as the source of truth for API-related documentation and to facilitate discussion and consensus among API teams. AIPs are similar to Python's enhancement proposals (PEPs) and are organized into different areas within Google to accommodate historical differences in customs, styles, and guidance.

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.
speakeasy
Speakeasy is a tool that helps developers create production-quality SDKs, Terraform providers, documentation, and more from OpenAPI specifications. It supports a wide range of languages, including Go, Python, TypeScript, Java, and C#, and provides features such as automatic maintenance, type safety, and fault tolerance. Speakeasy also integrates with popular package managers like npm, PyPI, Maven, and Terraform Registry for easy distribution.

apicat
ApiCat is an API documentation management tool that is fully compatible with the OpenAPI specification. With ApiCat, you can freely and efficiently manage your APIs. It integrates the capabilities of LLM, which not only helps you automatically generate API documentation and data models but also creates corresponding test cases based on the API content. Using ApiCat, you can quickly accomplish anything outside of coding, allowing you to focus your energy on the code itself.
aiohttp-pydantic
Aiohttp pydantic is an aiohttp view to easily parse and validate requests. You define using function annotations what your methods for handling HTTP verbs expect, and Aiohttp pydantic parses the HTTP request for you, validates the data, and injects the parameters you want. It provides features like query string, request body, URL path, and HTTP headers validation, as well as Open API Specification generation.
ain
Ain is a terminal HTTP API client designed for scripting input and processing output via pipes. It allows flexible organization of APIs using files and folders, supports shell-scripts and executables for common tasks, handles url-encoding, and enables sharing the resulting curl, wget, or httpie command-line. Users can put things that change in environment variables or .env-files, and pipe the API output for further processing. Ain targets users who work with many APIs using a simple file format and uses curl, wget, or httpie to make the actual calls.
OllamaKit
OllamaKit is a Swift library designed to simplify interactions with the Ollama API. It handles network communication and data processing, offering an efficient interface for Swift applications to communicate with the Ollama API. The library is optimized for use within Ollamac, a macOS app for interacting with Ollama models.
ollama4j
Ollama4j is a Java library that serves as a wrapper or binding for the Ollama server. It facilitates communication with the Ollama server and provides models for deployment. The tool requires Java 11 or higher and can be installed locally or via Docker. Users can integrate Ollama4j into Maven projects by adding the specified dependency. The tool offers API specifications and supports various development tasks such as building, running unit tests, and integration tests. Releases are automated through GitHub Actions CI workflow. Areas of improvement include adhering to Java naming conventions, updating deprecated code, implementing logging, using lombok, and enhancing request body creation. Contributions to the project are encouraged, whether reporting bugs, suggesting enhancements, or contributing code.